
8: Entrenamiento de una Red Neuronal
- Page ID
- 51027
This page is a draft and is under active development.

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)En lo que sigue, vamos a analizar el proceso de entrenamiento en una RNA de dos capas (ver figura 3). La red consta de una capa de entrada (correspondiente a \(l=0\), con dos neuronas), una capa intermedia oculta (correspondiente a \(l=1\), con tres neuronas) y la capa de salida (\(l=2\) y dos neuronas). El objetivo es calcular los pesos de la RNA, utilizando el algoritmo de retropropagación de la siguiente forma:
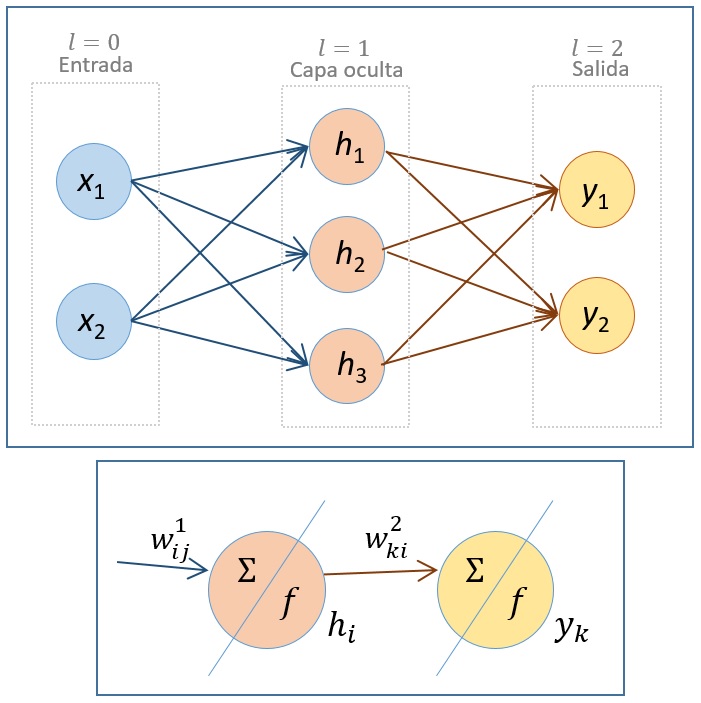
- Las entradas (en \(l=0\)), \(\textbf{x}=(x_1,x_2)^T\) son valores constantes. Vamos a denotar por \(h_i\) la salida de la neurona \(i\) de la capa \(l=1\), que serán a su vez entradas de la capa \(l=2\). Análogamente, denotamos por \(y_1\) e \(y_2\) las salidas de la capa \(l=2\) (salidas de la RNA).
- Los parámetros que debemos ajustar son los pesos (enlaces entre neuronas de diferentes capas). Se denotan por \(w^{l}_{ij}\), donde el superíndice \(l\) hace referencia a la capa a la que llega y los subíndices \(i\) y \(j\) a las neuronas de las capas \(l\) y \(l-1\), respectivamente, que conecta este peso.
- En las neuronas de la capa oculta y de la capa de salida se realizan dos procesos:
- El primero, que simbolizamos con \(\Sigma\), corresponde en ambas capas a la combinación lineal de la salida de la capa anterior con los pesos correspondientes. Esto es:
- En la neurona \(i\) \((i=1,2,3)\) de la capa \(l=1\): \(a^{1}_i=x_1w^1_{i1}+x_2w^1_{i2}\).
- En la neurona \(k\) \((k=1,2)\) de la capa \(l=2\): \(a^{2}_k=h_1w^2_{k1}+h_2w^2_{k2}+h_3w^2_{k3}\).
- El segundo, que represintamos en la figura con \(f\), corresponde a la función de activación que suponemos que es la misma para \(l=1,2\): \[\sigma(u) = \dfrac{1}{1+e^{-u}}\] Recordemos que la derivada de esta función es: \[\sigma ' (u) = \dfrac{e^{-u}}{(1+e^{-u})^2}=\sigma(u)(1-\sigma(u))\] Entonces, tenemos que las salidas de cada capa son:
- \(h_i = \sigma(a^{1}_i)\), \(i=1,2,3\)
- \(y_k = \sigma(a^{2}_k)\), \(k=1,2\)
- El primero, que simbolizamos con \(\Sigma\), corresponde en ambas capas a la combinación lineal de la salida de la capa anterior con los pesos correspondientes. Esto es:
- Definimos la función de pérdida o de error, como se hace usualmente, mediante la desviación cuadrática media \[L(y_1,y_2)=\frac{1}{2} \sum_{k=1}^{2} \left( y_k -t_k \right)^2\] siendo \(t_k\) (\(k=1,2\)) los valores deseados correspondientes a cada salida \(y_k\) de la RNA.
Puesto que nuestro objetivo es minimimar la función de pérdida, debemos buscar los pesos que lo consiguen, utilizando el algoritmo de retropropagación. Se trata de un proceso iterativo en el que se parte de unos valores iniciales para los pesos y estos se van modificando mediante el método del gradiente descendiente. Con los valores iniciales de los pesos, a partir de los valores \(\bf{x}\) se calculan los de \(\bf{a^1}, \bf{h}, \bf{a^2}\) e \(\bf{y}\). Con ellos, partiendo de la capa de salida, vamos hacia atrás:
- Aplicamos la regla de la cadena \[\dfrac{\partial L}{\partial w^{2}_{ki}} \rightarrow \dfrac{\partial L}{\partial y_k}\dfrac{\partial y_k}{\partial a^{2}_k}\dfrac{\partial a^{2}_k}{\partial w^{2}_{ki}}\] con \((k=1,2)\):
- \(\dfrac{\partial }{\partial w^{2}_{ki}}a^{2}_{k}(w^2_{k1},w^2_{k2},w^2_{k3})=h_i \quad (i=1,2,3)\)
- \(\dfrac{\partial y_k}{\partial a^{2}_k} = \dfrac{\partial}{\partial a^{2}_{k}} \sigma (a^{2}_{k})=\sigma(a^{2}_{k})(1-\sigma(a^{2}_{k}))=y_k(1-y_k)\)
- \(\dfrac{\partial }{\partial y_k}L(y_1,y_2) = \left( y_k -t_k \right)\)
Resulta, sustituyendo: \[\dfrac{\partial L}{\partial w^{2}_{ki}} \rightarrow \left( y_k -t_k \right)y_k(1-y_k)h_i\]
- Siguiendo el método del gradiente descendente, actualizamos los pesos \(w^{2}_{ki}\) en esta capa. Llamando \(\textbf{w}^2=\left( w^2_{ki} \right)_{k=1,2;i=1,2,3}\) \[\textbf{w}^2 \leftarrow \textbf{w}^2 - \varepsilon \nabla_{\textbf{w}^2}L\]
- Aplicamos la regla de la cadena en la capa oculta: \[\dfrac{\partial L}{\partial w^{1}_{ij}} \rightarrow \dfrac{\partial L}{\partial h_i}\dfrac{\partial h_i}{\partial a^{1}_i}\dfrac{\partial a^{1}_i}{\partial w^{1}_{ij}}\] con \((i=1,2,3)\):
- \(\dfrac{\partial }{\partial w^{1}_{ij}}a^{1}_i(w^1_{i1},w^1_{i2})=x_j \quad (j=1,2)\)
- \(\dfrac{\partial h_i}{\partial a^{1}_i}=\dfrac{\partial }{\partial a^{1}_i}\sigma (a_i^1)=\sigma(a^{1}_{i})(1-\sigma(a^{1}_{i}))=h_i(1-h_i)\)
- Para calcular \(\dfrac{\partial L}{\partial h_i}\) tenemos en cuenta la dependencia de las funciones respecto a las distintas variables: \(L(y_1,y_2)\), \(y_k(a_k^2)\) y \(a_k^2(h_1,h_2,h_3)\). Así, aplicando la regla de la cadena: \[\dfrac{\partial L}{\partial h_{i}} \rightarrow \dfrac{\partial L}{\partial y_1}\dfrac{\partial y_1}{\partial a^{2}_1}\dfrac{\partial a^{2}_1}{\partial h_{i}} + \dfrac{\partial L}{\partial y_2}\dfrac{\partial y_2}{\partial a^{2}_2}\dfrac{\partial a^{2}_2}{\partial h_{i}}\] Ya habíamos obtenido anteriormente las expresiones para \(\dfrac{\partial L}{\partial y_k}\) y \(\dfrac{\partial y_k}{\partial a^{2}_k}\), por lo que sólo queda calcular el último factor de cada sumando:
- \(\dfrac{\partial a^{k}_2}{\partial h_{i}}=w^{2}_{ki}\)
Sustituyendo: \[\dfrac{\partial L}{\partial w^{1}_{ij}} \rightarrow x_jh_i(1-h_i)\sum^{2}_{k=1}\left[(y_k-t_k)y_k(1-y_k)w^{2}_{ki} \right]\]
- Finalmente, se actualizan los pesos \(w^{1}_{ij}\). Llamando \(\textbf{w}^1=\left( w^1_{ij} \right)_{i=1,2,3:j=1,2}\) \[\textbf{w}^1 \leftarrow \textbf{w}^1 - \varepsilon \nabla_{\textbf{w}^1}L\]
Con esto se ha dado un paso de la iteración de la actualización de los pesos. A continuación, se volvería a repetir el proceso partiendo de los valores de los datos \(\bf{x}\).
En la práctica se suele contar para el entrenamiento con un conjunto de datos (no solo uno) y la función que se minimiza entonces es la suma de todas las “pérdidas” que se tienen al considerar todos esos datos.