
2.4: La distribución normal
- Page ID
- 110006

Hay muchos tipos diferentes de distribuciones (formas) de datos cuantitativos. En la sección 1.5 observamos diferentes histogramas y describimos las formas de los mismos como simétricas, sesgadas a la izquierda y oblicuas a la derecha. Hay una distribución especial de forma simétrica llamada distribución normal. Es alto en el medio y luego baja rápida e igualmente en ambos extremos. Parece una campana, así que a veces se le llama curva de campana. Una propiedad de la distribución normal es que es simétrica con respecto a la media. Otra propiedad tiene que ver con qué porcentaje de los datos cae dentro de ciertas desviaciones estándar de la media. Esta propiedad se define como la Regla empírica.
La Regla Empírica: Dado un conjunto de datos que se distribuye aproximadamente normalmente:
Aproximadamente el 68% de los datos se encuentra dentro de una desviación estándar de la media.
Aproximadamente el 95% de los datos se encuentran dentro de dos desviaciones estándar de la media.
Aproximadamente 99.7% de los datos se encuentran dentro de tres desviaciones estándar de la media.
Para visualizar estos porcentajes, consulte la siguiente figura.
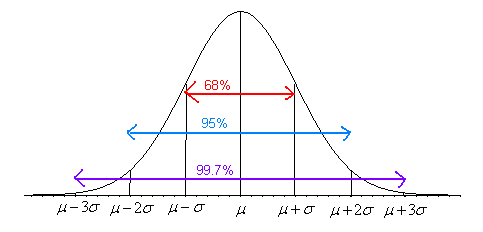
Nota: La regla empírica solo es cierta para distribuciones aproximadamente normales.
Ejemplo\(\PageIndex{1}\): Uso de la regla empírica
Supongamos que tu clase tomó una prueba y la puntuación media fue de 75% y la desviación estándar fue de 5%. Si los resultados de las pruebas siguen una distribución aproximadamente normal, responda las siguientes preguntas:
- ¿Qué porcentaje de los alumnos tuvo puntuaciones entre 65 y 85?
- ¿Qué porcentaje de los alumnos tuvo puntuaciones entre 65 y 75?
- ¿Qué porcentaje de los alumnos tuvo puntuaciones entre 70 y 80?
- ¿Qué porcentaje de los alumnos tuvieron puntuaciones superiores a 85?
Para resolver cada uno de estos, sería útil trazar la curva normal que sigue esta situación. La media es 75, por lo que el centro es 75. La desviación estándar es 5, por lo que para cada línea por encima de la media sumar 5 y por cada línea por debajo de la media resta 5. La gráfica tiene el siguiente aspecto:
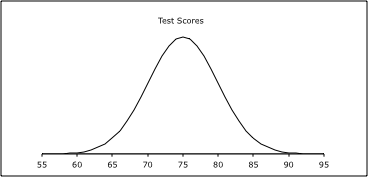
- De la gráfica podemos ver que 95% de los alumnos tuvieron puntuaciones entre 65 y 85.
- Las puntuaciones de 65 a 75 son la mitad del área de la gráfica de 65 a 85. Debido a la simetría, eso significa que el porcentaje para 65 a 85 es ½ del 95%, que es 47.5%.
- De la gráfica podemos ver que 68% de los alumnos tuvieron puntuaciones entre 70 y 80.
- Para este problema necesitamos un poco de matemáticas. Si miraras toda la curva, dirías que el 100% de todos los puntajes de las pruebas caen por debajo de ella. Entonces, debido a la simetría 50% de los puntajes de las pruebas caen en el área por encima de la media y 50% de los puntajes de las pruebas caen en el área por debajo Sabemos por la parte b que el porcentaje de 65 a 75 es de 47.5%. Debido a la simetría, el porcentaje de 75 a 85 también es 47.5%. Por lo que el porcentaje por encima del 85 es 50% - 47.5% = 2.5%.
Cuando miramos Ejemplo\(\PageIndex{1}\), nos damos cuenta de que los números en la escala no son tan importantes como cuántas desviaciones estándar es un número de la media. Como ejemplo, el número 80 es una desviación estándar de la media. El número 65 es 2 desviaciones estándar de la media. Sin embargo, 80 está por encima de la media y 65 está por debajo de la media. Supongamos que quisiéramos saber cuántas desviaciones estándar es el número 82 de la media. ¿Cómo haríamos eso? Los otros números fueron más fáciles porque eran un número entero de desviaciones estándar de la media. Necesitamos una forma de cuantificar esto. Utilizaremos una puntuación z (también conocida como valor z o puntaje estandarizado) para medir cuántas desviaciones estándar es un valor de datos de la media. Esto se define como:
puntuación z:\(z = \dfrac{x-\mu}{\sigma}\)
donde\(x\) = valor de datos (puntaje sin procesar)
\(z\)= valor estandarizado (puntaje z o valor z)
\(\mu\)= media poblacional
\(\sigma\)= desviación estándar de la población
Nota: Recuerde que la puntuación z es siempre cuántas desviaciones estándar es un valor de datos de la media de la distribución.
Supongamos que un valor de datos tiene una puntuación z de 2.13. Esto nos dice dos cosas. En primer lugar, dice que el valor de los datos está por encima de la media, ya que es positivo. Segundo, nos dice que hay que sumar más de dos desviaciones estándar a la media para llegar a este valor. Dado que la mayoría de los datos (95%) están dentro de dos desviaciones estándar, entonces cualquier cosa fuera de este rango se consideraría un valor extraño o inusual. Una puntuación z de 2.13 está fuera de este rango por lo que es un valor inusual. Como otro ejemplo, supongamos que un valor de datos tiene una puntuación z de -1.34. Este valor de datos debe estar por debajo de la media, ya que la puntuación z es negativa, y es necesario restar más de una desviación estándar de la media para llegar a este valor. Dado que esto se encuentra dentro de dos desviaciones estándar, es un valor ordinario.
Un valor inusual tiene una puntuación z < o una puntuación z > 2
Un valor habitual tiene una puntuación z entre y 2, es decir\(-2 < z-score < 2\).
Puede encontrar puntajes estandarizados en informes para pruebas estandarizadas o pruebas de comportamiento como se mencionó anteriormente.
Ejemplo\(\PageIndex{2}\): Cálculo de puntuaciones Z
Supongamos que tu clase tomó una prueba la puntuación media fue de 75% y la desviación estándar fue de 5%. Si los resultados de las pruebas siguen una distribución aproximadamente normal, responda las siguientes preguntas:
- Si un estudiante obtuvo 87 en la prueba, ¿qué es el puntaje z de ese estudiante y qué significa?
\(\mu = 75\),\(\sigma = 5\), y\(x = 87\)
\(z = \dfrac{x-\mu}{\sigma}\)
\( = \dfrac{87-75}{5}\)
\(=2.40\)
Esto significa que la puntuación de 87 es más de dos desviaciones estándar por encima de la media, por lo que se considera una puntuación inusual.
- Si un estudiante obtuvo 73 en la prueba, ¿qué es el puntaje z de ese estudiante y qué significa?
\(\mu = 75\),\(\sigma = 5\), y\(x = 73\)
\(z = \dfrac{x-\mu}{\sigma}\)
\( = \dfrac{73-75}{5}\)
\(=-0.40\)
Esto significa que la puntuación de 73 es menor a la mitad de una desviación estándar por debajo de la media. Se considera que es una puntuación habitual u ordinaria.
- Si un estudiante obtuvo 54 en la prueba, ¿qué es el puntaje z de ese estudiante y qué significa?
\(\mu = 75\),\(\sigma = 5\), y\(x = 54\)
\(z = \dfrac{x-\mu}{\sigma}\)
\( = \dfrac{54-75}{5}\)
\(=-4.20\)
El significa que la puntuación de 54 es más de cuatro desviaciones estándar por debajo de la media, por lo que se considera una puntuación inusual.
- Si un estudiante tiene un puntaje z de 1.43, ¿qué puntaje real obtuvo en la prueba?
\(\mu = 75\),\(\sigma = 5\), y\(z = 1.43\)
Este problema involucra un poco de álgebra. No te preocupes, no es tan difícil. Como ahora está buscando x en lugar de z, reorganice la resolución de ecuaciones para x de la siguiente manera:
\(z = \dfrac{x-\mu}{\sigma}\)
\(z \cdot \sigma= \dfrac{x-\mu}{\cancel{\sigma}} \cdot \cancel{\sigma}\)
\(z \sigma= x - \mu\)
\(z\sigma + \mu = x - \cancel{\mu} + \cancel{\mu}\)
\(x = z\sigma + \mu\)
Ahora, puedes usar esta fórmula para encontrar x cuando te den z.
\(x = z\sigma + \mu \)
\(x = 1.43 \cdot 5 + 75 \)
\(x = 7.15 + 75 \)
\(x = 82.15 \)
Así, la puntuación z de 1.43 corresponde a una puntuación real de prueba de 82.15%.
- Si un alumno tiene un puntaje z de -2.34, ¿qué puntaje real obtuvo en la prueba?
\(\mu = 75\),\(\sigma = 5\), y\(z = -2.34\)
Usa la fórmula para x de la parte d de este problema:
\(x = z\sigma + \mu \)
\(x = -2.34 \cdot 5 + 75 \)
\(x = -11.7 + 75 \)
\(x = 63.3 \)
Así, el puntaje z de -2.34 corresponde a un puntaje real de prueba de 63.3%.
El resumen de cinco números para una distribución normal
Al observar la Regla Empírica, el 99.7% de todos los datos se encuentra dentro de tres desviaciones estándar de la media. Esto significa que una aproximación para el valor mínimo en una distribución normal es la media menos tres veces la desviación estándar, y para el máximo es la media más tres veces la desviación estándar. En una distribución normal, la media y la mediana son las mismas. Por último, el primer cuartil puede aproximarse restando 0.67448 veces la desviación estándar de la media, y el tercer cuartil se puede aproximar sumando 0.67448 veces la desviación estándar a la media. Todos estos juntos dan el resumen de cinco números.
En notación matemática, el resumen de cinco números para la distribución normal con media y desviación estándar
es el siguiente:
Resumen de cinco números para una distribución normal
\(min = \mu - 3\sigma\)
\(Q_{1} = \mu - 0.67448\sigma\)
\(med = \mu \)
\(Q_{3} = \mu + 0.67448\sigma\)
\(max = \mu + 3\sigma\)
Ejemplo\(\PageIndex{3}\): Cálculo del Resumen de Cinco Números para una Distribución Normal
Supongamos que tu clase tomó una prueba y la puntuación media fue de 75% y la desviación estándar fue de 5%. Si los puntajes de las pruebas siguen una distribución aproximadamente normal, encuentra el resumen de cinco números.
La media es\(\mu = 75 \%\) y la desviación estándar es\(\sigma = 5 \%\). Así, el resumen de cinco números para este problema es:
\(min = 75 - 3(5) = 60 \%\)
\(Q_{1} = 75 - 0.67448(5)\approx 71.6 \%\)
\(med = 75 \% \)
\(Q_{3} = 75 + 0.67448(5)\approx 78.4 \%\)
\(max = 75 + 3(5) = 90 \%\)