
16.7: Síntesis de Proteínas de ARN y Código Genético
- Page ID
- 72576
- Describir las características del código genético.
- Describir cómo se sintetiza una proteína a partir de ARNm.
Una de las definiciones de un gen es la siguiente: un segmento de ácido desoxirribonucleico (ADN) que porta el código para un polipéptido específico. Cada molécula de ARN mensajero (ARNm) es una copia transcrita de un gen que es utilizado por una célula para sintetizar una cadena polipeptídica. Si una proteína contiene dos o más cadenas polipeptídicas diferentes, cada cadena está codificada por un gen diferente. Pasamos ahora a la pregunta de cómo la secuencia de nucleótidos en una molécula de ácido ribonucleico (ARN) se traduce en una secuencia de aminoácidos.
¿Cómo puede una molécula que contiene solo 4 nucleótidos diferentes especificar la secuencia de los 20 aminoácidos que ocurren en las proteínas? Si cada nucleótido codificaba para 1 aminoácido, entonces obviamente los ácidos nucleicos podrían codificar solo para 4 aminoácidos. ¿Y si los aminoácidos fueran codificados por grupos de 2 nucleótidos? Hay 4 2, o 16, diferentes combinaciones de 2 nucleótidos (AA, AU, AC, AG, UU, etc.). Dicho código es más extenso pero aún no es adecuado para codificar 20 aminoácidos. Sin embargo, si los nucleótidos están dispuestos en grupos de 3, el número de diferentes combinaciones posibles es 4 3, o 64. Aquí tenemos un código que es lo suficientemente extenso como para dirigir la síntesis de la estructura primaria de una molécula proteica.
Video: Animación de proyecto NDSU Virtual Cell Animations “Traducción”. Para obtener más información, consulte http://vcell.ndsu.nodak.edu/animations
Por lo tanto, el código genético puede describirse como la identificación de cada grupo de tres nucleótidos y su aminoácido particular. La secuencia de estos grupos tripletes en el ARNm dicta la secuencia de los aminoácidos en la proteína. Cada unidad codificadora individual de tres nucleótidos, como hemos visto, se llama codón.
La síntesis de proteínas se logra mediante interacciones ordenadas entre el ARNm y los otros ácidos ribonucleicos (ARN de transferencia [ARNt] y ARN ribosómico [ARNr]), el ribosoma y más de 100 enzimas. El ARNm formado en el núcleo durante la transcripción se transporta a través de la membrana nuclear hacia el citoplasma hasta los ribosomas, llevando consigo las instrucciones genéticas. El proceso en el que la información codificada en el ARNm se usa para dirigir la secuenciación de aminoácidos y así finalmente sintetizar una proteína se denomina traducción.
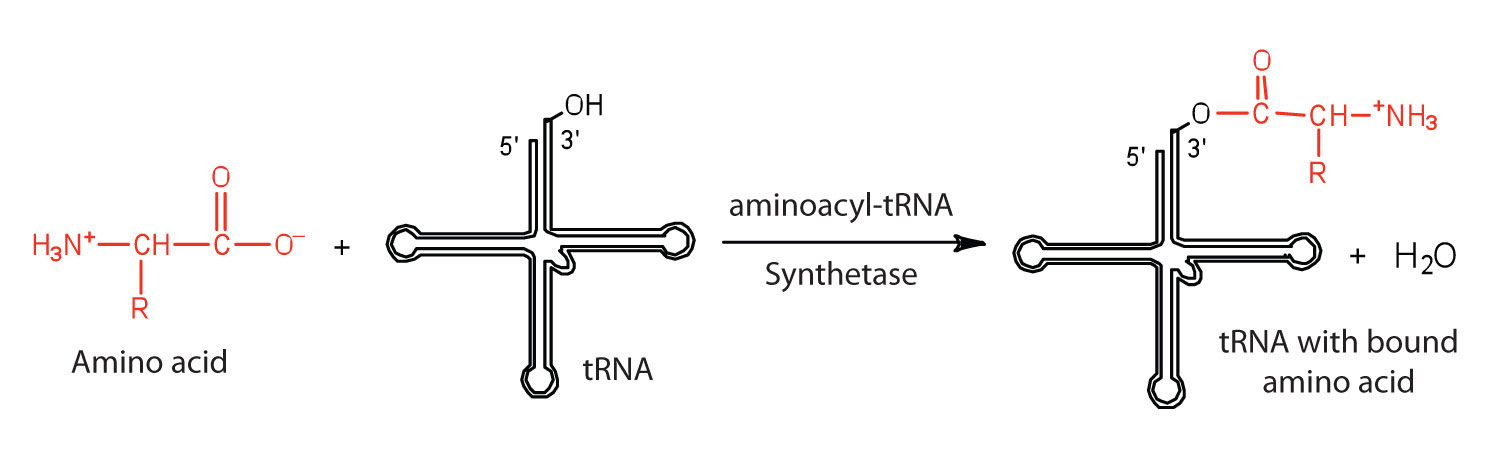
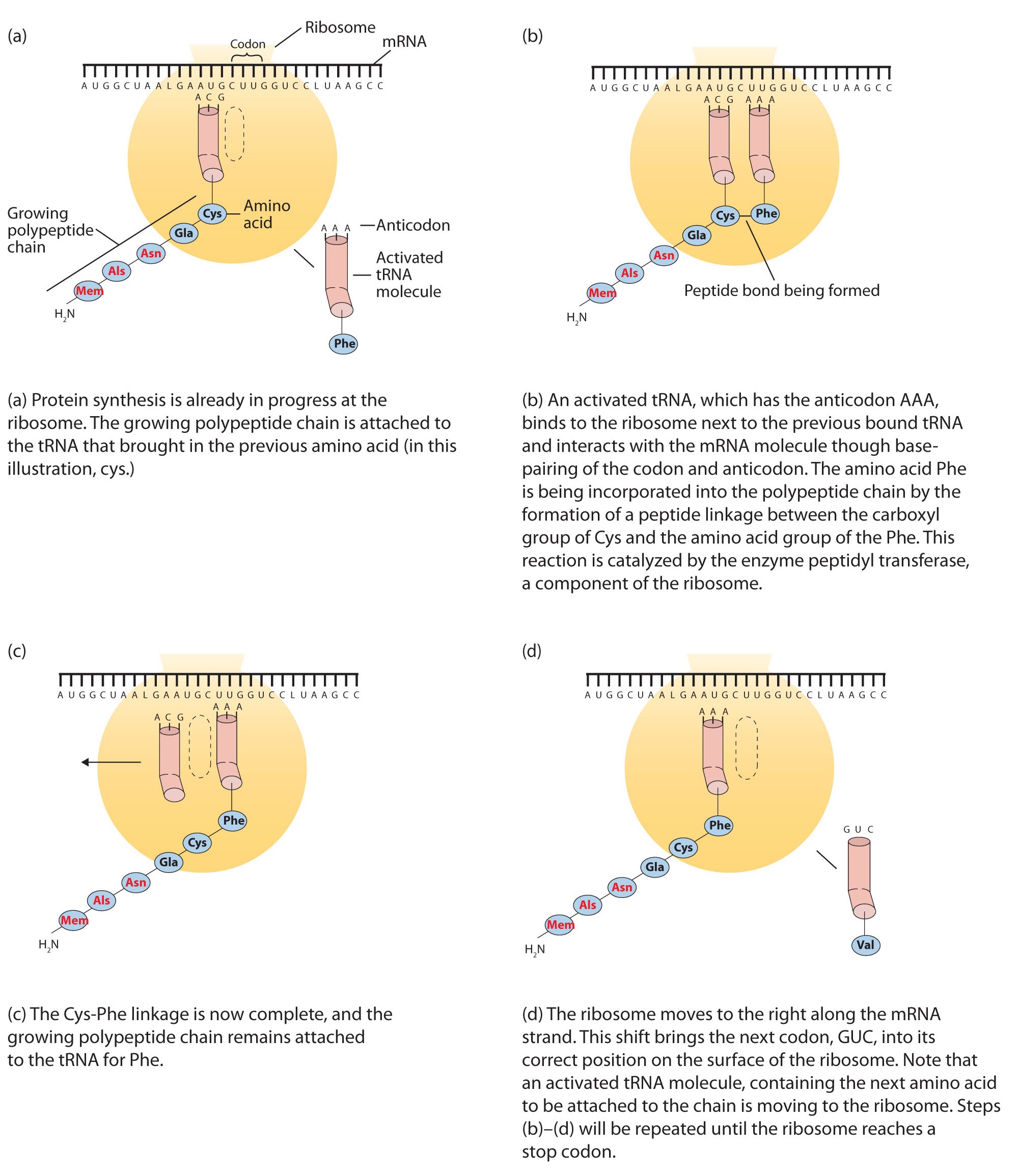
Antes de que un aminoácido pueda incorporarse a una cadena polipeptídica, debe unirse a su ARNt único. Este proceso crucial requiere de una enzima conocida como aminoacil-ARNt sintetasa (Figura\(\PageIndex{1}\)). Hay una aminoacil-ARNt sintetasa específica para cada aminoácido. Este alto grado de especificidad es vital para la incorporación del aminoácido correcto a una proteína. Después de que la molécula de aminoácido se haya unido a su portador de ARNt, puede tener lugar la síntesis de proteínas. La figura\(\PageIndex{2}\) representa una representación escalonada esquemática de este proceso tan importante.
Los primeros experimentadores se enfrentaron a la tarea de determinar cuál de los 64 codones posibles representaba cada uno de los 20 aminoácidos. El agrietamiento del código genético fue el logro conjunto de varios genetistas conocidos, en particular Har Khorana, Marshall Nirenberg, Philip Leder y Severo Ocho, entre 1961 y 1964. El diccionario genético que compilaron, resumido en la Figura\(\PageIndex{3}\), muestra que 61 codones codifican para aminoácidos, y 3 codones sirven como señales para la terminación de la síntesis de polipéptidos (al igual que el periodo al final de una oración). Observe que solo la metionina (AUG) y el triptófano (UGG) tienen codones únicos. Todos los demás aminoácidos tienen dos o más codones.
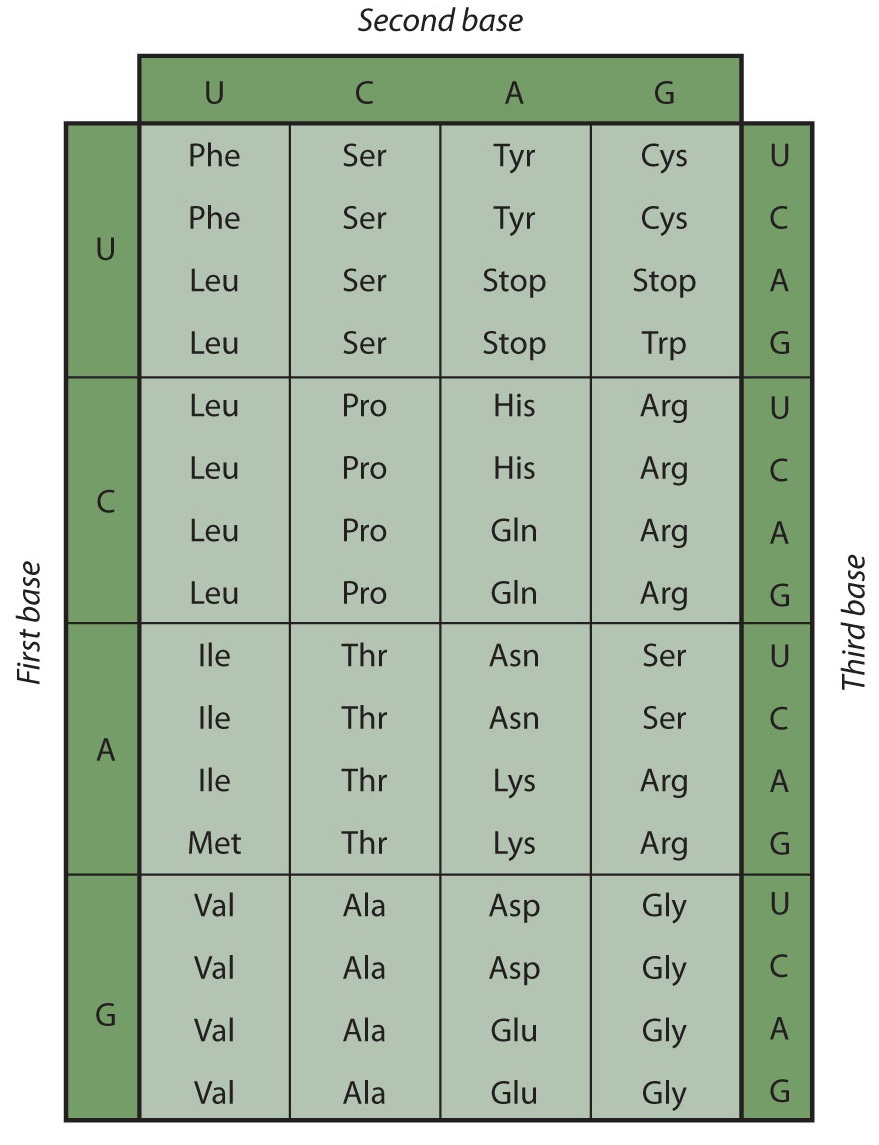
Una porción de una molécula de ARNm tiene la secuencia 5′‑AUGCCACGAGUUGAC‑3′. ¿Para qué secuencia de aminoácidos codifica esta?
Solución
Utilice la Figura\(\PageIndex{3}\) para determinar para qué aminoácido codifica cada conjunto de tres nucleótidos (codón). Recuerde que la secuencia se lee a partir del extremo 5' y que se sintetiza una proteína a partir del aminoácido N-terminal. La secuencia 5′‑AUGCCACGAGUUGAC‑3′ codifica para met-pro-arg-val-asp.
Una porción de una molécula de ARNm tiene la secuencia 5′‑AUGCUGAAUUGCGUAGGA-3′. ¿Para qué secuencia de aminoácidos codifica esta?
met-leu-asn-cys-val-gly
La experimentación posterior arrojó mucha luz sobre la naturaleza del código genético, de la siguiente manera:
- El código es prácticamente universal; las células animales, vegetales y bacterianas utilizan los mismos codones para especificar cada aminoácido (con algunas excepciones).
- El código es “degenerado”; en todos menos dos casos (metionina y triptófano), más de un triplete codifica para un aminoácido dado.
- Las dos primeras bases de cada codón son las más significativas; la tercera base suele variar. Esto sugiere que un cambio en la tercera base por una mutación aún puede permitir la incorporación correcta de un aminoácido dado a una proteína. A la tercera base se le llama a veces la base de “bamboleo”.
- El código es continuo y no se superpone; no hay nucleótidos entre codones, y los codones adyacentes no se superponen.
- Los tres codones de terminación son leídos por proteínas especiales llamadas factores de liberación, que señalan el final del proceso de traducción.
- El codón AUG codifica metionina y también es el codón de iniciación. Así, la metionina es el primer aminoácido en cada polipéptido recién sintetizado. Este primer aminoácido generalmente se elimina enzimáticamente antes de que se complete la cadena polipeptídica; la gran mayoría de los polipéptidos no comienzan con metionina.
Resumen
- En la transcripción, un segmento de ADN sirve como molde para la síntesis de una secuencia de ARN.
- La ARN polimerasa es la enzima primaria necesaria para la transcripción.
- En la traducción, la información en ARNm dirige el orden de los aminoácidos en la síntesis de proteínas. Un conjunto de tres nucleótidos (codón) codifica para un aminoácido específico.
Colaboradores y Atribuciones
- Libretexto: Las Baiscs de la Química GOB (Ball et al.)