
7.6: Una pregunta interesante- ¿Podemos incorporar la memoria en nuestro modelo?
- Page ID
- 54336

La respuesta a esta pregunta es - ¡Sí, podemos! Pero, ¿cómo? Recordemos que, los modelos de Markov no tienen memoria. Es decir, toda la memoria del modelo está encerrada en estados. Entonces, para almacenar información adicional, debemos incrementar el número de estados. Ahora, volvamos al ejemplo biológico que dimos en la Sección 7.4.2. En nuestro modelo, las emisiones estatales dependían únicamente del estado actual. Y, el estado actual codificaba sólo un nucleótido. Pero, ¿y si queremos que nuestro modelo cuente frecuencias de di-nucleótidos (para islas CpG 1), o, frecuencias de tri-nucleótidos (para codones), o frecuencias de di-codones que involucran seis nucleótidos? Tenemos que ampliar el número de estados.
Por ejemplo, el último nucleótido visto puede incorporarse a la “memoria” del HMM dividiendo los estados más y menos de nuestro HMM de alto GC/bajo GC en múltiples estados: uno por cada combinación nucleótido/región, como en la Figura 7.18.
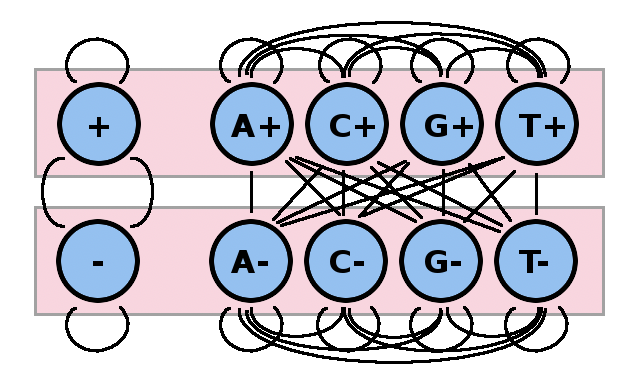
Pasar de dos a ocho estados permite conservar la memoria del último nucleótido observado, a la vez que se distingue entre dos regiones distintas. Cuatro nuevos estados corresponden ahora a cada uno de los dos estados originales en el HMM de GC alto/bajo. Mientras que los pesos de transición en el HMM más pequeño se basaron puramente en las frecuencias de los nucleótidos individuales, ahora en el más grande, se basan en frecuencias de di-nucleótidos.
Con esta potencia añadida, ciertas secuencias de di-nucleótidos, como las islas CpG, se pueden modelar específicamente: a la transición de C+ a G+ se le puede asignar mayor peso que la transición de A+ a G+. Además, las transiciones entre + y - se pueden modelar más específicamente para reflejar la frecuencia (o infrecuencia) de secuencias de di-nucleótidos particulares dentro de una u otra.
El proceso de agregar memoria a un HMM puede generalizarse y se puede agregar más memoria para permitir el reconocimiento de secuencias de mayor longitud. Por ejemplo, podemos detectar tripletes de codones con 32 estados, o sextipletes de di-codones con 2048 estados. La memoria dentro del HMM permite una especificidad cada vez más personalizada en el escaneo.
1 CpG significa C-fosfato-g. Entonces, isla CpG se refiere a una región donde el di-nucleótido GC aparece en la misma cadena.