33.5: Modelado y Pruebas de Causalidad
- Page ID
- 54806
Una cuestión central para la genómica personal es la cuestión de qué marcadores son causales de enfermedad. Por ejemplo, uno podría preguntarse si la metilación en ciertos loci, o una cierta modificación de histonas, aumenta el riesgo de una persona de una determinada enfermedad. Esta pregunta es difícil porque necesitamos separar las correlaciones espurias de los efectos causales -por ejemplo, es posible que una mutación en otra parte del genoma cause la enfermedad, y también aumente la probabilidad de observar un marcador en particular, pero que el marcador no tenga ningún efecto causal sobre la enfermedad. En este caso, encontraríamos una correlación entre el fenotipo de la enfermedad y la presencia del marcador a pesar de la falta de algún efecto causal.
La visión clave que nos permite determinar los efectos causales, a diferencia de las meras correlaciones, es la observación de que si bien el genotipo puede influir en el riesgo de una persona de una enfermedad en particular, la enfermedad no modificará el genotipo de una persona. Esto nos permite utilizar el genotipo como variable instrumental para la metilación. Esto limita el número de modelos posibles para que podamos probar estadísticamente qué modelo es más consistente con los datos observados.
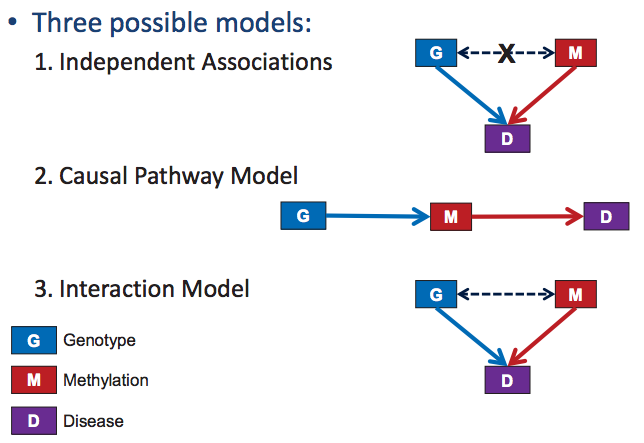
Existen tres posibilidades para modelar enfermedades humanas complejas: el modelo de asociaciones independientes, el modelo de interacción y el modelo de vía causal, representados en la Figura 33.4. Utilizaremos el ejemplo de estudiar la relación causal entre la metilación en ciertos loci y la enfermedad para demostrar cómo probar un efecto causal.
Licencia Commons. Para obtener más información, consulte http://ocw.mit.edu/help/faq-fair-use/.
Figura 33.4: Modelado de enfermedades humanas
Bajo el modelo de asociaciones independientes, los datos no deben contener correlación entre el genotipo y la enfermedad, lo que distingue a este modelo de los modelos de interacción y vía causal. Sin embargo, habrá correlaciones entre cada uno de los factores y la enfermedad por separado. Por lo tanto, este modelo es sencillo de probar. Un ejemplo de esto serían dos genes de riesgo independientes.
Bajo el modelo de interacción, el efecto del factor Bs sobre una enfermedad puede variar dependiendo del valor de A. Por ejemplo, un efecto de drogas en alguien puede ser diferente según su genotipo. Para probar esto, determinamos la significancia estadística del efecto del término de interacción,\(\beta_{2}\), en la regresión\(D=\beta_{0} A+\beta_{1} B+\beta_{2} A * B\). Si hay un efecto de interacción significativo, podemos aislar los efectos separados por estratificación a través de diferentes niveles de A.
El modelo de vía causal es un poco más complejo. Si observamos una correlación entre un factor de riesgo y una enfermedad, podemos preguntarnos si existe un vínculo directo entre el factor de riesgo A y una enfermedad, o si el factor de riesgo A afecta al factor de riesgo B que luego afecta a la enfermedad. En el caso de que el factor de riesgo A solo tenga un efecto sobre la enfermedad a través del B, observaremos que después de condicionar a B, la correlación entre A y D desaparece, es decir, B “media” esta interacción. En realidad, el efecto de A sobre una enfermedad suele estar mediado solo parcialmente a través de B, por lo que podemos buscar si el tamaño del efecto de A sobre la enfermedad disminuye cuando se observa B.
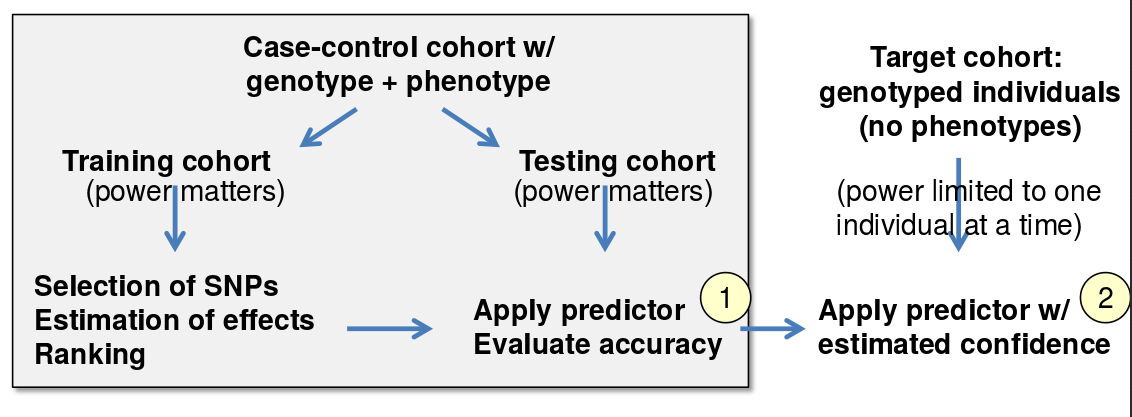
Predicción de riesgo poligénico
Una de las cuestiones más centrales de la genómica personal es la predicción de predisposiciones genéticas a diversos rasgos genéticos, utilizando múltiples genes para informar nuestras predicciones. El enfoque básico se explica en la Figura 33.5. Primero, el conjunto de datos se divide en un conjunto de entrenamiento y prueba, y en la cohorte de entrenamiento, seleccionamos qué SNP son más importantes y sus ponderaciones adecuadas. Luego usamos el conjunto de pruebas para evaluar la precisión de nuestras predicciones. Finalmente, utilizamos este modelo para predecir predisposiciones genéticas para la cohorte objetivo mediante el uso de las confidencias que determinamos a partir del conjunto de pruebas.