
1.10: Gestión de Bases de Datos
- Page ID
- 57755
Para muchos proyectos de monitoreo, la administración de datos a menudo se considera una molestia y de menor importancia que el diseño de muestreo, el establecimiento de objetivos y la recolección y análisis de datos. Sin embargo, un sistema adecuado de gestión de bases de datos es un componente crítico de cualquier plan de monitoreo y debe considerarse temprano en el proceso de planeación. En muchos sentidos, dicho sistema sirve como registro del buque de una misión de monitoreo y debe detallar cada paso de la recolección, almacenamiento y difusión de datos. La gestión de datos sólida es muy vital porque un proyecto de monitoreo se adapta y cambia con el tiempo y como tal, también lo podrían hacer los datos. Además, debido a que la mayoría de los proyectos de monitoreo se llevan a cabo a lo largo de muchos años e incluyen los inevitables cambios en el personal, la recolección de datos y metodologías, la propiedad y accesibilidad de la tierra y las tecnologías cambiantes, la gestión inadecuada de los datos puede no documentar estos cambios y iniciativa. Además, debido a que la difusión de datos en línea y los archivos digitales son cada vez más populares (si no es necesario), la gestión de datos sirve como un plan de instrucciones muy necesario para futuros usuarios de los datos que podrían no haber estado involucrados en ningún aspecto del plan de monitoreo original.
Los fundamentos de la gestión de bases de datos
Los datos generados a partir de los programas de monitoreo suelen ser complejos y los protocolos utilizados para generar estos datos pueden cambiar y adaptarse con el tiempo. En consecuencia, el sistema utilizado para describir estos datos, y los métodos utilizados para recogerlos, deben ser integrales, detallados y flexibles a los cambios. En un mundo perfecto, los datos de monitoreo se recopilan y a menudo se ingresan a una base de datos (en lugar de almacenarse en un archivador). Una base de datos integral debe incluir seis descriptores básicos de los datos que detallen cómo fueron recolectados, medidos, estimados y manejados. En última instancia, estos descriptores básicos aseguran el éxito a largo plazo de un esfuerzo de monitoreo porque describen los detalles de la recolección y almacenamiento de datos.
Los seis descriptores esenciales son: qué (el tipo de organismo), cuántos (unidades de observación para organismos o colonias individuales, presencia/ausencia, detección/no detección, abundancia relativa, mediciones de distancia), dónde (el ubicación geográfica en la que se registró el organismo y qué sistema de coordenadas se referenció), cuándo (la fecha y hora del evento de grabación), cómo (qué tipo de registro se representa y otros detalles de los protocolos de recolección de datos; por ejemplo, punto de 5 minutos conteos, redes de niebla, trampa de trébol, etc.), y quién (el responsable de recabar los datos). Cada uno de estos componentes representa un aspecto importante de la recolección de datos que facilita el uso futuro. Por ejemplo, la información sobre cómo se realizó un evento de grabación permite a alguien separado de la recolección de datos dar cuenta adecuadamente de la variación en el esfuerzo y la probabilidad de detección, tratar datos de múltiples protocolos y determinar si los datos son de múltiples especies o registros de taxón único.
La estructura general de una base de datos de monitoreo
Desafortunadamente, no existe una solución de “talla única” para la estructura básica de una base de datos de monitoreo. Los programas de monitoreo son diversos y también lo son los datos que recopilan. Existen, sin embargo, varias plantillas básicas y estandarizadas que se pueden utilizar al crear una base de datos de monitoreo (Huettmann 2005, ene 2006). Como ejemplo, el Darwin Core es un estándar de datos simple que se usa comúnmente para datos de ocurrencia (especímenes, observaciones, etc. de organismos vivos) (Bisby 2000). El estándar Darwin Core especifica varios componentes de base de datos, incluidos elementos a nivel de registro (por ejemplo, identificador de registro), elementos taxonómicos (por ejemplo, nombre científico), elementos de localidad (por ejemplo, nombre de lugar) y elementos biológicos (por ejemplo, etapa de vida). Jan (2006) proporcionó otro excelente ejemplo de una estructura funcional para una base de datos observacional. Utilizando la terminología de Jan (2006), la información de muestreo biológico se relaciona con las visitas a sitios de campo, y cada una de estas visitas se considera un Encuentro. Cada evento de recolección debe describirse por la ocurrencia y/o abundancia de una especie e información adicional del sitio, incluyendo el nombre del sitio, el período de tiempo, el nombre del recolector, el método de recolección y la geografía. El campo geográfico debe indicar usando los códigos de país utilizando los estándares de la Organización Internacional de Normalización (ISO) (www.iso.org), y debe tener un atributo que detalle si esta información es actualmente válida porque los límites políticos y los nombres cambian con el tiempo (por ejemplo, nuevos países forman, sus nombres pueden cambiar) (Ene 2006). Los datos geoespaciales se almacenan bajo el título de GatheringSite e incluyen datos de coordenadas (por ejemplo, latitud y longitud, altitud), datos de nomenclátor (por ejemplo, unidades políticas o administrativas) y clasificaciones geo-ecológicas (por ejemplo, tipos geomorfológicos). Es importante que este campo permita georeferenciación de alta resolución para su posterior integración con un SIG (por ejemplo, usando 5 dígitos significativos para coordenadas de latitud y longitud). El campo Unidad incluye organismos observados en el campo, especímenes de herbario, datos de campo, identificaciones taxonómicas o datos descriptivos. Un campo de Identificaciones detalla el nombre común de la especie, el nombre científico de la especie y un código de especie (utilizando el Sistema Integrado de Información Taxonómica [ITIS; www.itis.gov]) a una Unidad (espécimen, observación, etc.). Las identificaciones se pueden conectar a una base de datos de taxones usando un campo TaxidRF. La organización de cualquier base de datos de monitoreo debe tener estos campos de información necesarios (aunque los nombres de los campos pueden variar) y probablemente requerirá el uso de una base de datos digital para su almacenamiento y manipulación.
Bases de Datos Digitales
Las bases de datos digitales ahora se consideran una herramienta invaluable y de uso común para almacenar datos generados a partir de programas de monitoreo. Incluso en sitios remotos de campo, los investigadores están utilizando unidades móviles GPS (Sistema de Posicionamiento Global) y PDA (Asistente Digital Personal) para registrar huellas censales georreferenciadas y observaciones de especies (Travaini et al. 2007) (Fig. 10.1). Usando cualquier computadora portátil, estos datos pueden integrarse rápidamente en software de administración de bases de datos como CyberTracker (cybertracker.org), Microsoft Excel (office.microsoft.com/en-us/excel) o Microsoft Access (office.microsoft.com/en-us/access). Al utilizar una base de datos digital, los investigadores obtienen la capacidad de georreferenciar puntos censales para su posterior integración en un SIG, como ArcGIS (esri.com/software/arcgis/), lo que permite opciones analíticas adicionales como el modelado predictivo de distribución de especies (Fig. 10.1). Travaini et al. (2007) proporcionaron una excelente revisión y aplicación de un marco de base de datos basado en el campo para el uso de datos almacenados digitalmente para posteriormente mapear distribuciones de animales en regiones remotas. Una ventaja clave para registrar datos en una base de datos digital durante el evento de recolección en sí es la capacidad de desarrollar y mantener múltiples bases de datos. Las bases de datos digitales también aumentan la capacidad de integrar datos en programas de gestión de datos en línea y así acceder a los datos en fechas posteriores.
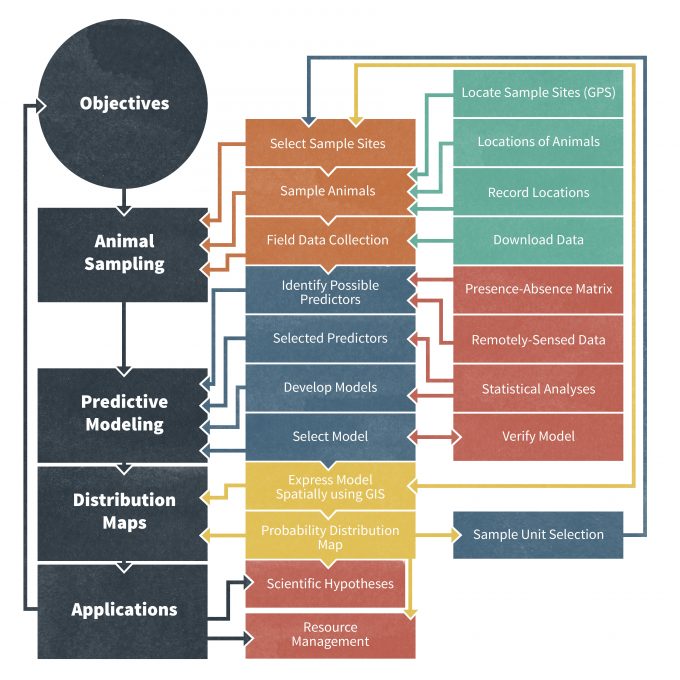
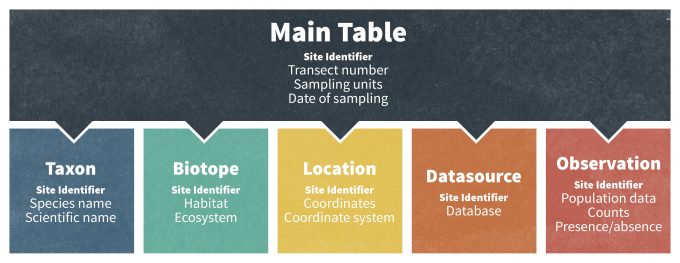
Además de esto, los administradores de bases de datos suelen utilizar bases de datos en línea y digitales porque pueden vincularse fácilmente a otras bases de datos para una mayor funcionalidad. La conexión de múltiples bases de datos da como resultado un sistema de gestión de bases de datos relacionales (RDMS) (Fig. 10.2), que permite realizar consultas entre múltiples bases de datos. A la luz de estos desarrollos, la estructura y el marco de muchas grandes bases de datos de monitoreo son cada vez más sofisticados y los datos sobre tasas demográficas, abundancia y ocurrencias de especies pueden vincularse con otra información geográfica almacenada en bases de datos auxiliares. Por ejemplo, una base de datos relacional estándar puede consistir en subtablas de datos que están conectadas a través de un número de identificación de registro común (Fig. 10.2). Una tabla principal normalmente contiene información sobre las unidades de muestreo, las unidades utilizadas para la presentación de datos, los años del estudio y notas sobre el diseño del muestreo. Otras tablas de uso frecuente incluyen una tabla de taxones (información sobre el organismo muestreado en cada conjunto de datos; ver ITIS (ver www.itis.org para los nombres de especies aceptados globalmente), una tabla de biotopos (hábitat del organismo), una tabla de ubicación (detalles geográficos de el sitio de monitoreo), una tabla Fuente de datos (referencia a la fuente original de los datos) y la tabla Datos reales (datos de población originales). En este caso, una base de datos relacional y un identificador común de registro permiten al usuario realizar múltiples consultas basadas en especies, grupos taxonómicos, hábitats, áreas, latitudes o países. Esto es particularmente poderoso porque un usuario puede consultar un identificador único que se refiere a un sitio de estudio específico y luego extraer datos en ese sitio de múltiples tablas de datos. En la práctica, desarrollar, mantener y recuperar datos de un RMDS a menudo requiere el conocimiento de SQL (Structured Query Language; http://en.Wikipedia.org/wiki/SQL), un lenguaje de filtro de bases de datos ampliamente utilizado que está diseñado específicamente para la gestión, consulta y uso de RMDS. SQL es un lenguaje estandarizado con una enorme comunidad de usuarios que es reconocida tanto por el American National Standards Institute (ANSI) como por la Organización Internacional de Normalización (ISO; [iso.org/iso/home.htm]). Se implementa en muchos sistemas populares de gestión de bases de datos relacionales incluyendo Informix (ibm.com/software/data/informix), Oracle (oracle.com/index.html), SQL Server (microsoft.com/sql/default.mspx (enlace inactivo a partir del 18/05/2021)), MySQL (mysql.com) y PostresQL (postgresql.org).

Formularios de datos
Todos los recopiladores de datos deben utilizar un formulario de datos estándar que sea aprobado por las partes interesadas en el programa de monitoreo (Cuadro 10.1). Se deben incluir copias de estos formularios de datos como apéndice del documento de planeación. El apéndice también debe proporcionar una hoja de formato de datos que identifique el tipo de datos, la unidad de medida y el rango válido de valores para cada campo del formulario de recolección de datos. En la hoja de formato de datos también se deben identificar todos los códigos y abreviaturas que puedan utilizarse en el formulario.
Hora Comienzo__________________Hora Fin _________
| Fecha __________ | Punto de muestra________ | Paisaje__________________ | Observador __________ | |||
| Tiempo ____________________ | ||||||
| Obs. Núm. | Especies | Número | Distancia (m) | Repetir (Y/N) | Comportamiento | Tipo de parche |
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| 9 | ||||||
| 10 | ||||||
| 11 | ||||||
| 12 | ||||||
| 13 | ||||||
| 14 | ||||||
| 15 | ||||||
| 16 | ||||||
| 17 | ||||||
| Especie = usar código de 4 letras Número = número de individuos Repetir = ingresar “Y” solo para observaciones repetidas del mismo ave Comportamiento = F (eeding), R (esting), O (paso elevado), Tipo de parche = P (lesionado), G (rass), W ( Vía navegable con pasto), S (hrubby), T (caña) |
||||||
Almacenamiento de datos
Para muchos programas de monitoreo, aún se recopilan datos impresos a pesar de la creciente disponibilidad de formatos digitales. En general, existen tres obstáculos principales para el cambio de las copias impresas a los formatos digitales. Primero, quedan por digitalizar cantidades significativas de datos (históricos) impresos (por ejemplo, en archivos, bibliotecas y archivadores). En segundo lugar, aunque los avances tecnológicos están haciendo más factible la recolección de datos digitales en el campo (Travaini et al. 2007), muchos datos de campo aún se recopilan en cuadernos de campo cuando las condiciones de campo son difíciles y el sitio de campo es remoto. En tercer lugar, muchos conjuntos de datos digitales todavía se están imprimiendo en papel por razones culturales y logísticas.
En muchos casos, incluso cuando los datos se compilan digitalmente, se recopilan copias impresas como un respaldo importante para muchos programas de monitoreo, o dichos datos se conservan y mantienen como fuentes críticas de información para programas heredados que han estado funcionando durante décadas. Sin embargo, a pesar de esto, y aunque sin duda existen otros ejemplos de obstáculos asociados con la transición a la documentación digital, existen muchas razones por las que los datos de monitoreo deben ser recolectados y almacenados en formato digital (con los sistemas de respaldo necesarios). Las ventajas de usar métodos de recopilación de datos digitales de campo incluyen disponibilidad inmediata de datos (por ejemplo, entrada de datos en línea en tiempo real), falta de sesiones de claves de datos intensas en mano de obra después y metadatos y procesamiento automatizados. Dados estos beneficios, sería ideal un uso más universal de la recolección de datos digitales, pero muchas universidades, gobiernos, ONG y agencias dudan en adoptar las tecnologías actuales. Las razones de la renuencia a volverse completamente digital son variadas, pero generalmente incluyen la falta de capacitación computacional y una infraestructura insuficiente para usar y almacenar datos digitales.
Metadatos
Las bases de datos resultantes de inventarios biológicos y estudios de monitoreo pueden beneficiar otros esfuerzos de investigación científica y facilitar programas de conservación de especies durante muchas décadas. Sin embargo, la utilidad de una base de datos para estos fines está determinada no sólo por el rigor de los métodos utilizados para llevar a cabo el programa de monitoreo, sino también por la capacidad de futuros investigadores para descifrar los códigos variables, unidades de medida y otros detalles que afectan su comprensión de la base de datos. Cuando un usuario potencial de una base de datos está interesado en descifrar los detalles de esa base de datos, a menudo se refieren a los metadatos. Los metadatos son “datos sobre datos” y son un aspecto esencial de cualquier base de datos porque sirven como una guía proporcionada por el desarrollador de la base de datos. Los metadatos facilitan el intercambio de información entre los usuarios actuales y son cruciales para mantener el valor de los datos para futuras investigaciones. De hecho, si los datos de monitoreo se colocan en línea o se pretende que se compartan entre las partes interesadas participativas, entonces es necesario que haya una descripción clara que documente cada paso relevante de la curación y procesamiento de datos. Hay pocas cosas más frustrantes para los posibles usuarios de datos que recibir una base de datos o mapa con poca o ninguna información sobre lo que representan las variables o cómo se recolectaron los datos. Los metadatos estandarizados que acompañan a las bases de datos de monitoreo deben ser altamente valorados como uno de los principales medios para mejorar la transferibilidad de la información de monitoreo biológico entre diferentes programas, unidades de manejo y futuros usuarios de datos.
Con respecto a los metadatos, el gobierno federal ha desarrollado varios sistemas, estándares y plantillas para la documentación de bases de datos que se pueden aplicar a cualquier base de datos de monitoreo. Desde 1995, todas las agencias federales han adoptado un estándar de contenido para datos geoespaciales llamado Content Standard for Digital Geospatial Metadata (CSDGM; Tsou 2002)). Este estándar fue desarrollado por el Comité Federal de Datos Geográficos (FGDC), que también se encarga de revisar y actualizar el estándar según sea necesario. El estándar FGDC actualmente aprobado es CSDGM Versión 2 — FGDC-STD-001-1998 y fue desarrollado para ser aplicable a todas las bases de datos geoespaciales. El estándar incluye siete elementos principales. Ciertos paquetes SIG incluyen herramientas de software que automatizan una serie de estas tareas de documentación de metadatos, sin embargo, el creador de la base de datos debe completar manualmente la mayoría de los campos. El proceso de descripción de fuentes de datos, pruebas de precisión, métodos de geoprocesamiento e información organizacional puede ser tedioso y agregar muchas horas a la preparación de un conjunto de datos. Este costo inicial de la mano de obra y tiempo, sin embargo, asegurará que los datos puedan ser utilizados durante muchos años en el futuro, posiblemente con fines de investigación o conservación no anticipados por el originador del conjunto de datos.
Aunque profecía, la naturaleza genérica del CSDGM, no prevé la estandarización de muchos atributos comúnmente compartidos entre las bases de datos biológicas. Para extender la efectividad del marco CSDGM al muestreo biológico, el Grupo de Trabajo de Datos Biológicos del FGDC ha estandarizado el uso de términos y definiciones en metadatos elaborados para bases de datos biológicas con el desarrollo del Perfil de Metadatos Biológicos (FGDC 1999). El Perfil de Metadatos Biológicos se encuentra dentro del perfil más amplio de la Estructura Nacional de Información Biológica (NBII) (>www.nbii.gov) y se aplica a temas como clasificación taxonómica, especímenes de vales, atributos ambientales y otros no considerados en el CSDGM. El Perfil de Metadatos Biológicos también es aplicable a conjuntos de datos no geoespaciales. Considerando que la mayoría de los programas de monitoreo recopilan información biológica, los administradores de bases de datos deben consultar el Perfil de Metadatos Biológicos antes y después
El estándar FGDC y sus perfiles son ampliamente adoptados por el Gobierno Federal de Estados Unidos e iniciativas internacionales (por ejemplo, el Año Polar Internacional (IPY)). Sin embargo, existen varios otros estándares de metadatos, entre ellos: a) Directory Interchange Format (DIF) para una breve descripción de entrada telefónica, que todavía es ampliamente utilizado por BAS (British Antarctica Service), b) EML (Ecological Metadata Language) para una descripción bastante detallada de bases de datos relacionales, que es utilizado por sitios de Investigación Ecológica a Largo Plazo en los Estados Unidos, y c) SML (Lenguaje de Metadatos de Sensores) para una descripción muy potente y progresiva de redes de sensores de alto rendimiento. También hay una amplia gama de estándares de metadatos que solo tienen relevancia local y no son compatibles con los estándares globales de metadatos. Existe un movimiento actual, sin embargo, hacia el desarrollo e implementación de una estandarización más global. La variación entre los estudios en los estándares de metadatos impide la disponibilidad global de datos, y desviarse del estándar FGDC NBII a menudo resulta en una gran pérdida de información. La idea de que conceptos de metadatos más locales y simples pueden simplemente mapearse, y luego cruzarse a través del software de análisis automático a otros estándares como FGDC NBII para satisfacer las necesidades de entrega, puede resultar fatal para la calidad de los datos porque una vez que falta un campo de información, su contenido probablemente nunca pueda nuevamente llenarse de una manera que mantenga el rigor de la base de datos en su conjunto.
Más de 50 años colectivos de experiencia en bases de datos en monitoreo de poblaciones han llevado a una conclusión importante: la falta de metadatos hace que las bases de datos sean completamente inutilizables. Por lo tanto, la gestión de metadatos y datos debe ocupar una parte importante del presupuesto del proyecto y debe considerarse temprano en el proceso de planeación.
Considere un administrador de bases de datos
Como se puede decir de las secciones anteriores, la administración de bases de datos no es una tarea sencilla. Requiere una comprensión de estándares de metadatos complicados y, en el caso de muchas bases de datos digitales, un conjunto de habilidades pertenecientes a la programación informática (por ejemplo, lenguaje SQL). Desafortunadamente, quizás por la considerable capacitación y esfuerzo que son necesarios, la gestión de bases de datos no recibe suficiente atención en términos de tiempo y asignaciones presupuestales en muchos esfuerzos de monitoreo. Las tareas asociadas con la administración de bases de datos a menudo se dan a miembros de menor rango del equipo de investigación, y se consideran “trabajo técnico”; no parte de la ciencia o monitoreo “real”. En otros entornos, las bases de datos simplemente se contratan a otras, y se espera que cualquier problema pueda solucionarse de esa manera. Debido a estas prácticas, muchas bases de datos de monitoreo existen en formatos sin procesar o torpes, se publican como archivos PDF sin salida o se almacenan en hojas de trabajo antiguas de tipo Excel. El peor de los casos implica el envío de años de datos impresos a un archivador, luego a una caja y, finalmente, al centro de reciclaje local (a menudo cuando el administrador de datos original se jubila). Esta situación es particularmente desalentadora considerando que la gestión de datos tiene implicaciones críticas en el proceso de monitoreo y difusión de datos y que el almacenamiento y documentación adecuados de años de monitoreo de datos es de suma relevancia para el uso futuro de los datos de monitoreo. Para superar esta situación, los programas de monitoreo necesitan hacer el compromiso presupuestario necesario para asegurar que cuenten con la pericia requerida para una excelente gestión de datos. Esto normalmente implica contratar gerentes de bases de datos con experiencia.
Un ejemplo de un sistema de gestión de bases de datos: FAUNA
Como ejemplo de un sistema de gestión reciente de bases de datos, el Servicio Forestal de Estados Unidos requiere que todos los datos de monitoreo se almacenen en la base de datos FAUNA del Sistema de Información de Recursos Naturales (NRIS) del Servicio Forestal (ver Woodbridge y Hargis 2006 para un ejemplo). Todos los planes de monitoreo del Servicio Forestal describen varios pasos en la preparación de datos para ingresar a la base de datos FAUNA que están destinados a ser abordados durante el desarrollo de un inventario o protocolo de monitoreo. Si bien estos pasos básicos están diseñados para los protocolos del Servicio Forestal, pueden incorporarse a cualquier iniciativa de monitoreo:
- Todos los datos recopilados en campo deben ser revisados para verificar su integridad y errores antes de ingresar a FAUNA. Deben discutirse las preocupaciones y técnicas específicas del protocolo que se está desarrollando.
- Los equipos de desarrollo de protocolos deben familiarizarse con los principales elementos del FGDC-CSDGM, Biological Metadata Profile (FGDC 1999) para comprender mejor los estándares de metadatos.
- Se deben proporcionar descripciones completas y citas bibliográficas para sistemas de clasificación taxonómica, poblacional o ecológica, incluyendo la identificación de palabras clave consistentes con el Perfil de Metadatos Biológicos cuando corresponda.
- Deben identificarse fuentes de mapas, datos geoespaciales e información poblacional que se utilicen para delinear los límites geográficos del programa de monitoreo o para ubicar unidades de muestreo.
- Deben identificarse las unidades de medida.
- Se debe identificar a los autores del protocolo y al personal encargado de mantener y distribuir los datos resultantes de los programas de monitoreo (es decir, administrador de datos).
- Se debe describir el cronograma previsto para las revisiones y actualizaciones de datos.
- Deben definirse todos los códigos de datos, nombres de variables, acrónimos y abreviaturas utilizados en el protocolo.
- Se deberá proporcionar un esquema o plantilla de la estructura de bases de datos tabulares en las que se llevarán a cabo los datos del programa de monitoreo.
Resumen
La administración de bases de datos es a menudo una idea de último momento para muchos programas de monitoreo, pero la administración adecuada de la base de datos y la documentación son fundamentales para el éxito a largo plazo Una administración efectiva de la base de datos detalla seis componentes esenciales de la recopilación de datos, incluyendo qué, cuántos, dónde, cuándo, cómo y quién recopiló los datos. Si es posible, los datos deben incorporarse rápidamente a una base de datos digital, ya sea durante la recolección de datos o poco después. Los formatos digitales permiten la construcción de sistemas de gestión de bases de datos relacionales, a menudo documentación automatizada de metadatos y compatibilidad con estándares de metadatos actuales y globales. Dada la creciente sofisticación de los sistemas de gestión de bases de datos, los programas de monitoreo deben poner un mayor énfasis en la consultoría o contratación de un administrador de bases de datos con el conjunto de habilidades necesarias para mantener y consultar grandes bases de datos. La falta de desarrollo de un sistema sólido de gestión de bases de datos al principio del programa de monitoreo puede conducir a la pérdida de información y a la incapacidad de analizar e implementar adecuadamente los resultados de una iniciativa de monitoreo en el futuro.
Referencias
Bisby, F.A., 2000. La revolución silenciosa: la informática de la biodiversidad y la internet. Ciencia 289:2309—2312.
FGDC 1998 Estándar de contenido para metadatos geoespaciales digitales, versión 2.0. FGDC-STD-001-1998. Comité Federal de Datos Geográficos, Washington, DC [http://www.fgdc.gov].
Huettmann, F. 2005. Bases de datos y manejo basado en la ciencia en el contexto de la vida silvestre y el hábitat: Hacia una norma ISO certificada para la toma de decisiones objetivas para la comunidad global mediante el uso de internet. Revista de Manejo de Vida Silvestre 69:466-472.
Ene, L. 2006. Modelo de base de datos para datos taxonómicos y de observación. en Actas de la 2da conferencia internacional IASTED sobre Avances en informática y tecnología. ACTA Press, Puerto Vallarta, Méx.
Travaini, A., Bustamante, J., Rodríguez, A., Zapata, S., Procopio, D., Pedrana, J. & Martínez-Peck, R. 2007. Un marco integrado para mapear distribuciones de animales en regiones grandes y remotas. Diversidad y Distribuciones, 13.
Tsou, M.H. 2002. Un marco operativo de metadatos para la búsqueda, indexación y recuperación de servicios de información geográfica distribuida en Internet. Páginas 312—333 En M. Egenhofer y D. Mark, editores. Ciencia de la Información Geográfica-Segundo Congreso Internacional GIScience 2002, Notas de la Conferencia en Ciencias de la Computación 2478, Springer, Berlín.
Woodbridge, B. y C.D. Hargis. 2006. Guía técnica de inventario y monitoreo de azor norteño. USDA Servicio Forestal Informe Técnico General WO-71. 80 p.