
1.11: Análisis de Datos en Monitoreo
- Page ID
- 57797
Los datos de plantas y animales vienen en muchas formas, incluidos índices, recuentos y ocurrencias. La diversidad de estos tipos de datos puede presentar desafíos especiales durante el análisis porque pueden seguir diferentes distribuciones y pueden ser más o menos apropiados para diferentes enfoques estadísticos. Como complicación adicional, los datos de monitoreo a menudo se toman de sitios que están muy cerca o las encuestas se repiten en el tiempo, por lo que se debe tener especial cuidado con respecto a los supuestos de independencia. En este capítulo discutiremos algunas características esenciales de estos tipos de datos, visualización de datos, diferentes enfoques de modelado y paradigmas de inferencia.
Este capítulo está diseñado para ayudarle a obtener conocimientos bioestadísticos y construir un marco efectivo para el análisis de datos de monitoreo. Estos temas son bastante complejos, y como tal, solo se discuten los elementos clave y conceptos del análisis efectivo de datos. Se han escrito muchos libros sobre el tema del análisis de datos ecológicos. Por lo tanto, sería imposible cubrir de manera efectiva la gama completa de los temas relacionados en un solo capítulo. El propósito, por lo tanto, del segmento de análisis de datos de este libro es servir de introducción a algunas de las técnicas clásicas y contemporáneas para analizar los datos recopilados por los programas de monitoreo. Después de leer este capítulo, si deseas ampliar tu comprensión del análisis de datos y aprender a aplicarlo con confianza en la investigación y monitoreo ecológicos, te recomendamos los siguientes textos que cubren muchos de los enfoques clásicos: Cochran (1977), Underwood (1997), Thompson et al. (1998), Zar (1999), Crawley (2005, 2007), Scheiner y Gurevitch (2001), Quinn y Keough (2002), Gotelli y Ellison (2004), y Bolker (2008). Para una cobertura más profunda y analítica de algunos de los enfoques contemporáneos recomendamos Williams et al. (2002), MacKenzie et al. (2006), Royle y Dorazio (2008) y Thomson et al. (2009).
El campo del análisis de datos en ecología es una empresa de rápido crecimiento, al igual que la gestión de datos (Capítulo 10), y es difícil mantenerse al tanto de sus múltiples desarrollos. En consecuencia, uno de los primeros pasos para desarrollar un enfoque estadísticamente sólido para el análisis de datos es consultar con un biométrico en las primeras fases de desarrollo de su plan de monitoreo. Una de las lamentos más comunes (y más antiguas) de muchos estadísticos es que las personas con preguntas de análisis de datos buscan asesoramiento después de que se hayan recopilado los datos. Esto ha sido comparado con un examen post mortem (R.A. Fisher); solo hay tanto que un biométrico puede hacer y/o sugerir después de que se hayan recolectado los datos. Consultar a un biometrista es imperativo en casi todas las fases del programa de monitoreo, pero una sólida comprensión de los enfoques analíticos desde el principio ayudará a garantizar un esquema más completo y riguroso para la recolección y análisis de datos
Visualización de Datos I: Conociendo Sus Datos
La fase inicial de cada análisis de datos debe incluir la evaluación exploratoria de datos (Tukey 1977). Una vez que se recopilan los datos, pueden exhibir una serie de distribuciones diferentes. Trazar sus datos e informar varias estadísticas resumidas (por ejemplo, media, mediana, cuantiles, error estándar, mínimos y máximos) le permite identificar la forma general de los datos y posiblemente identificar entradas erróneas o errores de muestreo. Anscombe (1973) aboga por hacer del examen de datos un proceso iterativo mediante la utilización de varios tipos de pantallas gráficas y estadísticas de resumen para revelar características únicas antes del análisis de datos. Las pantallas más utilizadas incluyen gráficas de probabilidad normal, gráficas de densidad (histogramas, diagramas dit), gráficas de caja, gráficas de dispersión, gráficos de barras, gráficos de puntos y líneas, y gráficas de puntos de Cleveland (Cleveland 1985, Elzinga et al. 1998, Gotelli y Ellison 2004, Zuur et al. 2007). Las pantallas gráficas efectivas muestran la esencia de los datos recopilados y deben (Tufte 2001):
- Mostrar los datos,
- Inducir al espectador a pensar en la sustancia de los datos más que en la metodología, el diseño gráfico o la tecnología de producción gráfica,
- Evitar distorsionar lo que tienen que decir los datos,
- Presentar muchos números en un espacio pequeño,
- Hacer que los grandes conjuntos de datos sean coherentes y visualmente informativos,
- Animar al ojo a comparar diferentes piezas de datos y posiblemente diferentes estratos,
- Revelar los datos en varios niveles de detalle, desde una visión general amplia hasta la estructura fina,
- Servir a un propósito razonablemente claro: descripción, exploración o tabulación,
- Estar estrechamente integrado con las descripciones numéricas (es decir, estadísticas resumidas) de un conjunto de datos.
En algunos casos, explorar diferentes pantallas gráficas y comparar los patrones visuales de los datos guiará realmente la selección del modelo estadístico (Anscombe 1973, Hilborn y Mangel 1997, Bolker 2008). Por ejemplo, refiérase a las cuatro gráficas de la Figura 11.1. Todos muestran relaciones que producen resultados idénticos si se analizan mediante un análisis de regresión de mínimos cuadrados ordinarios (OLS) (Cuadro 11.1). Sin embargo, mientras que un modelo de regresión simple puede describir razonablemente bien la tendencia en el caso A, su uso en los tres casos restantes no es apropiado, al menos no sin un adecuado examen y transformación de los datos. El caso B podría describirse mejor usando un modelo logarítmico en lugar de un modelo lineal y la relación en el caso D es espuria, resultante de conectar un solo punto con el resto del clúster de datos. Los casos C y D también revelan la presencia de valores atípicos (es decir, valores extremos que pueden haberse omitido sin un examen cuidadoso de los datos). En estos casos, el investigador deberá investigar estos valores atípicos para ver si sus valores eran muestras verdaderas o un error en la recolección y/o entrada de datos. Este sencillo ejemplo ilustra el valor de un escrutinio visual de datos previo al análisis de datos.
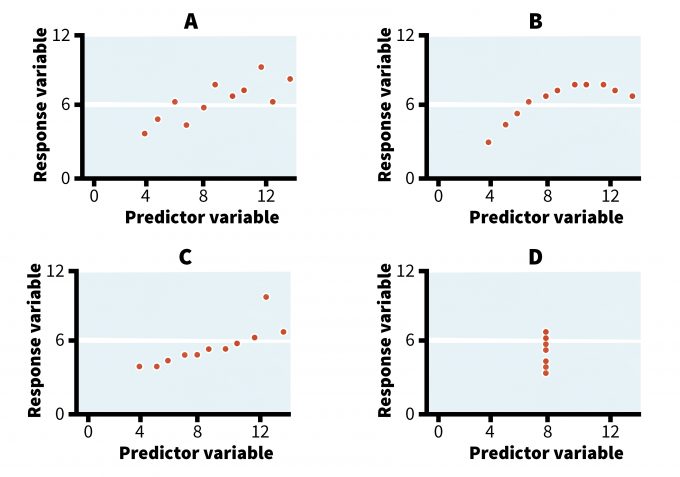
| A | B | C | D | Salida de análisis | ||||||||
| X | Y | X | Y | X | Y | X | Y | N = 11
Media de Xs = 9.0 Media de Ys = 7.5 Línea de regresión: Y = 3 + 0.5X Regresión SS = 27.50 r = 0.82 R 2 = 0.67 |
||||
| 10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 | |||||
| 8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 | |||||
| 13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 | |||||
| 9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 | |||||
| 11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 | |||||
| 14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 | |||||
| 6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 | |||||
| 4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 | |||||
| 12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 | |||||
| 7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 | |||||
| 5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 | |||||
El hecho de que, en algunas circunstancias, las pantallas visuales por sí solas puedan proporcionar una evaluación adecuada de los datos subraya el valor del análisis visual en una medida aún mayor. Un enfoque estrictamente visual (o gráfico) puede incluso ser superior al análisis formal de datos en situaciones con grandes cantidades de datos (por ejemplo, mediciones detalladas de demografía o cobertura vegetal) o si los conjuntos de datos son escasos (por ejemplo, en el caso de muestreo inadecuado o investigaciones piloto). Por ejemplo, los mapas pueden ser utilizados de manera efectiva para presentar un gran volumen de información. Tufte (2001) sostiene que los mapas son en realidad el único medio para mostrar grandes cantidades de datos en una cantidad relativamente pequeña de espacio y aún así permitir una interpretación significativa de la información. Además, los mapas permiten un análisis visual de datos a diferentes niveles de resolución temporal y espacial y una evaluación de las relaciones espaciales entre variables que pueden ayudar a identificar posibles causas del patrón detectado.
Otras técnicas de visualización de datos también proporcionan información práctica. Una simple evaluación de la riqueza de especies de una comunidad se puede lograr presentando el número total de especies detectadas durante la encuesta. Esto se hace más informativo al trazar el número acumulado de especies detectadas frente a un indicador del esfuerzo de muestreo como el tiempo dedicado al muestreo o el número de muestras tomadas (es decir, curva de detección o funciones de distribución acumulativa empírica). Estas curvas de esfuerzo de muestreo pueden darnos una evaluación rápida y preliminar de qué tan bien se ha muestreado la riqueza de especies de la comunidad investigada. Una pendiente pronunciada de la curva resultante sugeriría la presencia de especies adicionales desconocidas, mientras que un aplanamiento de la curva indicaría que la mayoría de las especies han sido contabilizadas (Magurran 1988, Southwood 1992). Al principio del muestreo, se recomiendan estos tipos de curvas de muestreo porque pueden proporcionar algunas estimaciones aproximadas de la cantidad mínima de esfuerzo de muestreo necesario.
La construcción de modelos de abundancia de especies como distribución normal logarítmica, series de troncos, palo roto de McArthur o modelo de serie geométrica puede proporcionar un perfil visual de áreas de investigación particulares (Southwood 1992). De hecho, los diferentes modelos de abundancia de especies describen comunidades con características distintas. Por ejemplo, los sistemas maduros no perturbados caracterizados por una mayor riqueza de especies suelen mostrar una relación logarítmica normal entre el número de especies y sus respectivas abundancias. Por otro lado, los sitios sucesionales tempranos o comunidades ambientalmente estresadas (por ejemplo, contaminación) se caracterizan por modelos geométricos o de distribución de especies de series logarítmicas (Southwood 1992).
El uso de intervalos de confianza presenta otro enfoque atractivo para el análisis exploratorio de datos. Algunos incluso argumentan que los intervalos de confianza representan una alternativa más significativa y poderosa a las pruebas de hipótesis estadísticas ya que dan una estimación de la magnitud de un efecto bajo investigación (Steidl et al. 1997, Johnson 1999, Stephens et al. 2006). En otras palabras, determinar los intervalos de confianza es generalmente mucho más informativo que simplemente determinar el valor P (Stephens et al. 2006). Los intervalos de confianza son ampliamente aplicables y pueden colocarse sobre estimaciones de densidad poblacional, efectos observados del cambio poblacional en muestras tomadas a lo largo del tiempo o efectos del tratamiento en experimentos de perturbación. También se utilizan comúnmente en cálculos del tamaño del efecto en potencia o metaanálisis (Hedges y Olkin 1985, Gurevitch et al. 2000, Stephens et al. 2006).
A pesar de su popularidad histórica y su atractiva simplicidad, sin embargo, el análisis visual de los datos conlleva algunas advertencias y posibles trampas para las pruebas de hipótesis. Por ejemplo, Hilborn y Mangel (1997) recomendaron trazar los datos de diferentes maneras para descubrir “relaciones plausibles”. A primera vista, esta parece ser una recomendación razonable e inocua, pero hay que tener cuidado de dejar que los datos descubran relaciones plausibles. Es decir, es totalmente posible crear múltiples gráficas entre una variable dependiente (Y) y múltiples variables explicativas (X 1, X 2, X 3,..., X N) y descubrir un efecto o patrón inesperado que sea un artefacto de ese único conjunto de datos, no de los más importante proceso biológico que generó los datos de la muestra (es decir, efectos espurios) (Anderson et al. 2001). Este tipo de efectos espurios son más probables cuando se trata de tamaños de muestra pequeños o limitados y muchas variables explicativas. Las relaciones e hipótesis plausibles deben desarrollarse a priori con aportes significativos del sistema conceptual de un programa de monitoreo, aportes de actores y objetivos bien desarrollados.
Visualización de datos II: Conociendo su modelo
La mayoría de los modelos estadísticos se basan en un conjunto de supuestos que son necesarios para que los modelos se ajusten y describan adecuadamente los datos. Si se violan los supuestos, los análisis estadísticos pueden producir resultados erróneos (Sokal y Rohlf 1994, Krebs 1999). Tradicionalmente, los investigadores están más preocupados por los supuestos asociados a las pruebas paramétricas (por ejemplo, ANOVA y análisis de regresión) ya que estos son los análisis más utilizados. La siguiente descripción puede ser utilizada como marco básico para evaluar si los datos se ajustan o no a supuestos paramétricos.
Independencia de los puntos de datos
La condición esencial de la mayoría de las pruebas estadísticas es la independencia y selección aleatoria de puntos de datos en el espacio y el tiempo. En muchos entornos ecológicos, sin embargo, los puntos de datos pueden ser recuentos de individuos o réplicas de unidades de tratamiento en estudios manipulativos y se debe pensar en la dependencia espacial y temporal entre las unidades de muestreo. Los datos dependientes son más parecidos de lo que se esperaría solo por selección aleatoria. Intuitivamente, si dos observaciones no son independientes entonces hay menos contenido de información entre ellas. Krebs (1999) argumentó que si se viola el supuesto de independencia, no se puede lograr la probabilidad elegida para el error Tipo I (a). Las técnicas de ANOVA y regresión lineal son generalmente sensibles a esta violación (Sokal y Rohlf 1994, Krebs 1999). Las gráficas de autocorrelación se pueden utilizar para visualizar la correlación de puntos a través del espacio (por ejemplo, correlogramas espaciales) (Fortin y Dale 2005) o como una serie temporal (Crawley 2007). Las parcelas deben ser desarrolladas utilizando los puntos de respuesta reales así como los residuales del modelo para buscar patrones de autocorrelación.
Homogeneidad de varianzas
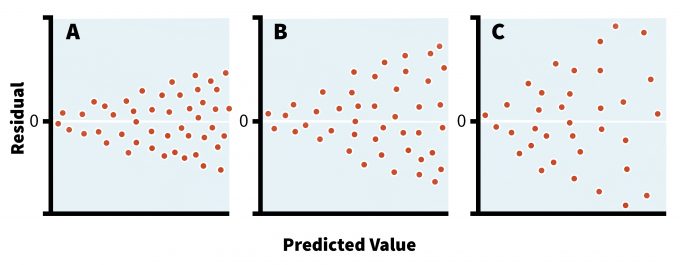
Los modelos paramétricos suponen que las poblaciones muestreadas tienen varianzas similares aunque sus medias sean diferentes. Esta suposición se vuelve crítica en estudios que comparan diferentes grupos de organismos, tratamientos o intervalos de muestreo y es responsabilidad del investigador aclarar abundantemente estas consideraciones en los protocolos de dichos estudios. Si los tamaños de muestra son iguales entonces las pruebas paramétricas son bastante robustas a la desviación de la homocedasticidad (es decir, igual varianza de errores entre los datos) (Day y Quinn 1989, Sokal y Rohlf 1994). De hecho, se debe asegurar un tamaño de muestra igual entre diferentes tratamientos o áreas siempre que sea posible ya que la mayoría de las pruebas paramétricas son excesivamente sensibles a violaciones de supuestos en situaciones con tamaños de muestra desiguales (Day y Quinn 1989). Sin embargo, el mejor enfoque para detectar una violación en la homoescedasticidad es graficar los residuos del análisis frente a valores predichos (es decir, análisis residual) (Crawley 2007). Esta gráfica puede revelar la naturaleza y severidad del posible desacuerdo/discordia entre varianzas (Figura 11.2), y es una característica estándar en muchos paquetes estadísticos. En efecto, dicha inspección visual de los residuos del modelo, además de los beneficios señalados anteriormente, puede ayudar a determinar no sólo si hay necesidad de transformación de datos, sino también el tipo de distribución. Aunque existen varias pruebas formales para determinar la heterogeneidad de las varianzas (por ejemplo, la prueba de Bartlett, la prueba de Levine), estas técnicas asumen una distribución de datos normal, lo que reduce su utilidad en la mayoría de los estudios ecológicos (Sokal y Rohlf 1994).
Normalidad
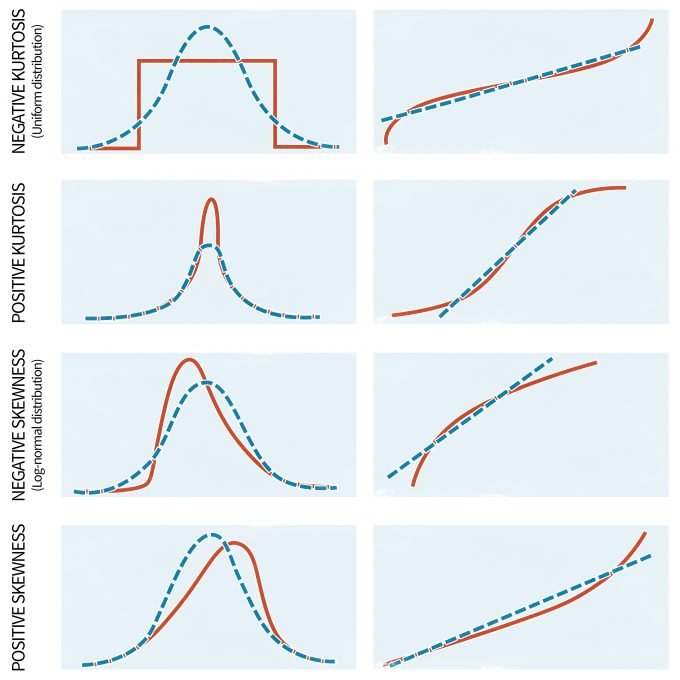
Aunque las estadísticas paramétricas son bastante robustas ante las violaciones del supuesto de normalidad, las distribuciones altamente sesgadas pueden afectar significativamente los resultados. Desafortunadamente, la no normalidad parece ser la norma en ecología; en otras palabras, los datos ecológicos solo raramente siguen una distribución normal (Potvin y Roff 1993, White y Bennetts 1996, Hayek y Buzas 1997, Zar 1999). Además, la distribución normal describe principalmente variables continuas mientras que los datos de conteo, a menudo el tipo de información recopilada durante los programas de monitoreo, son discretos (Thompson et al. 1998, Krebs 1999). Por lo tanto, es importante estar atentos a grandes desviaciones de la normalidad en sus datos. Esto se puede hacer con una serie de pruebas si sus datos cumplen con ciertas especificaciones. Por ejemplo, si el tamaño de la muestra es igual entre grupos y suficientemente grande (por ejemplo, n > 20) se pueden implementar pruebas para evaluar la normalidad o para determinar la significancia de la no normalidad. Este último se realiza comúnmente con varias técnicas, entre ellas la prueba W y la prueba D de Kolmogorov-Smirnov para tamaños de muestra más grandes. La aplicabilidad de ambas pruebas, sin embargo, es limitada debido a que presentan una baja potencia si el tamaño de la muestra es pequeño y una sensibilidad excesiva cuando el tamaño de la muestra es grande. Para superar estas complicaciones, también se realizan exámenes visuales de los datos. Los exámenes visuales son generalmente más apropiados que los exámenes formales ya que permiten detectar la extensión y el tipo de problema. Tenga en cuenta, sin embargo, que al trabajar con modelos lineales el objetivo es “normalizar” los datos/residuales. Trazar los residuos con gráficas de probabilidad normal (Figura 11.3), diagramas de tallo y hoja o histogramas puede ayudar a comprender la naturaleza de los datos no normales (Day y Quinn 1989).
Posibles remedios si se violan los supuestos paramétricos
A menudo se recomiendan transformaciones de datos o pruebas no paramétricas como soluciones adecuadas si los datos no cumplen con los supuestos paramétricos (Sabin y Stafford 1990, Thompson et al. 1998). Sin embargo, quienes desarrollan planes de monitoreo deberían abogar repetidamente (y en voz alta) por un diseño experimental sólido como la única prevención efectiva de muchos problemas estadísticos. Esto mantendrá al mínimo la recolección de datos desorganizada y las transformaciones cuestionables de datos. No hay transformación ni botón estadístico mágico para los datos que se recopilan incorrectamente. Sin embargo, un programa de monitoreo adecuadamente diseñado tampoco es una panacea; los ecosistemas son complejos. Por lo tanto, incluso los diseños adecuados pueden producir datos que confunden el análisis, son desordenados y requieren algunas soluciones si se van a utilizar modelos paramétricos.
Transformación de datos
Si se producen violaciones significativas de los supuestos paramétricos, se acostumbra implementar una transformación de datos adecuada para tratar de resolver las violaciones. Durante una transformación, los datos serán convertidos y analizados a una escala diferente. En general, los investigadores deben ser conscientes de la necesidad de retrotransformar los resultados después del análisis para presentar valores de parámetros en la escala de datos original o tener claro que sus resultados se están presentando en una escala transformada. En el Cuadro 11.2 se presentan ejemplos de tipos comunes de transformaciones que un biometrico puede recomendar para su uso. Una transformación sabiamente elegida a menudo puede mejorar la homogeneidad de las varianzas y producir una aproximación de una distribución normal.
| Tipo de transformación | Cuando sea apropiado para usar |
| Logarítmica | Usar con datos de conteo y cuando las medias se correlacionen positivamente con varianzas. Una regla general sugiere su uso cuando el valor más grande de la variable de respuesta es al menos 10 x el valor más pequeño. |
| Raíz cuadrada | Usar con datos de conteo siguiendo una distribución de Poisson. |
| Inverso | Utilízalo cuando los residuos de datos muestran un patrón severo en forma de embudo, a menudo el caso en conjuntos de datos con muchos valores cercanos a cero. |
| Raíz cuadrada de arcoseno | Bueno para datos proporcionales o binomiales. |
| Enfoque objetivo de Box-Cox | Si es difícil decidir qué transformación utilizar, este procedimiento encuentra un modelo óptimo para los datos. |
Alternativas no paramétricas
Si los datos violan supuestos paramétricos básicos, y las transformaciones no logran remediar el problema, entonces es posible que desee utilizar métodos no paramétricos (Sokal y Rohlf 1994, Thompson et al. 1998, Conover 1999). Las técnicas no paramétricas tienen suposiciones menos estrictas sobre los datos, son menos sensibles a la presencia de valores atípicos y, a menudo, son más intuitivas y fáciles de calcular (Hollander y Wolfe 1999). Dado que los modelos no paramétricos son menos potentes que sus homólogos paramétricos, sin embargo, se prefieren las pruebas paramétricas si se cumplen los supuestos o las transformaciones de datos son exitosas (Day y Quinn 1989, Johnson 1995).
Distribución estadística de los datos
Como se mencionó anteriormente, los datos de plantas y animales suelen estar en forma de recuentos de organismos y esto puede presentar desafíos especiales durante los análisis. La probabilidad de que los organismos ocurran en un hábitat particular incide directamente en la selección de protocolos de muestreo y modelos estadísticos apropiados (Southwood 1992). Los datos de monitoreo probablemente se aproximarán a distribuciones aleatorias o agrupadas, sin embargo esto no debe asumirse ciegamente. Ajustar los datos a los modelos binomiales de Poisson o negativos son formas comunes de probar si lo hacen (Southwood 1992, Zuur 2009). Estos modelos también son particularmente apropiados para describir datos de conteo, que son, una vez más, ejemplos de variables discretas (por ejemplo, recuentos de cuadratas, proporciones de sexos, proporciones de juveniles a adultos). Las siguientes subsecciones describen brevemente cómo identificar si los datos siguen o no un modelo de distribución binomial de Poisson o negativo.
Distribución de Poisson
Las distribuciones de Poisson son comunes entre las especies, donde la probabilidad de detectar un individuo en cualquier muestra es bastante baja (Southwood 1992). El modelo de Poisson da un buen ajuste a los datos si el recuento medio (por ejemplo, número de anfibios por cuadrático de muestreo) está en el rango de 1—5. A medida que aumenta el número medio de individuos en la muestra, y supera los 10, sin embargo, la distribución aleatoria comienza a acercarse a la distribución normal (Krebs 1999, Zar 1999).
Durante el muestreo, el supuesto clave de la distribución (aleatoria) de Poisson es que el número esperado de organismos en una muestra es el mismo y que es igual a μ, la media poblacional (Krebs 1999, Zuur 2009). Una propiedad intrigante de la distribución aleatoria es que se puede describir por su media, y que la media es igual a la varianza (s 2). La probabilidad (frecuencia) de detectar un número dado de individuos en una muestra recolectada de una población con media = μ es:
P μ = e -μ (μ μ /μ!)
Si los datos siguen o no una distribución aleatoria se puede probar con una simple prueba de bondad de ajuste de Chi-cuadrado o con un índice de dispersión (I), que se espera que sea 1.0 si se cumple la suposición de aleatoriedad:
I = s 2/x,
donde xy s 2 son la media y varianza de la muestra observada, respectivamente.
Zurr et al. (2009) proporcionaron excelentes ejemplos de pruebas de bondad de ajuste para distribuciones de Poisson. En la práctica, la presencia de una distribución de Poisson en los datos también se puede evaluar visualmente examinando el patrón de dispersión de los residuos durante el análisis. Si rechazamos la hipótesis nula de que las muestras provienen de una distribución aleatoria, s 2 < μ, y s 2/μ < 1.0, entonces los organismos muestreados se distribuyen de manera uniforme o regular (subdispersos). Si rechazamos la hipótesis nula pero los valores de s 2 y s 2/μ no caen dentro de esos límites, entonces los organismos muestreados se agrupan (sobredispersan).
Distribución binomial negativa
Un enfoque alternativo a la distribución de Poisson, y una de las distribuciones matemáticas que describen patrones espaciales agrupados o agregados, es la distribución binomial negativa (Pascal) (Anscombe 1973, Krebs 1999, Hilbe 2007, Zuur 2009). White y Bennetts (1996) sugirieron que esta distribución es una mejor aproximación a los datos de conteo que las distribuciones de Poisson o normales. La distribución binomial negativa se describe por la media y el parámetro de dispersión k, que expresa el grado de aglutinación. Como resultado de la agregación, siempre se deduce que s 2 > μ y el índice de dispersión (I) > 1.0. Existen varias técnicas para evaluar la bondad de ajuste de los datos a la distribución binomial negativa. Como ejemplo, White y Bennetts (1996) dan un ejemplo de ajuste de la distribución binomial negativa a los datos de conteo de puntos para currucas coronadas anaranjadas para comparar su abundancia relativa entre sitios forestales. Se recomiendan modelos de Poisson inflados con cero (modelos ZIP) para el análisis de datos de conteo con valores cero frecuentes (por ejemplo, estudios de especies raras) o donde las transformaciones de datos no sean factibles o apropiadas (por ejemplo, Heilbron 1994, Welsh et al. 1996, Hall y Berenhaut 2002, Zuur 2009). Se pueden encontrar buenas descripciones y ejemplos de su uso en Krebs (1999), Southwood (1992), Faraway (2006) y Zurr et al. (2009). Dado que la variedad de posibles patrones de aglutinación en la naturaleza es prácticamente infinita, es posible que las distribuciones binomiales de Poisson y negativas no siempre se ajusten adecuadamente a los datos disponibles.
Análisis de Datos de Inventario — Abundancia
Densidad absoluta o tamaño de la población
La política nacional sobre especies amenazadas y amenazadas se dirige en última instancia a los esfuerzos para aumentar o mantener el número total de individuos de la especie dentro de su área de distribución geográfica natural (Carroll et al. 1996). El tamaño total de la población y el tamaño efectivo de la población (es decir, el número de individuos reproductores en una población) (Harris y Allendorf 1989) son los dos parámetros que más directamente indican el grado de peligro de especies y/o la efectividad de las políticas y prácticas de conservación. La densidad poblacional es informativa para evaluar el estado y las tendencias de la población porque el parámetro es sensible a los cambios en la mortalidad natural, la explotación y la calidad del hábitat. En algunas circunstancias, puede ser factible realizar un censo de todos los individuos de una especie en particular en un área para determinar el tamaño total de la población o los parámetros de densidad. Por lo general, sin embargo, los parámetros de tamaño poblacional y densidad se estiman mediante análisis estadísticos basados únicamente en una muestra de miembros de la población (Yoccoz et al. 2001, Pollock et al. 2002). Las densidades poblacionales de plantas y animales sésiles se pueden estimar a partir de recuentos tomados en parcelas o datos que describen el espaciamiento entre individuos (es decir, métodos de distancia) y son relativamente sencillas. Los análisis poblacionales de muchas especies animales deben dar cuenta de la respuesta animal a la captura u observación, los sesgos de los observadores y las diferentes probabilidades de detección entre las subpoblaciones (Kery y Schmid 2004). Por ejemplo, la contratación de múltiples técnicos para el trabajo de campo y el monitoreo de una especie cuyo comportamiento o cambio de hábitat preferido estacionalmente son dos factores que habría que abordar en el análisis. Por lo general, se requieren estudios piloto para recabar los datos necesarios para ello. Además, las técnicas más comunes utilizadas para especies animales, como los estudios de marca-recaptura, los programas de monitoreo de esfuerzo de captura por unidad y los estudios de ocupación, requieren visitas repetidas a las unidades de muestreo. Esto, junto con la necesidad de estudios piloto, aumenta la complejidad y el costo del monitoreo para estimar los parámetros poblacionales relativos al monitoreo de organismos sésiles.
Para las especies animales, los modelos de marca-recaptura suelen valer la inversión adicional en términos de los datos generados, ya que pueden ser utilizados para estimar densidades absolutas de poblaciones y proporcionar información adicional sobre estadísticas vitales tales como movimiento animal, distribución geográfica y supervivencia (Lebreton et al. 1992, Nichols 1992, Nichols y Kendall 1995, Thomson et al. 2009). Los modelos de marca-recaptura abierta (por ejemplo, Jolly-Seber) asumen cambios naturales en el tamaño poblacional de la especie de interés durante el muestreo. En contraste, los modelos cerrados asumen un tamaño de población constante. El programa MARK (White et al. 2006) realiza sofisticados análisis de marca-recaptura basados en la probabilidad máxima y puede probar y dar cuenta de muchos de los supuestos, tales como poblaciones abiertas y heterogeneidad.
Índices de abundancia relativa
A veces ocurre que los análisis de datos para inventarios biológicos y estudios de monitoreo pueden realizarse con base en índices de densidad o abundancia poblacional, más que en estimadores de población (Pollock et al. 2002). La diferencia entre estimadores e índices es que los primeros producen valores absolutos de densidad poblacional mientras que los segundos proporcionan medidas relativas de densidad que pueden ser utilizadas para evaluar las diferencias poblacionales en el espacio o el tiempo. Caughley (1977) abogó por el uso de índices después de determinar que muchos estudios que utilizaron estimaciones de densidad absoluta podrían haber utilizado índices de densidad sin perder información. Sugirió que el uso de índices a menudo resulta en un uso mucho más eficiente del tiempo y los recursos y produce resultados con mayor precisión (Caughley 1977, Caughley y Sinclair 1994). Engelan (2003) también indicó que el uso de un índice puede ser el medio más eficiente para abordar los objetivos de monitoreo poblacional y que las preocupaciones asociadas con el uso de índices pueden abordarse con un diseño experimental adecuado y minucioso y análisis de datos. Es importante, por lo tanto, comprender estas preocupaciones antes de utilizar un índice, a pesar de que los índices de abundancia relativa tienen un amplio apoyo entre los practicantes que a menudo señalan su eficiencia y mayor precisión (Caughley 1977, Engeman 2003). En primer lugar, se basan en el supuesto de que los valores del índice están estrechamente asociados con los valores de un parámetro poblacional. Debido a que la relación precisa entre el índice y el parámetro generalmente no se cuantifica, la confiabilidad de esta suposición a menudo se pone en duda (Thompson et al. 1998, Anderson 2001). Además, la oportunidad de sesgo asociado a los índices de abundancia es bastante alta. Por ejemplo, los recuentos de huellas podrían estar relacionados con la abundancia animal, los niveles de actividad animal o ambos. Los índices a menudo se utilizan debido a limitaciones logísticas. Las tasas de captura de animales en el espacio y el tiempo pueden estar relacionadas con la abundancia animal o con su vulnerabilidad a la captura en áreas de diferente calidad de hábitat. Si se utiliza alguna de estas técnicas para generar el índice, se debe tener considerable precaución a la hora de interpretar los resultados. Ante estas preocupaciones, es clara la utilidad de un estudio piloto que permita determinar, con un nivel de certeza conocido, la relación entre el índice y la población real (o idoneidad) para la especie que se está monitoreando. Determinar esta relación, sin embargo, requiere una estimación de la población.
La idoneidad de cualquier técnica, incluidos los índices, debe basarse en última instancia en qué tan bien aborda el objetivo del estudio y la confiabilidad de sus resultados (Thompson 2002). También es importante considerar que los análisis estadísticos de los datos de abundancia relativa requieren familiaridad con los supuestos básicos de los modelos paramétricos y no paramétricos. Algunos ejemplos del uso y análisis de datos de densidad relativa se pueden encontrar en James et al. (1996), Rotella et al. (1996), Knapp y Matthews (2000), Huff et al. (2000), y Rosenstock et al. (2002).
Los análisis de los datos de abundancia relativa requieren familiaridad con los supuestos básicos de los modelos paramétricos. Dado que el foco está en los datos de conteo, se pueden emplear métodos estadísticos alternativos para ajustar la distribución de los datos (por ejemplo, Poisson o binomio negativo). Aunque las técnicas de abundancia absoluta son independientes de los supuestos paramétricos, sin embargo tienen sus propios requisitos estrictos.
Cuando un investigador decide utilizar un índice de monitoreo, es importante recordar que el poder estadístico se correlaciona negativamente con la variabilidad del índice de monitoreo. Esto realmente subraya la necesidad de elegir un indicador apropiado de abundancia y estimar con precisión su intervalo de confianza (Harris 1986, Gerrodette 1987, Gibbs et al. 1999). Una excelente visión general de una variedad de grupos de animales y plantas por los que se conoce la variabilidad en la estimación de su población se da en Gibbs et al. (1998). También es importante tener en cuenta que las medidas relativas de densidad pueden ser menos robustas a los cambios en el hábitat que las medidas absolutas. Por ejemplo, las prácticas forestales pueden afectar significativamente los índices que se basan en observaciones visuales de organismos. Aunque estos factores también pueden confundir las medidas absolutas, los métodos modernos de análisis de distancia y marca-recaptura pueden explicar las variaciones en la visibilidad y la trapabilidad. Ver Caughley (1977), Thompson et al. (1998), Rosenstock et al. (2002), Pollock et al. (2002) y Yoccoz et al. (2001) para discusiones en profundidad sobre los méritos y limitaciones de estimar densidad relativa vs. densidad absoluta en estudios de monitoreo poblacional.
Modelos Lineales Generalizados y Efectos Mixtos
Recientemente, los modelos lineales generalizados (GLM) se han vuelto cada vez más populares y aprovechan la verdadera distribución de los datos sin intentar normalizarlos (Faraway 2006, Bolker 2008, McCulloch et al. 2008). Muchas veces, el modelo lineal estándar no puede manejar respuestas no normales, como recuentos o proporciones, mientras que los modelos lineales generalizados se desarrollaron para manejar tipos de respuesta categórica, binaria y otros tipos de respuesta (Faraway 2006, McCulloch et al. 2008). En la práctica, la mayoría de los datos tienen errores no normales, por lo que los GLM permiten al usuario especificar una variedad de distribuciones de errores. Esto puede ser particularmente útil con datos de conteo (por ejemplo, errores de Poisson), datos binarios (por ejemplo, errores binomiales), datos de proporciones (por ejemplo, errores binomiales), datos que muestran un coeficiente de variación constante (por ejemplo, errores gamma) y análisis de supervivencia (por ejemplo, errores exponenciales) (Crawley 2007).
Una extensión del GLM es el enfoque del Modelo Mixto Lineal Generalizado (GLMM). Los GLMM son ejemplos de modelos jerárquicos y son los más apropiados cuando se trata de datos anidados. ¿Qué son los datos anidados? Como ejemplo, los programas de monitoreo pueden recopilar datos sobre abundancias de especies o ocurrencias de múltiples sitios en diferentes ocasiones de muestreo dentro de cada sitio. Alternativamente, los investigadores también podrían tomar muestras de un solo sitio en diferentes años. En ambos casos, los datos se “anidan” dentro de un sitio o un año, y analizar los datos generados a partir de estas encuestas sin considerar el efecto “sitio” o “año” se consideraría pseudoreplicación (Hullbert 1984). Es decir, existe una falsa suposición de independencia de las ocasiones de muestreo dentro de un solo sitio o a lo largo del periodo de muestreo. Tradicionalmente, los investigadores podrían evitar este problema promediando los resultados de esas ocasiones de muestreo a través de los sitios o años y enfocarse en los medios, o simplemente pueden enfocar su análisis dentro de un sitio individual o período de muestreo. Los enfoques estadísticos más estándar, sin embargo, intentan cuantificar el efecto exacto de las variables predictoras (por ejemplo, área forestal, densidad forb), pero los problemas ecológicos a menudo involucran efectos aleatorios que son resultado de la variación entre sitios o períodos de muestreo (Bolker et al. 2009). Los efectos aleatorios que provienen del mismo grupo (p. ej., sitio o periodo de tiempo) a menudo se correlacionarán, violando así el supuesto estándar de independencia de errores en la mayoría de los modelos estadísticos.
Los modelos jerárquicos ofrecen una excelente manera de lidiar con estos problemas, pero al usar GLMs, los investigadores deben ser capaces de identificar correctamente la diferencia entre un efecto fijo y un efecto aleatorio. En su forma más básica, los efectos fijos tienen niveles de factores “informativos”, mientras que los efectos aleatorios suelen tener niveles de factores “poco informativos” (Crawley 2007). Es decir, los efectos aleatorios tienen niveles de factores que pueden considerarse muestras aleatorias de una población mayor (por ejemplo, bloques, sitios, años). En este caso, es más apropiado modelar la variación agregada causada por las diferencias entre los niveles de los efectos aleatorios y la variación en las variables de respuesta (a diferencia de las diferencias en la media). En la mayoría de las situaciones aplicadas, las variables de efecto aleatorio suelen incluir nombres de sitios o años. En otros casos, cuando se miden múltiples respuestas en un individuo (por ejemplo, supervivencia), los efectos aleatorios pueden incluir individuos, genotipos o especies. En contraste, los efectos fijos entonces solo modelan diferencias en la media de la variable de respuesta, a diferencia de la varianza de la variable de respuesta a través de los niveles del efecto aleatorio, y pueden incluir variables ambientales predictoras que se miden en un sitio o dentro de un año. En la práctica, estas distinciones son a veces difíciles de hacer y los modelos de efectos mixtos pueden ser desafiantes de aplicar. Por ejemplo, en su revisión de 537 estudios ecológicos que utilizaron análisis GLMM, Bolker (2009) encontró que 58% utilizó esta herramienta de manera inapropiada. En consecuencia, como ocurre con muchos de estos procedimientos, es importante consultar con un estadístico a la hora de desarrollar e implementar su análisis. Hay varias excelentes críticas y libros sobre el tema del modelado de efectos mixtos (Gelman y Hill 2007, Bolker et al. 2009, Zuur 2009).
Análisis de Ocurrencias y Distribución de Especies
¿Ocurre una especie o no ocurre con certeza razonable en un área bajo consideración para su manejo? ¿Dónde es probable que se produzca la especie? Este tipo de preguntas han sido y siguen siendo de interés para muchos programas de monitoreo (MacKenzie 2005, MacKenzie 2006). Los datos sobre las ocurrencias de especies suelen ser más rentables de recopilar que los datos sobre la abundancia de especies o los datos demográficos. Tradicionalmente, la información sobre las ocurrencias de especies se ha utilizado para:
- Identificar hábitats que soportan el menor o mayor número de especies,
- arrojar luz sobre la distribución de especies, y
- Señalar las relaciones entre los atributos del hábitat (p. ej., tipos de vegetación, características estructurales del hábitat) y la ocurrencia de especies o riqueza de especies comunitarias.
Para muchos programas de monitoreo, los datos de ocurrencia de especies a menudo se consideran datos preliminares que solo se recopilan durante la fase inicial de un proyecto de inventario y, a menudo, para recopilar información de antecedentes para el área del proyecto. En los últimos años, sin embargo, el modelado y estimación de la ocupación (MacKenzie et al. 2002, MacKenzie et al. 2005, Mackenzie y Royle 2005, MacKenzie 2006) se ha convertido en un aspecto crítico para el monitoreo de poblaciones animales y vegetales. Este tipo de datos categóricos han representado una fuente importante de datos para muchos programas de monitoreo que se han dirigido a especies raras o esquivas, o donde los recursos no están disponibles para recolectar los datos requeridos para los modelos de estimación de parámetros (ver Hayek y Buzas 1997, Thompson 2004).
Para algunos estudios poblacionales, el simple hecho de determinar si una especie está presente en un área puede ser suficiente para realizar el análisis de datos planificado. Por ejemplo, los biólogos que intentan conservar una orquídea de humedal amenazada pueden necesitar monitorear la extensión del rango de especies y la proporción del área ocupada (POA) en un Bosque Nacional. Un enfoque hipotético es mapear todos los humedales en los que se sabe que la orquídea está presente, así como humedales adicionales que pueden calificar como el tipo de hábitat para las especies dentro del Bosque. Para monitorear los cambios en la distribución de orquídeas a escala gruesa, la recolección de datos podría consistir en un programa semestral de monitoreo realizado a lo largo de transectos en cada uno de los humedales mapeados para determinar si al menos una orquídea individual (o algún criterio alternativo para establecer ocupación) está presente. Usando solo una lista que incluya la etiqueta de humedal (es decir, el identificador único), el año de monitoreo y una variable indicadora de ocupación, los biólogos pudieron preparar una serie temporal de mapas que muestran todos los humedales por año de monitoreo y distinguir el subconjunto de humedales que fueron encontrados ocupados por la orquídea.
Los programas de monitoreo para determinar la presencia de una especie suelen requerir menos intensidad de muestreo que el trabajo de campo necesario para recolectar otras estadísticas poblacionales. Es mucho más fácil determinar si hay al menos un individuo de las especies objetivo en una unidad de muestreo que contar todos los individuos. Por el contrario, para determinar con confianza que una especie no está presente en una unidad de muestreo requiere un muestreo más intensivo que recolectar datos de conteo o frecuencia porque es muy difícil descartar la posibilidad de que un individuo falte la detección (es decir, una falla en la detección no equivale necesariamente a ausencia). Tradicionalmente, el uso de datos de ocurrencia se consideró una evaluación cualitativa de los cambios en el patrón de distribución de especies y sirvió como un primer paso importante para formular nuevas hipótesis sobre la causa de los cambios observados. Más recientemente, sin embargo, el muestreo repetido y la estimación de modelos de ocupación de uso han incrementado la aplicabilidad de los datos de ocurrencia en el monitoreo ecológico.
Posibles modelos de análisis para datos de ocurrencia
Diversidad de especies
El número de especies por muestra (por ejemplo, 1-m 2 cuadrático) puede dar una evaluación simple de la diversidad local, α, o estos datos pueden ser utilizados para comparar la composición de especies entre varias ubicaciones (diversidad β) usando fórmulas binarias simples como el índice de Jaccard o el coeficiente de Sorensen (Magurran 1988). Por ejemplo, el índice cualitativo de Sorensen puede calcularse como:
C S = 2 j/(a + b),
donde a y b son números de especies en las ubicaciones A y B, respectivamente, y j es el número de especies encontradas en ambos lugares. Si se conoce la abundancia de especies (número individuos/especies), la diversidad de especies puede analizarse con una mayor variedad de descriptores tales como riqueza numérica de especies (por ejemplo, número de especies/número de individuos), índices de similitud cuantitativa (por ejemplo, índice cuantitativo de Sorensen, índice de Morista-Horn), proporcional índices de abundancia (por ejemplo, índice de Shannon, índice Brillouin), o modelos de abundancia de especies (Magurran 1988, Hayek y Buzas 1997).
Análisis Binario
Dado que los datos detectados/no detectados son categóricos, la relación entre la ocurrencia de especies y las variables explicativas puede modelarse con una regresión logística si se atribuyen a los datos valores de 1 (especies detectadas) o 0 (especies no detectadas) (Trexler y Travis 1993, Hosmer y Lemeshow 2000, Agresti 2002). La regresión logística requiere una variable de respuesta dicotómica (0 o 1) o proporcional (que va de 0 a 1). Sin embargo, en muchos casos, la regresión logística se utiliza en combinación con un conjunto de variables para predecir la detección o no detección de una especie. Por ejemplo, una regresión logística puede enriquecerse con predictores tales como el porcentaje de cobertura vegetal, área de parche forestal o presencia de inconvenientes para crear un modelo más informativo de la ocurrencia de una especie de ave que habita en el bosque. La función logística resultante proporciona un índice de probabilidad con respecto a la ocurrencia de especies. Existen una serie de funciones de validación cruzada que permiten al usuario identificar el valor de probabilidad que mejor separa los sitios donde se encontró una especie de donde no se encontró con base en los datos existentes (Freeman y Moisen 2008). En algunos casos, los puntos de datos se retienen del análisis formal (por ejemplo, datos de validación) y se utilizan para probar las relaciones después de que se desarrollen las relaciones predictivas utilizando el resto de datos (por ejemplo, datos de entrenamiento) (Harrell 2001). La regresión logística, sin embargo, es una prueba paramétrica. Si los datos no cumplen o aproximan el supuesto paramétrico, se pueden utilizar alternativas a la regresión logística estándar, incluidos los análisis de Modelos Aditivos Generales (GAM) y variaciones del árbol de clasificación (CART).
Predicción de la densidad de especies
En algunos casos, los datos de ocurrencia se han utilizado para predecir la densidad de organismos si se conoce la relación entre la ocurrencia de especies y la densidad y el poder predictivo del modelo es razonablemente alto (Hayek y Buzas 1997). Por ejemplo, se puede registrar la abundancia de plantas y la riqueza de especies en cuadrantes de muestreo. La abundancia proporcional de especies, o constancia de su frecuencia de ocurrencia (P o), puede calcularse entonces como:
P o = Número de ocurrencias de especies (+ o 0)/número de muestras (cuadrantes)
En consecuencia, la densidad promedio de especies se grafica contra su abundancia proporcional para derivar un modelo para predecir la abundancia de especies en otras localidades con solo datos de ocurrencia. Tenga en cuenta, sin embargo, que el modelo puede funcionar razonablemente bien solo en tipos similares y geográficamente relacionados de comunidades vegetales (Hayek y Buzas 1997).
Modelado de Ocupación
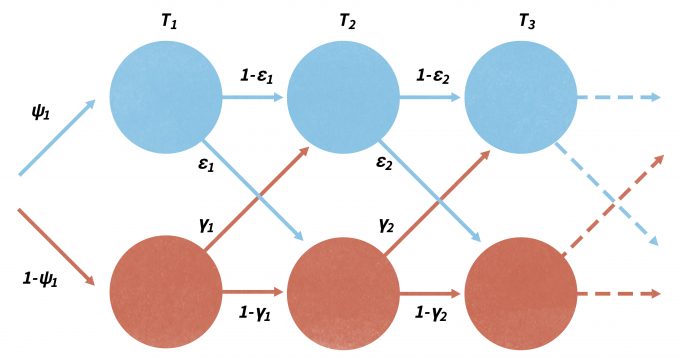
Nótese que sin un diseño adecuado, los datos detectados/no detectados no pueden usarse de manera confiable para medir o describir distribuciones de especies (Kery y Schmid 2004, MacKenzie 2006, Kéry et al. 2008). Aunque los métodos tradicionales que utilizan regresión logística y otras técnicas pueden ser utilizados para desarrollar un modelo de base biológica que pueda predecir la probabilidad de ocurrencia de un sitio sobre un paisaje, el modelado de ocupación se ha desarrollado rápidamente en los últimos años. Al igual que con el análisis de marca-recaptura, los cambios en la ocupación a lo largo del tiempo se pueden parametrizar en términos de procesos de extinción local (ε) y colonización (γ), análogos a los procesos demográficos poblacionales de mortalidad y reclutamiento (Figura 11.4) (MacKenzie et al. 2003, MacKenzie 2006, Royle y Dorazio 2008). En este caso, el muestreo debe realizarse de manera repetida dentro de periodos separados de muestreo primario (Figura 11.4). Los modelos de ocupación son robustos a las observaciones faltantes y pueden modelar efectivamente la variación en las probabilidades de detección entre especies. De mayor importancia, las probabilidades de ocupación (ψ), colonización (γ) y extinción local (ε) se pueden modelar como funciones de variables covariables ambientales que pueden ser específicas de sitio, específicas de recuento o cambio entre los períodos primarios (MacKenzie et al. 2003, MacKenzie et al. 2009). Además, las probabilidades de detección también pueden ser funciones de covariables específicas de la temporada y pueden cambiar con cada levantamiento de un sitio. Más recientemente, el programa PRESENCIA se ha puesto a disposición como una sofisticada familia de modelos basados en la simpatía que ha sido cada vez más popular utilizando la ocurrencia de especies para su monitoreo (www.mbr-pwrc.usgs.gov/software/presence.html). Donovan y Hines (2007) también presentan una explicación de los modelos de ocupación y varios ejercicios en línea (www.uvm.edu/envnr/vtcfwru/spreadsheets/occupancy/occupancy.htm).
Supuestos, interpretación de datos y limitaciones
Es crucial recordar que no detectar una especie en un hábitat no significa que la especie estuviera realmente ausente (Kery y Schmid 2004, MacKenzie 2006, Kéry et al. 2008). Las especies crípticas o raras, como los anfibios, son especialmente propensas a la subdetección y a las ausencias falsas (Thompson 2004). Tenga en cuenta que las confirmaciones ocasionales de presencia de especies proporcionan solo datos limitados. Por ejemplo, el uso de un hábitat por parte de un depredador puede reflejar la disponibilidad de presas, que puede fluctuar anualmente o incluso durante un año. Es necesario un enfoque más sistemático con visitas repetidas para generar datos más significativos (Mackenzie y Royle 2005).
Extrapolar la densidad sin entender los requisitos de las especies también es probable que produzca resultados sin sentido, ya que los organismos dependen de muchos factores que normalmente no entendemos. Además, se deben reconocer las limitaciones de las medidas de diversidad de especies, especialmente en los proyectos de conservación. Por ejemplo, el reemplazo de una especie rara o clave por una especie común o exótica no afectaría la riqueza de especies de la comunidad y en realidad podría 'mejorar' las métricas de diversidad. Además, el valor informativo de los índices cualitativos es bastante bajo ya que ignoran la abundancia de especies y son sensibles a las diferencias en el tamaño de la muestra (Magurran 1988). Las especies raras y comunes se ponderan por igual en las comparaciones comunitarias. A menudo esto puede ser una suposición errónea ya que se espera que el efecto de una especie en la comunidad sea proporcional a su abundancia; las especies clave son raras excepciones (Power and Mills 1995). Además, los análisis que se centran en las coocurrencias de especies sin modelar efectivamente o tomando en cuenta las diferentes probabilidades de detección de la especie pueden ser propensos al error, aunque los nuevos modelos de ocupación comienzan a incorporar detectabilidad en modelos de riqueza de especies (MacKenzie et al. 2004, Royle et al. 2007, Kéry et al. 2009).
Análisis de Datos de Tendencia
Se deben utilizar modelos de tendencia si el objetivo de un plan de monitoreo es detectar un cambio en un parámetro poblacional a lo largo del tiempo. Más comúnmente, el tamaño de la población se estima repetidamente a intervalos de tiempo establecidos. El monitoreo de tendencias es crucial en el manejo de las especies ya que puede ayudar a:
- Reconocer la disminución poblacional y centrar la atención en las especies afectadas,
- Identificar variables ambientales correlacionadas con la tendencia observada y así ayudar a formular hipótesis para estudios de causa y efecto, y
- Evaluar la efectividad de las decisiones de gestión (Thomas 1996, Thomas y Martin 1996).
El estado de una población puede evaluarse comparando estimaciones observadas del tamaño de la población en algún intervalo de tiempo con valores umbral relevantes para el manejo (Gibbs et al. 1999, Elzinga et al. 2001). Todos los planes de monitoreo, pero particularmente aquellos diseñados para generar datos de tendencias, deben enfatizar que la selección de indicadores confiables o estimadores del cambio poblacional es un requisito clave para los esfuerzos efectivos de monitoreo. A menudo se utilizan índices de abundancia relativa en lugar de medidas del tamaño real de la población, a veces debido al costo y esfuerzo relativamente reducidos necesarios para recopilar los datos necesarios de forma iterativa. Por ejemplo, los recuentos de masas de huevos de rana pueden realizarse anualmente en estanques (Gibbs et al. 1998) o los recuentos de puntos de aves pueden realizarse a lo largo de rutas de muestreo (Böhning-Gaese et al. 1993, Link y Sauer 1997a, b; 2007). El análisis de mapas de distribución, listas de verificación y datos recopilados por voluntarios también puede proporcionar estimaciones de tendencias poblacionales (Robbins 1990, Temple y Cary 1990, Cunningham y Olsen 2009, Zuckerberg et al. 2009). Para minimizar el sesgo en la detección de una tendencia, como en estudios de especies sensibles, la misma población puede ser monitoreada usando diferentes métodos (por ejemplo, una serie de diferentes índices) (Temple y Cary 1990). Los datos también pueden ser cribados antes del análisis. Por ejemplo, solo se pueden incluir programas de monitoreo que cumplan con criterios acordados, o las especies con muy pocas observaciones pueden ser excluidas del análisis (Thomas 1996, Thomas y Martin 1996).
Posibles modelos de análisis
Las tendencias sobre el espacio y el tiempo presentan muchos desafíos para el análisis en la medida en que no existe consenso sobre el método más adecuado para analizar los datos relacionados. Esta es una restricción significativa ya que la selección de modelos puede tener un impacto considerable en la interpretación de los resultados del análisis (Thomas 1996, Thomas y Martin 1996).
La regresión de Poisson es independiente de los supuestos paramétricos y es especialmente apropiada para los datos de conteo. Los modelos clásicos de regresión lineal en los que se trazan estimaciones del tamaño de la población frente a periodos de muestreo biológicamente relevantes se han utilizado históricamente en estudios poblacionales ya que son fáciles de calcular e interpretar. Sin embargo, estos modelos están sujetos a supuestos paramétricos, que a menudo se violan en los datos de conteo (Krebs 1999, Zar 1999). Las regresiones lineales también asumen una tendencia lineal constante en los datos, y esperan puntos de datos independientes e igualmente espaciados. Dado que las mediciones individuales en los datos de tendencia son autocorrelacionadas, la regresión clásica puede dar estimaciones sesgadas de errores estándar e intervalos de confianza, e inflar el coeficiente de determinación (Edwards y Coull 1987, Gerrodette 1987). Edwards y Coull (1987) sugirieron que los errores correctos en el análisis de regresión lineal pueden modelarse usando un modelo de proceso autorregresivo (modelo ARIMA). Los modelos de regresión lineal de ruta representan una forma más robusta de regresión lineal y son populares entre los ecologistas de aves en los análisis de programas de monitoreo en carretera (Geissler y Sauer 1990, Sauer et al. 1996, Thomas 1996). Pueden manejar datos desequilibrados realizando análisis sobre promedios ponderados de tendencias de rutas individuales (Geissler y Sauer 1990) pero pueden ser sensibles a tendencias no lineales (Thomas 1996). Las regresiones armónicas o periódicas no requieren puntos de datos espaciados regularmente y son valiosos para analizar datos sobre organismos que muestran tendencias periódicas diarias significativas en abundancia o actividad (Lorda y Saila 1986).
Para algunos datos donde no son posibles grandes tamaños de muestra, o donde la estructura de varianza no se puede estimar de manera confiable, pueden ser necesarios enfoques analíticos alternativos. Esto es especialmente cierto cuando el riesgo de concluir que no se puede detectar una tendencia es causado por una gran varianza o pequeños tamaños de muestra, la especie es rara y la falta de detección de una tendencia podría ser catastrófica para la especie. Wade (2000) proporciona una excelente visión general del uso del análisis bayesiano para abordar este tipo de problemas. Thomas (1996) da una revisión exhaustiva de los modelos más populares ajustados a los datos de tendencias y supuestos asociados con su uso.
Supuestos, interpretación de datos y limitaciones
El supuesto subyacente de los proyectos de monitoreo de tendencias es que un parámetro de población se mide en los mismos puntos de muestreo (por ejemplo, cuadrantes, rutas) usando procedimientos idénticos o similares (por ejemplo, equipo, observadores, período de tiempo) a intervalos regularmente espaciados. Si se violan estos requisitos, los datos pueden contener ruido excesivo, lo que puede complicar su interpretación. Thomas (1996) identificó cuatro fuentes de variación en los datos de tendencias:
- Tendencia predominante — tendencia poblacional de interés (por ejemplo, disminución de la población),
- Alteraciones irregulares: interrupciones por eventos estocásticos (p. ej., mortalidad por sequía),
- Autocorrelación parcial — dependencia del estado actual de la población de sus niveles previos, y
- Error de medición: ruido de datos agregado por procedimientos de muestreo deficientes.
Aunque los análisis de tendencias son útiles para identificar el cambio poblacional, los resultados son correlativos y nos dicen poco sobre los mecanismos subyacentes. En última instancia, solo los estudios de causa y efecto bien diseñados pueden validar la causalidad y facilitar las decisiones de manejo.
Análisis de datos de monitoreo de causa y efecto
La fuerza de los estudios de tendencias radica en su capacidad para detectar cambios en el tamaño de la población. Para entender la razón de las fluctuaciones poblacionales, sin embargo, se debe determinar el mecanismo causal detrás del cambio poblacional. Los estudios de causa y efecto representan uno de los enfoques más fuertes para probar las relaciones causa-efecto y a menudo se utilizan para evaluar los efectos de las decisiones de manejo en las poblaciones. De manera similar a los análisis de tendencias, los análisis de causa y efecto pueden realizarse sobre índices de abundancia relativa o datos de abundancia absoluta.
Posibles modelos de análisis
Los modelos paramétricos y libres de distribución (no paramétricos) proporcionan innumerables alternativas para ajustar datos de causa y efecto (Sokal y Rohlf 1994, Zar 1999). Excelente material introductorio al diseño y análisis de experimentos ecológicos, específicamente para modelos ANOVA, se puede encontrar en Underwood (1997) y Scheiner y Gurevitch (2001).
Se recomienda un diseño único para situaciones en las que se aplica una perturbación (tratamiento) y sus efectos se evalúan tomando una serie de mediciones antes y después de la perturbación (Before-After Control-Impact, BACI) (Stewart-Oaten et al. 1986) (Figura 11.5). Este modelo fue desarrollado originalmente para estudiar los efectos de la contaminación (Green 1979), pero también ha encontrado aplicaciones adecuadas en otras áreas de la ecología (Wardell-Johnson y Williams 2000, Schratzberger et al. 2002, Stanley y Knopf 2002). En su diseño original, un sitio de impacto tendría un sitio de control paralelo. Además, las variables consideradas al inicio del estudio como relevantes para las acciones de gestión serían planeadas para ser monitoreadas periódicamente a lo largo del tiempo. Entonces cualquier diferencia entre las tendencias de esas variables medidas en el sitio de impacto con las del sitio control (efecto del tratamiento) se demostraría como una interacción significativa tiempo*ubicación (Verde 1979). Este enfoque ha sido criticado ya que el diseño se limitó originalmente a sitios de impacto y control no replicados (Figura 11.5), pero se puede mejorar replicando y asignando aleatoriamente sitios (Hullbert 1984, Underwood 1994).
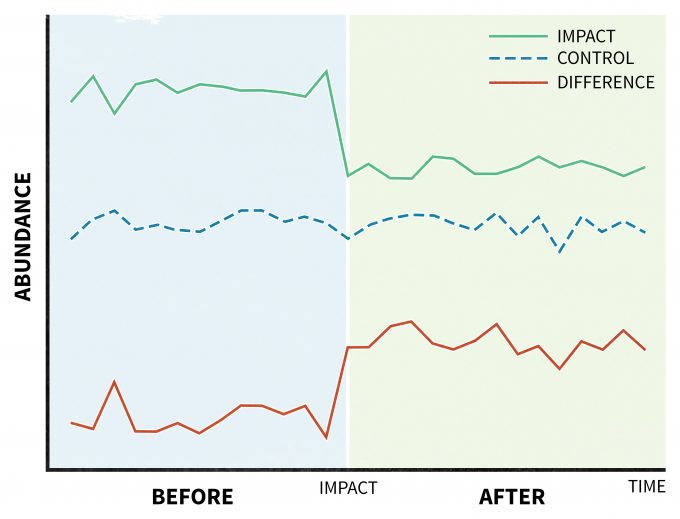
Supuestos, interpretación de datos y limitaciones
Dado que los datos de causa y efecto se analizan frecuentemente con modelos ANOVA, un modelo paramétrico, se debe prestar atención a los supuestos paramétricos. También se pueden emplear medios alternativos para evaluar estudios manipuladores. Por ejemplo, se puede usar el tamaño del efecto biológicamente significativo con intervalos de confianza en lugar de las pruebas de hipótesis estadísticas clásicas. Una excelente visión general de los argumentos en apoyo de este enfoque con ejemplos se puede encontrar en Hayes y Steidl (1997)), Steidl et al. (1997), Johnson (1999) y Steidl y Thomas (2001).
Paradigmas de inferencia: Decir algo con tus datos y modelos
Pruebas de aleatorización
Estas pruebas no son alternativas a las pruebas paramétricas, sino que son medios únicos para estimar la significancia estadística. Son extremadamente versátiles y se pueden utilizar para estimar estadísticas de pruebas para una amplia gama de modelos, y son especialmente valiosos en el análisis de puntos de datos seleccionados no aleatoriamente. Es importante tener en cuenta, sin embargo, que las pruebas de aleatorización son computacionalmente difíciles incluso con tamaños de muestra pequeños (Edgington y Onghena 2007). Un estadístico necesita estar involucrado en la elección de usar e implementar estas técnicas. Se puede encontrar más información sobre pruebas de aleatorización y otras técnicas intensivas en computación en Crowley (1992), Potvin y Roff (1993), y Petraitis et al. (2001).
Enfoques Teóricos de la Información: Criterio de Información de Akaike
El criterio de información de Akaike (AIC), derivado de la teoría de la información, se puede utilizar para seleccionar el modelo que mejor se ajuste entre una serie de alternativas a priori. Este enfoque es más robusto y menos arbitrario que los métodos de prueba de hipótesis, ya que el valor P suele ser predominantemente una función del tamaño de la muestra. La AIC se puede calcular fácilmente para cualquier modelo estadístico basado en probabilidad máxima, incluyendo regresión lineal, ANOVA y modelos lineales generales. La hipótesis del modelo con el menor valor de AIC se identifica generalmente como el “mejor” modelo con mayor soporte (dados los datos) (Burnham y Anderson 2002). Una vez identificado el mejor modelo, los resultados pueden interpretarse en función de los cambios en las variables explicativas a lo largo del tiempo. Por ejemplo, si la cantidad de bosque maduro cerca de arroyos se asociara con la probabilidad de ocurrencia de ranas de cola, entonces se podría usar un mapa generado sobre el alcance de la inferencia para identificar áreas actuales y probables futuras donde las ranas de cola podrían ser vulnerables a acciones de manejo. Además, una de las ventajas más útiles de utilizar enfoques teóricos de la información es que no es necesario identificar un solo, mejor modelo. Usando la métrica AIC (o cualquier otro criterio de información), se pueden clasificar modelos y promediar entre modelos para calcular estimaciones o predicciones de parámetros ponderados (es decir, promedio del modelo). Una discusión más profunda de los usos prácticos de AIC se puede encontrar en Burnham y Anderson (2002) y Anderson (2008).
Inferencia Bayesiana
La estadística bayesiana se refiere a un enfoque distinto para hacer inferencia ante la incertidumbre. En general, las estadísticas bayesianas comparten mucho con las estadísticas frecuencistas tradicionales con las que la mayoría de los ecologistas están familiarizados. En particular, existe una dependencia similar en los modelos de verosimilitud que son aplicados rutinariamente por la mayoría de los estadísticos y biométricos. La inferencia bayesiana también se puede utilizar en una variedad de tareas estadísticas, incluyendo estimación de parámetros y pruebas de hipótesis, pruebas de comparación múltiple post hoc, análisis de tendencias, ANOVA y análisis de sensibilidad (Ellison 1996). Los métodos bayesianos, sin embargo, prueban hipótesis no rechazándolas o aceptándolas, sino calculando sus probabilidades de ser verdaderas. Así, los valores de P, los niveles de significancia y los intervalos de confianza son puntos discutidos (Dennis 1996). Con base en el conocimiento existente, los investigadores asignan probabilidades a priori a hipótesis alternativas y luego utilizan datos para calcular (“verificar”) probabilidades posteriores de las hipótesis con una función de verosimilitud (teorema de Bayes). La probabilidad más alta identifica la hipótesis que es la más probable de ser cierta dados los datos experimentales (Dennis 1996, Ellison 1996). La estadística bayesiana tiene varias características clave que difieren de las estadísticas frecuentistas clásicas:
- Bayes se basa en un mecanismo matemático explícito para actualizar y propagar la incertidumbre (teorema de Bayes)
- Los análisis bayesianos cuantifican las inferencias de una manera más simple e intuitiva. Esto es especialmente cierto en entornos de gestión que requieren tomar decisiones bajo incertidumbre
- Aprovecha los datos preexistentes y se puede utilizar con tamaños de muestra pequeños
Por ejemplo, las conclusiones de un análisis de monitoreo podrían enmarcarse como: “Existe un 65% de probabilidad de que la tala de claros afecte negativamente a esta especie”, o “La probabilidad de que esta población esté disminuyendo a una tasa de 3% anual es de 85%”. Una cobertura más profunda del uso de la inferencia bayesiana en ecología se puede encontrar en Dennis (1996), Ellison (1996), Taylor et al. (1996), Wade (2000) y O'Hara et al. (2002). Aunque la inferencia bayesiana es fácil de comprender y realizar, todavía es relativamente rara en aplicaciones de recursos naturales (aunque eso está cambiando rápidamente) y es posible que no haya suficientes recursos de apoyo para este tipo de pruebas. Se recomienda que sólo se implemente con la asistencia de un estadístico consultor.
Análisis Retrospectivo de Potencia
¿El resultado de una prueba estadística sugiere que no se produjo ningún cambio biológico real en el sitio de estudio? ¿Se produjo realmente el cambio pero no se detectó debido a una baja potencia de la prueba estadística utilizada, es decir, se cometió un error Tipo II (cambio perdido) en el proceso? Se recomienda que quienes realicen estudios de inventario evalúen rutinariamente la validez de los resultados de pruebas estadísticas realizando un análisis de potencia post hoc o retrospectivo por dos razones importantes:
- La posibilidad de aceptar falsamente la hipótesis nula es bastante real en los estudios ecológicos, y
- Los cálculos a priori del poder estadístico solo se realizan raramente en la práctica, pero son críticos para la interpretación y extrapolación de datos (Fowler 1990).
Un análisis de potencia es imperativo siempre que una prueba estadística resulte no significativa y no rechace la hipótesis nula (H 0); por ejemplo, si P > 0.05 a nivel de significancia del 95%. Existen diversas técnicas para llevar a cabo bien un análisis retrospectivo de potencia. Por ejemplo, deben realizarse únicamente utilizando un tamaño de efecto distinto al tamaño del efecto observado en el estudio (Hayes y Steidl 1997, Steidl et al. 1997). En otras palabras, los análisis de potencia post hoc solo pueden responder si el estudio realizado en su diseño original hubiera permitido detectar el tamaño del efecto recién seleccionado.
Elzinga et al. (2001) recomiendan el siguiente enfoque para realizar una evaluación de análisis de potencia post hoc (Figura 11.6). Si una prueba estadística se declarara no significativa, se podría calcular un valor de potencia para detectar un efecto de interés biológicamente significativo, generalmente un punto desencadenante vinculado a una acción gerencial. Si la potencia resultante es baja, se deben tomar medidas cautelares en el programa de monitoreo. Alternativamente, se puede calcular un tamaño mínimo de efecto detectable a un nivel de potencia seleccionado. Un nivel de potencia aceptable en los estudios de vida silvestre a menudo se establece en aproximadamente 0.80 (Hayes y Steidl 1997). Si la potencia seleccionada solo puede detectar un cambio que sea mayor que el valor del punto de activación, el resultado del estudio debe ser nuevamente visto con precaución.
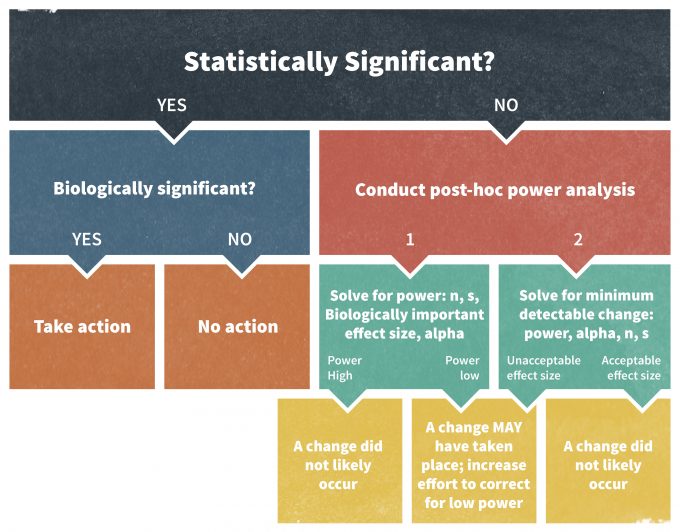
Los planes de monitoreo también pueden alentar el uso de intervalos de confianza como un enfoque alternativo para realizar un análisis de potencia post hoc. Este método es en realidad superior al análisis de potencia ya que los intervalos de confianza no solo sugieren si el efecto fue diferente o no de cero, sino que también proporcionan una estimación de la magnitud probable del tamaño del efecto verdadero y su significado biológico. En última instancia, para los esfuerzos científicos estas son reglas generales. En contextos de gestión, sin embargo, la toma de decisiones bajo incertidumbre donde los resultados tienen costos, cálculos de potencia y otras estimaciones de cantidades aceptables de incertidumbre deben abordarse de manera más rigurosa.
Resumen
Incluso antes de la recolección de datos, los investigadores deben considerar qué técnicas analíticas probablemente serán adecuadas para interpretar sus datos. Las técnicas serán altamente dependientes del diseño del programa de monitoreo, por lo que un plan de monitoreo debe articular claramente los enfoques analíticos esperados después de consultar con un biometrista. Después de la recolección de datos pero antes de realizar análisis estadísticos, a menudo es útil ver los datos gráficamente para comprender la estructura de los datos. Deben probarse los supuestos en los que se basan ciertas técnicas (por ejemplo, normalidad, independencia de observaciones y uniformidad de varianzas para análisis paramétricos). Algunas violaciones de supuestos pueden abordarse con transformaciones, mientras que otras pueden necesitar enfoques diferentes. Detectados/no detectados, los datos de conteo, las series temporales y los diseños de impacto de control antes-después tienen diferentes estructuras de datos y deberán analizarse de maneras muy diferentes. Dado el considerable margen para el análisis espurio y posterior interpretación errónea, de ser posible, se debe consultar a un biométrico/estadístico a lo largo de todo el proceso de análisis de datos.
Referencias
Agresti, A. 2002. Análisis de datos categóricos. 2ª edición. John Wiley & Sons, Nueva York, Nueva York.
Anderson, D.R. 2001. La necesidad de obtener lo básico correcto en los estudios de campo de vida silvestre. Boletín de la Sociedad de Vida Silvestre 29:1294-1297.
Anderson, D.R. 2008. Inferencia basada en modelos en las ciencias de la vida: una cartilla sobre la evidencia. Springer, Nueva York, Nueva York.
Anderson, D.R., K.P. Burnham, W.R. Gould, y S. Cherry. 2001. Preocupaciones por encontrar efectos que en realidad son espurios. Boletín de la Sociedad Widlife 29:311-316.
Anscombe, F.J. 1973. Gráficas en análisis estadístico. Estadístico Americano 27:17-21.
Böhning-Gaese, K., M.L. Taper, y J.H. Brown. 1993. Son descensos en pájaros cantores insectívoros norteamericanos por causas en el área de reproducción. Biología de la Conservación 7:76-86.
Bolker, B.M. 2008. Modelos y datos ecológicos en R. Princeton University Press, Princeton, Nueva Jersey. 408pp.
Bolker, B.M., M.E. Brooks, C.J. Clark, S.W. Geange, J.R. Poulsen, M.H.H. Stevens, y J.S.S. White. 2009. Modelos mixtos lineales generalizados: una guía práctica para la ecología y la evolución. Tendencias en Ecología y Evolución 24:127-135.
Burnham, K.P., y D.R. Anderson. 2002. Selección e inferencia de modelos: un enfoque práctico de la teoría de la información. Springer-Verlag, Nueva York, Nueva York, EUA. 454pp.
Carroll, R., C. Augspurger, A. Dobson, J. Franklin, G. Orians, W. Reid, R. Tracy, D. Wilcove, y J. Wilson. 1996. Fortalecer el uso de la ciencia en el logro de las metas del acto de especies amenazadas: Una evaluación de la Sociedad Ecológica de América. Aplicaciones Ecológicas 6:1-11.
Caughley, G. 1977. Análisis de poblaciones de vertebrados. John Wiley & Sons, Nueva York, Nueva York.
Caughley, G., y A. R. E. Sinclair. 1994. Manejo de vida silvestre y ecología. Blackwell Publishing, Malden, MA.
Cleveland, W.S. 1985. Los elementos de graficar datos. Wadsworth Libros Avanzados y Software, Monterey, Calif.
Cochran, W.G. 1977. Técnicas de muestreo. 3ª edición. John Wiley & Sons, Nueva York.
Conover, W.J. 1999. Estadística práctica no paramétrica. 3ª edición. Wiley, Nueva York.
Crawley, M.J. 2005. Estadística: una introducción usando R. John Wiley & Sons, Ltd, West Sussex, Inglaterra.
Crawley, M.J. 2007. El libro R. John Wiley & Sons, Ltd, Sussex del Oeste, Inglaterra.
Crowley, P.H. 1992. Métodos de remuestreo para análisis de datos intensivos en computación en ecología y evolución. Revisión Anual de Ecología y Sistemática 23:405-447.
Cunningham, R.B., y P. Olsen. 2009. Una metodología estadística para rastrear el cambio a largo plazo en las tasas de reporte de aves a partir de datos de presencia-ausencia recolectados por voluntarios. Biodiversidad y Conservación 18:1305-1327.
Day, R.W., y G.P. Quinn. 1989. Comparaciones de tratamientos después de un análisis de varianza en ecología. Monografías Ecológicas 59:433-463.
Dennis, B. 1996. Discusión: ¿Deberían los ecologistas convertirse en bayesianos? Aplicaciones Ecológicas 6:1095-1103.
Donovan, T.M., y J. Hines. 2007. Ejercicios de modelización y estimación de ocupación. www.uvm.edu/envnr/vtcfwru/spreadsheets/occupancy/occupancy.htm
Edgington, E.S., y P. Onghena. 2007. Pruebas de aleatorización. 4ª edición. Chapman & Hall/CRC, Boca Ratón, Florida.
Edwards, D., y B.C. Coull. 1987. Análisis de tendencias autorregresivas: un ejemplo que utiliza datos ecológicos a largo plazo. Oikos 50:95-102.
Ellison, A.M. 1996. Una introducción a la inferencia bayesiana para la investigación ecológica y la toma de decisiones ambientales. Aplicaciones Ecológicas 6:1036-1046.
Elzinga, C.L., D.W. Salzer, y J.W. Willoughby. 1998. Medición y monitoreo de poblaciones vegetales. Referencia Técnica 1730-1., Bureau of Land Management, National Business Center, Denver, CO.
Elzinga, C.L., D.W. Salzer, J.W. Willoughby, y J.P. Gibbs. 2001. Monitoreo de poblaciones vegetales y animales. Blackwell Science, Inc., Malden, Massachusetts.
Engelan, R.M. 2003. Más sobre la necesidad de acertar lo básico: índices de población. Boletín de la Sociedad de Vida Silvestre 31:286-287.
Lejos, J. J. 2006. Extendiendo el modelo lineal con R: modelos de regresión lineal generalizada, efectos mixtos y no paramétricos. Chapman & Hall/CRC, Boca Ratón.
Fortín, M.-J., y M.R.T. Dale. 2005. Análisis espacial: una guía para ecologistas. Cambridge University Press, Cambridge, Reino Unido; Nueva York.
Fowler, N. 1990. Los 10 errores estadísticos más comunes. Boletín de la Sociedad Ecológica de América 71:161-164.
Freeman, E.A., y G.G. Moisen. 2008. Una comparación del desempeño de los criterios de umbral para la clasificación binaria en términos de prevalencia predicha y kappa. Modelado Ecológico 217:48-58.
Geissler, P.H., y J.R. Sauer. 1990. Temas en análisis de regresión de ruta. Páginas 54-57 en J.R. Sauer y S.Droege, editores. Diseños de encuestas y métodos estadísticos para la estimación de las tendencias de la población aviar. Servicio de Pesca y Vida Silvestre del USDI, Washington, DC.
Gelman, A., y J. Hill. 2007. Análisis de datos mediante regresión y modelos multiniveles/jerárquicos. Cambridge University Press, Cambridge; Nueva York.
Gerrodette, T. 1987. Un análisis de potencia para detectar tendencias. Ecología 68:1364-1372.
Gibbs, J.P., S. Droege, y P. Eagle. 1998. Monitoreo de poblaciones de plantas y animales. Biociencia 48:935-940.
Gibbs, J.P., H.L. Snell, y C.E. Causton. 1999. Monitoreo efectivo para el manejo adaptativo de vida silvestre: Lecciones de las Islas Galápagos. Revista de Manejo de Vida Silvestre 63:1055-1065.
Gotelli, N.J., y A.M. Ellison. 2004. Una cartilla de estadística ecológica. Sinaeur, Sunderland, MA.
Verde, R.H. 1979. Diseño de muestreo y métodos estadísticos para biólogos ambientales. Wiley, Nueva York.
Gurevitch, J., J.A. Morrison, y L.V. Hedges. 2000. La interacción entre competencia y depredación: Un metaanálisis de experimentos de campo. Naturalista Americano 155:435-453.
Hall, D.B., y K.S. Berenhaut. 2002. Prueba de puntuación para heterogeneidad y sobredispersión en modelos de regresión binomial y Poisson inflados a cero. The Canadian Journal of Statistics 30:1-16.
Harrell, F.E. 2001. Estrategias de modelación de regresión con aplicaciones a modelos lineales, regresión logística y análisis de supervivencia. Springer, Nueva York.
Harris, R.B. 1986. Confiabilidad de las líneas de tendencia obtenidas de recuentos de variables. Revista de Manejo de Vida Silvestre 50:165-171.
Harris, R.B., y F.W. Allendorf. 1989. Tamaño de la población genéticamente efectiva de mamíferos grandes: una evaluación de estimadores. Biología de la Conservación 3:181-191.
Hayek, L.-A.C. y M.A. Buzas. 1997. Topografía de poblaciones naturales. Columbia University Press, Nueva York.
Hayes, J.P., y R.J. Steidl. 1997. Análisis estadístico de poder y tendencias poblacionales de anfibios. Biología de la Conservación 11:273-275.
Hedges, L.V., e I. Olkin. 1985. Métodos estadísticos para metaanálisis. Prensa Académica, Orlando.
Heilbron, D. 1994. Modelos de regresión alterados por cero y otros para datos de conteo con ceros añadidos. Revista Biométrica 36:531-547.
Hilbe, J. 2007. Regresión binomial negativa. Cambridge University Press, Cambridge; Nueva York.
Hilborn, R., y M. Mangel. 1997. El detective ecológico: confrontar modelos con datos. Prensa de la Universidad de Princeton, Princeton, Nueva Jersey.
Hollander, M., y D.A. Wolfe. 1999. Métodos estadísticos no paramétricos. 2ª edición. Wiley, Nueva York.
Hosmer, D.W., y S. Lemeshow. 2000. Regresión logística aplicada. 2ª edición. Wiley, Nueva York.
Huff, M.H., K.A. Bettinger, H.L. Ferguson, M.J. Brown, y B. Altman. 2000. Un protocolo de conteo puntual basado en hábitats para aves terrestres, enfatizando Washington y Oregón. USDA Forst Service Informe Técnico General, PNW-GTR-501.
Hullbert, S.H. 1984. Pseudoreplicación y diseño de experimentos ecológicos de campo. Monografías Ecológicas 54:187-211.
James, F.C., C.E. McCullogh, y D.A. Wiedenfeld. 1996. Nuevos enfoques para el análisis de tendencias poblacionales en aves terrestres. Ecología 77:13-27.
Johnson, D.H. 1995. Sirenas estadísticas — el atractivo de los no paramétricos. Ecología 76:1998-2000.
Johnson, D.H. 1999. La insignificancia de las pruebas de significancia estadística. Revista de Manejo de Vida Silvestre 63:763-772.
Kéry, M., J.A. Royle, M. Plattner, y R.M. Dorazio. 2009. Estimación de la riqueza y ocupación de especies en comunidades sujetas a emigración temporal. Ecología 90:1279-1290.
Kéry, M., J.A. Royle, y H. Schmid. 2008. Importancia del diseño de muestreo y análisis en estudios de población animal: un comentario sobre Sergio et al. Revista de Ecología Aplicada 45:981-986.
Kery, M., y H. Schmid. 2004. Los programas de monitoreo deben tomar en cuenta la detectabilidad de especies imperfectas. Ecología Básica y Aplicada 5:65-73.
Knapp, R.A., y K.R. Matthews. 2000. Introducciones de peces no nativos y disminución de la rana de patas amarillas de montaña desde dentro de áreas protegidas. Biología de la Conservación 14:428-438.
Krebs, C.J. 1999. Metodología ecológica. 2ª edición. Benjamin/Cummings, Menlo Park, Calif.
Lebreton, J.D., K.P. Burnham, J. Clobert, y D.R. Anderson. 1992. Modelar la supervivencia y probar hipótesis biológicas utilizando animales marcados, un enfoque unificado con estudios de casos. Monografías Ecológicas 62:67-118.
Link, W.A., y J.R. Sauer. 1997a. Estimación de trayectorias poblacionales a partir de datos de conteo. Biometría 53:488-497.
Link, W.A., y J.R. Sauer. 1997b. Nuevos enfoques para el análisis de tendencias poblacionales en aves terrestres: Comentario. Ecología 78:2632-2634.
Link, W.A., y J.R. Sauer. 2007. Componentes estacionales del cambio poblacional aviar: análisis conjunto de dos programas de monitoreo a gran escala. Ecología 88:49-55.
Lorda, E., y S.B. Saila. 1986. Técnica estadística para el análisis de datos ambientales que contienen componentes de varianza periódica. Modelado Ecológico 32:59-69.
MacKenzie, D.I. 2005. ¿Cuáles son los problemas con los datos de presencia-ausencia para los administradores de vida silvestre? Diario de Manejo de Vida Silvestre 69:849-860.
MacKenzie, D.I., J.D. Nichols, J.A. Royle, K.H. Pollock, L.L. Bailey, y J.E. Hines. 2006. Estimación y modelación de la ocupación: inferir patrones y dinámicas de ocurrencia de especies. Elsevier Academic Press, Burlingame, MA.
MacKenzie, D.I., L.L. Bailey, y J.D. Nichols. 2004. Investigar patrones de coocurrencia de especies cuando las especies son detectadas imperfectamente. Revista de Ecología Animal 73:546-555.
MacKenzie, D.I., J.D. Nichols, J.E. Hines, M.G. Knutson, y A.B. Franklin. 2003. Estimar la ocupación del sitio, la colonización y la extinción local cuando una especie se detecta imperfectamente. Ecología 84:2200-2207.
MacKenzie, D.I., J.D. Nichols, G.B. Lachman, S. Droege, J.A. Royle, y C.A. Langtimm. 2002. Estimar las tasas de ocupación del sitio cuando las probabilidades de detección son menores a una. Ecología 83:2248-2255.
MacKenzie, D.I., J.D. Nichols, M.E. Seamans, y R.J. Gutierrez. 2009. Modelado de dinámicas de ocurrencia de especies con múltiples estados y detección imperfecta. Ecología 90:823-835.
MacKenzie, D.I., J.D. Nichols, N. Sutton, K. Kawanishi, y L.L. Bailey. 2005. Mejorando las inferencias en estudios de popoulación de especies raras que se detectan imperfectamente. Ecología 86:1101-1113.
Mackenzie, D.I., y J.A. Royle. 2005. Diseño de estudios de ocupación: asesoría general y asignación de esfuerzos de levantamiento. Revista de Ecología Aplicada 42:1105-1114.
Magurran, A.E. 1988. Diversidad ecológica y su medición. Prensa de la Universidad de Princeton, Princeton, N.J.
McCulloch, C.E., S.R. Searle, y J.M. Neuhaus. 2008. Modelos generalizados, lineales y mixtos. 2ª edición. Wiley, Hoboken, N.J.
Nichols, J.D. 1992. Modelos de captura-recaptura. Biociencia 42:94-102.
Nichols, J.D., y W.L. Kendall. 1995. El uso de modelos multiestatales de captura-recaptura para abordar cuestiones de ecología evolutiva. Revista de Estadística Aplicada 22:835-846.
O'Hara, R.B., E. Arjas, H. Toivonen, e I. Hanski. 2002. Análisis bayesiano de datos de metapopulación. Ecología 83:2408-2415.
Petraitis, P.S., S.J. Beaupre, y A.E. Dunham. 2001. ANCOVA: abordajes no paramétricos y de aleatorización. Páginas 116-133 en S.M. Scheiner y J. Gurevitch, editores. Diseño y análisis de experimentos ecológicos. Oxford University Press, Oxford, Nueva York.
Pollock, K.H., J.D. Nichols, T.R. Simons, G.L. Farnsworth, L.L. Bailey, y J.R. Sauer. 2002. Estudios de monitoreo de vida silvestre a gran escala: métodos estadísticos para el diseño y análisis. Ambimetría 13:105-119.
Potvin, C., y D.A. Roff. 1993. Métodos estadísticos robustos y libres de distribución: alternativas viables a la estadística paramétrica. Ecología 74:1617-1628.
Power, M.E., y L.S. Mills. 1995. Los policías clave se encuentran en Hilo. Tendencias en Ecología y Evolución 10:182-184.
Quinn, G.P., y M.J. Keough. 2002. Diseño experimental y análisis de datos para biólogos. Cambridge University Press, Cambridge, Reino Unido.
Robbins, C.S. 1990. Uso de atlas de aves reproductoras para monitorear el cambio poblacional. Páginas 18-22 en J.R. Sauer y S. Droege, editores. Diseños de encuestas y métodos estadísticos para la estimación de las tendencias de la población aviar. Servicio de Pesca y Vida Silvestre del USDI, Washington, DC.
Rosenstock, S.S., D.R. Anderson, K.M. Giesen, T. Leukering, y M.F. Carter. 2002. Técnicas de conteo de aves terrestres: Prácticas actuales y una alternativa. Auk 119:46-53.
Rotella, J.J., J.T. Ratti, K.P. Reese, M.L. Taper, y B. Dennis. 1996. Análisis poblacional a largo plazo de perdiz gris en el oriente de Washington. Revista de Manejo de Vida Silvestre 60:817-825.
Royle, J.A., y R.M. Dorazio. 2008. Modelado hiearchal e inferencia en ecología: el análisis de datos de poblaciones, metapopulaciones y comunidades. Prensa Académica, Boston, Ma.
Royle, J.A., M. Kery, R. Gautier, y H. Schmid. 2007. Modelos espaciales jerárquicos de abundancia y ocurrencia a partir de datos de levantamiento imperfectos. Monografías Ecológicas 77:465-481.
Sabin, T.E., y S.G. Stafford. 1990. Evaluar la necesidad de transformación de variables de respuesta. Laboratorio de Investigación Forestal, Universidad Estatal de Oregón, Corvallis, Oregón.
Sauer, J.R., G.W. Pendleton, y B G. Peterjohn. 1996. Evaluación de las causas del cambio poblacional en pájaros cantores insectívoros norteamericanos. Biología de la Conservación 10:465-478.
Scheiner, S.M., y J. Gurevitch. 2001. Diseño y análisis de experimentos ecológicos. 2ª edición. Oxford University Press, Oxford, Reino Unido.
Schratzberger, M., T.A. Dinmore, y S. Jennings. 2002. Impactos de la pesca de arrastre en la diversidad, biomasa y estructura de ensamblajes de meiofauna. Biología Marina 140:83-93.
Sokal, R. R., y F. J. Rohlf. 1994. Biometría; principios y práctica de la estadística en la investigación biológica. 3ª edición. W. H. Freeman, San Francisco, CA.
Southwood, R. 1992. Métodos ecológicos, con particular referencia al estudio de poblaciones de insectos. Methuen, Londres, Reino Unido.
Stanley, T.R., y F.L. Knopf. 2002. Respuestas aviares al pastoreo tardío en una llanura aluvial arbustiva y sauce. Biología de la Conservación 16:225-231.
Steidl, R.J., J.P. Hayes, y E. Schauber. 1997. Análisis estadístico de potencia en la investigación de vida silvestre. Revista de Manejo de Vida Silvestre 61:270-279.
Steidl, R.J., y L. Thomas. 2001. Análisis de potencia y diseño experimental. Páginas 14-36 en S. M. Scheiner y J. Gurevitch, editores. Diseño y análisis de experimentos ecológicos. Oxford University Press, Reino Unido.
Stephens, P.A., S.W. Buskirk, y C. Martínez del Río. 2006. Inferencia en ecología y evolución. Tendencias en Ecología y Evolución 22:192-197.
Stewart-Oaten, A., W.W. Murdoch, y K.R. Parker. 1986. Evaluación de impacto ambiental — pseudoreplicación en el tiempo. Ecología 67:929-940.
Taylor, B.L., P.R. Wade, R.A. Stehn, y J.F. Cochrane. 1996. Una aproximación bayesiana a los criterios de clasificación para eiders de anteojos. Aplicaciones Ecológicas 6:1077-1089.
Temple, S., y J.R. Cary. 1990. Usar registros de lista de verificación para revelar tendencias en las poblaciones de aves. Páginas 98-104 en J.R. Sauer y S. Droege, editores. Diseños de encuestas y métodos estadísticos para la estimación de las tendencias de la población aviar. Servicio de Pesca y Vida Silvestre del USDI, Washington, DC.
Thomas, L. 1996. Seguimiento del cambio poblacional a largo plazo: ¿Por qué hay tantos métodos de análisis? Ecología 77:49-58.
Thomas, L., y K. Martin. 1996. La importancia del método de análisis para las estimaciones de tendencias poblacionales de encuestas de aves reproductoras Biología de la Conservación 10:479-490.
Thompson, S.K. 2002. Muestreo. 2ª edición. Wiley, Nueva York.
Thompson, W.L. 2004. Muestreo de especies raras o esquivas: conceptos, diseños y técnicas para estimar parámetros poblacionales. Island Press, Washington.
Thompson, W.L., G.C. White, y C. Gowan. 1998. Monitoreo de poblaciones de vertebrados. Prensa Académica, San Diego, Calif.
Thomson, D.L., M.J. Conroy, y E.G. Cooch, editores. 2009. Modelación de procesos demográficos en poblaciones marcadas. Springer, Nueva York.
Trexler, J.C. y J. Travis. 1993. Análisis de regresión no tradicional. Ecología 74:1629-1637.
Tufte, E.R. 2001. La visualización de la información cuantitativa. 2ª edición. Prensa Gráfica, Cheshire, Conn.
Tukey, J.W. 1977. Análisis exploratorio de datos. Pub Addison-Wesley. Co., Lectura, Misa.
Underwood, A.J. 1994. Más allá de BACI: diseños de muestreo que podrían detectar de manera confiable perturbaciones ambientales. Aplicaciones Ecológicas 4:3-15.
Underwood, A.J. 1997. Experimentos en ecología: Su diseño lógico e interpretación mediante análisis de varianza. Cambridge University Pres, Nueva York, Nueva York.
Wade, P.R. 2000. Métodos bayesianos en biología de la conservación. Biología de la Conservación 14:1308-1316.
Wardell-Johnson, G., y M. Williams. 2000. Bordes y brechas en el bosque maduro de karri, suroeste de Australia: efectos de tala en la abundancia y diversidad de especies de aves. Ecología y Manejo Forestal 131:1-21.
Welsh, A.H., R.B. Cunningham, C.F. Donnelly, y D.B. Lindenmayer. 1996. Modelización de la abundancia de especies raras: Modelos estadísticos para recuentos con ceros adicionales. Modelado Ecológico 88:297-308.
White, G.C., y R.E. Bennetts. 1996. Análisis de los datos de conteo de frecuencias utilizando la distribución binomial negativa. Ecología 77:2549-2557.
White, G.C., W.L. Kendall, y R.J. Barker. 2006. Modelos multiestatales de supervivencia y sus extensiones en el Programa MARK. Diario de Manejo de Vida Silvestre 70:1521 —1529.
Williams, B.K., J.D. Nichols, y M.J. Conroy. 2002. Análisis y manejo de poblaciones animales: modelación, estimación y toma de decisiones. Prensa Académica, San Diego.
Yoccoz, N.G., J.D. Nichols, y T. Boulinier. 2001. Monitoreo de la diversidad biológica en el espacio y el tiempo. Tendencias en Ecología y Evolución 16:446-453.
Zar, J.H. 1999. Análisis bioestadístico. 4ª edición. Prentice Hall, Upper Saddle River, N.J.
Zuckerberg, B., W.F. Porter, y K. Corwin. 2009. La consistencia y estabilidad de las relaciones abundancia-ocupación en dinámicas poblacionales a gran escala. Revista de Ecología Animal 78:172-181.
Zuur, A. 2009. Modelos de efectos mixtos y extensiones en ecología con R. 1a edición. Springer, Nueva York.
Zuur, A. F., E. N. Ieno, y G. M. Smith. 2007. Análisis de datos ecológicos. Springer, Nueva York; Londres.