
2.2: Los psicólogos utilizan diseños de investigación descriptiva, correlacional y experimental para comprender el comportamiento
- Page ID
- 143366
Objetivos de aprendizaje
- Diferenciar los objetivos de los diseños de investigación descriptiva, correlacional y experimental y explicar las ventajas y desventajas de cada uno.
- Explicar los objetivos de la investigación descriptiva y las técnicas estadísticas utilizadas para interpretarla.
- Resumir los usos de la investigación correlacional y describir por qué la investigación correlacional no puede ser utilizada para inferir causalidad.
- Revisar los procedimientos de la investigación experimental y explicar cómo se puede utilizar para extraer inferencias causales.
Los psicólogos coinciden en que para que sus ideas y teorías sobre el comportamiento humano sean tomadas en serio, deben estar respaldadas por datos. Sin embargo, la investigación de diferentes psicólogos está diseñada con diferentes objetivos en mente, y los diferentes objetivos requieren diferentes enfoques. Estos enfoques variables, resumidos en Tabla\(\PageIndex{2}\), se conocen como diseños de investigación. Un diseño de investigación es el método específico que utiliza un investigador para recopilar, analizar e interpretar datos. Los psicólogos utilizan tres tipos principales de diseños de investigación en sus investigaciones, y cada uno proporciona una vía esencial para la investigación científica. La investigación descriptiva es una investigación diseñada para proporcionar una instantánea del estado actual de las cosas. La investigación correlacional es una investigación diseñada para descubrir relaciones entre variables y permitir la predicción de eventos futuros a partir del conocimiento presente. La investigación experimental es una investigación en la que se crea la equivalencia inicial entre los participantes de la investigación en más de un grupo, seguida de una manipulación de una experiencia dada para estos grupos y una medición de la influencia de la manipulación. Cada uno de los tres diseños de investigación varía según sus fortalezas y limitaciones, y es importante entender en qué se diferencia cada uno.
| Diseño de investigación | Gol | Ventajas | Desventajas |
|---|---|---|---|
| Descriptivo | Para crear una instantánea del estado actual de las cosas | Proporciona una imagen relativamente completa de lo que está ocurriendo en un momento dado. Permite el desarrollo de preguntas para su posterior estudio. | No evalúa las relaciones entre variables. Puede ser poco ético si los participantes no saben que están siendo observados. |
| Correlacional | Evaluar las relaciones entre y entre dos o más variables | Permite probar las relaciones esperadas entre y entre variables y la realización de predicciones. Puede evaluar estas relaciones en los acontecimientos de la vida cotidiana. | No se puede utilizar para hacer inferencias sobre las relaciones causales entre y entre las variables. |
| Experimental | Evaluar el impacto causal de una o más manipulaciones experimentales sobre una variable dependiente | Permite sacar conclusiones sobre las relaciones causales entre variables. | No se pueden manipular experimentalmente muchas variables importantes. Puede ser costoso y consumir mucho tiempo. |
| Hay tres grandes diseños de investigación utilizados por los psicólogos, y cada uno tiene sus propias ventajas y desventajas. Stangor, C. (2011). Métodos de investigación para las ciencias del comportamiento (4ª ed.). Mountain View, CA: Cengage. | |||
Investigación descriptiva: Evaluación del estado actual de las cosas
La investigación descriptiva está diseñada para crear una instantánea de los pensamientos, sentimientos o comportamientos actuales de los individuos. En esta sección se revisan tres tipos de investigación descriptiva: estudios de casos, encuestas y observación naturalista.
A veces los datos de un proyecto de investigación descriptiva se basan en solo un pequeño conjunto de individuos, a menudo solo una persona o un solo grupo pequeño. Estos diseños de investigación se conocen como estudios de casos, registros descriptivos de una o más experiencias y comportamientos individuales. A veces los estudios de casos involucran a individuos comunes, como cuando el psicólogo del desarrollo Jean Piaget utilizó su observación de sus propios hijos para desarrollar su teoría escénica del desarrollo cognitivo. Con mayor frecuencia, se realizan estudios de casos en individuos que tienen experiencias o características inusuales o anormales o que se encuentran en situaciones particularmente difíciles o estresantes. El supuesto es que al estudiar cuidadosamente a individuos que son socialmente marginales, que están viviendo situaciones inusuales, o que están pasando por una fase difícil en sus vidas, podemos aprender algo sobre la naturaleza humana.
Sigmund Freud fue un maestro en el uso de las dificultades psicológicas de los individuos para sacar conclusiones sobre los procesos psicológicos básicos. Freud escribió estudios de caso de algunos de sus pacientes más interesantes y utilizó estos cuidadosos exámenes para desarrollar sus importantes teorías de la personalidad. Un ejemplo clásico es la descripción de Freud de “Little Hans”, un niño cuyo miedo a los caballos interpretó el psicoanalista en términos de impulsos sexuales reprimidos y el complejo de Edipo (Freud (1909/1964).

Otro caso de estudio bien conocido es Phineas Gage, un hombre cuyos pensamientos y emociones fueron ampliamente estudiados por psicólogos cognitivos luego de que una espiga de ferrocarril le atravesara el cráneo en un accidente. Aunque existe duda sobre la interpretación de este estudio de caso (Kotowicz, 2007), sí aportó evidencia temprana de que el lóbulo frontal del cerebro está involucrado en la emoción y la moral (Damasio et al., 2005). Un ejemplo interesante de un estudio de caso en psicología clínica es descrito por Rokeach (1964), quien investigó en detalle las creencias e interacciones entre tres pacientes con esquizofrenia, todos los cuales estaban convencidos de que eran Jesucristo.
En otros casos los datos de proyectos de investigación descriptiva vienen en forma de encuesta, una medida administrada a través de una entrevista o un cuestionario escrito para obtener una imagen de las creencias o comportamientos de una muestra de personas de interés. Las personas elegidas para participar en la investigación (conocida como la muestra) son seleccionadas para ser representativas de todas las personas que el investigador desea conocer (la población). En las encuestas electorales, por ejemplo, se toma una muestra de la población de todos los “probables votantes” en las próximas elecciones.
Los resultados de las encuestas a veces pueden ser bastante mundanos, como “Nueve de cada diez médicos prefieren Tymenocin” o “El ingreso medio en el condado de Montgomery es de 36 mil 712 dólares”. Sin embargo, en otras ocasiones (particularmente en las discusiones sobre el comportamiento social), los resultados pueden ser impactantes: “Más de 40 mil personas mueren por disparos en Estados Unidos cada año”, o “Más del 60% de las mujeres entre las edades de 50 y 60 años sufren de depresión”. La investigación descriptiva es utilizada frecuentemente por psicólogos para obtener una estimación de la prevalencia (o incidencia) de trastornos psicológicos.
Un último tipo de investigación descriptiva, conocida como observación naturalista, es la investigación basada en la observación de eventos cotidianos. Por ejemplo, un psicólogo del desarrollo que vigila a los niños en un patio de recreo y se describe lo que se dicen mientras juegan está realizando una investigación descriptiva, al igual que un biopsicólogo que observa a los animales en sus hábitats naturales. Un ejemplo de investigación observacional involucra un procedimiento sistemático conocido como la extraña situación, utilizado para hacerse una idea de cómo interactúan adultos y niños pequeños. Los datos que se recogen en la extraña situación se codifican sistemáticamente en una hoja de codificación como la que se muestra en la Tabla\(\PageIndex{3}\).
| Nombre del codificador: Olive | ||||
|---|---|---|---|---|
| Codificación de categorías | ||||
| Episodio | Proximidad | Contacto | Resistencia | Evitación |
| Madre y bebé juegan solos | 1 | 1 | 1 | 1 |
| Madre pone bebé abajo | 4 | 1 | 1 | 1 |
| Extraño entra habitación | 1 | 2 | 3 | 1 |
| Madre deja habitación; extraño juega con bebé | 1 | 3 | 1 | 1 |
| La madre vuelve a entrar, saluda y puede consolar al bebé, luego se va de nuevo | 4 | 2 | 1 | 2 |
| Extraño intenta jugar con bebé | 1 | 3 | 1 | 1 |
| Madre vuelve a entrar y recoge bebé | 6 | 6 | 1 | 2 |
| Explicación de categorías de codificación | ||||
| Proximidad | El bebé se mueve hacia el adulto, agarra o sube sobre él. | |||
| Mantener el contacto | El bebé se resiste a ser abatido por el adulto llorando o tratando de volver a subir. | |||
| Resistencia | El bebé empuja, golpea o se retuerce para ser bajado de los brazos del adulto. | |||
| Evitación | El bebé se da la vuelta o se aleja del adulto. | |||
| Esta tabla representa una hoja de codificación de muestra de un episodio de la “extraña situación”, en la que se observa a un bebé (generalmente de aproximadamente 1 año de edad) jugando en una habitación con dos adultos: la madre del niño y un extraño. Cada una de las cuatro categorías de codificación es calificada por el codificador de 1 (el bebé no hace ningún esfuerzo para participar en el comportamiento) a 7 (el bebé hace un esfuerzo significativo para participar en el comportamiento). Puede encontrar más información sobre el significado de la codificación en Ainsworth, Blehar, Waters y Wall (1978). Stangor, C. (2011). Métodos de investigación para las ciencias del comportamiento (4ª ed.). Mountain View, CA: Cengage. | ||||
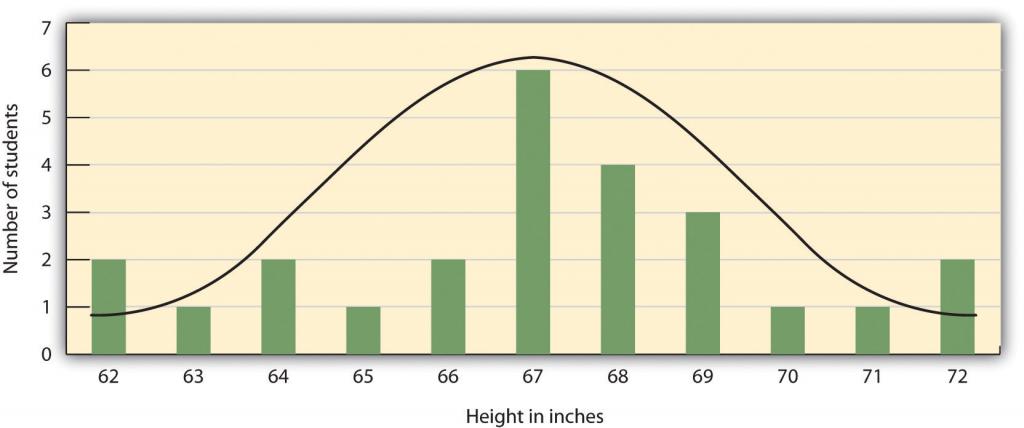
Los resultados de los proyectos de investigación descriptiva se analizan mediante estadísticas descriptivas, números que resumen la distribución de puntajes en una variable medida. La mayoría de las variables tienen distribuciones similares a las que se muestran en la Figura\(\PageIndex{5}\), donde la mayoría de las puntuaciones se encuentran cerca del centro de la distribución, y la distribución es simétrica y en forma de campana. Una distribución de datos que tiene forma de campana se conoce como una distribución normal.
| Nombre del alumno | Altura en pulgadas | Ingresos familiares en dólares |
|---|---|---|
| Lauren | 62 | 48,000 |
| Courtnie | 62 | 57,000 |
| Leslie | 63 | 93,000 |
| Renee | 64 | 107,000 |
| Katherine | 64 | 110,000 |
| Jordania | 65 | 93,000 |
| Rabiah | 66 | 46,000 |
| Alina | 66 | 84,000 |
| Joven Su | 67 | 68,000 |
| Martin | 67 | 49,000 |
| Hanzhu | 67 | 73.000 |
| Caitlin | 67 | 3,800,000 |
| Steven | 67 | 107,000 |
| Emily | 67 | 64,000 |
| Amy | 68 | 67,000 |
| Jonathan | 68 | 51,000 |
| Julian | 68 | 48,000 |
| Alissa | 68 | 93,000 |
| Christine | 69 | 93,000 |
| Candace | 69 | 111,000 |
| Xiaohua | 69 | 56,000 |
| Charlie | 70 | 94,000 |
| Timoteo | 71 | 73.000 |
| Ariane | 72 | 70,000 |
| Logan | 72 | 44,000 |
Una distribución se puede describir en términos de su tendencia central, es decir, el punto en la distribución alrededor del cual se centran los datos, y su dispersión o propagación. El promedio aritmético, o media aritmética, es la medida de tendencia central más utilizada. Se calcula calculando la suma de todas las puntuaciones de la variable y dividiendo esta suma por el número de participantes en la distribución (denotada por la letra N). En los datos presentados en la Figura\(\PageIndex{5}\), la estatura media de los estudiantes es de 67.12 pulgadas. La media de la muestra suele indicarse con la letra M.
En algunos casos, sin embargo, la distribución de datos no es simétrica. Esto ocurre cuando hay una o más puntuaciones extremas (conocidas como valores atípicos) en un extremo de la distribución. Consideremos, por ejemplo, la variable de ingreso familiar (Figura\(\PageIndex{6}\)), que incluye un valor atípico (un valor de $3,800,000). En este caso la media no es una buena medida de tendencia central. Si bien de la Figura se desprende\(\PageIndex{6}\) que la tendencia central de la variable de ingreso familiar debe rondar los $70,000, el ingreso familiar promedio es en realidad de 223,960 dólares. El ingreso único muy extremo tiene un impacto desproporcionado en la media, resultando en un valor que no representa bien la tendencia central.
La mediana se utiliza como medida alternativa de tendencia central cuando las distribuciones no son simétricas. La mediana es la puntuación en el centro de la distribución, lo que significa que el 50% de las puntuaciones son mayores que la mediana y el 50% de las puntuaciones son menores que la mediana. En nuestro caso, el ingreso familiar promedio ($73,000) es un indicador mucho mejor de tendencia central que el ingreso promedio de los hogares (223,960 dólares).
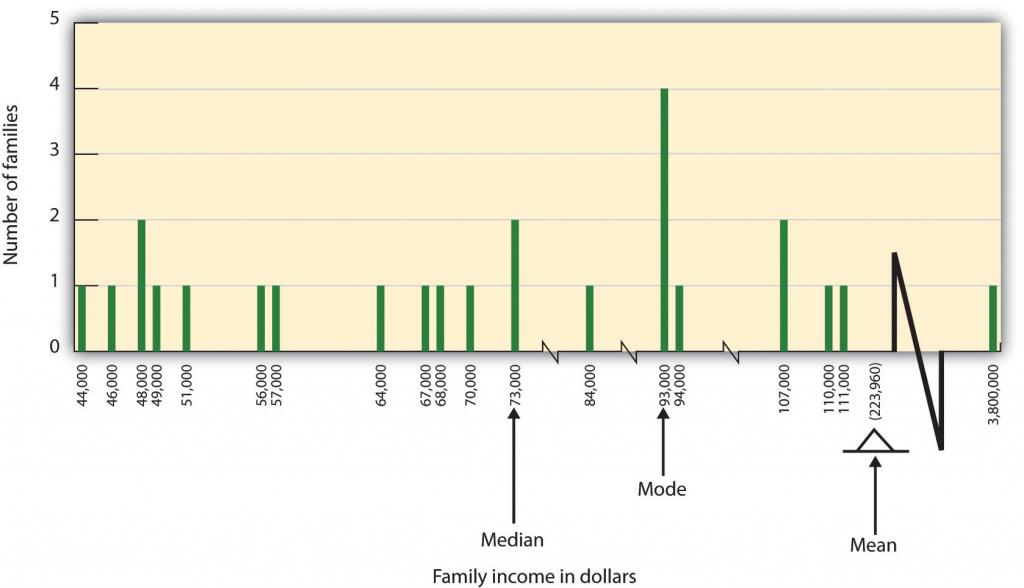
Una medida final de tendencia central, conocida como el modo, representa el valor que ocurre con mayor frecuencia en la distribución. Se puede ver en Figura\(\PageIndex{6}\) que el modo para la variable de ingresos familiares es de $93,000 (ocurre cuatro veces).
Además de resumir la tendencia central de una distribución, las estadísticas descriptivas transmiten información sobre cómo las puntuaciones de la variable se distribuyen alrededor de la tendencia central. La dispersión se refiere a la medida en que las puntuaciones se agrupan estrechamente alrededor de la tendencia central, así:
O pueden estar más alejados de él, así:
Una simple medida de dispersión es encontrar el mayor (el máximo) y el menor (el mínimo) valores observados de la variable y calcular el rango de la variable como la puntuación máxima observada menos la puntuación mínima observada. Se puede comprobar que el rango de la variable de altura en la Figura\(\PageIndex{5}\) es 72 — 62 = 10. La desviación estándar, simbolizada como s, es la medida de dispersión más utilizada. Las distribuciones con una desviación estándar mayor tienen más dispersión. La desviación estándar de la variable estatura es s = 2.74, y la desviación estándar de la variable ingreso familiar es s = $745,337.
Una ventaja de la investigación descriptiva es que intenta capturar la complejidad del comportamiento cotidiano. Los estudios de casos proporcionan información detallada sobre una sola persona o un pequeño grupo de personas, las encuestas capturan los pensamientos o comportamientos reportados de una gran población de personas, y la observación naturalista registra objetivamente el comportamiento de las personas o animales tal como ocurre naturalmente. Por lo tanto, se utiliza la investigación descriptiva para proporcionar una comprensión relativamente completa de lo que está sucediendo actualmente.
A pesar de estas ventajas, la investigación descriptiva tiene una clara desventaja en el sentido de que, aunque nos permite hacernos una idea de lo que ocurre actualmente, generalmente se limita a imágenes estáticas. Aunque las descripciones de experiencias particulares pueden ser interesantes, no siempre son transferibles a otros individuos en otras situaciones, ni nos dicen exactamente por qué ocurrieron comportamientos o eventos específicos. Por ejemplo, las descripciones de individuos que han sufrido un evento estresante, como una guerra o un terremoto, pueden usarse para comprender las reacciones de los individuos ante el evento pero no pueden decirnos nada sobre los efectos a largo plazo del estrés. Y como no hay un grupo de comparación que no haya experimentado la situación estresante, no podemos saber cómo serían estos individuos si no hubieran tenido la experiencia estresante.
Investigación correlacional: búsqueda de relaciones entre variables
En contraste con la investigación descriptiva, que está diseñada principalmente para proporcionar imágenes estáticas, la investigación correlacional implica la medición de dos o más variables relevantes y una evaluación de la relación entre esas variables o entre ellas. Por ejemplo, las variables de estatura y peso están sistemáticamente relacionadas (correlacionadas) porque las personas más altas generalmente pesan más que las personas más bajas. De la misma manera, también se relacionan los errores de tiempo de estudio y memoria, porque cuanto más tiempo se le da a una persona para estudiar una lista de palabras, menos errores cometerá. Cuando hay dos variables en el diseño de la investigación, una de ellas se denomina variable predictora y la otra variable de resultado. El diseño de la investigación se puede visualizar así, donde la flecha curva representa la correlación esperada entre las dos variables:

Una forma de organizar los datos de un estudio correlacional con dos variables es graficar los valores de cada una de las variables medidas utilizando un diagrama de dispersión. Como puede ver en la Figura\(\PageIndex{10}\), un diagrama de dispersión es una imagen visual de la relación entre dos variables. Se traza un punto para cada individuo en la intersección de sus puntuaciones para las dos variables. Cuando la asociación entre las variables en el diagrama de dispersión se puede aproximar fácilmente con una línea recta, como en las partes (a) y (b) de la Figura\(\PageIndex{10}\), se dice que las variables tienen una relación lineal.
Cuando la línea recta indica que los individuos que tienen valores superiores a la media para una variable también tienden a tener valores por encima del promedio para la otra variable, como en la parte (a), se dice que la relación es lineal positiva. Ejemplos de relaciones lineales positivas incluyen aquellas entre estatura y peso, entre educación e ingresos, y entre edad y habilidades matemáticas en niños. En cada caso, las personas que obtienen una puntuación más alta en una de las variables también tienden a obtener una puntuación más alta en la otra variable. Las relaciones lineales negativas, en contraste, como se muestra en la parte (b), ocurren cuando los valores por encima del promedio para una variable tienden a asociarse con valores por debajo del promedio para la otra variable. Ejemplos de relaciones lineales negativas incluyen aquellas entre la edad de un niño y el número de pañales que usa, y entre la práctica y los errores cometidos en una tarea de aprendizaje. En estos casos, las personas que obtienen una puntuación más alta en una de las variables tienden a anotar más bajas en la otra variable.
Las relaciones entre variables que no pueden describirse con una línea recta se conocen como relaciones no lineales. La parte (c) de la Figura\(\PageIndex{10}\) muestra un patrón común en el que la distribución de los puntos es esencialmente aleatoria. En este caso no existe ninguna relación entre las dos variables, y se dice que son independientes. Las partes (d) y (e) de la Figura\(\PageIndex{10}\) muestran patrones de asociación en los que, aunque existe una asociación, los puntos no están bien descritos por una sola línea recta. Por ejemplo, la parte (d) muestra el tipo de relación que ocurre frecuentemente entre la ansiedad y el desempeño. Los aumentos en la ansiedad de niveles bajos a moderados se asocian con aumentos en el rendimiento, mientras que los aumentos en la ansiedad de niveles moderados a altos se asocian con disminuciones en el rendimiento. Las relaciones que cambian de dirección y por lo tanto no son descritas por una sola línea recta se denominan relaciones curvilíneas.
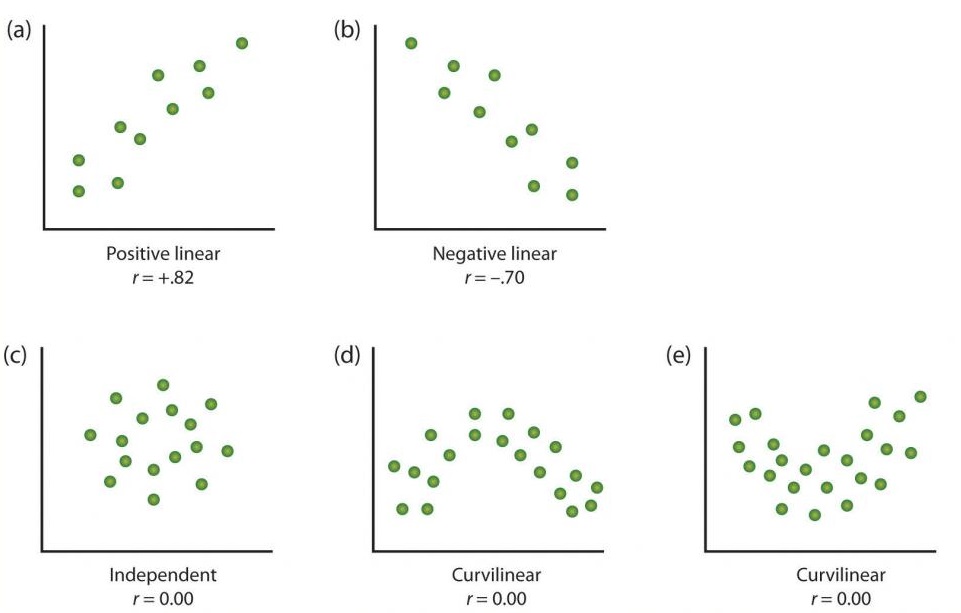
La medida estadística más común de la fuerza de las relaciones lineales entre variables es el coeficiente de correlación de Pearson, que está simbolizado por la letra r. El valor del coeficiente de correlación varía de r = —1.00 a r = +1.00. La dirección de la relación lineal está indicada por el signo del coeficiente de correlación. Los valores positivos de r (como r = 0.54 o r = 0.67) indican que la relación es lineal positiva (es decir, el patrón de los puntos en el gráfico de dispersión va desde la parte inferior izquierda hasta la parte superior derecha), mientras que los valores negativos de r (como r = —0 .30 o r = —0.72) indican relaciones lineales negativas (es decir, los puntos van desde la parte superior izquierda hasta la parte inferior derecha). La fuerza de la relación lineal es indexada por la distancia del coeficiente de correlación desde cero (su valor absoluto). Por ejemplo, r = -0.54 es una relación más fuerte que r = 0.30, y r = 0.72 es una relación más fuerte que r = —0.57. Debido a que el coeficiente de correlación de Pearson solo mide las relaciones lineales, las variables que tienen relaciones curvilíneas no están bien descritas por r, y la correlación observada será cercana a cero.
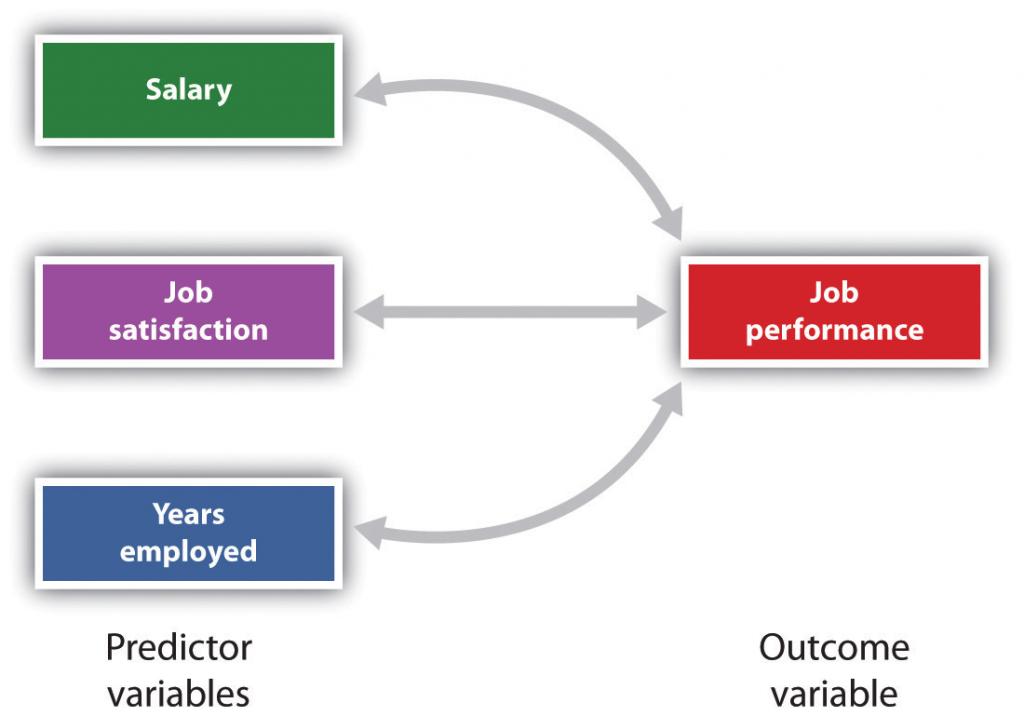
También es posible estudiar las relaciones entre más de dos medidas al mismo tiempo. Se analiza un diseño de investigación en el que se utiliza más de una variable predictora para predecir una única variable de resultado mediante regresión múltiple (Aiken & West, 1991). La regresión múltiple es una técnica estadística, basada en coeficientes de correlación entre variables, que permite predecir una única variable de resultado a partir de más de una variable predictora. Por ejemplo, la Figura\(\PageIndex{11}\) muestra un análisis de regresión múltiple en el que se utilizan tres variables predictoras para predecir un solo resultado. El uso del análisis de regresión múltiple muestra una ventaja importante de los diseños de investigación correlacional: se pueden usar para hacer predicciones sobre la puntuación probable de una persona en una variable de resultado (por ejemplo, desempeño laboral) basada en el conocimiento de otras variables.
Una limitación importante de los diseños de investigación correlacional es que no pueden ser utilizados para sacar conclusiones sobre las relaciones causales entre las variables medidas. Consideremos, por ejemplo, a un investigador que haya planteado la hipótesis de que ver comportamientos violentos provocará un mayor juego agresivo en los niños. Ha recopilado, a partir de una muestra de niños de cuarto grado, una medida de cuántos programas de televisión violentos ve cada niño durante la semana, así como una medida de cuán agresivamente juega cada niño en el patio de recreo de la escuela. A partir de sus datos recopilados, el investigador descubre una correlación positiva entre las dos variables medidas.
Si bien esta correlación positiva parece apoyar la hipótesis del investigador, no se puede tomar para indicar que ver televisión violenta provoca un comportamiento agresivo. Si bien el investigador se siente tentado a asumir que ver televisión violenta provoca un juego agresivo,
 Figura\(\PageIndex{2}\) .2
Figura\(\PageIndex{2}\) .2hay otras posibilidades. Una posibilidad alternativa es que la dirección causal sea exactamente opuesta a lo que se ha planteado la hipótesis. Quizás los niños que se han comportado agresivamente en la escuela desarrollen una excitación residual que los lleva a querer ver programas violentos de televisión en casa:
 Figura\(\PageIndex{2}\) .2
Figura\(\PageIndex{2}\) .2Si bien esta posibilidad puede parecer menos probable, no hay manera de descartar la posibilidad de tal causalidad inversa sobre la base de esta correlación observada. También es posible que ambas direcciones causales estén operando y que las dos variables se causen entre sí:
 Figura\(\PageIndex{2}\) .2
Figura\(\PageIndex{2}\) .2Otra posible explicación para la correlación observada es que se ha producido por la presencia de una variable causal-común (también conocida como tercera variable). Una variable causal-común es una variable que no forma parte de la hipótesis de investigación sino que causa tanto la variable predictora como la variable de resultado y así produce la correlación observada entre ellas. En nuestro ejemplo, una variable potencial causal-común es el estilo disciplinario de los padres de los niños. Los padres que usan un estilo de disciplina dura y punitiva pueden producir hijos a los que les gusta ver televisión violenta y que se comportan agresivamente en comparación con los niños cuyos padres usan una disciplina menos dura:
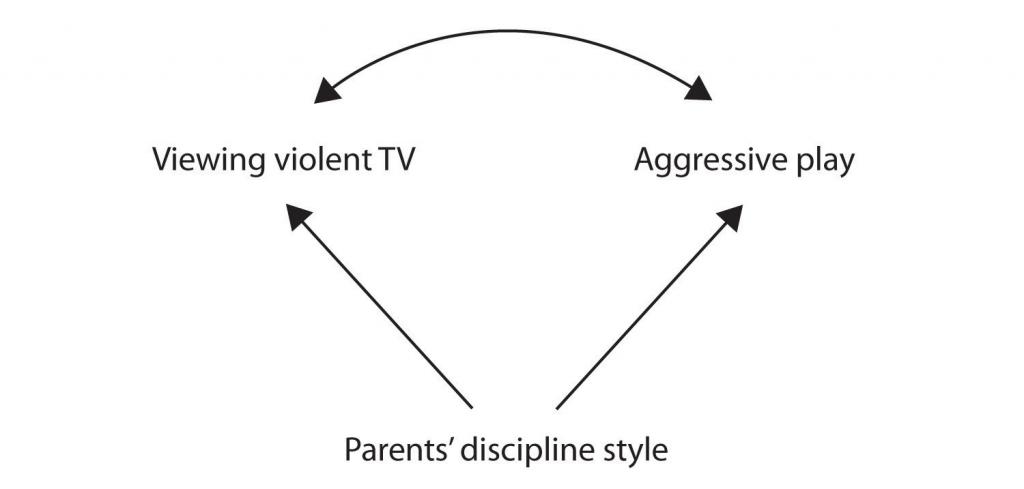
En este caso, la visualización de televisión y el juego agresivo estarían correlacionados positivamente (como lo indica la flecha curva entre ellos), a pesar de que ninguno causó el otro pero ambos fueron causados por el estilo disciplinario de los padres (las flechas rectas). Cuando tanto las variables predictoras como las variables de resultado son causadas por una variable causal-común, se dice que la relación observada entre ellas es espuria. Una relación espuria es una relación entre dos variables en la que una variable común-causal produce y “explica” la relación. Si se quitaran o controlaban los efectos de la variable causalidad común, la relación entre las variables predictoras y de resultado desaparecería. En el ejemplo la relación entre la agresión y la visualización de televisión puede ser espuria porque al controlar el efecto del estilo disciplinario de los padres, la relación entre la visualización de televisión y el comportamiento agresivo podría desaparecer.
Las variables causales comunes en los diseños de investigación correlacional pueden considerarse variables “misteriosas” porque, como no se han medido, su presencia e identidad suelen ser desconocidas para el investigador. Dado que no es posible medir todas las variables que puedan causar tanto las variables predictoras como las variables de resultado, la existencia de una variable causal-común desconocida es siempre una posibilidad. Por esta razón, nos quedamos con la limitación básica de la investigación correlacional: La correlación no demuestra causalidad. Es importante que cuando leas sobre proyectos de investigación correlacionales, tengas en cuenta la posibilidad de relaciones espurias, y asegúrate de interpretar los hallazgos adecuadamente. Aunque en ocasiones se reporta que la investigación correlacional demuestra la causalidad sin que se mencione la posibilidad de causalidad inversa o variables causales comunes, los consumidores informados de la investigación, como usted, son conscientes de estos problemas interpretacionales.
En suma, los diseños de investigación correlacional tienen fortalezas y limitaciones. Una fortaleza es que se pueden utilizar cuando la investigación experimental no es posible porque las variables predictoras no pueden ser manipuladas. Los diseños correlacionales también tienen la ventaja de permitir al investigador estudiar el comportamiento tal como ocurre en la vida cotidiana. Y también podemos usar diseños correlacionales para hacer predicciones, por ejemplo, para predecir a partir de los puntajes en su batería de pruebas el éxito de los aprendices laborales durante una sesión de capacitación. Pero no podemos usar esa información correlacional para determinar si la capacitación causó un mejor desempeño laboral. Para eso, los investigadores confían en experimentos.
Investigación Experimental: Comprensión de las Causas del Comportamiento
El objetivo del diseño de investigación experimental es proporcionar conclusiones más definitivas sobre las relaciones causales entre las variables en la hipótesis de investigación que las disponibles a partir de diseños correlacionales. En un diseño de investigación experimental, las variables de interés se denominan la variable independiente (o variables) y la variable dependiente. La variable independiente en un experimento es la variable causante que es creada (manipulada) por el experimentador. La variable dependiente en un experimento es una variable medida que se espera sea influenciada por la manipulación experimental. La hipótesis de investigación sugiere que la variable o variables independientes manipuladas provocarán cambios en las variables dependientes medidas. Podemos trazar la hipótesis de la investigación usando una flecha que apunta en una dirección. Esto demuestra la dirección esperada de la causalidad:

Enfoque de Investigación: Videojuegos y Agresión
Considera un experimento realizado por Anderson y Dill (2000). El estudio fue diseñado para probar la hipótesis de que ver videojuegos violentos aumentaría el comportamiento agresivo. En esta investigación, estudiantes universitarios masculinos y femeninos de la Universidad Estatal de Iowa tuvieron la oportunidad de jugar ya sea con un videojuego violento (Wolfenstein 3D) o con un videojuego no violento (Myst). Durante la sesión experimental, los participantes jugaron sus videojuegos asignados durante 15 minutos. Entonces, después de la jugada, cada participante jugó un juego competitivo con un oponente en el que el participante pudo entregar ráfagas de ruido blanco a través de los auriculares del oponente. La definición operativa de la variable dependiente (comportamiento agresivo) fue el nivel y duración del ruido entregado al oponente. El diseño del experimento se muestra en la Figura\(\PageIndex{17}\).
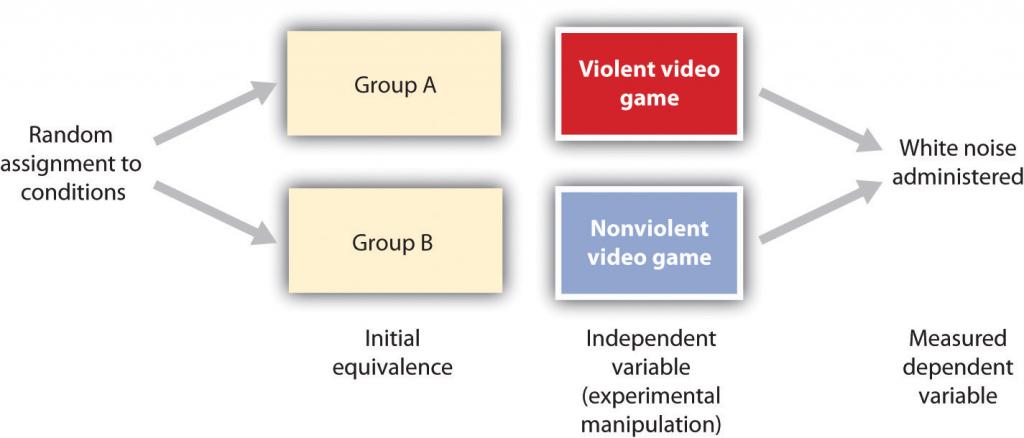 Figura\(\PageIndex{17}\) Un Diseño de Investigación Experimental
Figura\(\PageIndex{17}\) Un Diseño de Investigación ExperimentalDos ventajas del diseño de investigación experimental son (1) la seguridad de que la variable independiente (también conocida como la manipulación experimental) ocurre antes de la variable dependiente medida, y (2) la creación de equivalencia inicial entre las condiciones del experimento (en este caso mediante el uso aleatorio asignación a condiciones).
Los diseños experimentales tienen dos características muy bonitas. Por un lado, garantizan que la variable independiente se produce antes de la medición de la variable dependiente. Esto elimina la posibilidad de causalidad inversa. En segundo lugar, la influencia de las variables causales comunes es controlada, y así eliminada, mediante la creación de equivalencia inicial entre los participantes en cada una de las condiciones experimentales antes de que ocurra la manipulación.
El método más común para crear equivalencia entre las condiciones experimentales es a través de la asignación aleatoria a condiciones, procedimiento en el que la condición a la que se asigna cada participante se determina mediante un proceso aleatorio, como extraer números de un sobre o usar un número aleatorio mesa. Anderson y Dill asignaron primero al azar alrededor de 100 participantes a cada uno de sus dos grupos (Grupo A y Grupo B). Debido a que utilizaron asignación aleatoria a condiciones, podrían estar seguros de que, antes de que ocurriera la manipulación experimental, los estudiantes del Grupo A eran, en promedio, equivalentes a los estudiantes del Grupo B en todas las variables posibles, incluyendo variables que probablemente estén relacionadas con la agresión, como estilo de disciplina parental, relaciones entre pares, niveles hormonales, dieta y de hecho todo lo demás.
Entonces, después de haber creado la equivalencia inicial, Anderson y Dill crearon la manipulación experimental —hicieron que los participantes del Grupo A jugaran el juego violento y los participantes del Grupo B jueguen el juego no violento. Luego compararon la variable dependiente (las ráfagas de ruido blanco) entre los dos grupos, encontrando que los estudiantes que habían visto el videojuego violento dieron ráfagas de ruido significativamente más largas que los estudiantes que habían jugado el juego no violento.
Anderson y Dill habían creado desde un principio la equivalencia inicial entre los grupos. Esta equivalencia inicial les permitió observar diferencias en los niveles de ruido blanco entre los dos grupos después de la manipulación experimental, llevando a la conclusión de que fue la variable independiente (y no alguna otra variable) la que causó estas diferencias. La idea es que lo único que era diferente entre los alumnos de los dos grupos era el videojuego que habían jugado.
A pesar de la ventaja de determinar la causalidad, los experimentos tienen limitaciones. Una es que a menudo se llevan a cabo en situaciones de laboratorio más que en la vida cotidiana de las personas. Por lo tanto, no sabemos si los resultados que encontremos en un entorno de laboratorio necesariamente se mantendrán en la vida cotidiana. En segundo lugar, y más importante, es que algunas de las variables sociales más interesantes y clave no pueden ser manipuladas experimentalmente. Si queremos estudiar la influencia del tamaño de una turba en la destructividad de su comportamiento, o comparar las características de personalidad de las personas que se unen a cultos suicidas con las de las personas que no se unen a tales cultos, estas relaciones deben evaluarse utilizando diseños correlacionales, porque simplemente no lo es posible manipular experimentalmente estas variables.
Claves para llevar
- Se utilizan diseños de investigación descriptivos, correlacionales y experimentales para recopilar y analizar datos.
- Los diseños descriptivos incluyen estudios de casos, encuestas y observación naturalista. El objetivo de estos diseños es obtener una imagen de los pensamientos, sentimientos o comportamientos actuales en un grupo determinado de personas. La investigación descriptiva se resume mediante estadística descriptiva.
- Los diseños de investigación correlacional miden dos o más variables relevantes y evalúan una relación entre ellas o entre ellas. Las variables pueden presentarse en un diagrama de dispersión para mostrar visualmente las relaciones. El Coeficiente de Correlación de Pearson (r) es una medida de la fuerza de la relación lineal entre dos variables.
- Las variables causales comunes pueden causar tanto la variable predictora como la variable de resultado en un diseño correlacional, produciendo una relación espuria. La posibilidad de variables causales comunes hace imposible extraer conclusiones causales a partir de diseños de investigación correlacionales.
- La investigación experimental implica la manipulación de una variable independiente y la medición de una variable dependiente. La asignación aleatoria a condiciones se utiliza normalmente para crear equivalencia inicial entre los grupos, lo que permite a los investigadores sacar conclusiones causales.
Ejercicios y Pensamiento Crítico
- Existe una correlación negativa entre la fila en la que un estudiante se sienta en una clase grande (cuando las filas están numeradas de adelante hacia atrás) y su calificación final en la clase. ¿Crees que esto representa una relación causal o una relación espuria, y por qué?
- Piense en dos variables (distintas a las mencionadas en este libro) que probablemente estén correlacionadas, pero en las que la correlación es probablemente espuria. ¿Cuál es la probable variable causal-común que está produciendo la relación?
- Imagínese que un investigador quiere probar la hipótesis de que participar en psicoterapia provocará una disminución de la ansiedad reportada. Describir el tipo de diseño de investigación que el investigador podría utilizar para sacar esta conclusión. ¿Cuáles serían las variables independientes y dependientes en la investigación?
Referencias
Aiken, L., & West, S. (1991). Regresión múltiple: Prueba e interpretación de interacciones. Parque Newbury, CA: Sage.
Ainsworth, M. S., Blehar, M. C., Waters, E., & Wall, S. (1978). Patrones de apego: Un estudio psicológico de la extraña situación. Hillsdale, NJ: Lawrence Erlbaum Asociados.
Anderson, C. A., & Dill, K. E. (2000). Videojuegos y pensamientos, sentimientos y comportamientos agresivos en el laboratorio y en la vida. Revista de Personalidad y Psicología Social, 78 (4), 772—790.
Damasio, H., Grabowski, T., Frank, R., Galaburda, A. M., Damasio, A. R., Cacioppo, J. T., & Berntson, G. G. (2005). El regreso de Phineas Gage: Pistas sobre el cerebro desde el cráneo de un paciente famoso. En Neurociencia social: Lecturas clave. (págs. 21—28). Nueva York, NY: Psychology Press.
Freud, S. (1964). Análisis de fobia en un niño de cinco años. En E. A. Southwell & M. Merbaum (Eds.), Personalidad: lecturas en teoría e investigación (pp. 3—32). Belmont, CA: Wadsworth. (Obra original publicada en 1909)
Kotowicz, Z. (2007). El extraño caso de Phineas Gage. Historia de las Ciencias Humanas, 20 (1), 115—131.
Rokeach, M. (1964). Los tres Cristos de Ypsilanti: Un estudio psicológico. Nueva York, NY: Knopf.