
1.3: Pensamiento estadístico
- Page ID
- 145341

Por Beth Chance y Allan Rossman
Universidad Estatal Politécnica de California, San Luis Obispo
A medida que nuestra sociedad reclama cada vez más la toma de decisiones basada en la evidencia, es importante considerar cómo y cuándo podemos extraer inferencias válidas a partir de los datos. Este módulo utilizará cuatro estudios de investigación recientes para resaltar elementos clave de una investigación estadística.
objetivos de aprendizaje
- Definir elementos básicos de una investigación estadística.
- Describir el papel de los valores p y los intervalos de confianza en la inferencia estadística.
- Describir el papel del muestreo aleatorio en la generalización de conclusiones de una muestra a una población.
- Describir el papel de la asignación aleatoria en la elaboración de conclusiones de causa y efecto.
- Estudios estadísticos críticos.
Introducción
¿Beber café realmente aumenta tu esperanza de vida? Un estudio reciente (Freedman, Park, Abnet, Hollenbeck, & Sinha, 2012) encontró que los hombres que bebían al menos seis tazas de café al día tenían un 10% menos de probabilidades de morir (mujeres 15% menos) que aquellos que no bebían ninguno. ¿Significa esto que debes recoger o aumentar tu propio hábito de café?
La sociedad moderna se ha vuelto desbordada en estudios como este; se puede leer sobre varios estudios de este tipo en las noticias todos los días. Además, los datos abundan en todas partes de la vida moderna. Realizar bien dicho estudio e interpretar bien los resultados de dichos estudios para tomar decisiones informadas o establecer políticas, requiere comprender las ideas básicas de la estadística, la ciencia de obtener información a partir de los datos. En lugar de confiar en la anécdota y la intuición, la estadística nos permite estudiar sistemáticamente los fenómenos de interés.

Los componentes clave de una investigación estadística son:
- Planear el estudio: Comience haciendo una pregunta de investigación comprobable y decidiendo cómo recolectar datos. Por ejemplo, ¿cuánto tiempo duró el periodo de estudio del estudio del café? ¿Cuántas personas fueron reclutadas para el estudio, cómo fueron reclutadas y de dónde? ¿Cuántos años tenían? ¿Qué otras variables se registraron sobre los individuos, como los hábitos de tabaquismo, en los cuestionarios integrales de estilo de vida? ¿Se realizaron cambios en los hábitos de café de los participantes durante el transcurso del estudio?
- Examinar los datos: ¿Cuáles son las formas adecuadas de examinar los datos? ¿Qué gráficas son relevantes y qué revelan? ¿Qué estadísticas descriptivas se pueden calcular para resumir aspectos relevantes de los datos y qué revelan? ¿Qué patrones ves en los datos? ¿Hay alguna observación individual que se desvíe del patrón general, y qué revelan? Por ejemplo, en el estudio del café, ¿difirieron las proporciones cuando comparamos a los fumadores con los no fumadores?
- Inferir de los datos: ¿Cuáles son los métodos estadísticos válidos para extraer inferencias “más allá” de los datos que recopiló? En el estudio del café, ¿la reducción del 10% — 15% en el riesgo de muerte es algo que podría haber ocurrido sólo por casualidad?
- Sacar conclusiones: A partir de lo que aprendiste de tus datos, ¿qué conclusiones puedes sacar? ¿A quién crees que se aplican estas conclusiones? (¿Las personas en el estudio del café eran mayores? ¿Saludable? ¿Vivir en ciudades?) ¿Puedes sacar una conclusión de causa y efecto sobre tus tratamientos? (¿Están diciendo ahora los científicos que el consumo de café es la causa de la disminución del riesgo de muerte?)
Observe que el análisis numérico (“números crujidos” en la computadora) comprende solo una pequeña parte de la investigación estadística general. En este módulo, verás cómo podemos responder algunas de estas preguntas y qué preguntas deberías estar haciendo sobre cualquier investigación estadística sobre la que leas.
Pensamiento Distribucional
Cuando se recopilan datos para abordar una cuestión en particular, un primer paso importante es pensar en formas significativas de organizar y examinar los datos. El principio más fundamental de la estadística es que los datos varían. El patrón de esa variación es crucial para capturar y comprender. A menudo, la presentación cuidadosa de los datos abordará muchas de las preguntas de investigación sin requerir análisis más sofisticados. Puede, sin embargo, señalar cuestiones adicionales que deben ser examinadas con más detalle.
Ejemplo 1: Investigadores investigaron si los folletos sobre el cáncer están escritos a un nivel apropiado para ser leídos y entendidos por pacientes con cáncer (Short, Moriarty, & Cooley, 1995). Se realizaron pruebas de capacidad lectora a 63 pacientes. Además, se determinó el nivel de legibilidad para una muestra de 30 folletos, con base en características como la longitud de las palabras y oraciones del folleto. Los resultados, reportados en términos de niveles de grado, se muestran en el Cuadro 1.

Estas dos variables revelan dos aspectos fundamentales del pensamiento estadístico:
- Los datos varían. Más específicamente, los valores de una variable (como el nivel de lectura de un paciente con cáncer o el nivel de legibilidad de un folleto de cáncer) varían.
- Analizar el patrón de variación, llamado distribución de la variable, a menudo revela percepciones.
Abordar la pregunta de investigación de si los folletos sobre el cáncer están escritos en niveles apropiados para los pacientes con cáncer requiere comparar las dos distribuciones. Una comparación ingenua podría enfocarse únicamente en los centros de las distribuciones. Ambas medianas resultan ser de noveno grado, pero considerando solo las medianas ignora la variabilidad y las distribuciones generales de estos datos. Un enfoque más iluminador es comparar las distribuciones completas, por ejemplo con una gráfica, como en la Figura 1.
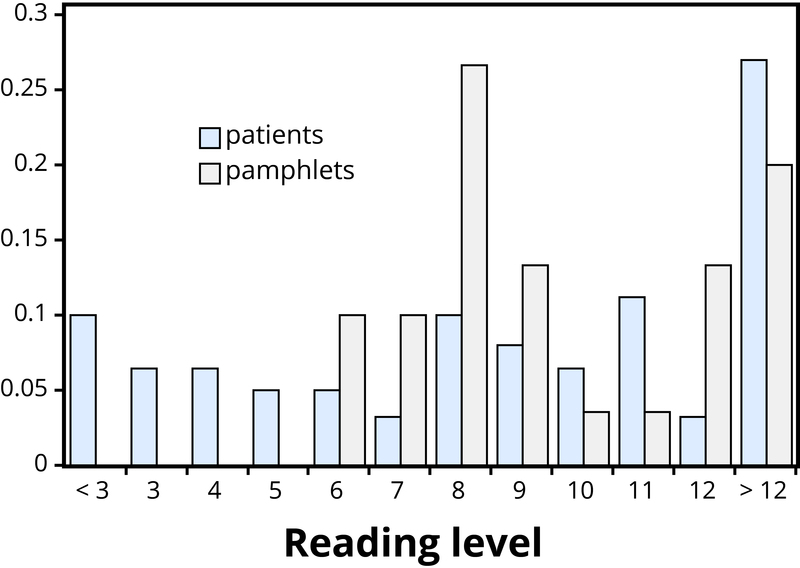
La Figura 2.3.1 deja claro que las dos distribuciones no están bien alineadas en absoluto. La discrepancia más evidente es que muchos pacientes (17/63, o 27%, para ser precisos) tienen un nivel de lectura por debajo del del folleto más legible. Estos pacientes necesitarán ayuda para comprender la información proporcionada en los panfletos sobre el cáncer. Obsérvese que esta conclusión se deriva de considerar las distribuciones en su conjunto, no simplemente medidas de centro o variabilidad, y que la gráfica contrasta esas distribuciones más inmediatamente que las tablas de frecuencias.
Significancia estadística
Incluso cuando encontramos patrones en los datos, a menudo todavía hay incertidumbre en diversos aspectos de los datos. Por ejemplo, puede haber posibles errores de medición (incluso su propia temperatura corporal puede fluctuar casi 1 °F en el transcurso del día). O tal vez solo tengamos una “instantánea” de observaciones de un proceso de más largo plazo o solo de un pequeño subconjunto de individuos de la población de interés. En tales casos, ¿cómo podemos determinar si los patrones que vemos en nuestro pequeño conjunto de datos son evidencia convincente de un fenómeno sistemático en el proceso o población más grande?
Ejemplo 2: En un estudio reportado en la edición de noviembre de 2007 de Nature, los investigadores investigaron si los bebés preverbales toman en cuenta las acciones de un individuo hacia los demás al evaluar a ese individuo como atractivo o aversivo (Hamlin, Wynn, & Bloom, 2007). En un componente del estudio, a los infantes de 10 meses de edad se les mostró un carácter “escalador” (un trozo de madera con ojos “saltones” pegados sobre él) que no pudieron subir una colina en dos intentos. Después a los infantes se les mostraron dos escenarios para el siguiente intento del escalador, uno donde el escalador fue empujado a la cima del cerro por otro personaje (“ayudante”), y uno donde el escalador fue empujado hacia atrás por el cerro por otro personaje (“obstaculizador”). Al lactante se le mostraron alternativamente estos dos escenarios varias veces. Después al infante se le presentaron dos piezas de madera (que representaban a los personajes ayudantes y obstaculizadores) y se le pidió que eligiera uno con el que jugar. Los investigadores encontraron que de los 16 infantes que tomaron una decisión clara, 14 optaron por jugar con el juguete auxiliar.

Una posible explicación para este claro resultado mayoritario es que el comportamiento de ayuda de un juguete aumenta la probabilidad de que los bebés elijan ese juguete. Pero, ¿hay otras posibles explicaciones? ¿Y el color del juguete? Bueno, antes de recolectar los datos, los investigadores organizaron para que cada color y forma (cuadrado rojo y círculo azul) fueran vistos por el mismo número de infantes. ¿O tal vez los infantes tenían tendencias diestras y así eligieron el juguete que estuviera más cerca de su mano derecha? Bueno, antes de recabar los datos, los investigadores lo organizaron para que la mitad de los infantes vieran el juguete auxiliar a la derecha y la mitad a la izquierda. O, ¿tal vez las formas de estos personajes de madera (cuadrado, triángulo, círculo) tuvieron un efecto? Quizás, pero de nuevo, los investigadores controlaron para ello girando qué forma era el juguete auxiliar, el juguete obstaculizador, y el escalador. Al diseñar experimentos, es importante controlar tantas variables como puedan afectar las respuestas como sea posible.
Está empezando a aparecer que los investigadores contabilizaron todas las demás explicaciones plausibles. Pero hay una consideración más importante que no se puede controlar: si volviéramos a hacer el estudio con estos 16 infantes, es posible que no tomen las mismas decisiones. En otras palabras, existe cierta aleatoriedad inherente a su proceso de selección. Tal vez cada bebé no tenía ninguna preferencia genuina en absoluto, y fue simplemente “suerte aleatoria” lo que llevó a que 14 infantes eligieran el juguete auxiliar. Aunque este componente aleatorio no puede ser controlado, podemos aplicar un modelo de probabilidad para investigar el patrón de resultados que ocurriría a largo plazo si el azar aleatorio fuera el único factor.
Si los bebés tenían la misma probabilidad de elegir entre los dos juguetes, entonces cada bebé tenía un 50% de probabilidad de elegir el juguete auxiliar. Es como si cada bebé lanzara una moneda, y si aterrizó cabezas, el infante recogió el juguete auxiliar. Entonces, si lanzamos una moneda 16 veces, ¿podría aterrizar cabezas 14 veces? Claro, es posible, pero resulta muy poco probable. Obtener 14 (o más) cabezas en 16 tiradas es tan probable como lanzar una moneda y obtener 9 cabezas seguidas. Esta probabilidad se conoce como un valor p. El valor p te indica con qué frecuencia un proceso aleatorio daría un resultado al menos tan extremo como lo que se encontró en el estudio real, asumiendo que no había otra cosa que una oportunidad aleatoria en juego. Entonces, si asumimos que cada infante estaba eligiendo por igual, entonces la probabilidad de que 14 o más de cada 16 infantes eligieran el juguete auxiliar se encuentra en 0.0021. Solo tenemos dos posibilidades lógicas: o los infantes tienen una preferencia genuina por el juguete auxiliar, o los infantes no tienen preferencia (50/50) y un resultado que ocurriría solo 2 veces en 1,000 iteraciones ocurrió en este estudio. Debido a que este valor p de 0.0021 es bastante pequeño, concluimos que el estudio proporciona evidencia muy fuerte de que estos bebés tienen una preferencia genuina por el juguete auxiliar. A menudo comparamos el valor p con algún valor de corte (llamado el nivel de significancia, típicamente alrededor de 0.05). Si el valor p es menor que ese valor de corte, entonces rechazamos la hipótesis de que aquí solo estaba en juego la posibilidad aleatoria. En este caso, estos investigadores concluirían que significativamente más de la mitad de los infantes en el estudio eligieron el juguete auxiliar, dando fuertes evidencias de una genuina preferencia por el juguete con el comportamiento de ayuda.
Generalizabilidad

Una limitación del estudio previo es que la conclusión solo se aplica a los 16 infantes en el estudio. No sabemos mucho sobre cómo se seleccionaron esos 16 infantes. Supongamos que queremos seleccionar un subconjunto de individuos (una muestra) de un grupo mucho mayor de individuos (la población) de tal manera que las conclusiones de la muestra puedan generalizarse a la población más grande. Esta es la pregunta que enfrentan los encuestadores todos los días.
Ejemplo 3: La Encuesta Social General (GSS) es una encuesta sobre tendencias sociales realizada cada dos años en Estados Unidos. A partir de una muestra de alrededor de 2,000 estadounidenses adultos, los investigadores hacen afirmaciones sobre qué porcentaje de la población estadounidense se considera “liberal”, qué porcentaje se considera “feliz”, qué porcentaje se siente “apresurado” en su vida diaria y muchos otros temas. La clave para hacer estas afirmaciones sobre la mayor población de todos los adultos estadounidenses radica en cómo se selecciona la muestra. El objetivo es seleccionar una muestra que sea representativa de la población, y una manera común de lograr este objetivo es seleccionar una muestra aleatoria que dé a cada miembro de la población la misma oportunidad de ser seleccionado para la muestra. En su forma más simple, el muestreo aleatorio implica numerar a cada miembro de la población y luego usar una computadora para seleccionar aleatoriamente el subconjunto que se va a encuestar. La mayoría de las encuestas no operan exactamente así, pero sí utilizan métodos de muestreo basados en la probabilidad para seleccionar individuos de paneles representativos a nivel nacional.
En 2004, el GSS informó que 817 de 977 encuestados (o 83.6%) indicaron que siempre o a veces se sienten apresurados. Esta es una clara mayoría, pero nuevamente necesitamos considerar la variación por muestreo aleatorio. Afortunadamente, podemos usar el mismo modelo de probabilidad que hicimos en el ejemplo anterior para investigar el tamaño probable de este error. (Tenga en cuenta que podemos usar el modelo de lanzamiento de monedas cuando el tamaño real de la población es mucho, mucho mayor que el tamaño de la muestra, ya que entonces aún podemos considerar que la probabilidad es la misma para cada individuo de la muestra). Este modelo de probabilidad predice que el resultado de la muestra estará dentro de los 3 puntos porcentuales del valor de la población (aproximadamente 1 sobre la raíz cuadrada del tamaño de la muestra, el margen de error). Un estadístico concluiría, con 95% de confianza, que entre 80.6% y 86.6% de todos los estadounidenses adultos en 2004 habrían respondido que a veces o siempre se sienten apresurados.
La clave del margen de error es que cuando utilizamos un método de muestreo probabilístico, podemos hacer afirmaciones sobre la frecuencia (a la larga, con muestreo aleatorio repetido) el resultado de la muestra caería dentro de cierta distancia del valor desconocido de la población por casualidad (es decir, por variación de muestreo aleatorio) solo. Por el contrario, a menudo se sospecha que las muestras no aleatorias sesgan, lo que significa que el método de muestreo sobrerepresenta sistemáticamente algunos segmentos de la población y subrepresenta a otros. También necesitamos considerar otras fuentes de sesgo, como los individuos que no responden honestamente. Estas fuentes de error no se miden por el margen de error.
Conclusiones de Causa y Efecto
En muchos estudios de investigación, la cuestión principal de interés se refiere a las diferencias entre grupos. Entonces la pregunta se convierte en cómo se formaron los grupos (por ejemplo, seleccionar a las personas que ya toman café vs. a las que no). En algunos estudios, los investigadores forman activamente los propios grupos. Pero entonces tenemos una pregunta similar: ¿podría alguna diferencia que observemos en los grupos ser un artefacto de ese proceso de formación grupal? O tal vez la diferencia que observamos en los grupos es tan grande que podemos descontar una “casualidad” en el proceso de formación grupal como una explicación razonable de lo que encontramos?
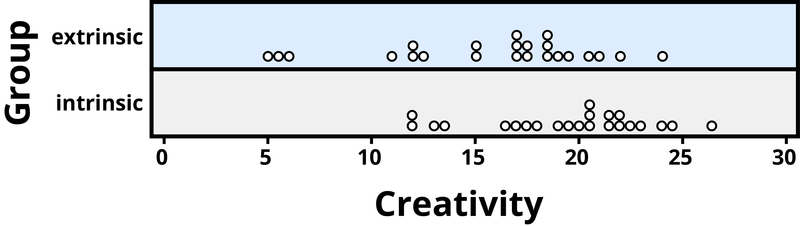
Ejemplo 4: Un estudio de psicología investigó si las personas tienden a mostrar más creatividad cuando piensan en motivaciones intrínsecas o extrínsecas (Ramsey & Schafer, 2002, basado en un estudio de Amabile, 1985). Los temas fueron 47 personas con amplia experiencia en escritura creativa. Los sujetos comenzaron respondiendo preguntas de encuesta sobre motivaciones intrínsecas para escribir (como el placer de la autoexpresión) o motivaciones extrínsecas (como el reconocimiento público). Entonces todos los sujetos fueron instruidos para escribir un haiku, y esos poemas fueron evaluados para su creatividad por un panel de jueces. Los investigadores conjeturaron de antemano que los sujetos que estaban pensando en motivaciones intrínsecas mostrarían más creatividad que los sujetos que estaban pensando en motivaciones extrínsecas. Los puntajes de creatividad de los 47 sujetos de este estudio se muestran en la Figura 2, donde los puntajes más altos indican más creatividad.
En este ejemplo, la pregunta clave es si el tipo de motivación afecta los puntajes de creatividad. En particular, ¿los sujetos a los que se les preguntó sobre motivaciones intrínsecas tienden a tener puntuaciones de creatividad más altas que los sujetos a quienes se les preguntó sobre motivaciones extrínsecas?
La Figura 2.3.2 revela que ambos grupos de motivación vieron una variabilidad considerable en los puntajes de creatividad, y estos puntajes tienen una superposición considerable entre los grupos. En otras palabras, ciertamente no siempre ocurre que quienes tienen motivaciones extrínsecas tienen mayor creatividad que aquellos con motivaciones intrínsecas, pero aún puede haber una tendencia estadística en esta dirección. (El psicólogo Keith Stanovich (2013) se refiere a las dificultades de las personas para pensar en tendencias probabilísticas como “el talón de Aquiles de la cognición humana”.)
El puntaje medio de creatividad es de 19.88 para el grupo intrínseco, frente a 15.74 para el grupo extrínseco, lo que respalda la conjetura de los investigadores. Sin embargo, al comparar solo las medias de los dos grupos, no se tiene en cuenta la variabilidad de las puntuaciones de creatividad en los grupos. Podemos medir la variabilidad con estadísticas utilizando, por ejemplo, la desviación estándar: 5.25 para el grupo extrínseco y 4.40 para el grupo intrínseco. Las desviaciones estándar nos dicen que la mayoría de los puntajes de creatividad están dentro de aproximadamente 5 puntos de la puntuación media en cada grupo. Vemos que la puntuación media para el grupo intrínseco se encuentra dentro de una desviación estándar de la puntuación media para el grupo extrínseco. Entonces, aunque hay una tendencia a que los puntajes de creatividad sean más altos en el grupo intrínseco, en promedio, la diferencia no es extremadamente grande.
De nuevo queremos considerar posibles explicaciones para esta diferencia. El estudio solo involucró a individuos con amplia experiencia en escritura creativa. Aunque esto limita la población a la que podemos generalizar, no explica por qué la puntuación media de creatividad fue un poco mayor para el grupo intrínseco que para el grupo extrínseco. ¿Quizás las mujeres tienden a recibir puntuaciones de creatividad más altas? Aquí es donde debemos enfocarnos en cómo los individuos fueron asignados a los grupos de motivación. Si solo las mujeres estuvieran en el grupo de motivación intrínseca y solo los hombres en el grupo extrínseco, entonces esto presentaría un problema porque no sabríamos si al grupo intrínseco le fue mejor por el diferente tipo de motivación o por ser mujeres. Sin embargo, los investigadores se guardaron contra tal problema asignando aleatoriamente a los individuos a los grupos de motivación. Al igual que lanzar una moneda, cada individuo era igual de probable que se le asignara a cualquier tipo de motivación. ¿Por qué es útil esto? Porque esta asignación aleatoria tiende a equilibrar todas las variables relacionadas con la creatividad que podemos pensar, e incluso aquellas en las que no pensamos de antemano, entre los dos grupos. Entonces deberíamos tener una división similar masculino/mujer entre los dos grupos; deberíamos tener una distribución por edades similar entre los dos grupos; deberíamos tener una distribución similar de los antecedentes educativos entre los dos grupos; y así sucesivamente. La asignación aleatoria debe producir grupos que sean lo más similares posible excepto por el tipo de motivación, lo que presumiblemente elimina todas esas otras variables como posibles explicaciones de la tendencia observada a puntuaciones más altas en el grupo intrínseco.
Pero, ¿esto siempre funciona? No, entonces por “suerte del sorteo” los grupos pueden ser un poco diferentes antes de responder a la encuesta de motivación. Entonces la pregunta es, ¿es posible que una asignación aleatoria desafortunada sea responsable de la diferencia observada en los puntajes de creatividad entre los grupos? En otras palabras, supongamos que el poema de cada individuo iba a obtener la misma puntuación de creatividad sin importar a qué grupo se le asignara, que el tipo de motivación de ninguna manera impactó su puntuación. Entonces, ¿con qué frecuencia el proceso de asignación aleatoria por sí solo conduciría a una diferencia en las puntuaciones medias de creatividad tan grande (o mayor) que 19.88 — 15.74 = 4.14 puntos?
Nuevamente queremos aplicar a un modelo de probabilidad para aproximar un valor p, pero esta vez el modelo será un poco diferente. Piense en escribir las puntuaciones de creatividad de todos en una ficha, barajar las fichas y luego repartir 23 al grupo de motivación extrínseca y 24 al grupo de motivación intrínseca, y encontrar la diferencia en los medios grupales. Nosotros (mejor aún, la computadora) podemos repetir este proceso una y otra vez para ver con qué frecuencia, cuando las puntuaciones no cambian, la asignación aleatoria conduce a una diferencia de medias al menos tan grande como 4.41. La Figura 2.3.3 muestra los resultados de 1,000 asignaciones aleatorias hipotéticas para estas puntuaciones.
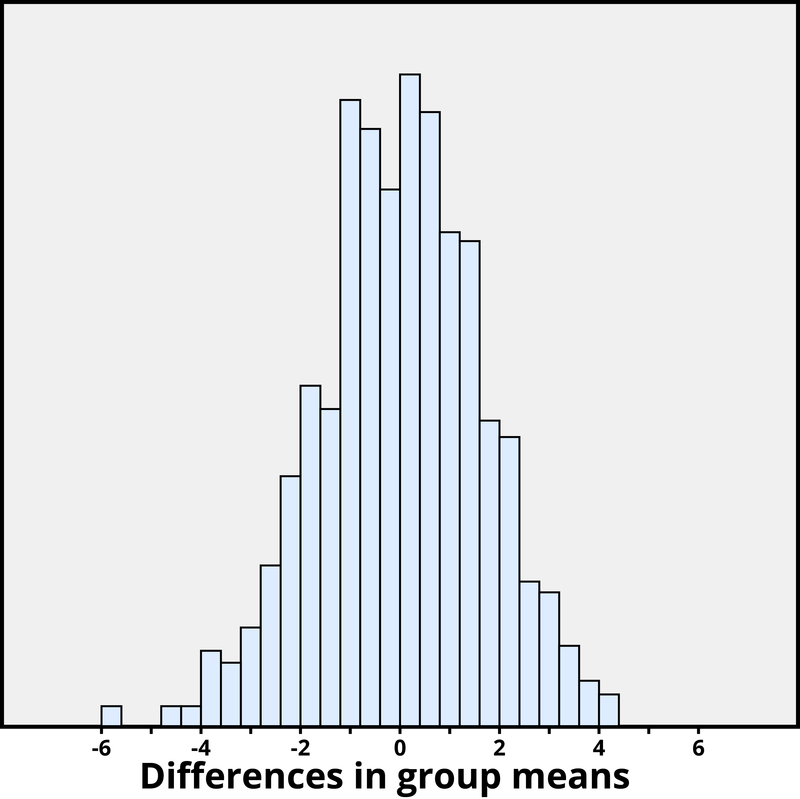
Solo 2 de las mil asignaciones aleatorias simuladas produjeron una diferencia en las medias grupales de 4.41 o más. Es decir, el valor p aproximado es 2/1000 = 0.002. Este pequeño valor p indica que sería muy sorprendente para el proceso de asignación aleatoria por sí solo producir una diferencia tan grande en las medias grupales. Por lo tanto, al igual que con el Ejemplo 2, tenemos fuertes evidencias de que enfocarse en motivaciones intrínsecas tiende a aumentar los puntajes de creatividad, en comparación con pensar en motivaciones extrínsecas.
Observe que la afirmación anterior implica una relación de causa y efecto entre motivación y puntaje de creatividad; ¿se justifica una conclusión tan fuerte? Sí, por la asignación aleatoria utilizada en el estudio. Eso debería haber equilibrado cualquier otra variable entre los dos grupos, así que ahora que el pequeño valor p nos convence de que la media más alta en el grupo intrínseco no era solo una coincidencia, la única explicación razonable que queda es la diferencia en el tipo de motivación. ¿Podemos generalizar esta conclusión a todos? No necesariamente, podríamos generalizar con cautela esta conclusión a individuos con amplia experiencia en escritura creativa similares a los individuos de este estudio, pero aún así quisiéramos saber más sobre cómo estos individuos fueron seleccionados para participar.
Conclusión

El pensamiento estadístico implica el diseño cuidadoso de un estudio para recopilar datos significativos para responder a una pregunta de investigación enfocada, análisis detallado de patrones en los datos y sacar conclusiones que van más allá de los datos observados. El muestreo aleatorio es primordial para generalizar los resultados de nuestra muestra a una población mayor, y la asignación aleatoria es clave para sacar conclusiones de causa y efecto. Con ambos tipos de aleatoriedad, los modelos de probabilidad nos ayudan a evaluar cuánta variación aleatoria podemos esperar en nuestros resultados, con el fin de determinar si nuestros resultados podrían ocurrir solo por casualidad y estimar un margen de error.
Entonces, ¿dónde nos deja esto con respecto al estudio del café mencionado al inicio de este módulo? Podemos responder muchas de las preguntas:
- Este fue un estudio de 14 años realizado por investigadores del Instituto Nacional del Cáncer.
- Los resultados fueron publicados en la edición de junio del New England Journal of Medicine, una revista respetada y revisada por pares.
- El estudio revisó los hábitos de café de más de 402,000 personas de 50 a 71 años de seis estados y dos áreas metropolitanas. Aquellos con cáncer, cardiopatía y accidente cerebrovascular fueron excluidos al inicio del estudio. El consumo de café se evaluó una vez al inicio del estudio.
- Alrededor de 52 mil personas murieron durante el transcurso del estudio.
- Las personas que bebían entre dos y cinco tazas de café diariamente también mostraron un menor riesgo, pero la cantidad de reducción aumentó para quienes tomaban seis o más tazas.
- Los tamaños de muestra fueron bastante grandes y por lo tanto los valores de p son bastante pequeños, a pesar de que la reducción porcentual en el riesgo no fue extremadamente grande (bajando de una probabilidad de 12% a aproximadamente 10% — 11%).
- Si el café estaba cafeinado o descafeinado no pareció afectar los resultados.
- Este fue un estudio observacional, por lo que no se pueden extraer conclusiones de causa y efecto entre el consumo de café y el aumento de la longevidad, contrariamente a la impresión que transmiten muchos titulares de noticias sobre este estudio. En particular, es posible que las personas con enfermedades crónicas no tiendan a tomar café.
Este estudio debe revisarse en el contexto más amplio de estudios similares y la consistencia de los resultados entre los estudios, con la constante precaución de que no se trataba de un experimento aleatorio. Mientras que un análisis estadístico todavía puede “ajustarse” para otras posibles variables de confusión, aún no estamos convencidos de que los investigadores las hayan identificado todas o completamente aisladas por qué esta disminución en el riesgo de muerte es evidente. Los investigadores ahora pueden tomar los hallazgos de este estudio y desarrollar estudios más enfocados que aborden nuevas preguntas.
Recursos externos
- Aplicaciones: Los applets web interactivos para la enseñanza y el aprendizaje de estadísticas incluyen la colección en
- http://www.rossmanchance.com/applets/
- Extravagancia P-Value
- Web: Consorcio Interuniversitario de Investigación Política y Social
- http://www.icpsr.umich.edu/index.html
- Web: El Consorcio para el Avance de la Estadística de Pregrado
- https://www.causeweb.org/
Preguntas de Discusión
- Encuentra un artículo de investigación reciente en tu campo y responde lo siguiente: ¿Cuál fue la pregunta principal de investigación? ¿Cómo se seleccionaron los individuos para participar en el estudio? ¿Se proporcionaron resultados resumidos? ¿Qué tan fuerte es la evidencia presentada a favor o en contra de la pregunta de investigación? ¿Se utilizó asignación aleatoria? Resumir las principales conclusiones del estudio, abordando los temas de significancia estadística, confianza estadística, generalizabilidad y causa y efecto. ¿Está de acuerdo con las conclusiones extraídas de este estudio, con base en el diseño del estudio y los resultados presentados?
- ¿Es razonable utilizar una muestra aleatoria de 1,000 individuos para sacar conclusiones sobre todos los adultos estadounidenses? Explique por qué o por qué no.
El vocabulario
- Causa y Efecto
- Relacionado con si decimos que una variable está causando cambios en la otra variable, versus otras variables que pueden estar relacionadas con estas dos variables.
- Intervalo de confianza
- Un intervalo de valores plausibles para un parámetro de población; el intervalo de valores dentro del margen de error de una estadística.
- Distribución
- El patrón de variación en los datos.
- Generalizabilidad
- Relacionado con si los resultados de la muestra pueden generalizarse a una población mayor.
- Margen de error
- La cantidad esperada de variación aleatoria en un estadístico; a menudo definida para el nivel de confianza del 95%.
- Parámetro
- Un resultado numérico que resume una población (e.g., media, proporción).
- Población
- Una colección más grande de individuos a los que nos gustaría generalizar nuestros resultados.
- Valor P
- La probabilidad de observar un resultado particular en una muestra, o más extrema, bajo una conjetura sobre la mayor población o proceso.
- Asignación aleatoria
- Usando un método basado en probabilidades para dividir una muestra en grupos de tratamiento.
- Muestreo aleatorio
- Utilizando un método basado en probabilidades para seleccionar un subconjunto de individuos para la muestra de la población.
- Muestra
- La recolección de personas físicas sobre las que recabamos datos.
- Estadística
- Un resultado numérico calculado a partir de una muestra (por ejemplo, media, proporción).
- Significancia estadística
- Un resultado es estadísticamente significativo si es poco probable que surja solo por casualidad.
Referencias
- Amabile, T. (1985). Motivación y creatividad: Efectos de la orientación motivacional en escritores creativos. Revista de Personalidad y Psicología Social, 48 (2), 393—399.
- Freedman, N. D., Park, Y., Abnet, C. C., Hollenbeck, A. R., & Sinha, R. (2012). Asociación del consumo de café con la mortalidad total y por causa específica. New England Journal of Medicine, 366, 1891—1904.
- Hamlin, J. K., Wynn, K., & Bloom, P. (2007). Evaluación social por infantes preverbales. Naturaleza, 452 (22), 557—560.
- Ramsey, F., & Schafer, D. (2002). El detector estadístico: Un curso en métodos de análisis de datos. Belmont, CA: Duxbury.
- Short, T., Moriarty, H., & Cooley, M. E. (1995). Legibilidad de materiales educativos para pacientes con cáncer. Revista de Educación Estadística, 3 (2).
- Stanovich, K. (2013). Cómo pensar directamente sobre la psicología (10a ed.). Upper Saddle River, Nueva Jersey: Pearson.