
12.2: Representación del conocimiento en el cerebro
- Última actualización
- Guardar como PDF
- Page ID
- 146651

- Wikipedia
Conceptos y Categorías
Para muchas funciones cognitivas, los conceptos son esenciales. Los conceptos son representaciones mentales, incluyendo la memoria, el razonamiento y el uso/comprensión del lenguaje. Una función de los conceptos es la categorización del conocimiento que se ha estudiado intensamente. En el transcurso de este capítulo, nos centraremos en esta función de conceptos.
Imagina que te despiertas cada mañana y empiezas a preguntarte por todas las cosas que nunca antes habías visto. Piensa en cómo te sentirías si un auto desconocido aparcara frente a tu casa. Has visto miles de autos pero como nunca has visto este auto específico en esta posición en particular, no podrías darte ninguna explicación. Como podemos encontrar una explicación, las preguntas que debemos hacernos son: ¿Cómo podemos abstraernos del conocimiento previo y por qué no empezamos de nuevo si nos enfrentamos a una situación ligeramente nueva? La respuesta es fácil: Categorizamos el conocimiento. La categorización es el proceso por el cual las cosas se colocan en grupos llamados categorías.
Las categorías se llaman “punteros de conocimiento”. Se puede imaginar una categoría como una caja, en la que se agrupan objetos similares y que se etiqueta con propiedades comunes y otra información general sobre la categoría. Nuestro cerebro no solo memoriza ejemplos específicos de miembros de una categoría, sino que también almacena información general que todos los miembros tienen en común y que por lo tanto define la categoría. Volviendo al ejemplo del auto, esto significa que nuestro cerebro no solo almacena cómo se ve tu auto, el de tus vecinos y el de tus amigos, sino que también nos brinda la información general de que la mayoría de los autos tienen cuatro ruedas, necesitan ser alimentados y así sucesivamente. Debido a que la categorización inmediatamente nos permite obtener una imagen general de una escena al permitirnos reconocer nuevos objetos como miembros de una categoría, nos ahorra mucho tiempo y energía que de otro modo tendríamos que gastar en investigar nuevos objetos. Nos ayuda a enfocarnos en los detalles importantes de nuestro entorno, y nos permite sacar las inferencias correctas. Para que esto sea obvio, imagínate parado al costado de una carretera, queriendo atravesarla. Un automóvil se acerca desde la izquierda. Ahora bien, lo único que debes saber de este auto es la información general proporcionada por la categoría, que te atropellará si no esperas hasta que haya pasado. No es necesario que te importe el color del auto, el número de puertas, etc. Si no pudieras asignar inmediatamente el auto a la categoría “auto”, e inferir la necesidad de dar un paso atrás, te golpearían porque seguirías ocupado examinando los detalles de ese auto específico y desconocido. Por lo tanto, la categorización ha demostrado ser muy útil para sobrevivir durante la evolución y nos permite navegar rápida y eficientemente por nuestro entorno.
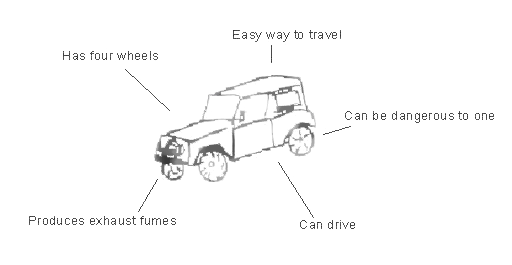
Enfoque Definicional
¡Echa un vistazo a la siguiente imagen! Verás cuatro tipos diferentes de autos. Difieren en forma, color y otras características, sin embargo probablemente estés seguro de que todos son autos.
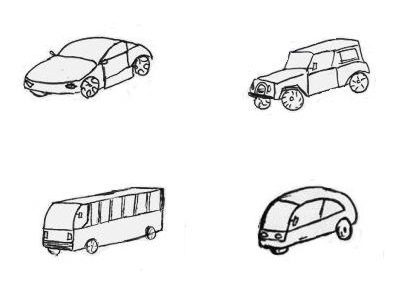
¿Qué nos hace tan convencidos de la identidad de estos objetos? Tal vez podamos tratar de encontrar una definición que describa todos estos autos. ¿Tienen todas cuatro ruedas? No, hay algunos que sólo tienen tres. ¿Todos los autos conducen con gasolina? No, eso tampoco es cierto para todos los autos. Al parecer no lograremos llegar a una definición. El motivo de este fracaso es que tenemos que generalizar para hacer una definición. Eso funcionaría quizás para objetos geométricos, pero obviamente no para cosas naturales. No comparten características completamente idénticas en una categoría por lo que resulta problemático encontrar una definición adecuada. Sin embargo, hay similitudes entre los miembros de una categoría, entonces, ¿qué pasa con esta familiaridad? El famoso filósofo y lingüista Ludwig Wittgenstein se hizo esta pregunta y afirmó haber encontrado una solución. Desarrolló la idea del parecido familiar. Eso significa que los miembros de una categoría se parecen entre sí de varias maneras. Por ejemplo, los autos difieren en forma, color y muchas otras propiedades pero cada auto se parece de alguna manera a otros autos. Los dos enfoques siguientes determinan categorías por similitud.
Enfoque de prototipo
El enfoque prototipo fue propuesto por Rosch en 1973. Un prototipo es un caso promedio de todos los miembros de una categoría en particular, pero no es un miembro real, realmente existente de la categoría. Incluso las diversas características extremas de los miembros dentro de una categoría pueden explicarse por este enfoque. Los diferentes grados de prototipicidad representan diferencias entre los miembros de la categoría. Los miembros que se asemejan muy fuertemente al prototipo son altamente prototípicos. Los miembros que difieren en muchos aspectos del prototipo son, por lo tanto, poco prototípicos. Parece haber conexiones con la idea del parecido familiar y, de hecho, algunos experimentos mostraron que la alta prototipicidad y el alto parecido familiar están fuertemente conectados. El efecto de tipicidad describe el hecho de que los miembros altamente prototípicos son más rápidos reconocidos como miembros de una categoría. Por ejemplo, los participantes tuvieron que decidir si declaraciones como “Un pingüino es un pájaro” o “Un gorrión es pájaro”. son ciertas. Sus decisiones fueron mucho más rápidas respecto al “gorrión” como miembro altamente prototípico de la categoría “ave” que para un miembro atípico como “pingüino”. Los participantes también tienden a preferir miembros prototípicos de una categoría cuando se les pide que enumeren objetos de una categoría. En cuanto al ejemplo de las aves, más bien enumeran “gorrión” que “pingüino”, lo que es un resultado bastante intuitivo. Además, los objetos de alto prototípico se ven fuertemente afectados por el cebado.
Enfoque ejemplar
El efecto de tipicidad también puede explicarse por un tercer enfoque que se refiere a los ejemplares. Similar a un prototipo, un ejemplar es un miembro muy típico de la categoría. La diferencia entre ejemplares y prototipos es que los ejemplares son realmente miembros existentes de una categoría que una persona ha encontrado en el pasado. Sin embargo, implica también la similitud de un objeto con un objeto estándar. Sólo que el estándar aquí involucra muchos ejemplos y no el promedio, cada uno llamado ejemplar.
Nuevamente podemos mostrar el efecto de tipicidad: Los objetos que son similares a muchos ejemplos que hemos encontrado se clasifican más rápido a objetos que son similares a pocos ejemplos. Has visto un gorrión con más frecuencia en tu vida que un pingüino, por lo que debes reconocer al gorrión más rápido.
Tanto para el enfoque prototipo como para el modelo existen experimentos cuyos resultados apoyan cualquiera de los dos enfoques. Algunas personas afirman que el enfoque ejemplar tiene menos problemas con categorías variables y con casos atípicos dentro de categorías. Por ejemplo, la categoría “juegos” es bastante difícil de realizar con el enfoque prototipo. ¿Cómo quieres encontrar un caso promedio para todos los partidos, como fútbol, golf, ajedrez. La razón de ello podría ser que se utilicen miembros de categoría “reales” y se almacene toda la información de los ejemplares individuales, que puede ser útil al encontrarse con otros miembros posteriormente. Otro punto en el que se pueden comparar los enfoques es qué tan bien funcionan para categorías de diferentes tamaños. El enfoque ejemplar parece funcionar mejor para categorías más pequeñas y los prototipos funcionan mejor para categorías más grandes.
Algunos investigadores concluyeron que las personas pueden usar ambos enfoques: Cuando inicialmente aprendemos algo sobre una categoría, promediamos los ejemplares vistos en un prototipo. Sería muy malo en el aprendizaje temprano, si ya tomamos en cuenta qué excepciones tiene una categoría. Al conocer con más detalle algunos de estos ejemplares se fortalece la información.
“Sabemos generalmente qué son los gatos (el prototipo), pero conocemos específicamente a nuestro propio gato el mejor (un ejemplar)”. (Minda y Smith, 2001)
Organización jerárquica de categorías
Ahora que conocemos los diferentes enfoques de cómo vamos a formar categorías, veamos la estructura de una categoría y la relación entre categorías. La idea básica es que las categorías más grandes se puedan dividir en categorías más específicas y más pequeñas.
Rosch afirmó que mediante este proceso se crean tres niveles de categorización:

Es interesante que la disminución de la información de básica a superordenada es realmente alta pero que el incremento de la información de básica hacia abajo a subordinada es bastante bajo. Los científicos querían saber si entre estos niveles se prefiere uno sobre los otros. Pidieron a los participantes que nombraran los objetos presentados lo más rápido posible. El resultado fue que los sujetos tendieron a usar el nombre de nivel básico, que incluye la cantidad óptima de información almacenada. Por lo tanto, una imagen de un retriever se llamaría “perro” en lugar de “animal” o “perdiever”. Es importante señalar que los niveles son diferentes para cada persona dependiendo de factores como la experiencia y la cultura.
Un factor que influye en nuestra categorización es el conocimiento mismo. Los expertos prestan más atención a las características específicas de los objetos en su área que lo harían los no expertos. Por ejemplo después de presentar algunas fotos de aves los expertos de aves tienden a decir el nombre subordinado (mirlo, gorrión) mientras que los no expertos solo dicen “pájaro”. El nivel básico en el área de interés de un experto es inferior al nivel básico de un laico. Por tanto, el conocimiento y la experiencia de las personas afectan la categorización
Otro factor es la cultura. Imagínese a un pueblo que vive por ejemplo en estrecho contacto con su entorno natural, y por lo tanto tiene un mayor conocimiento sobre las plantas etc. que, por ejemplo, los estudiantes en Alemania. Si le preguntas a estos últimos qué ven en la naturaleza, utilizan el nivel básico 'árbol' y si haces la misma tarea por las personas más cercanas a la naturaleza tenderán a responder en términos de conceptos de nivel inferior como 'encino'.
Representación de Categorías en el Cerebro
Existe evidencia de que algunas áreas del cerebro son selectivas para diferentes categorías, pero no es muy probable que haya un área cerebral correspondiente para cada categoría. Los resultados de la investigación neurofisiológica apuntan a una especie de doble disociación para seres vivos y no vivos. Se ha encontrado evidencia en estudios de fMRI de que efectivamente están representados en diferentes áreas cerebrales. Es importante denotar que sin embargo existe mucho solapamiento entre la activación de diferentes áreas cerebrales por categorías. Además al acercarse un paso más al área física también hay una conexión con las categorías mentales. Parece que existen neuronas que responden mejor a objetos de una categoría particular, a saber, las llamadas “neuronas específicas de categoría”. Estas neuronas disparan no sólo como respuesta a un objeto sino a muchos objetos dentro de una categoría. Esto lleva a la idea de que probablemente muchas neuronas se disparan si una persona reconoce un objeto en particular y que tal vez estos patrones combinados de las neuronas disparadoras representen el objeto.
Redes Semánticas
El “enfoque de la Red Semántica” propone que los conceptos de la mente estén dispuestos en redes, es decir, en un sistema de almacenamiento funcional para los “significados” de las palabras. Por supuesto, el concepto de red semántica es muy flexible. En una ilustración gráfica de tal red semántica, los conceptos de nuestro diccionario mental están representados por nodos, que de esta manera representan un pedazo de conocimiento sobre nuestro mundo.
Las propiedades de un concepto podrían colocarse, o “almacenarse”, junto a un nodo que represente ese concepto. Los vínculos entre los nodos indican la relación entre los objetos. Los enlaces no sólo pueden mostrar que existe una relación, también pueden indicar el tipo de relación por su longitud, por ejemplo.
Cada concepto en la red está en correlación dinámica con otros conceptos, los cuales pueden tener características o funciones protoípicamente similares.
Modelo de Collins y Quillian
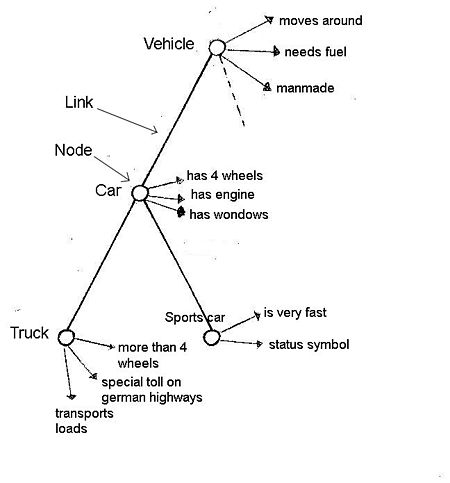
Red Semántica según Collins y Quillian con nodos, enlaces, nombres conceptuales y propiedades.
Uno de los primeros científicos que pensó en modelos estructurales de memoria humana que podrían ejecutarse en una computadora fue Ross Quillian (1967). Junto con Allan Collins, desarrolló la Red Semántica con categorías relacionadas y con una organización jerárquica.
En la imagen del lado derecho, se muestra la red Collins y Quillians con propiedades agregadas en cada nodo. Como ya se mencionó, los esqueleto-nodos están interconectados por enlaces. En los nodos, se agregan nombres de concepto. Al igual que en el párrafo “Organización Jerárquica de Categorías”, los conceptos generales están en la parte superior y los más particulares en la parte inferior. Al mirar el concepto “auto”, se obtiene la información de que un automóvil tiene 4 ruedas, tiene motor, tiene ventanas, y además se mueve, necesita combustible, está hecho por el hombre.
Estas piezas de información deben almacenarse en algún lugar. Tomaría demasiado espacio, si cada detalle debe ser almacenado en todos los niveles. Por lo que la información de un automóvil se almacena a nivel base y más información sobre autos específicos, por ejemplo, BMW, se almacena en el nivel inferior, donde no necesita el hecho de que el BMW también tenga cuatro ruedas, si ya sabe que es un automóvil. Esta forma de almacenar propiedades compartidas en un nodo de nivel superior se llama Economía Cognitiva.
Para no producir redundancias, Collins y Quillian pensaron en esto como un principio de herencia de información. La información, que es compartida por varios conceptos, se almacena en el nodo padre más alto, que contiene la información. Por lo que todos los nodos hijo, que están por debajo del portador de información, también pueden acceder a la información sobre las propiedades. No obstante, hay excepciones. A veces un auto especial no tiene cuatro ruedas, sino tres. Esta propiedad específica se almacena en el nodo hijo.
La estructura lógica de la red es convincente, ya que puede mostrar que el tiempo de recuperación de un concepto y las distancias en la red se correlacionan. La correlación se demuestra mediante la técnica de verificación de oraciones. En experimentos probands tuvieron que responder declaraciones sobre conceptos con “sí” o “no”. De hecho, tardó más en decir “sí”, si el concepto que lleva los nodos estaban más separados.
El fenómeno de que se activan los conceptos adyacentes se denomina activación por propagación. Estos conceptos son mucho más fáciles de acceder por la memoria, son “cebados”. Esto fue estudiado y respaldado por David Meyer y Roger Schaneveldt (1971) con una tarea de decisión léxica. Los probandos tenían que decidir si los pares de palabras eran palabras o no palabras. Eran más rápidos en encontrar pares de palabras reales si los conceptos de las dos palabras estaban cerca en la red pretendida.
Si bien tiene la capacidad de explicar muchas preguntas, el modelo tiene algunas fallas.
El Efecto Tipicalidad es uno de ellos. Se sabe que “los tiempos de reacción para los miembros más típicos de una categoría son más rápidos que para los miembros menos típicos”. (MITECS) Esto contradice los supuestos del modelo de Collins y Quillian, de que la distancia en la red es responsable del tiempo de reacción. Se determinó experimentalmente que algunas propiedades se almacenan en nodos específicos, por lo que la economía cognitiva se pone en duda. Además, hay ejemplos de recuperación de conceptos más rápida aunque las distancias en la red son más largas.
Estos puntos llevaron a otra versión del enfoque de la Red Semántica: Collins y Loftus Model.
Modelo Collins y Loftus
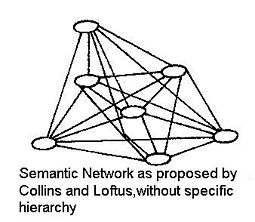
Collins y Loftus (1975) intentaron abandonar estos problemas mediante el uso de vínculos más cortos o más largos dependiendo de la relación e interconexiones entre conceptos que antes no estaban directamente vinculados. También la estructura jerárquica anterior fue sustituida por una estructura más individual de una persona. Sólo por nombrar algunas de las extensiones. Como se muestra en la imagen de la derecha, el nuevo modelo representa diferencias interpersonales, como las adquiridas durante la vida de los humanos. Se manifiestan en la maquetación y las diversas longitudes de los enlaces de los mismos conceptos.
Un ejemplo: El concepto “vehículo” está conectado a automóvil, camión o autobús por enlaces cortos, y a camión de bomberos o ambulancia con enlaces más largos.
Después de estas mejoras, el modelo es tan omnipotente que algunos investigadores lo escasearon por ser demasiado flexible. En su opinión, el modelo ya no es una teoría científica, porque no es desmensurable. Además, no sabemos cuánto tiempo están estos enlaces en nosotros. ¿Cómo deberían ser medibles y podrían realmente?
Enfoque Coneccionista
Cada concepto en una red semántica está en correlación dinámica con otros conceptos que pueden tener características o funciones prototípicamente similares. Las redes neuronales en el cerebro están organizadas de manera similar. Además, es útil incluir las características de “activación de propagación” y “actividad distribuida paralela” en un concepto de red semántica de este tipo para explicar la complejidad del entorno muy sofisticado.
Principios básicos del conexionismo
Los coneccionistas hicieron esto modelando sus redes a partir de redes neuronales en el sistema nervioso. Cada nodo del diagrama representa una unidad de procesamiento similar a una neurona. Estas unidades se pueden dividir en tres subgrupos: Unidades de entrada, que se activan por una estimulación del entorno, unidades ocultas, que reciben señales de una unidad de entrada y las pasan a una unidad de salida y unidades de salida, que muestran un patrón de activación que representa el estímulo inicial. Las conexiones excitadoras e inhibitorias entre unidades al igual que las sinapsis en el cerebro permiten analizar y evaluar la 'entrada'. Para computar el resultado de tales sistemas, es útil adjuntar un cierto 'peso' a la entrada del sistema de conexionistas, que imita la fuerza de un estímulo del sistema nervioso humano.
Es necesario enfatizar que las redes coneccionistas no son modelos de cómo funciona el sistema nervioso. El enfoque de las redes coneccionistas es un enfoque hipotético para representar categorías en patrones de red. Otro nombre para el enfoque coneccionista es el enfoque de Procesamiento Distribuido Parallel, para abreviar PDP, ya que el procesamiento se realiza en líneas paralelas y la salida se distribuye en muchas unidades.
Operación de Redes Coneccionistas
Primero se presenta un estímulo a las unidades de entrada. Entonces los enlaces pasan la señal a las unidades ocultas, que distribuyen la señal a las unidades de salida a través de enlaces adicionales. En la primera prueba, las unidades de salida muestran un patrón incorrecto. Después de muchas repeticiones, el patrón finalmente es correcto. Esto se logra mediante la retropropagación. Las señales de error se envían de vuelta a las unidades ocultas y las señales se vuelven a procesar. Durante estos ensayos repetitivos, los “pesos” de la señal se calibran gradualmente en nombre de las señales de error para obtener por fin un patrón de salida correcto. Después de haber logrado un patrón correcto para un estímulo, el sistema está listo para aprender un nuevo concepto.
Evaluando el conexionismo
El enfoque PDP es importante para los estudios de representación del conocimiento. Está lejos de ser perfecto, pero en movimiento para llegar allí. El proceso de aprendizaje permite al sistema hacer generalizaciones, ya que conceptos similares crean patrones similares. Después de conocer un automóvil, el sistema puede reconocer patrones similares a los de otros autos, o incluso puede predecir cómo se ven otros autos. Además, el sistema está protegido contra restos totales. Un daño a unidades individuales no causará la avería total del sistema, sino que eliminará solo algunos patrones, que utilizan esas unidades. Esto se llama degradación agraciada y a menudo se encuentra en pacientes con lesiones cerebrales. Estos dos argumentos llevan al tercero. El PDP se organiza de manera similar al cerebro humano. Y sobre esta base se han desarrollado algunos programas informáticos efectivos, que fueron capaces de predecir las consecuencias del daño cerebral humano.
Por otro lado, el enfoque coneccionista no está exento de problemas. Los conceptos aprendidos anteriormente pueden superponerse por nuevos conceptos. Además, el PDP no puede explicar procesos más complejos que aprender conceptos. Tampoco puede explicar el fenómeno del aprendizaje rápido, que no requiere un aprendizaje extensivo. Se supone que el aprendizaje rápido tiene lugar en el hipocampo, y que el aprendizaje conceptual y gradual se ubica en la corteza.
En conclusión, el enfoque PDP puede explicar muy bien algunas características de la representación del conocimiento pero falla para algunos procesos complejos.
Representación Mental
Existen diferentes teorías sobre cómo los seres vivos, especialmente los humanos, codifican la información al conocimiento. Podemos pensar en diversas representaciones mentales de un mismo objeto. Al leer la palabra escrita “coche”, llamamos a esto un símbolo discreto. Coincide con todos los autos imaginables y, por lo tanto, no está atado a un vehículo especial. Es una representación abstracta, o amodal. Esto es diferente si en cambio vemos una foto de un auto. Podría ser un deportivo rojo. Ahora hablamos de un símbolo no discreto, una imagen imaginable que aparece frente a nuestro ojo interno y que se ajusta sólo a ciertos autos de apariencia suficientemente similar.
Enfoque proposicional
El Enfoque Proposicional es una forma posible de modelar representaciones mentales en el cerebro humano. Funciona con símbolos discretos que están fuertemente conectados entre sí. El uso de símbolos discretos requiere definiciones claras de cada símbolo, así como información sobre las reglas sintácticas y las dependencias de contexto en las que se pueden usar los símbolos. El símbolo “auto” sólo es comprensible para las personas que sí entienden el inglés y han visto un automóvil antes y por lo tanto saben de qué se trata un automóvil. El Enfoque Proposicional es una forma explícita de explicar la representación mental.
Las definiciones de proposiciones difieren en los diferentes campos de investigación y aún están en discusión. Una posibilidad es la siguiente:” Tradicionalmente en filosofía se hace una distinción entre oraciones y las ideas subyacentes a esas oraciones, llamadas proposiciones. Una sola proposición puede ser expresada por un número casi ilimitado de oraciones. Las proposiciones no son atómicas, sin embargo; pueden dividirse en conceptos atómicos llamados” Conceptos”.
Además, las proposiciones mentales tratan del almacenamiento, recuperación e interconexión de la información como conocimiento en el cerebro humano. Hay una gran discusión, si el cerebro realmente trabaja con proposiciones o si el cerebro procesa su información hacia y desde el conocimiento de otra manera o quizás de más de una manera.
Enfoque de imágenes
Una posible alternativa al Enfoque Proposicional, es el Enfoque de Imágenes. Dado que aquí la representación del conocimiento se entiende como el almacenamiento de imágenes tal como las vemos, también se le llama enfoque analógico o perceptual. En contraste con el Enfoque Proposicional, trabaja con símbolos no discretos y es específico de modalidad. Se trata de una aproximación implícita a la representación mental. El cuadro del auto deportivo incluye implícitamente asientos de cualquier tipo. Si además se menciona que son de color blanquecino, la imagen cambia a una más específica. La forma en que se combinan dos símbolos no discretos no es tan predeterminado como lo es para los símbolos discretos. La imagen de los asientos blanquecinos puede existir sin el auto rojo alrededor, así como el auto rojo lo hacía antes sin los asientos blanquecinos. Las Imágenes y los Enfoques Proposicionales también se discuten en el capítulo 8.