En las secciones anteriores, se introdujeron términos como parámetro poblacional, estadística muestral y sesgo muestral. En esta sección, trataremos de entender qué significan estos términos y cómo se relacionan entre sí.
Cuando se mide una determinada observación de una unidad determinada, como la respuesta de una persona a un ítem con escala Likert, esa observación se denomina respuesta (ver Figura 8.2). En otras palabras, una respuesta es un valor de medición proporcionado por una unidad muestreada. Cada encuestado te dará diferentes respuestas a diferentes ítems en un instrumento. Las respuestas de diferentes encuestados al mismo ítem u observación se pueden graficar en una distribución de frecuencia basada en su frecuencia de ocurrencias. Para un gran número de respuestas en una muestra, esta distribución de frecuencia tiende a parecerse a una curva en forma de campana llamada distribución normal, que puede ser utilizada para estimar las características generales de toda la muestra, como la media de la muestra (promedio de todas las observaciones en una muestra) o desviación estándar (variabilidad o dispersión de observaciones en una muestra). Estas estimaciones de muestra se denominan estadísticas de muestra (una “estadística” es un valor que se estima a partir de datos observados). Las poblaciones también tienen medias y desviaciones estándar que podrían obtenerse si pudiéramos muestrear a toda la población. Sin embargo, dado que nunca se puede muestrear toda la población, las características de la población siempre se desconocen, y se denominan parámetros poblacionales (y no “estadísticos” porque no se estiman estadísticamente a partir de los datos). Los estadísticos muestrales pueden diferir de los parámetros poblacionales si la muestra no es perfectamente representativa de la población; la diferencia entre los dos se denomina error de muestreo. Teóricamente, si pudiéramos aumentar gradualmente el tamaño de la muestra para que la muestra se acerque cada vez más a la población, entonces el error de muestreo disminuirá y un estadístico muestral se aproximará cada vez más al parámetro poblacional correspondiente.
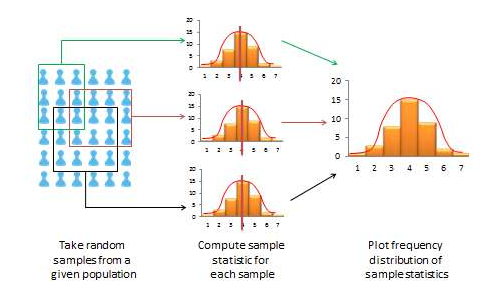
Si una muestra es verdaderamente representativa de la población, entonces las estadísticas de muestra estimadas deben ser idénticas a los parámetros teóricos de la población correspondientes. ¿Cómo sabemos si las estadísticas muestrales están al menos razonablemente cercanas a los parámetros poblacionales? Aquí, necesitamos entender el concepto de una distribución muestral. Imagine que tomó tres muestras aleatorias diferentes de una población determinada, como se muestra en la Figura 8.3, y para cada muestra, derivó estadísticas de muestra como la media de la muestra y la desviación estándar. Si cada muestra aleatoria era verdaderamente representativa de la población, entonces sus tres medias de muestra de las tres muestras aleatorias serán idénticas (e iguales al parámetro poblacional), y la variabilidad en las medias de la muestra será cero. Pero esto es extremadamente improbable, dado que cada muestra aleatoria probablemente constituirá un subconjunto diferente de la población, y por lo tanto, sus medias pueden ser ligeramente diferentes entre sí. Sin embargo, puede tomar estas tres medias de muestra y trazar un histograma de frecuencia de medias de muestra. Si el número de tales muestras aumenta de tres a 10 a 100, el histograma de frecuencia se convierte en una distribución de muestreo. Por lo tanto, una distribución de muestreo es una distribución de frecuencia de un estadístico de muestra (como la media de la muestra) de un conjunto de muestras, mientras que la distribución de frecuencia comúnmente referenciada es la distribución de una respuesta (observación) de una sola muestra. Al igual que una distribución de frecuencias, la distribución de muestreo también tenderá a tener más estadísticas muestrales agrupadas alrededor de la media (que presumiblemente es una estimación de un parámetro poblacional), con menos valores dispersos alrededor de la media. Con un número infinitamente grande de muestras, esta distribución se acercará a una distribución normal. La variabilidad o dispersión de un estadístico muestral en una distribución muestral (es decir, la desviación estándar de un estadístico de muestreo) se denomina su error estándar. En contraste, el término desviación estándar se reserva para la variabilidad de una respuesta observada de una sola muestra.
Figura 8.2. Estadística de muestra
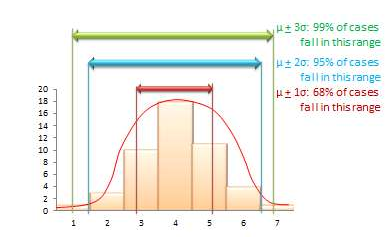
Se presume que el valor medio de un estadístico muestral en una distribución muestral es una estimación del parámetro poblacional desconocido. Con base en la dispersión de esta distribución de muestreo (es decir, con base en el error estándar), también es posible estimar intervalos de confianza para ese parámetro poblacional de predicción. El intervalo de confianza es la probabilidad estimada de que un parámetro de población se encuentre dentro de un intervalo específico de valores estadísticos de muestra. Todas las distribuciones normales tienden a seguir una regla del 68-95-99 por ciento (ver Figura 8.4), que dice que más del 68% de los casos en la distribución se encuentran dentro de una desviación estándar del valor medio (µ + 1σ), más del 95% de los casos en la distribución se encuentran dentro de dos desviaciones estándar de la media ( µ + 2σ), y más del 99% de los casos en la distribución se encuentran dentro de tres desviaciones estándar del valor medio (µ + 3σ). Dado que una distribución de muestreo con un número infinito de muestras se acercará a una distribución normal, se aplica la misma regla 68-95-99, y se puede decir que:
(Estadística de muestra un error estándar) representa un intervalo de confianza de 68% para el parámetro de población.
(Estadística de muestra dos errores estándar) representa un intervalo de confianza del 95% para el parámetro de población.
(Estadística de muestra tres errores estándar) representa un intervalo de confianza del 99% para el parámetro de población.
Figura 8.3. La distribución de muestreo
Una muestra es “sesgada” (es decir, no representativa de la población) si su distribución muestral no puede estimarse o si la distribución muestral viola la regla del 68-95-99 por ciento. Como un aparte, señalar que en la mayoría de los análisis de regresión donde examinamos la significancia de los coeficientes de regresión con p<0.05, estamos intentando ver si el estadístico de muestreo (coeficiente de regresión) predice el parámetro poblacional correspondiente (tamaño verdadero del efecto) con un intervalo de confianza del 95%. Curiosamente, el estándar “seis sigma” intenta identificar defectos de fabricación fuera del intervalo de confianza del 99% o seis desviaciones estándar (la desviación estándar se representa usando la letra griega sigma), representando pruebas de significancia a p<0.01.
Figura 8.4. La regla del 68-95-99 por ciento para el intervalo de confianza


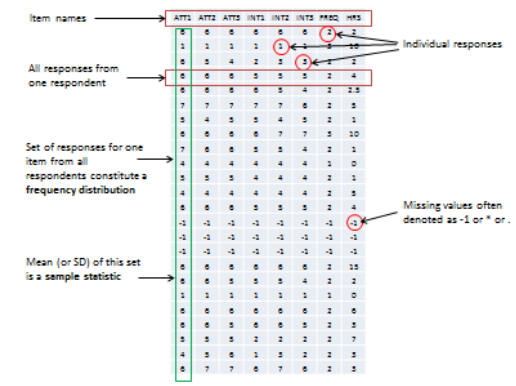
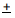 un error estándar) representa un intervalo de confianza de 68% para el parámetro de población.
un error estándar) representa un intervalo de confianza de 68% para el parámetro de población.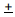 dos errores estándar) representa un intervalo de confianza del 95% para el parámetro de población.
dos errores estándar) representa un intervalo de confianza del 95% para el parámetro de población.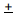 tres errores estándar) representa un intervalo de confianza del 99% para el parámetro de población.
tres errores estándar) representa un intervalo de confianza del 99% para el parámetro de población.