14.6: Observaciones influyentes
- Page ID
- 152300

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Describir lo que hace que un punto influya
- Definir “distancia”
Es posible que una sola observación tenga una gran influencia en los resultados de un análisis de regresión. Por lo tanto, es importante estar alerta ante la posibilidad de observaciones influyentes y tomarlas en consideración a la hora de interpretar los resultados.
Influencia
La influencia de una observación puede pensarse en términos de cuánto diferirían los puntajes previstos para otras observaciones si no se incluyera la observación en cuestión. La D de Cook es una buena medida de la influencia de una observación y es proporcional a la suma de las diferencias cuadradas entre las predicciones realizadas con todas las observaciones en el análisis y las predicciones realizadas dejando fuera la observación en cuestión. Si las predicciones son las mismas con o sin la observación en cuestión, entonces la observación no influye en el modelo de regresión. Si las predicciones difieren mucho cuando la observación no está incluida en el análisis, entonces la observación es influyente.
Una regla general común es que una observación con un valor de D de Cook sobre\(1.0\) tiene demasiada influencia. Al igual que con todas las reglas generales, esta regla debe aplicarse juiciosamente y no irreflexivamente.
La influencia de una observación es función de dos factores:
- Cuánto difiere el valor de la observación en la variable predictora de la media de la variable predictora y
- La diferencia entre la puntuación predicha para la observación y su puntaje real.
El primer factor se llama apalancamiento de la observación. Este último factor se denomina distancia de observación.
Cálculo de Cook D (Opcional)
El primer paso para calcular el valor de D de Cook para una observación es predecir todas las puntuaciones en los datos una vez usando una ecuación de regresión basada en todas las observaciones y una vez usando todas las observaciones excepto la observación en cuestión. El segundo paso es calcular la suma de las diferencias cuadradas entre estos dos conjuntos de predicciones. El paso final es dividir este resultado por\(2\) veces el\(MSE\) (ver la sección sobre particionar la varianza).
Apalancamiento
El apalancamiento de una observación se basa en cuánto difiere el valor de la observación en la variable predictora de la media de la variable predictora. Cuanto mayor sea el apalancamiento de una observación, más potencial tiene para ser una observación influyente. Por ejemplo, una observación con un valor igual a la media en la variable predictora no influye en la pendiente de la línea de regresión independientemente de su valor en la variable criterio. Por otro lado, una observación extrema sobre la variable predictora tiene el potencial de afectar mucho la pendiente.
Cálculo de Apalancamiento (h)
El primer paso es estandarizar la variable predictora para que tenga una media de\(0\) y una desviación estándar de\(1\). Luego, el apalancamiento (\(h\)) se calcula al cuadrado del valor de la observación en la variable predictora estandarizada\(1\), sumando y dividiendo por el número de observaciones.
Distancia
La distancia de una observación se basa en el error de predicción para la observación: Cuanto mayor sea el error de predicción, mayor será la distancia. La medida de distancia más utilizada es la\(\textit{studentized residual}\). El\(\textit{studentized residual}\) para una observación está estrechamente relacionado con el error de predicción para esa observación dividido por la desviación estándar de los errores de predicción. Sin embargo, la puntuación predicha se deriva de una ecuación de regresión en la que no se cuenta la observación en cuestión. Los detalles del cómputo de a\(\textit{studentized residual}\) son un poco complejos y están fuera del alcance de este trabajo.
Incluso una observación con una gran distancia no tendrá tanta influencia si su apalancamiento es bajo. Es la combinación del apalancamiento de una observación y distancia lo que determina su influencia.
Ejemplo\(\PageIndex{1}\)
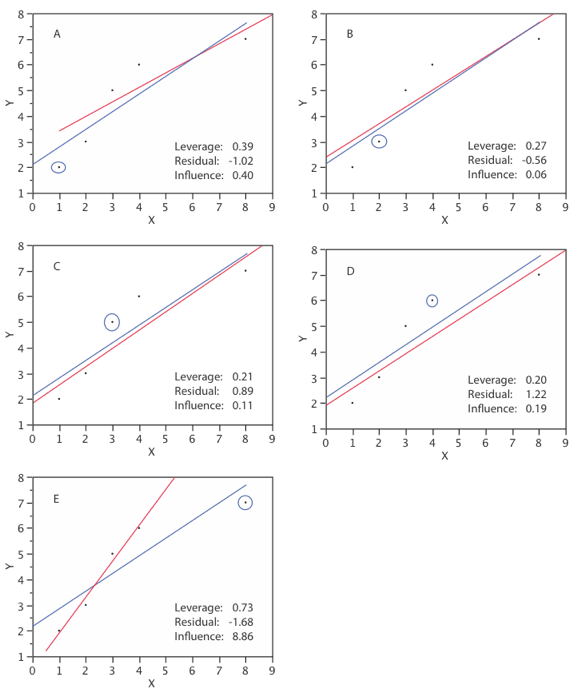
\(\PageIndex{1}\)La tabla muestra el apalancamiento\(\textit{studentized residual}\), y la influencia para cada una de las cinco observaciones en un pequeño conjunto de datos.
Tabla \(\PageIndex{1}\): Datos de ejemplo
| ID | X | Y | h | R | D |
|---|---|---|---|---|---|
| A | 1 | 2 | 0.39 | -1.02 | 0.40 |
| B | 2 | 3 | 0.27 | -0.56 | 0.06 |
| C | 3 | 5 | 0.21 | 0.89 | 0.11 |
| D | 4 | 6 | 0.20 | 1.22 | 0.19 |
| E | 8 | 7 | 0.73 | -1.68 | 8.86 |
En la tabla anterior,\(h\) is the leverage, \(R\) is the \(\textit{studentized residual}\), y\(D\) is Cook's measure of influence.
\(\text{Observation A}\)tiene un apalancamiento bastante alto, un residual relativamente alto y una influencia moderadamente alta.
\(\text{Observation B}\)tiene un apalancamiento pequeño y un residual relativamente pequeño. Tiene muy poca influencia.
\(\text{Observation C}\)tiene un pequeño apalancamiento y un residual relativamente alto. La influencia es relativamente baja.
\(\text{Observation D}\)tiene el apalancamiento más bajo y el segundo residuo más alto. Si bien su residual es mucho mayor que\(\text{Observation A }\), su influencia es mucho menor debido a su bajo apalancamiento.
\(\text{Observation E}\)tiene, con mucho, el mayor apalancamiento y el mayor residuo. Esta combinación de alto apalancamiento y alto residuo hace que esta observación sea extremadamente influyente.
La figura\(\PageIndex{1}\) muestra la línea de regresión para todo el conjunto de datos (azul) y la línea de regresión si no se incluye la observación en cuestión (rojo) para todas las observaciones. La observación en cuestión está enmarcada en un círculo. Naturalmente, la línea de regresión para todo el conjunto de datos es la misma en todos los paneles. El residuo se calcula en relación con la línea para la cual no se incluye en el análisis la observación en cuestión. La observación más influyente es\(\text{Observation E}\) para la cual las dos líneas de regresión son muy diferentes. Esto indica la influencia de esta observación.