
7.9: Lectura de archivos de datos inusuales



- Última actualización
- 31 oct 2022
- Guardar como PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
En esta sección voy a cambiar de tema (¡otra vez!) y pasar a la pregunta de cómo puede cargar datos de una variedad de fuentes diferentes. A lo largo de este libro he asumido que sus datos se almacenan como un archivo.Rdata o como un archivo CSV “correctamente” formateado. Y si es así, entonces las herramientas básicas que discutí en la Sección 4.5 deberían ser bastante suficientes. Sin embargo, en la vida real eso no es una suposición terriblemente plausible de hacer, así que será mejor que hable de algunas de las otras posibilidades con las que podrías encontrarte.
Cargar datos de archivos de texto
Lo primero que debo señalar es que si tus datos se guardan como un archivo de texto pero no están del todo en el formato CSV adecuado, entonces todavía hay bastante posibilidades de que la función read.csv () (o equivalentemente, read.table ()) pueda abrirla. Solo necesita especificar algunos más de los argumentos opcionales a la función. Si escribes? read.csv verás que la función read.csv () en realidad tiene varios argumentos que puedes especificar. Obviamente necesitas especificar el archivo que quieres que cargue, pero todos los demás tienen valores predeterminados sensibles. Sin embargo, a veces necesitarás cambiarlos. Los que a menudo me he encontrado necesitando cambiar son:
encabezado. Muchas veces cuando estás almacenando datos como un archivo CSV, la primera fila en realidad contiene los nombres de las columnas y no los datos. Si eso no es cierto, necesitas establecerheader = FALSO.sep. Como indica el nombre “valor separado por comas”, los valores en una fila de un archivo CSV suelen estar separados por comas. Esto no es universal, sin embargo. En Europa el punto decimal suele escribirse como,en lugar de.y como consecuencia sería algo incómodo de usar,como el separador. Por lo tanto, no es inusual de usar;por ahí. En otras ocasiones, he visto un carácter TAB usado. Para manejar estos casos, necesitaríamos establecersep = “;”osep = “\ t”.cotización. Es convencional en archivos CSV incluir un carácter de cita para datos textuales. Como puede ver al mirar el archivobooksales.csv}, este suele ser un carácter de comilla doble,". Pero a veces no hay ningún carácter de cita en absoluto, o es posible que vea una sola comilla'utilizada en su lugar. En esos casos necesitarías especificarquote = “”oquote = “'”.saltar. En realidad es muy común recibir archivos CSV en los que las primeras filas no tienen nada que ver con los datos reales. En cambio, proporcionan un resumen legible por humanos de dónde provienen los datos, o tal vez incluyen alguna información técnica que no se relaciona con los datos. Para decirle a R que ignore las primeras (digamos) tres líneas, deberá establecerskip = 3na.strings. A menudo obtendrás datos dados con valores faltantes. Por una razón u otra, faltan algunas entradas en la tabla. El archivo de datos necesita incluir una cadena “especial” para indicar que falta la entrada. Por defecto R asume que esta cadena esNA, ya que eso es lo que haría, pero no hay un acuerdo universal sobre qué usar en esta situación. Si el archivo usa???en su lugar, entonces necesitarás establecerna.strings = “???”.
Es un poco agradable poder tener todas estas opciones con las que puedes juguetear. Por ejemplo, eche un vistazo al archivo de datos que se muestra en la Figura 7.1. Este archivo contiene casi los mismos datos que el último archivo (excepto que no tiene encabezado), y usa un montón de características extravagantes que normalmente no ves en los archivos CSV. De hecho, da la casualidad de que voy a tener que cambiar los cinco argumentos mencionados anteriormente para poder cargar este archivo. Así es como lo haría:
data <- read.csv( file = "./rbook-master/data/booksales2.csv", # specify the name of the file
header = FALSE, # variable names in the file?
skip = 8, # ignore the first 8 lines
quote = "*", # what indicates text data?
sep = "\t", # what separates different entries?
na.strings = "NFI" ) # what is the code for missing data?Si ahora echo un vistazo a los datos que he cargado, veo que esto es lo que tengo:
head( data )## V1 V2 V3 V4
## 1 January 31 0 high
## 2 February 28 100 high
## 3 March 31 200 low
## 4 April 30 50 out
## 5 May 31 NA out
## 6 June 30 0 highPorque le dije a R que esperara que * se usara como el carácter de cita en lugar de "; para buscar tabulaciones (que escribimos así:\ t) en lugar de comas, y para saltarse las primeras 8 líneas del archivo, básicamente se cargan los datos correctos. Sin embargo, como booksales2.csv no contiene los nombres de las columnas, R los ha inventado. Mostrando el tipo de imaginación que espero del software insensible, R decidió llamarlos V1, V2, V3 y V4. Por último, debido a que le dije que el archivo usa “NFI” para denotar datos faltantes, R se da cuenta correctamente de que los datos de ventas de mayo realmente faltan.
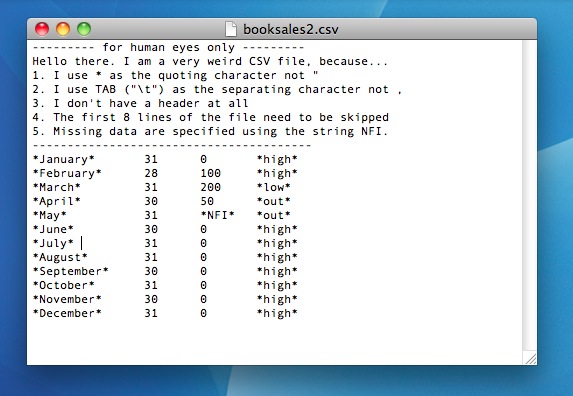
booksales2.csv. Contiene más o menos los mismos datos que el archivo de datos booksales.csv original, pero tiene muchas características muy extravagantes.En la vida real rara vez verás datos tan estúpidamente formateados. 125
Carga de datos de SPSS (y otros paquetes de estadísticas)
Los comandos enumerados anteriormente son los principales que necesitaremos para los archivos de datos en este libro. Pero en la vida real tenemos muchas más posibilidades. Por ejemplo, es posible que desee leer archivos de datos de otros programas de estadísticas. Dado que SPSS es probablemente el paquete de estadísticas más utilizado en psicología, vale la pena mostrar brevemente cómo abrir archivos de datos SPSS (extensión de archivo.sav). Es sorprendentemente fácil. El siguiente extracto debería ilustrar cómo hacerlo:
library( foreign ) # load the package
X <- read.spss( "./rbook-master/data/datafile.sav" ) # create a list containing the data
X <- as.data.frame( X ) # convert to data frameSi desea importar de un archivo SPSS a un marco de datos directamente, en lugar de importar una lista y luego convertir la lista a un marco de datos, también puede hacerlo:
X <- read.spss( file = "datafile.sav", to.data.frame = TRUE )Y eso es prácticamente todo, al menos hasta donde va SPSS. En lo que respecta a otro software estadístico, el paquete extranjero brinda una gran cantidad de posibilidades. Para abrir archivos SAS, consulte las funciones read.ssd () y read.xport (). Para abrir datos de Minitab, la función read.mtp () es lo que estás buscando. Para Stata, la función read.dta () es lo que quieres. Para Systat, la función read.systat () es lo que buscas.
Cargando archivos Excel
Un problema diferente lo plantean los archivos de Excel. A pesar de años de gritarle a la gente por enviarme datos codificados en un formato de datos propietario, me envían muchos archivos Excel. En general R hace un trabajo bastante bueno al abrirlos, pero es un poco quisquilloso porque Microsoft no parece ser terriblemente aficionado a las personas que usan productos que no son de Microsoft, y hacen todo lo posible para que sea complicado. Si obtienes un archivo Excel, mi sugerencia sería abrirlo en Excel (o mejor aún, OpenOffice, ya que eso es software libre) y luego guardar la hoja de cálculo como un archivo CSV. Una vez que tengas los datos en ese formato, puedes abrirlos usando read.csv (). Sin embargo, si por alguna razón estás desesperado por abrir el archivo.xls o .xlsx directamente, entonces puedes usar la función read.xls () en el paquete gdata:
library( gdata ) # load the package
X <- read.xls( "datafile.xlsx" ) # create a data frameEsto suele funcionar. Y si no es así, probablemente estés justificado en “sugerir” a la persona que te envió el archivo que en su lugar debería enviarte un buen archivo CSV limpio.
Cargando archivos Matlab (& Octave)
Muchos laboratorios científicos utilizan Matlab como su plataforma predeterminada para la computación científica; o Octave como alternativa gratuita. Abrir archivos de datos de Matlab (extensión de archivo.mat) un poco más complicado, y si no fuera por el hecho de que Matlab está muy extendido y es una plataforma extremadamente buena, no lo mencionaría. Sin embargo, dado que Matlab es tan ampliamente utilizado, creo que vale la pena discutir brevemente cómo conseguir que Matlab y R jueguen muy bien juntos. La forma de hacerlo es instalar el paquete R.matlab (no olvide instalar también las dependencias). Una vez instalado y cargado el paquete, tiene acceso a la función ReadMat (). Como sabrá cualquier usuario de Matlab, los archivos.mat que produce Matlab son archivos de espacio de trabajo, muy parecidos a los archivos.Rdata que produce R. Por lo tanto, no puede importar un archivo.mat como marco de datos. Sin embargo, puedes importarlo como una lista. Entonces, cuando hacemos esto:
library( R.matlab ) # load the package
data <- readMat( "matlabfile.mat" ) # read the data file to a listEl objeto de datos que se crea será una lista, que contiene una variable por cada variable almacenada en el archivo Matlab. Es bastante sencillo, aunque hay algunas sutilezas que estoy ignorando. En particular, tenga en cuenta que si no tiene el paquete Rcompression, no puede abrir los archivos de Matlab por encima del formato de la versión 6. Entonces, si como yo tienes una versión reciente de Matlab, y no tienes el paquete Rcompression, necesitarás guardar tus archivos usando el indicador -v6 de lo contrario R no puede abrirlos.
Ah, ¿y los usuarios de Octave? El paquete externo contiene un comando read.octave (). Solo por esta vez, el mundo hace la vida más fácil para ustedes que para todos esos cabrones de Matlab.
Guardar otros tipos de datos
Dado que hablé extensamente sobre cómo cargar datos de archivos que no son R, podría valer la pena mencionar brevemente que R también es bastante bueno para escribir datos en otros formatos de archivo además de sus propios formatos nativos. No los voy a discutir en este libro, pero la función write.csv () puede escribir archivos CSV, y la función write.foreign () (en el paquete foráneo) puede escribir archivos SPSS, Stata y SAS. También hay muchos comandos de bajo nivel que puedes usar para escribir información muy específica en un archivo, así que si realmente lo necesitabas podrías crear tu propia función write.obscurefiletype (), pero eso también está muy lejos del alcance de este libro. Por ahora, todo lo que quiero que reconozcan es que esta capacidad está ahí si la necesita.
hecho todavía?
Por supuesto que no. Si no he aprendido nada más sobre R es que nunca has terminado. Este listado ni siquiera se acerca a agotar las posibilidades. Las bases de datos son compatibles con los paquetes RODBC, DBI y RMySQL entre otros. Puede abrir páginas web usando el paquete RCurl. La lectura y escritura de objetos JSON es compatible a través del paquete rjson. Y así sucesivamente. En cierto sentido, la pregunta correcta no es tanto “¿puede R hacer esto?” tanto como “el paradero en la naturaleza de CRAN es el maldito paquete que lo hace?”