
4.4: Normalidad
- Page ID
- 149131

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Objetivos de aprendizaje
- La mayoría de las pruebas para variables de medición asumen que los datos se distribuyen normalmente (se ajustan a una curva en forma de campana) Aquí explico cómo verificar esto y qué hacer si los datos no son normales.
Introducción
Una distribución de probabilidad especifica la probabilidad de obtener una observación en un rango particular de valores; la distribución normal es la curva familiar en forma de campana, con una alta probabilidad de obtener una observación cerca de las probabilidades media e inferior a medida que se aleja de la mitad. Una distribución normal se puede describir completamente con solo dos números, o parámetros, la media y la desviación estándar; todas las distribuciones normales con la misma media y la misma desviación estándar serán exactamente de la misma forma. Uno de los supuestos de un anova y otras pruebas para las variables de medición es que los datos se ajustan a la distribución de probabilidad normal. Debido a que estas pruebas suponen que los datos pueden ser descritos por dos parámetros, la media y la desviación estándar, se denominan pruebas paramétricas.
F ig. 4.4.1 Histograma de pesos secos del crustáceo anfípodo Platorchestia platensis.
Cuando se traza un histograma de frecuencia de datos de medición, las frecuencias deben aproximarse a la distribución normal en forma de campana. Por ejemplo, la figura que se muestra a la derecha es un histograma de pesos secos de anfípodos recién eclosionados (Platorchestia platensis), datos que recopilé tediosamente para mi investigación de doctorado. Se ajusta bastante bien a la distribución normal.
Muchas variables biológicas se ajustan bastante bien a la distribución normal. Esto es resultado del teorema del límite central, que dice que cuando se toma un gran número de números aleatorios, las medias de esos números se distribuyen aproximadamente normalmente. Si piensas en una variable como el peso como resultado de los efectos de un montón de otras variables promediadas juntas—la edad, la nutrición, la exposición a enfermedades, el genotipo de varios genes, etc.— no es de extrañar que se distribuyera normalmente.
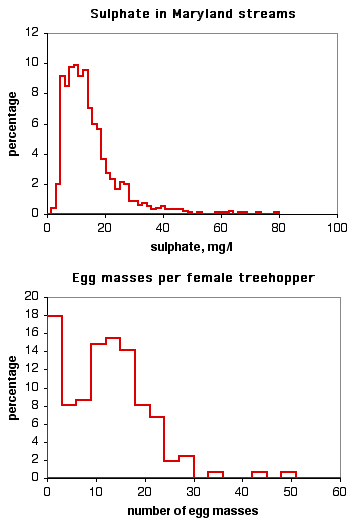
Otros conjuntos de datos no se ajustan muy bien a la distribución normal. El histograma en la parte superior es el nivel de sulfato en los arroyos de Maryland (datos del Maryland Biological Stream Survey). No se ajusta muy bien a la curva normal, porque hay un pequeño número de arroyos con niveles muy altos de sulfato. El histograma en la parte inferior es el número de masas de huevos depositadas por individuos de la raza hospedadora lentago del saltador arbóreo Enchenopa (datos inéditos cortesía de Michael Cast). La curva es bimodal, con un pico alrededor de las masas de\(14\) huevo y el otro en cero.
Las pruebas paramétricas asumen que sus datos se ajustan a la distribución normal. Si tu variable de medición no se distribuye normalmente, puedes estar aumentando tu probabilidad de un resultado falso positivo si analizas los datos con una prueba que asuma normalidad.
Qué hacer con la no normalidad
Una vez que haya recopilado un conjunto de datos de medición, debe mirar el histograma de frecuencia para ver si parece no normal. Existen pruebas estadísticas de la bondad de ajuste de un conjunto de datos a la distribución normal, pero no las recomiendo, porque muchos conjuntos de datos que son significativamente no normales serían perfectamente apropiados para un anova u otra prueba paramétrica. Afortunadamente, un anova no es muy sensible a desviaciones moderadas de la normalidad; estudios de simulación, utilizando una variedad de distribuciones no normales, han demostrado que la tasa de falsos positivos no se ve muy afectada por esta violación del supuesto (Glass et al. 1972, Harwell et al. 1992, Lix et al. 1996). Este es otro resultado del teorema del límite central, que dice que cuando se toma un gran número de muestras aleatorias de una población, las medias de esas muestras se distribuyen aproximadamente normalmente incluso cuando la población no es normal.
Debido a que las pruebas paramétricas no son muy sensibles a las desviaciones de la normalidad, te recomiendo que no te preocupes por ello a menos que tus datos te parezcan muy, muy poco normales. Este es un juicio subjetivo de tu parte, pero no parece haber reglas objetivas sobre cuánta no normalidad es demasiado para una prueba paramétrica. Deberías mirar lo que hacen otras personas en tu campo; si todos transforman el tipo de datos que estás recopilando, o usan una prueba no paramétrica, deberías considerar hacer lo que hacen los demás aunque la no normalidad no te parezca tan mala.
Si tu histograma parece una distribución normal que ha sido empujada hacia un lado, como los datos de sulfato anteriores, deberías probar diferentes transformaciones de datos para ver si alguna de ellas hace que el histograma se vea más normal. Lo mejor es que recopile algunos datos, verifique la normalidad y decida una transformación antes de ejecutar su experimento real; no quiere que la gente cínica piense que probó diferentes transformaciones hasta que encontró una que le dio un resultado signficante para su experimento.
Si tus datos aún se ven severamente no normales sin importar la transformación que apliques, probablemente todavía esté bien analizar los datos usando una prueba paramétrica; simplemente no son tan sensibles a la no normalidad. Sin embargo, es posible que desee analizar sus datos mediante una prueba no paramétrica. Casi todas las pruebas estadísticas paramétricas tienen un sustituto no paramétrico, como la prueba de Kruskal—Wallis en lugar de un anova unidireccional, la prueba de rangos firmados de Wilcoxon en lugar de una\(t\) prueba pareada y la correlación de rangos de Spearman en lugar de regresión lineal/correlación. Estas pruebas no paramétricas no suponen que los datos se ajusten a la distribución normal. Ellos sí asumen que los datos en diferentes grupos tienen la misma distribución entre sí, sin embargo; si diferentes grupos tienen diferentes distribuciones conformadas (por ejemplo, uno está sesgado a la izquierda, otro está sesgado a la derecha), una prueba no paramétrica no será mejor que una paramétrica.
Asimetría y curtosis
Se dice que un histograma con una cola larga en el lado derecho, como los datos de sulfato anteriores, está sesgado hacia la derecha; se dice que un histograma con una cola larga en el lado izquierdo está sesgado hacia la izquierda. Hay una estadística para describir la asimetría\(g_1\), pero no conozco ninguna razón para calcularla; no hay una regla general de que no se deba hacer una prueba paramétrica si\(g_1\) es mayor que algún valor de corte.
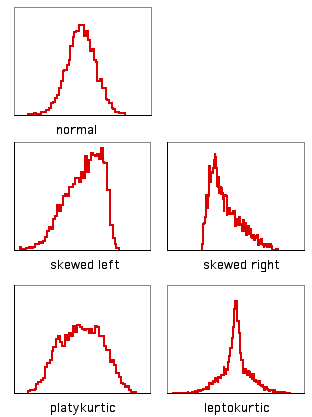
Otra forma en que los datos pueden desviarse de la distribución normal es la curtosis. Un histograma que tiene un pico alto en las colas medias y largas en ambos lados es leptoúrtico; un histograma con una cola media ancha, plana y corta es platykurtic. El estadístico para describir la curtosis es\(g_2\), pero tampoco se me ocurre ninguna razón por la que quieras calcularla.
Cómo mirar la normalidad
Hoja de Cálculo
He escrito una hoja de cálculo que trazará un histograma de frecuencia histogram.xls para datos no transformados, transformados logarítmicos y transformados de raíz cuadrada. Manejará hasta\(1000\) observaciones.
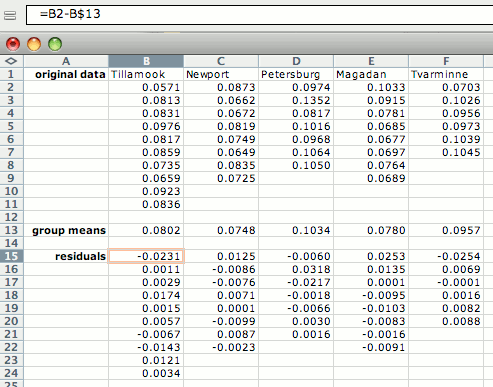
Si no hay suficientes observaciones en cada grupo para verificar la normalidad, es posible que desee examinar los residuos (cada observación menos la media de su grupo). Para ello, abra una hoja de cálculo separada y ponga los números de cada grupo en una columna separada. Después, crear columnas con la media de cada grupo restada de cada observación en su grupo, como se muestra a continuación. Copia estos números en la hoja de cálculo del histograma.
Páginas web
Hay varias páginas web que producirán histogramas, pero la mayoría de ellas no son muy buenas; esta calculadora de histogramas es la mejor que he encontrado.
SAS
Puede usar la opción PLAZAS en PROC UNIVARIATE para obtener una visualización de tallo y hoja, que es una especie de histograma muy crudo. También puede usar la opción HISTOGRAMA para obtener un histograma real, pero solo si sabe cómo enviar la salida a un controlador de dispositivo gráfico.
Referencias
- Glass, G.V., P.D. Peckham, y J.R. Sanders. 1972. Consecuencias de no cumplir con los supuestos subyacentes a los análisis de efectos fijos de varianza y covarianza. Revisión de Investigación Educativa 42:237-288.
- Harwell, M.R., E.N. Rubinstein, W.S. Hayes, y C.C. Olds. 1992. Resumiendo los resultados de Monte Carlo en la investigación metodológica: los casos ANOVA de efectos fijos de uno y dos factores. Revista de Estadística Educativa 17:315-339.
- Lix, L.M., J.C. Keselman, y H.J. Keselman. 1996. Consecuencias de violaciones de suposiciones revisadas: Una revisión cuantitativa de alternativas al análisis unidireccional de la prueba F de varianza. Revisión de Investigación Educativa 66:579-619.