
10.1: Un resumen de suposiciones de modelado
- Page ID
- 150049

Recordemos del Capítulo 4 que identificamos tres supuestos clave sobre el término de error que es necesario para que OLS proporcione estimadores lineales imparciales y eficientes; a) los errores tienen distribuciones idénticas, b) los errores son independientes, c) los errores se distribuyen normalmente. 17
Supuestos de error
- Los errores tienen distribuciones idénticas
E (2i) =σ2E (i2) =σ2
- Los errores son independientes de XX y otros ii
E (i) =E (|xi) =0E (i) =E (|xi) =0
y
E (i) E (j) E (i) E (j) para i≠ ji≠ j
- Los errores se distribuyen normalmente
i∼n (0, σ2) i∼n (0, σ2)
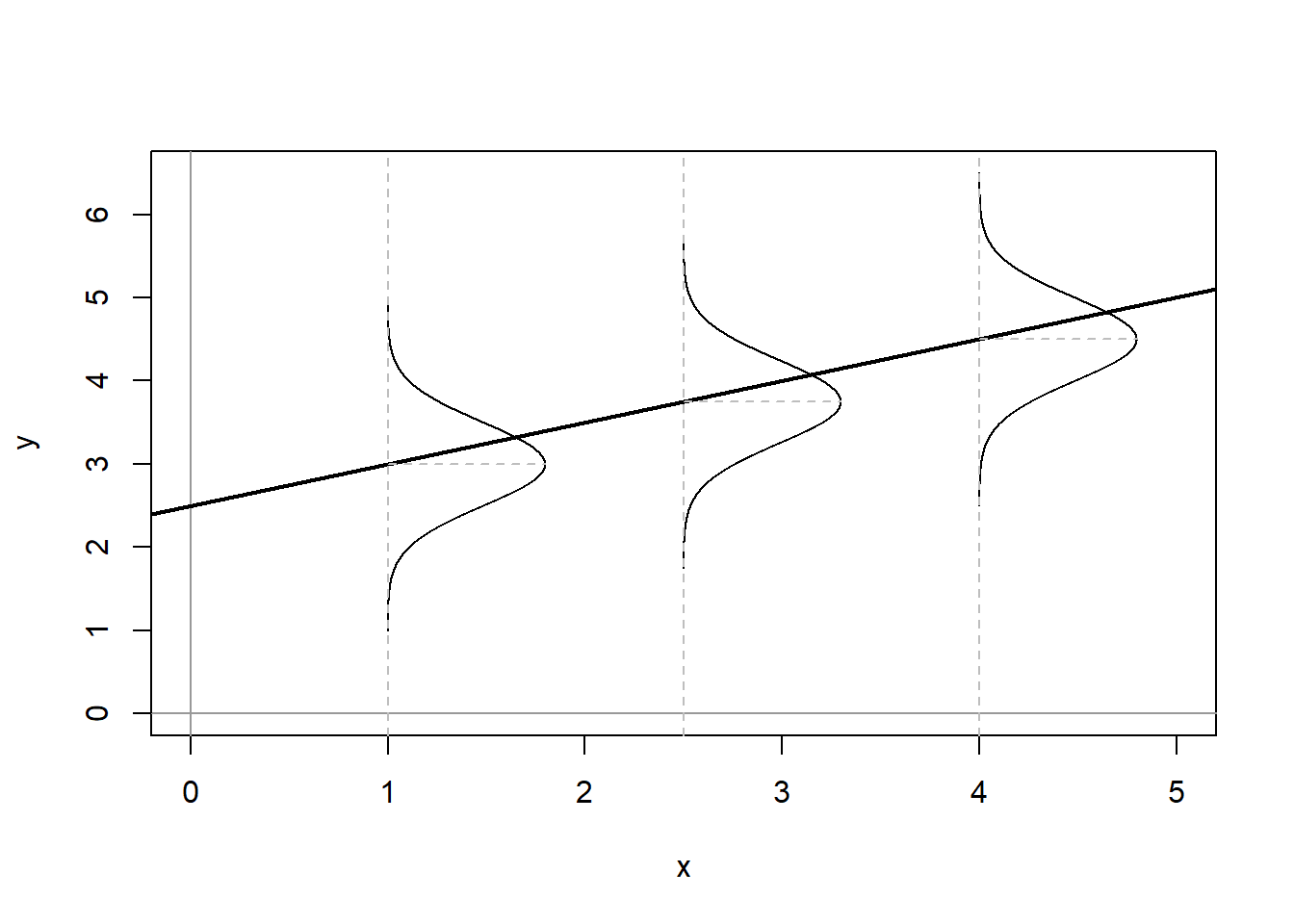
Tomados en conjunto, estos supuestos significan que el término de error tiene una distribución normal, independiente e idéntica (i.i.d. normal). La figura\(\PageIndex{1}\) muestra lo que estos supuestos implicarían para la distribución de residuos alrededor de los valores predichos de YY dado XX.
¿Cómo podemos determinar si nuestros residuos se aproximan al patrón esperado? El enfoque más directo es examinar visualmente la distribución de los residuos en el rango de los valores predichos para YY. Si todo está bien, no debería haber un patrón obvio en los residuos —deberían aparecer como una “trama de estornudos” (es decir, parece que estornudaste en la parcela. ¡Qué grosero!) como se muestra en la Figura\(\PageIndex{2}\).
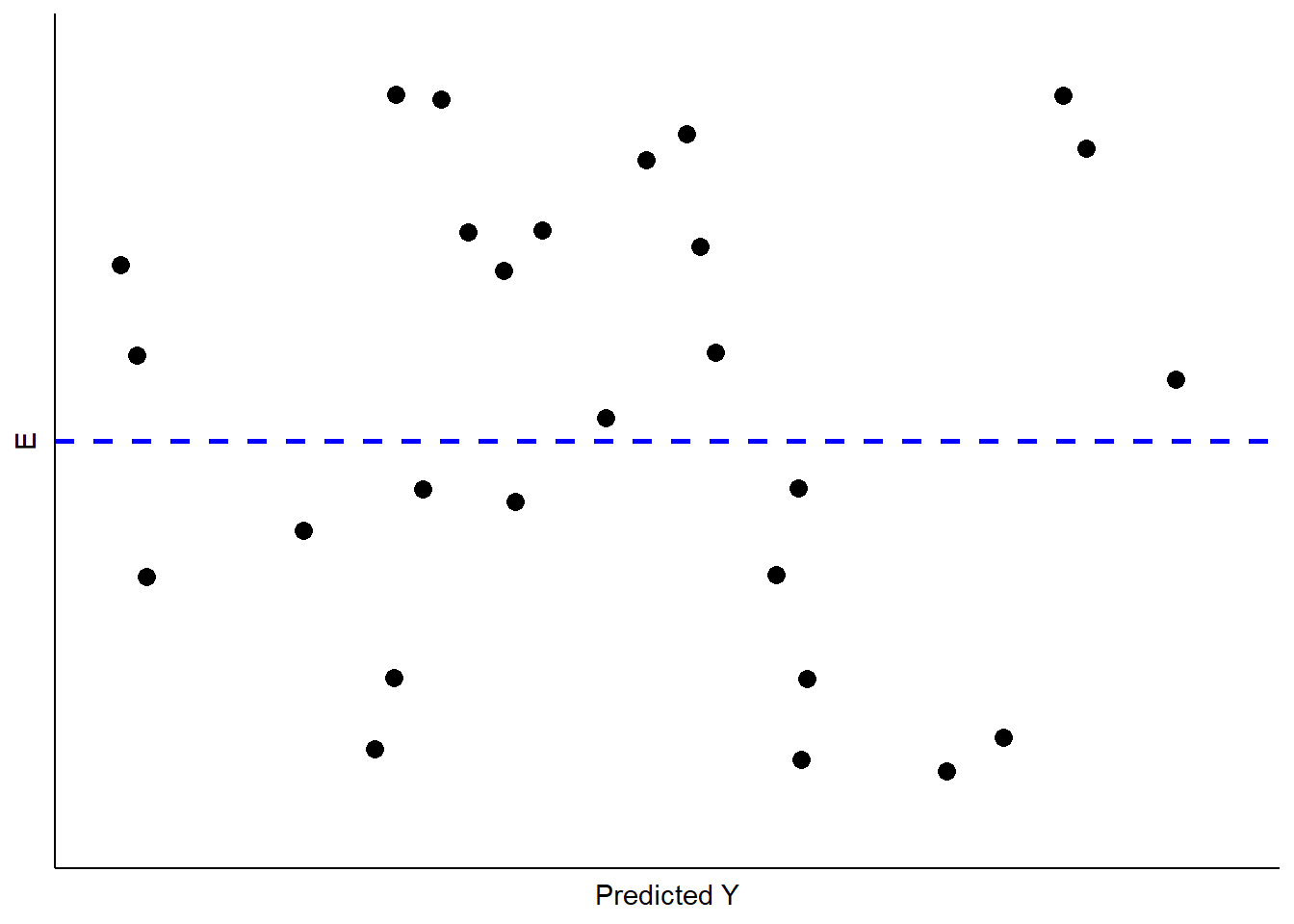
Generalmente, no hay patrón en una parcela de residuos de este tipo de estornudos. Una de las dificultades que tenemos, como seres humanos, es que tendemos a mirar la aleatoriedad y percibir patrones. Nuestros cerebros están conectados para ver patrones, incluso donde no son ninguno. Además, con distribuciones aleatorias, en algunas muestras habrá grumos y huecos que sí parecen representar algún tipo de orden cuando en realidad no hay ninguno. Existe el peligro, entonces, de sobreinterpretar el patrón de los residuos para ver problemas que no están ahí. La clave es saber qué tipo de patrones buscar, así que cuando observes uno lo conocerás.