
10.3: Aplicación de Diagnóstico Residual
- Page ID
- 150050

Hasta aquí hemos utilizado ilustraciones bastante simples de diagnósticos residuales y los tipos de patrones a buscar. Pero hay que advertir que, en aplicaciones reales, los patrones rara vez son tan claros. Entonces caminaremos a través de una sesión de diagnóstico de ejemplo, usando el conjunto de datos tbur.
Nuestro ejemplo de laboratorio en clase se centra en la relación entre la ideología política (“ideología” en nuestro conjunto de datos) como predictor de los riesgos percibidos que plantea el cambio climático (“gccrsk”). El modelo se especifica en R de la siguiente manera:
OLS_env <- lm(ds$glbcc_risk ~ ds$ideol)Usando el comando summary en R, podemos revisar los resultados.
summary(OLS_env)##
## Call:
## lm(formula = ds$glbcc_risk ~ ds$ideol)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.726 -1.633 0.274 1.459 6.506
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.81866 0.14189 76.25 <0.0000000000000002 ***
## ds$ideol -1.04635 0.02856 -36.63 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.479 on 2511 degrees of freedom
## (34 observations deleted due to missingness)
## Multiple R-squared: 0.3483, Adjusted R-squared: 0.348
## F-statistic: 1342 on 1 and 2511 DF, p-value: < 0.00000000000000022Obsérvese que, como se discutió en el capítulo anterior, el valor estimado para BB es negativo y altamente estadísticamente significativo. Esto indica que cuanto más conservador sea el encuestado, menores serán los riesgos percibidos atribuidos al cambio climático. Ahora utilizaremos estos resultados del modelo y los residuales asociados para evaluar los supuestos clave de OLS, comenzando por la linealidad.
10.3.1 Pruebas para no linealidad
Una forma de probar la no linealidad es ajustar el modelo a una forma funcional polinómica. Esto suena impresionante pero es bastante fácil de hacer y entender (¡de verdad!). Todo lo que necesitas hacer es incluir el cuadrado de la variable independiente como segundo predictor en el modelo. Un coeficiente de regresión significativo en la variable cuadrada indica problemas de linealidad. Para ello, primero producimos la variable cuadrada.
#first we square the ideology variable and create a new variable to use in our model.
ds$ideology2 <- ds$ideol^2
summary(ds$ideology2)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.00 16.00 25.00 24.65 36.00 49.00 23A continuación, ejecutamos la regresión con la variable independiente original y nuestra nueva variable cuadrada. Finalmente, verificamos el resultado de regresión.
OLS_env2 <- lm(glbcc_risk ~ ideol + ideology2, data = ds)
summary(OLS_env2)Un coeficiente significativo sobre la variable ideológica cuadrada nos informa que probablemente tenemos un problema de no linealidad. El coeficiente significativo y negativo para el cuadrado de la ideología significa que la curva se inclina (los riesgos percibidos caen más rápido) a medida que la escala se desplaza más arriba en el lado conservador de la escala. Podemos complementar la prueba de regresión polinomial produciendo una parcela residual con una prueba formal de Tukey. La gráfica residual (función de residuos de paquetes de automóviles) muestra los valores ajustados de Pearson frente a los valores observados del modelo. Idealmente, las parcelas producirán líneas rojas planas; las líneas curvas representan la no linealidad. La salida para la prueba de Tukey es visible en el espacio de trabajo RR. La hipótesis nula para la prueba de Tukey es una relación lineal, por lo que un valor p significativo es indicativo de no linealidad. La prueba de tukey se reporta como parte de la función ResidualPlot en el paquete del automóvil.
#A significant p-value indicates non-linearity using the Tukey test
library(car)
residualPlots(OLS_env)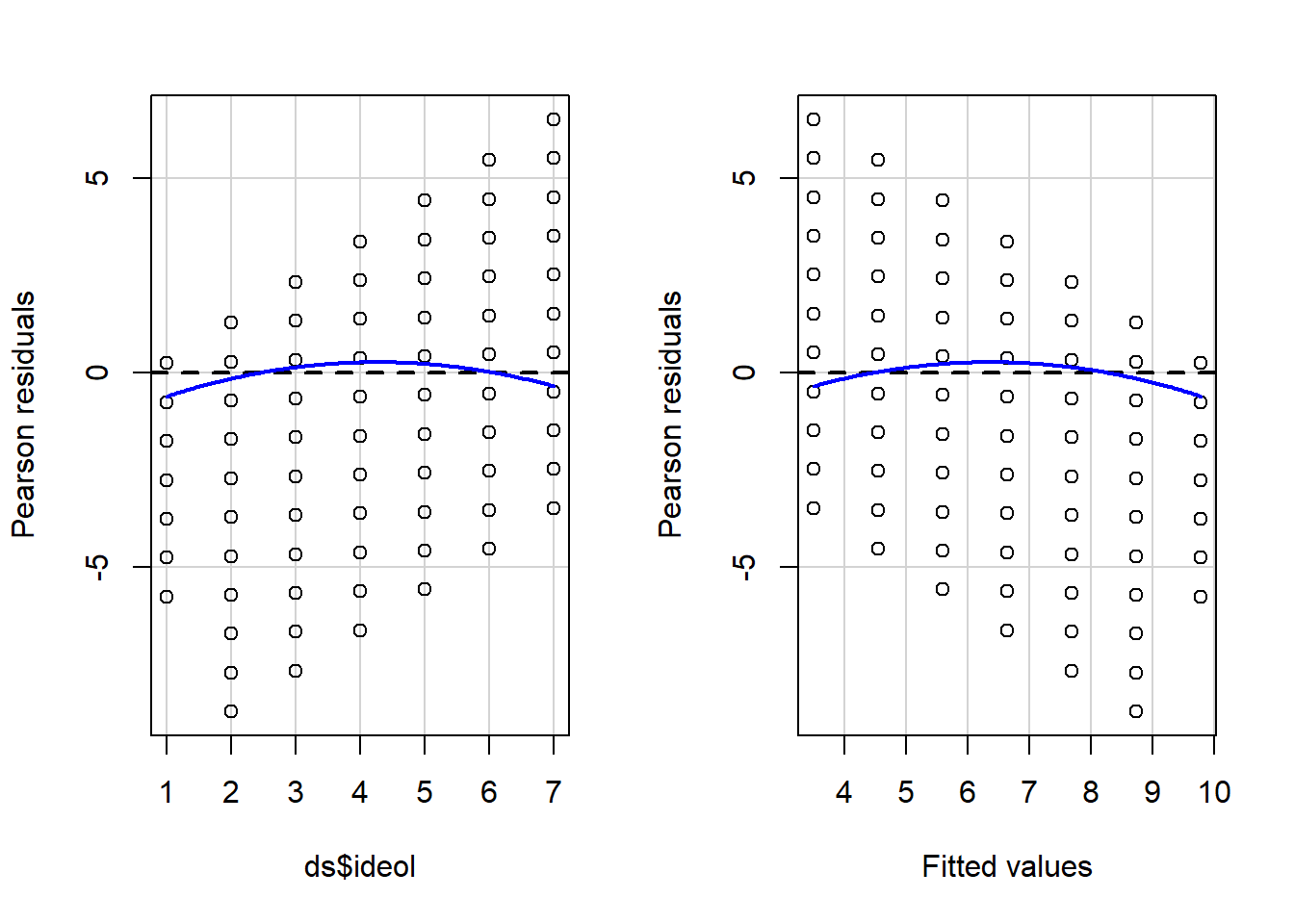
## Test stat Pr(>|Test stat|)
## ds$ideol -5.0181 0.0000005584 ***
## Tukey test -5.0181 0.0000005219 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Las líneas rojas curvas en la Figura\(\PageIndex{7}\) en las parcelas residuales y la prueba significativa de Tukey indican una relación no lineal en el modelo. Esta es una violación grave de un supuesto central de regresión de OLS, lo que significa que es probable que la estimación de BB esté sesgada. Nuestros hallazgos sugieren que la relación entre la ideología y los riesgos percibidos del cambio climático es aproximadamente lineal desde “liberales fuertes” hasta aquellos que son “republicanos inclinados”. Pero los riesgos percibidos parecen disminuir más rápidamente a medida que la escala aumenta hacia un “republicano fuerte”.
10.3.2 Pruebas de normalidad en Residuales Modelo
La prueba de normalidad en los residuos del modelo implicará el uso de muchas de las técnicas demostradas en capítulos anteriores. El primer paso es mostrar gráficamente los residuos para ver qué tan cerca se asemejan los residuos del modelo a una distribución normal. También se incluye una prueba formal de normalidad en la demostración.
Comience por crear un histograma de los residuos del modelo.
OLS_env$residuals %>% # Pipe the residuals to a data frame
data.frame() %>% # Pipe the data frame to ggplot
ggplot(aes(OLS_env$residuals)) +
geom_histogram(bins = 16)
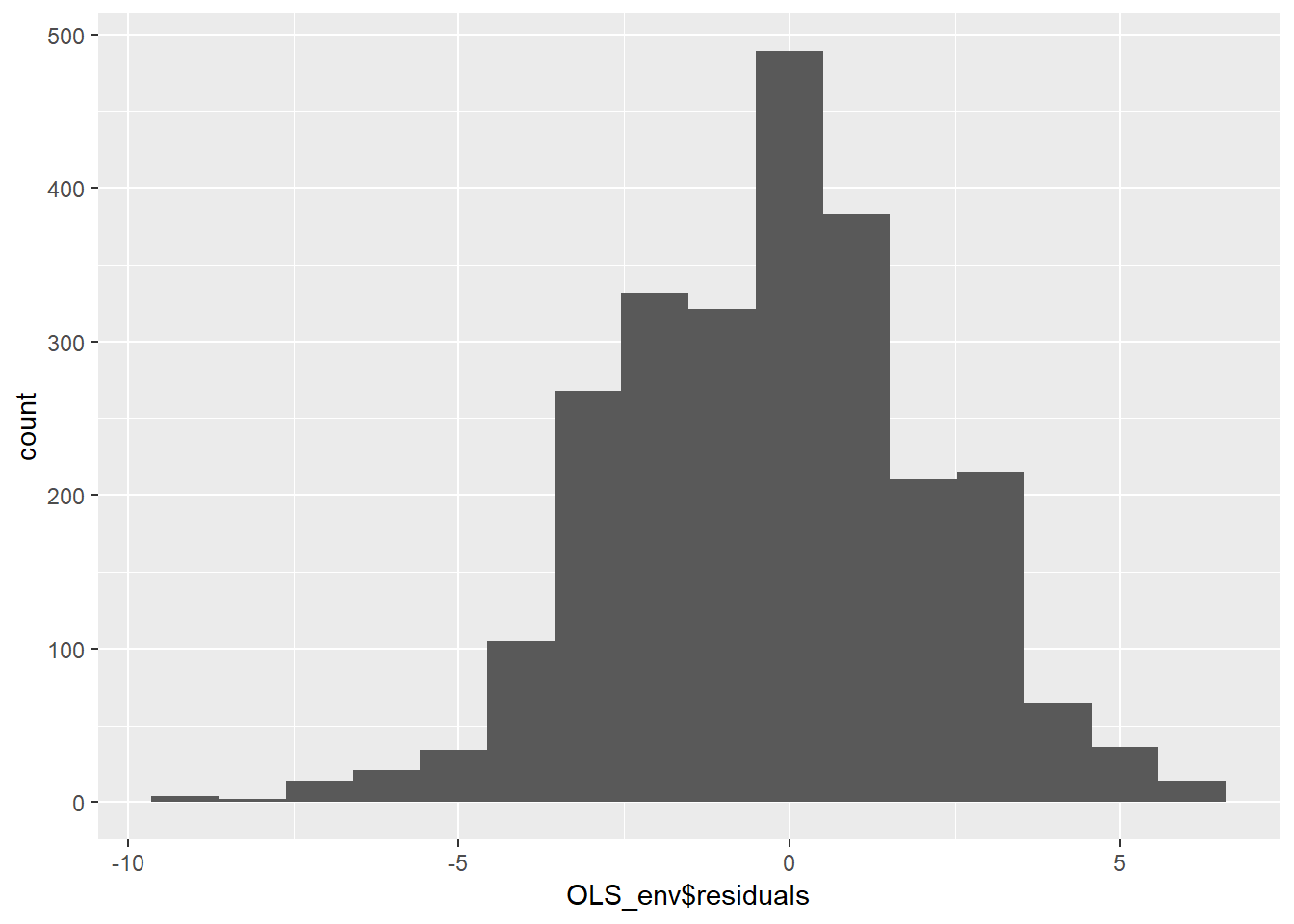
El histograma de la figura 10.8 indica que los residuos están aproximadamente distribuidos normalmente, pero parece haber un sesgo negativo. A continuación, podemos crear una densidad suavizada de los residuos del modelo en comparación con una distribución normal teórica.
OLS_env$residuals %>% # Pipe the residuals to a data frame
data.frame() %>% # Pipe the data frame to ggplot
ggplot(aes(OLS_env$residuals)) +
geom_density(adjust = 2) +
stat_function(fun = dnorm, args = list(mean = mean(OLS_env$residuals),
sd = sd(OLS_env$residuals)),
color = "red")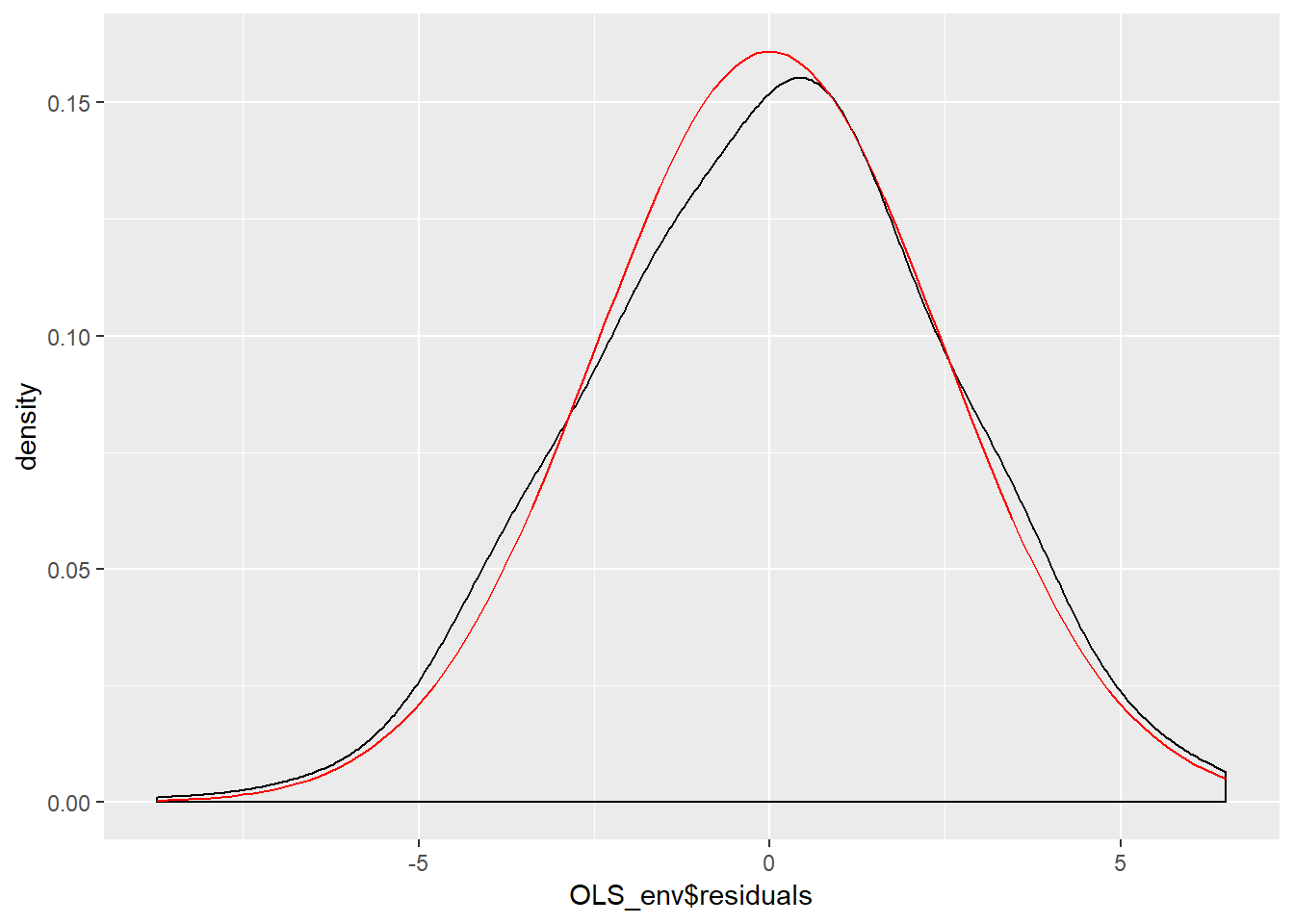
La figura\(\PageIndex{9}\) indica que los residuos del modelo se desvían ligeramente de una distribución normal debido a un sesgo ligeramente negativo y una media mayor de lo que esperaríamos en una distribución normal. Nuestro examen ocular final de los residuos será una gráfica de cuartil% (usando la función stat_qq del paquete ggplot2).
OLS_env$residuals %>% # Pipe the residuals to a data frame
data.frame() %>% # Pipe the data frame to ggplot
ggplot(aes(sample = OLS_env$residuals)) +
stat_qq() +
stat_qq_line()
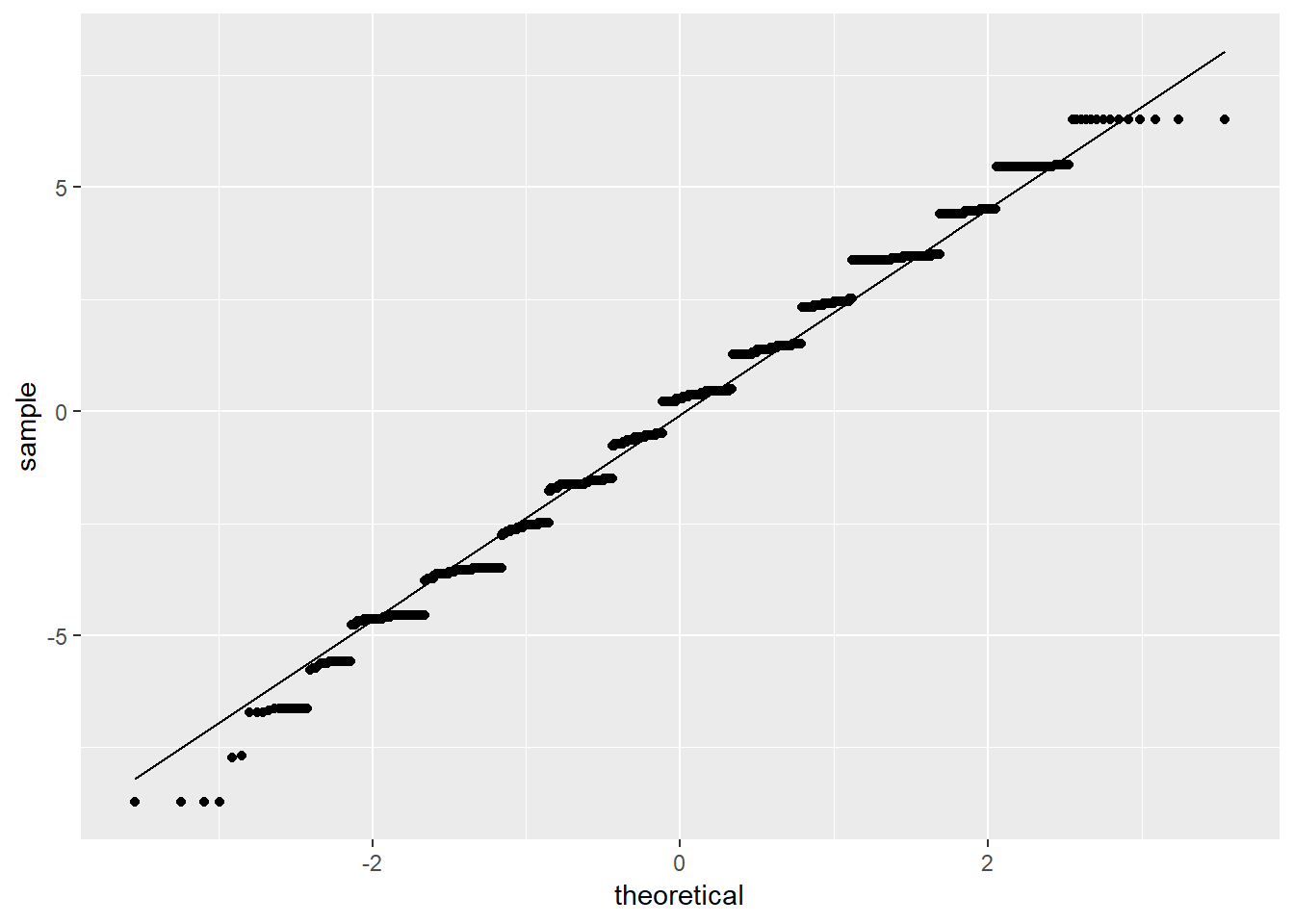
Según la Figura\(\PageIndex{10}\), aparece como si los residuos se distribuyeran normalmente excepto por las colas de la distribución. Tomadas en conjunto, las representaciones gráficas de los residuos sugieren modesta no normalidad. Como paso final, podemos realizar una prueba formal de normalidad de Shapiro-Wilk. La hipótesis nula para una prueba Shapiro-Wilk es una distribución normal, por lo que no queremos ver un valor p significativo.
#a significant value p-value potentially indicates the data is not normally distributed.
shapiro.test(OLS_env$residuals)##
## Shapiro-Wilk normality test
##
## data: OLS_env$residuals
## W = 0.98901, p-value = 0.000000000000551La prueba Shapiro-Wilk confirma lo que observamos en las pantallas gráficas de los residuos del modelo, los residuos normalmente no están distribuidos. Recordemos que nuestra variable dependiente (gccrsk) parece tener una distribución no normal. Esta podría ser la raíz de la no normalidad encontrada en los residuales del modelo. Dada esta información, se deben tomar medidas para asegurar que los residuos del modelo cumplan con los supuestos de OLS requeridos. Una posibilidad sería transformar la variable dependiente (glbccrisk) para inducir una distribución normal. Otro podría ser agregar un término polinomio a la variable independiente (ideología) como se hizo anteriormente. En cualquier caso, necesitaría volver a verificar los residuos para ver si las revisiones del modelo abordaron adecuadamente el problema. ¡Te sugerimos que hagas precisamente eso!
10.3.3 Pruebas de varianza no constante en los residuos
Las pruebas de varianza no constante (heterocedasticidad) en un modelo son bastante sencillas. Podemos comenzar creando una gráfica de nivel expandido que ajuste los residuos studentizados contra los valores ajustados del modelo. Una línea con una pendiente distinta de cero es indicativa de heterocedasticidad. La figura\(\PageIndex{11}\) muestra la parcela de nivel extendido del paquete de autos.
spreadLevelPlot(OLS_env)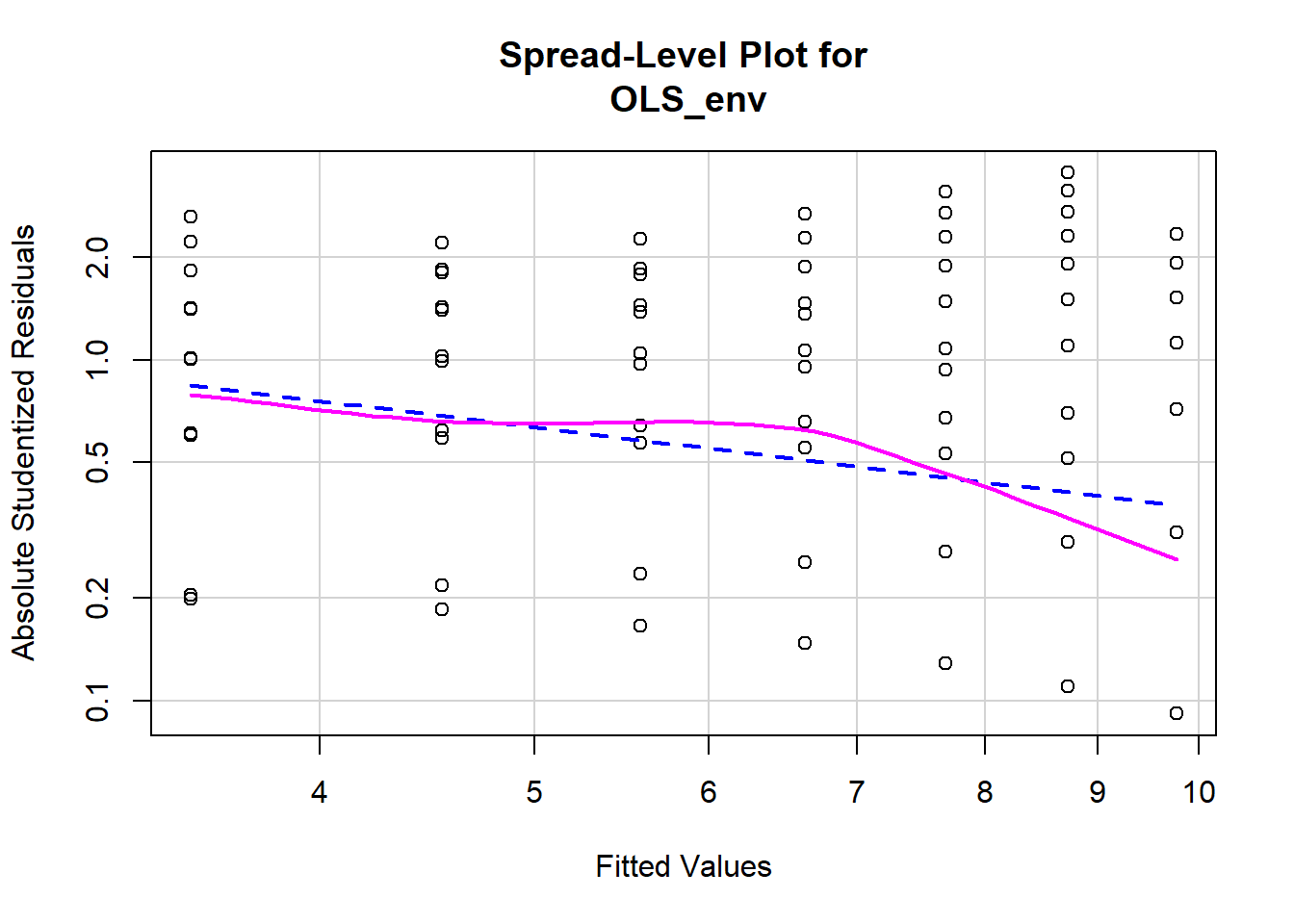
##
## Suggested power transformation: 1.787088dev.off() ## RStudioGD
## 2La pendiente negativa en la línea roja en la Figura\(\PageIndex{11}\) indica que el modelo puede contener heterocedasticidad. También podemos realizar una prueba formal de varianza no constante. La hipótesis nula es la varianza constante, por lo que no queremos ver un valor p significativo.
#a significant value indicates potential heteroscedasticity issues.
ncvTest(OLS_env)## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 68.107 Df = 1 p = 0.0000000000000001548597El valor p significativo en la prueba de varianza no constante nos informa que existe un problema con la heterocedasticidad en el modelo. Esta es otra violación de los supuestos centrales de la regresión de OLS, y pone en duda nuestras pruebas de hipótesis.
10.3.4 Examinar datos atípicos
Hay varias formas de examinar observaciones periféricas en una regresión de OLS. Esta sección ilustra brevemente un subconjunto de pruebas analíticas que proporcionarán una evaluación útil de valores atípicos potencialmente importantes. El propósito de examinar datos atípicos es doble. Primero, queremos asegurarnos de que no haya datos mal codificados o inválidos que influyan en nuestra regresión. Por ejemplo, una observación alejada con un valor de “-99” probablemente sesgaría nuestros resultados y obviamente necesita ser corregida. Segundo, los datos atípicos pueden indicar la necesidad de reconceptualizar teóricamente nuestro modelo. Quizás la relación en el modelo está mal especificada, con valores atípicos en los extremos de una variable sugiriendo una relación no lineal. O puede ser que un subconjunto de casos responda de manera diferente a la variable independiente, y por lo tanto deben ser tratados como “casos especiales” en el modelo. Examinar los valores atípicos nos permite identificar y abordar estos problemas potenciales.
Una de las primeras cosas que podemos hacer es realizar una Prueba Bonferroni Outlier. Las pruebas de valores atípicos de Bonferroni utilizan una distribución tt para probar si el estado atípico del valor residual studentizado más grande del modelo es estadísticamente diferente de las otras observaciones del modelo. Un valor p significativo indica un valor atípico extremo que merece un examen más detallado. Utilizamos la función OutlierTest en el paquete del automóvil para realizar una prueba de valor atípico de Bonferroni.
#a significant p-value indicates extreme case for review
outlierTest(OLS_env)## No Studentized residuals with Bonferonni p < 0.05
## Largest |rstudent|:
## rstudent unadjusted p-value Bonferonni p
## 589 -3.530306 0.00042255 NADe acuerdo con la salida de R, el valor p de Bonferroni para el residuo mayor (absoluto) no es estadísticamente significativo. Si bien esta prueba es importante para identificar una observación externa potencialmente significativa, no es una panacea para verificar patrones en datos periféricos. A continuación examinaremos las df.betas del modelo para ver qué observaciones ejercen más influencia en los coeficientes de regresión del modelo. DFBetasDFbetas son medidas de cuánto cambia el coeficiente de regresión cuando se omite la observación ii. Valores mayores indican una observación que tiene una influencia considerable en el modelo.
Un método útil para encontrar observaciones dfbeta es usar la función DFBetaPlot en el paquete de autos. Especificamos la opción id.n=2 para mostrar los dos df.betas más grandes. Ver figura 10.12.
plotdb<-dfbetaPlots(OLS_env, id.n=3)
# Check the observations with high dfbetas.
# We see the values 589 and 615 returned.
# We only want to see results from columns gccrsk and ideology in tbur.data.
ds[c(589,615),c("glbcc_risk", "ideol")]## glbcc_risk ideol
## 589 0 2
## 615 0 2Estas observaciones son interesantes porque identifican un problema potencial en la especificación de nuestro modelo. Ambas observaciones se consideran valores atípicos porque los encuestados se autoidentificaron como “liberales” (ideología = 1) y calificaron su riesgo percibido de cambio climático global como 0. Estos valores se desvían sustancialmente de la norma para otros liberales fuertes en el conjunto de datos. Recuerden, como vimos antes, nuestro modelo tiene un problema con la no linealidad —estas observaciones periféricas parecen corroborar este hallazgo. El examen de los valores atípicos arroja algo de luz sobre el tema.
Finalmente, podemos producir una gráfica que combine residuos estudentificados, “valores hat” y distancias D de Cook (estas son medidas de la cantidad de influencia que las observaciones tienen en el modelo) usando círculos como indicador de influencia: cuanto mayor sea el círculo, mayor será la influencia. La figura\(\PageIndex{13}\) muestra la gráfica de influencia combinada. Además, la función InfluencePlot devuelve los valores de mayor influencia.
influencePlot(OLS_env)
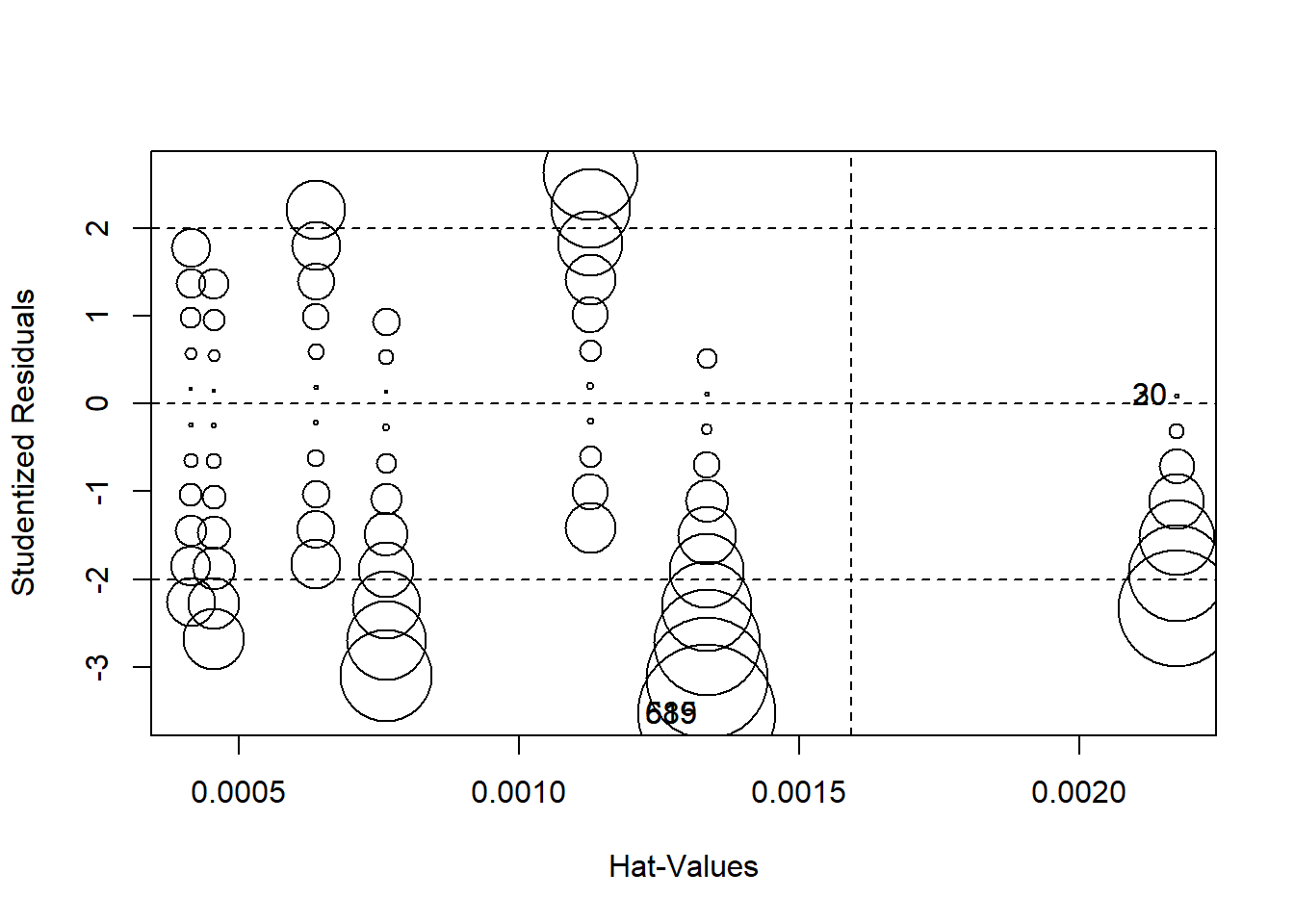
## StudRes Hat CookD
## 20 0.09192603 0.002172497 0.000009202846
## 30 0.09192603 0.002172497 0.000009202846
## 589 -3.53030574 0.001334528 0.008289418537
## 615 -3.53030574 0.001334528 0.008289418537La figura\(\PageIndex{13}\) indica que hay una serie de casos que ameritan un examen más detenido. Ya estamos familiarizados con 589 y 615 Agreguemos 20, 30, 90 y 1052.
#review the results
ds[c(589,615,20,30,90,1052),c("glbcc_risk", "ideol")]## glbcc_risk ideol
## 589 0 2
## 615 0 2
## 20 10 1
## 30 10 1
## 90 10 1
## 1052 3 6Una toma importante de un examen visual de estas observaciones es que no parece haber ningún dato completamente mal codificado o inválido que afecte a nuestro modelo. En general, incluso las observaciones más influyentes no parecen ser casos inverosímiles. Las observaciones 589 y 615 19 presentan un problema interesante respecto a las especificaciones teóricas y del modelo. Estas observaciones representan a los encuestados que se autoinformaron como “liberales” (ideology=2) y también calificaron el riesgo percibido de cambio climático global como 0 de cada 10. Por lo tanto, estas observaciones se desvían de los valores esperados del modelo (los encuestados “liberales fuertes”, en promedio, creían que el cambio climático global representa un alto riesgo). Anteriormente en nuestras pruebas diagnósticas, encontramos un problema con la no linealidad. En conjunto, parece que la no linealidad en nuestro modelo se debe a observaciones en los extremos ideológicos. Una forma de abordar este problema es incluir una variable ideológica cuadrada (un polinomio) en el modelo, como se ilustra anteriormente en este capítulo. Sin embargo, también es importante destacar esta relación no lineal en la conceptualización teórica de nuestro modelo. Quizás hay algo especial en las personas con ideologías extremas que hay que tener en cuenta a la hora de intentar predecir el riesgo percibido del cambio climático global. Este hallazgo también debería informar nuestro examen de las predicciones posteriores a la estimación, algo que se cubrirá más adelante en este texto.