
12.8: Consideraciones finales
- Page ID
- 150751

Correlaciones, aunque simples de calcular, y son muy complejas, y hay muchos temas adicionales que debemos considerar. Analizaremos dos de los problemas más comunes que afectan nuestras correlaciones, así como discutiremos algunas otras correlaciones y métodos de reporte que pueda encontrar.
Restricción de rango
La fuerza de una correlación depende de cuánta variabilidad hay en cada una de las variables\(X\) y\(Y\). Esto es evidente en la fórmula para Pearson\(r\), que utiliza tanto la covarianza (basada en la suma de productos, que proviene de las puntuaciones de desviación) como la desviación estándar de ambas variables (que se basan en las sumas de cuadrados, que también provienen de puntuaciones de desviación). Así, si reducimos la cantidad de variabilidad en una o ambas variables, nuestra correlación bajará. La falta de captura de la variabilidad completa de una variabilidad se llama restricción de rango.
Echa un vistazo a Figuras\(\PageIndex{1}\) y\(\PageIndex{2}\) a continuación. El primero muestra una fuerte relación (\(r\)= 0.67) entre dos variables. Un óvalo se superpone encima de él para hacer la relación aún más distinta. El segundo muestra los mismos datos, pero se ha eliminado la mitad inferior de la\(X\) variable (todas las puntuaciones por debajo de 5), lo que hace que nuestra relación (nuevamente representada por un óvalo rojo) se vuelva mucho más débil (\(r\)= 0.38). Así, la restricción de rango ha truncado (hecho más pequeño) nuestra correlación observada.
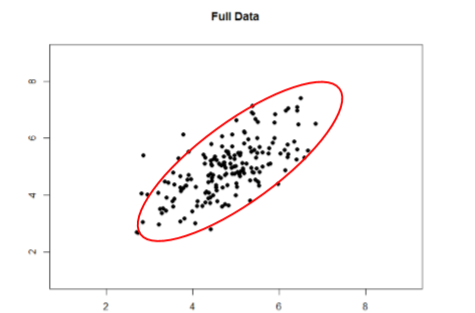
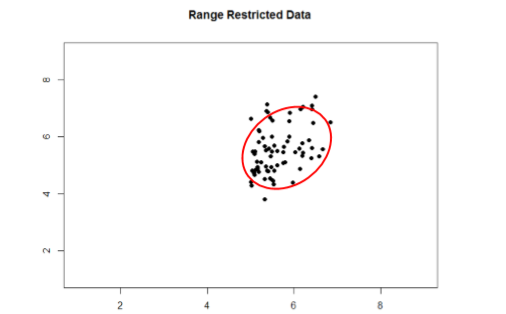
A veces la restricción de rango ocurre por diseño. Por ejemplo, rara vez contratamos a personas a las que les va mal en las solicitudes de empleo, por lo que no tendríamos el rango más bajo de esas variables predictoras. Otras veces, causamos inadvertidamente restricción de rango al no muestrear adecuadamente nuestra población. Si bien existen formas de corregir la restricción de rango, son complicadas y requieren mucha información que tal vez no se conozca, por lo que es mejor tener mucho cuidado durante el proceso de recolección de datos para evitarlo.
Valores atípicos
Otro tema que puede hacer que el tamaño observado de nuestra correlación sea inapropiadamente grande o pequeño es la presencia de valores atípicos. Un valor atípico es un punto de datos que se aleja del resto de las observaciones en el conjunto de datos. A veces los valores atípicos son el resultado de una entrada incorrecta de datos, respuestas deficientes o intencionalmente engañosas, o una simple posibilidad aleatoria. Otras veces, sin embargo, representan a personas reales con valores significativos sobre nuestras variables. La distinción entre valores atípicos significativos y accidentales es difícil que se basa en el juicio pericial del investigador. A veces, eliminaremos el valor atípico (si pensamos que es un accidente) o podemos decidir mantenerlo (si encontramos que las puntuaciones siguen siendo significativas aunque sean diferentes).
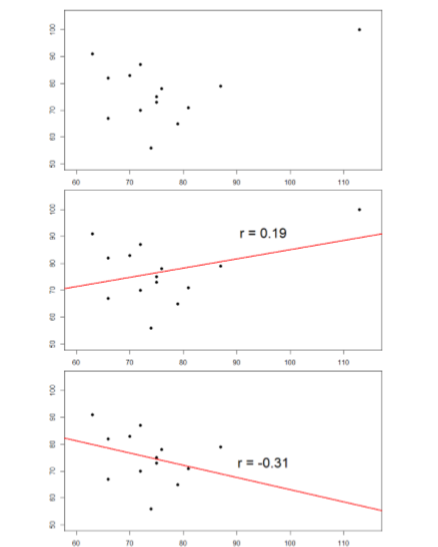
Las gráficas que aparecen a continuación en la Figura\(\PageIndex{3}\) muestran los efectos que un valor atípico puede tener sobre los datos. En la primera, tenemos nuestro conjunto de datos en bruto. Se puede ver en la esquina superior derecha que hay una observación atípica que está muy lejos del resto de nuestras observaciones tanto sobre las variables como sobre\(X\) las\(Y\) variables. En el medio, vemos la correlación calculada cuando incluimos el valor atípico, junto con una línea recta que representa la relación; aquí, es una relación positiva. En la tercera imagen, vemos la correlación después de eliminar el valor atípico, junto con una línea que muestra la dirección una vez más. ¡No solo se hizo más fuerte la correlación, sino que cambió de dirección por completo!
En general, hay tres efectos que un valor atípico puede tener sobre una correlación: puede cambiar la magnitud (hacerlo más fuerte o más débil), puede cambiar la significación (hacer que una correlación no significativa sea significativa o viceversa), y/o puede cambiar la dirección (hacer una relación positiva negativa o vice versa). Los valores atípicos son un gran problema en conjuntos de datos pequeños donde una sola observación puede tener un peso fuerte en comparación con el resto. Sin embargo, a medida que nuestros tamaños de muestras se vuelven muy grandes (en cientos), los efectos de los valores atípicos disminuyen porque son superados por el resto de los datos. Sin embargo, no importa cuán grande sea un conjunto de datos, siempre es una buena idea seleccionar valores atípicos, tanto estadísticamente (usando análisis que no cubrimos aquí) como visualmente (usando diagramas de dispersión).
Otros Coeficientes de Correlación
En este capítulo nos hemos centrado en Pearson\(r\) como nuestro coeficiente de correlación porque es muy común y muy útil. Existen, sin embargo, muchas otras correlaciones por ahí, cada una de las cuales está diseñada para un tipo diferente de datos. El más común de estos es el rho (\(ρ\)) de Spearman, que está diseñado para ser utilizado en datos ordinales en lugar de datos continuos. Este es un análisis muy útil si tenemos datos clasificados o nuestros datos no se ajustan a la distribución normal. Hay aún más correlaciones para las categorías ordenadas, pero son mucho menos comunes y están más allá del alcance de este capítulo.
Además, los principios de las correlaciones subyacen a muchos otros análisis avanzados. En el siguiente capítulo, aprenderemos sobre la regresión, que es una forma formal de correr y analizar una correlación que puede extenderse a más de dos variables. La regresión es una técnica muy poderosa que sirve de base incluso para nuestros modelos estadísticos más avanzados, por lo que lo que hemos aprendido en este capítulo abrirá la puerta a todo un mundo de posibilidades en el análisis de datos.
Matrices de Correlación
Muchos estudios de investigación analizan la relación entre más de dos variables continuas. En tales situaciones, podríamos simplemente enumerar todas nuestras correlaciones, pero eso ocuparía mucho espacio y dificultaría encontrar rápidamente la relación que estamos buscando. En su lugar, creamos matrices de correlación para que podamos mostrar nuestros resultados de manera rápida y sencilla. Una matriz es como una cuadrícula que contiene nuestros valores. Hay una fila y una columna para cada una de nuestras variables, y las intersecciones de las filas y columnas para diferentes variables contienen la correlación para esas dos variables.
Al inicio del capítulo, vimos diagramas de dispersión que presentaban datos de correlaciones entre la satisfacción laboral, el bienestar, el agotamiento y el desempeño laboral. Podemos crear una matriz de correlación para mostrar rápidamente los valores numéricos de cada uno. Dicha matriz se muestra a continuación.
| Satisfacción | Bienestar | Burnout | Desempeño | |
|---|---|---|---|---|
| Satisfacción | 1.00 | |||
| Bienestar | 0.41 | 1.00 | ||
| Burnout | -0.54 | -0.87 | 1.00 | |
| Desempeño | 0.08 | 0.21 | -0.33 | 1.00 |
Observe que hay valores de 1.00 donde se cruzan cada fila y columna de la misma variable. Esto se debe a que una variable se correlaciona perfectamente consigo misma, por lo que el valor siempre es exactamente 1.00. También observe que las celdas superiores se dejan en blanco y solo se rellenan las celdas por debajo de la diagonal de 1s. Esto se debe a que las matrices de correlación son simétricas: tienen los mismos valores por encima de la diagonal que por debajo de ella. Llenar ambos lados proporcionaría información redundante y dificultaría un poco la lectura de la matriz, por lo que dejamos en blanco el triángulo superior.
Las matrices de correlación son una forma muy condensada de presentar muchos resultados rápidamente, por lo que aparecen en casi todos los estudios de investigación que utilizan variables continuas. Muchas matrices también incluyen columnas que muestran las medias variables y desviaciones estándar, así como asteriscos que muestran si cada correlación es estadísticamente significativa o no.