3.12: Medidas de Variabilidad
- Page ID
- 152238

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Calcula el rango
- Calcula la varianza en la población
- Calcula la desviación estándar a partir de la varianza
¿Qué es la variabilidad?
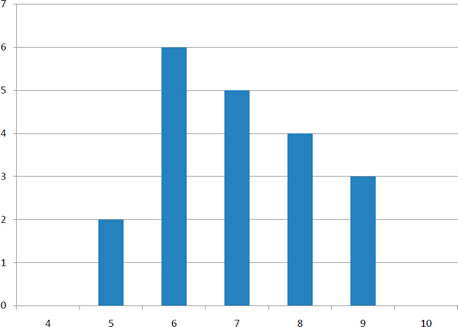
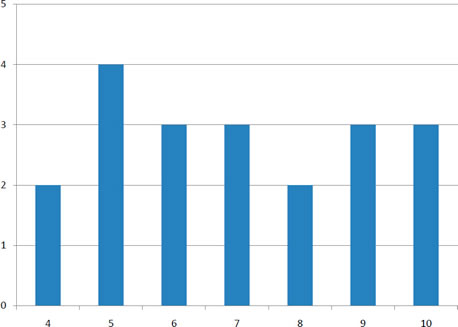
La variabilidad se refiere a lo “extendido” que está un grupo de puntajes. Para ver a qué nos referimos con spread out, considera gráficas en la Figura\(\PageIndex{1}\). Estas gráficas representan las puntuaciones en dos cuestionarios. La puntuación media para cada cuestionario es\(7.0\). A pesar de la igualdad de medios, se puede ver que las distribuciones son bastante diferentes. Específicamente, los puntajes\(\text{Quiz 1}\) puestos están más densamente empaquetados y los de\(\text{Quiz 2}\) arriba están más dispersos. Las diferencias entre los estudiantes fueron mucho mayores en adelante\(\text{Quiz 2}\) que en\(\text{Quiz 1}\).
\(\text{Quiz 1}\)
\(\text{Quiz 1}\)
Figura\(\PageIndex{1}\) : Gráficas de barras de dos cuestionarios
Los términos variabilidad, dispersión y dispersión son sinónimos, y se refieren a cómo se extiende una distribución. Así como en la sección sobre tendencia central donde discutimos medidas del centro de una distribución de puntajes, en este capítulo discutiremos medidas de la variabilidad de una distribución. Existen cuatro medidas de variabilidad de uso frecuente: el rango, rango intercuartil, varianza y desviación estándar. En los próximos párrafos, veremos cada una de estas cuatro medidas de variabilidad con más detalle.
Rango
El rango es la medida de variabilidad más simple de calcular, y una que probablemente hayas encontrado muchas veces en tu vida. El rango es simplemente el puntaje más alto menos el puntaje más bajo. Tomemos algunos ejemplos. ¿Cuál es el rango del siguiente grupo de números:\({10, 2, 5, 6, 7, 3, 4}\)? Bueno, el número más alto es\(10\), y el número más bajo es\(2\), entonces\(10 - 2 = 8\). El rango es\(8\). Tomemos otro ejemplo. Aquí hay un conjunto de datos con\(10\) números:\({99, 45, 23, 67, 45, 91, 82, 78, 62, 51}\). ¿Cuál es el rango? El número más alto es\(99\) y el número más bajo es\(23\), por lo que\(99 - 23\) es igual\(76\); el rango es\(76\). Consideremos ahora los dos cuestionarios que se muestran en la Figura\(\PageIndex{1}\). En\(\text{Quiz 1}\), la puntuación más baja es\(5\) y la puntuación más alta es\(9\). Por lo tanto, el rango es\(4\). El rango en\(\text{Quiz 2}\) fue mayor: la puntuación más baja fue\(4\) y la puntuación más alta fue\(10\). Por lo tanto el rango es\(6\).
Intercuartil
El rango intercuartílico (IQR) es el rango de la mitad\(50\%\) de las puntuaciones en una distribución. Se calcula de la siguiente manera:
\[IQR = 75^{th} percentile - 25^{th} percentile\]
Porque\(\text{Quiz 1}\), el\(75^{th}\) percentil es\(8\) y el\(25^{th}\) percentil es\(6\). El rango intercuartílico es por lo tanto\(2\). Porque\(\text{Quiz 2}\), que tiene mayor difusión, el\(75^{th}\) percentil es\(9\), el\(25^{th}\) percentil es\(5\), y el rango intercuartílico es\(4\). Recordemos que en la discusión de las parcelas de caja, el\(75^{th}\) percentil se llamó bisagra superior y el\(25^{th}\) percentil se llamó bisagra inferior. Usando esta terminología, el rango intercuartílico se conoce como el\(H\) -spread.
Una medida de variabilidad relacionada se llama rango semi-intercuartil. El rango semiintercuartílico se define simplemente como el rango intercuartílico dividido por\(2\). Si una distribución es simétrica, la mediana más o menos el rango semiintercuartil contiene la mitad de las puntuaciones en la distribución.
Varianza
La variabilidad también se puede definir en términos de cuán cerca están las puntuaciones en la distribución a la mitad de la distribución. Usando la media como la medida de la mitad de la distribución, la varianza se define como la diferencia cuadrada promedio de las puntuaciones a partir de la media. Los datos de\(\text{Quiz 1}\) se muestran en la Tabla\(\PageIndex{1}\). La puntuación media es\(7.0\). Por lo tanto, la columna “Desviación de la Media” contiene la puntuación menos\(7\). La columna “Desviación Cuadrada” es simplemente la columna anterior al cuadrado.
| Puntuaciones | Desviación de la Media | Desviación Cuadrada |
|---|---|---|
| 9 | 2 | 4 |
| 9 | 2 | 4 |
| 9 | 2 | 4 |
| 8 | 1 | 1 |
| 8 | 1 | 1 |
| 8 | 1 | 1 |
| 8 | 1 | 1 |
| 7 | 0 | 0 |
| 7 | 0 | 0 |
| 7 | 0 | 0 |
| 7 | 0 | 0 |
| 7 | 0 | 0 |
| 6 | -1 | 1 |
| 6 | -1 | 1 |
| 6 | -1 | 1 |
| 6 | -1 | 1 |
| 6 | -1 | 1 |
| 6 | -1 | 1 |
| 5 | -2 | 4 |
| 5 | -2 | 4 |
| Medios | ||
| 7 | 0 | 1.5 |
Una cosa que es importante notar es que la desviación media de la media es\(0\). Este siempre será el caso. La media de las desviaciones cuadradas es\(1.5\). Por lo tanto, la varianza es\(1.5\). Cálculos análogos con\(\text{Quiz 2}\) muestran que su varianza es\(6.7\). La fórmula para la varianza es:
\[s^2=\frac{\sum (X-\mu )^2}{N}\]
donde\(\sigma ^2\) está la varianza,\(\mu\) es la media, y\(N\) es el número de números. Para\(\text{Quiz 1}\),\(\mu = 7\) y\(N = 20\).
Si la varianza en una muestra se usa para estimar la varianza en una población, entonces la fórmula anterior subestima la varianza y se debe usar la siguiente fórmula:
\[s^2=\frac{\sum (X-M)^2}{N-1}\]
donde\(s^2\) es la estimación de la varianza y\(M\) es la media muestral. Nótese que\(M\) es la media de una muestra tomada de una población con una media de\(\mu\). Dado que, en la práctica, la varianza suele calcularse en una muestra, esta fórmula es la más utilizada. La simulación “estimación de varianza” ilustra el sesgo en la fórmula con\(N\) en el denominador.
Tomemos un ejemplo concreto. Supongamos que los puntajes\({1, 2, 4,\: and\; 5 }\) fueron muestreados de una población mayor. Para estimar la varianza en la población se calcularía de la\(s^2\) siguiente manera:
\[M = \dfrac {1 + 2 + 4 + 5}{4} = \dfrac {12}{4} = 3\]
\[\begin{align*} s^2 &= \dfrac{[(1-3)^2 + (2-3)^2 + (4-3)^2 + (5-3)^2]}{(4-1)}\\ &= \dfrac{(4 + 1 + 1 + 4)}{3}\\ &= \dfrac{10}{3}\\ &= 3.333 \end{align*}\]
Existen fórmulas alternativas que pueden ser más fáciles de usar si estás haciendo tus cálculos con una calculadora manual. Debes tener en cuenta que estas fórmulas están sujetas a error de redondeo si tus valores son muy grandes y/o tienes un número extremadamente grande de observaciones.
\[\sigma ^2=\cfrac{\sum X^2-\cfrac{(\sum X)^2}{N}}{N}\]
y
\[s^2=\cfrac{\sum X^2-\cfrac{(\sum X)^2}{N}}{N-1}\]
Para este ejemplo,
\[\sum X^2=1^2+2^2+4^2+5^2=46\]
\[\dfrac {(\sum X)^2}{N}=\dfrac {(1+2+4+5)^2}{4}=\dfrac {144}{4}=36\]
\[\sigma ^2=\dfrac {(46-36)}{4}=2.5\]
\[s^2=\dfrac {(46-36)}{3}=3.333\; \; \text{as with the other formula}\]
Desviación estándar
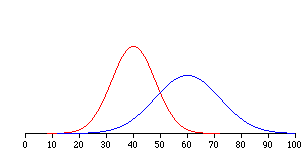
La desviación estándar es simplemente la raíz cuadrada de la varianza. Esto hace que las desviaciones estándar de las dos distribuciones de cuestionarios\(1.225\) y\(2.588\). La desviación estándar es una medida especialmente útil de variabilidad cuando la distribución es normal o aproximadamente normal (ver Capítulo sobre Distribuciones Normales) porque se puede calcular la proporción de la distribución dentro de un número dado de desviaciones estándar de la media. Por ejemplo,\(68\%\) de la distribución está dentro de una desviación estándar de la media y aproximadamente\(95\%\) de la distribución está dentro de dos desviaciones estándar de la media. Por lo tanto, si tuvieras una distribución normal con una media de\(50\) y una desviación estándar de\(10\), entonces\(68\%\) de la distribución estaría entre\(50 - 10 = 40\) y\(50 +10 =60\). De igual manera, sobre\(95\%\) de la distribución sería entre\(50 - 2 \times 10 = 30\) y\(50 + 2 \times 10 = 70\). El símbolo para la desviación estándar de población es\(\sigma\); el símbolo para una estimación calculada en una muestra es\(s\). La figura\(\PageIndex{2}\) muestra dos distribuciones normales. La distribución roja tiene una media de\(40\) y una desviación estándar de\(5\); la distribución azul tiene una media de\(60\) y una desviación estándar de\(10\). Para la distribución roja,\(68\%\) de la distribución es entre\(35\) y\(45\); para la distribución azul,\(68\%\) está entre\(50\) y\(70\).