
3.4: Fracciones, recuentos y rangos- datos secundarios

- Última actualización
- 31 oct 2022
- Guardar como PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Estos tipos de datos surgen de la modificación de los datos “primarios”, originales, principalmente de datos clasificados o nominales que no pueden analizarse de frente. Cerca de los datos secundarios hay una idea de datos composicionales que son descripciones cuantitativas de las partes del todo (probabilidades, proporciones, porcentajes etc.)
Los porcentajes, proporciones y fracciones (ratios) son bastante comunes y no necesitan explicación detallada. Así es como calcular porcentajes (redondeados a números enteros) para nuestros datos de sexo:
Código3.4.1 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
sex <- c("male", "female", "male", "male", "female", "male", "male")
sex.t <- table(sex)
round(100*sex.t/sum(sex.t))
Dado que es tan fácil mentir con proporciones, siempre deben ser suministradas con los datos originales. Por ejemplo, la mortalidad del 50% parece extremadamente alta pero si se descubre que solo hubo 2 pacientes, entonces la impresión es completamente diferente.
Las relaciones son particularmente útiles cuando los objetos medidos tienen valores absolutos ampliamente variables. Por ejemplo, el peso no es muy útil en medicina mientras que la relación altura-peso permite diagnósticos exitosos.
Los recuentos son solo números de elementos individuales dentro de las categorías. En R, la forma más fácil de obtener recuentos es el comando table ().
Hay muchas formas de visualizar recuentos y porcentajes. Bu default, R traza tablas unidimensionales (recuentos) con líneas verticales simples (prueba plot (sex.t) tú mismo).
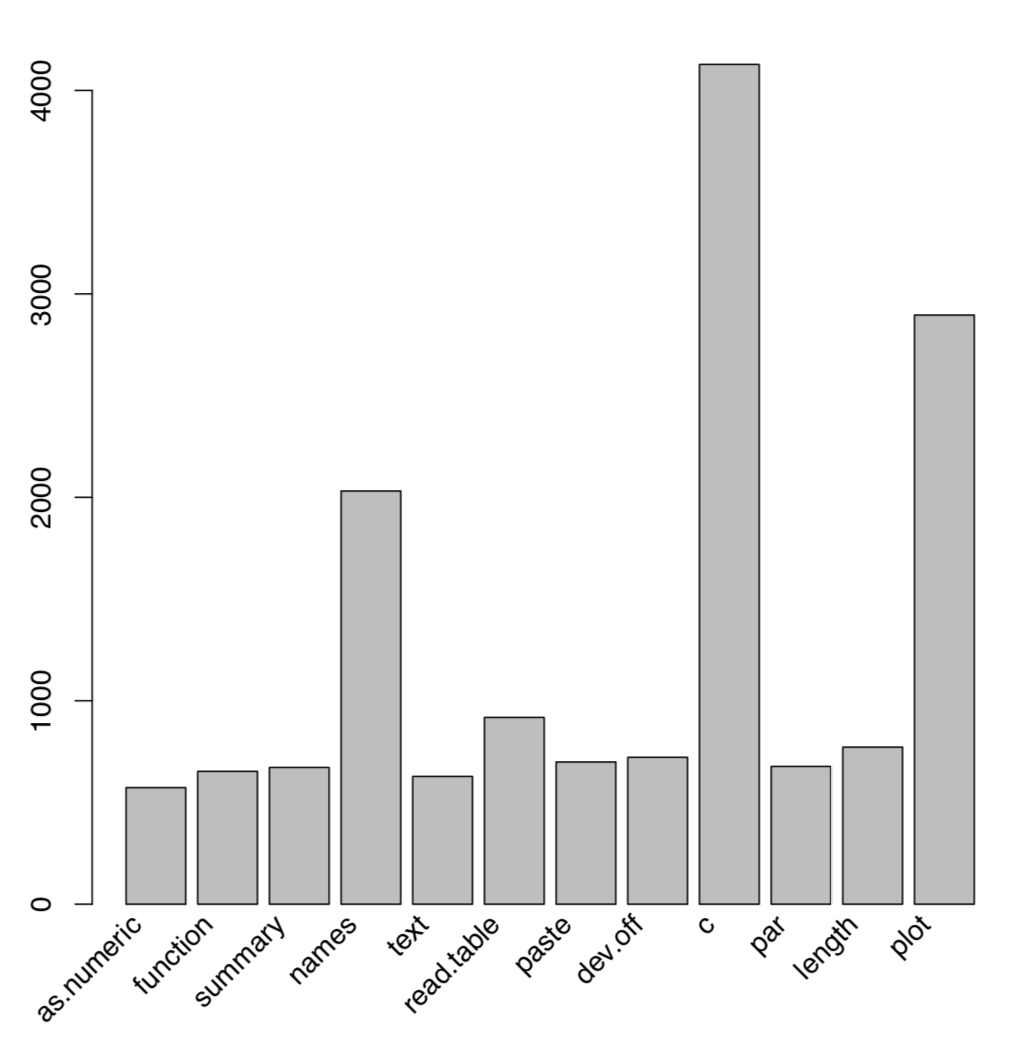
Más populares son los gráficos circulares y las gráficas de barras. No obstante, representan mal los datos. Hubo múltiples experimentos cuando se les pidió a las personas que buscaran diferentes tipos de parcelas, y luego reportaran números que realmente recuerden. Puedes ejecutar este experimento tú mismo. La figura3.4.1 es una gráfica de barras de los doce comandos R principales:
Código3.4.2 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
load("data/com12.rd")
exists("com12") # check if our object is here
com12.plot <- barplot(com12, names.arg="")
text(com12.plot, par("usr")[3]*2, srt=45, pos=2, xpd=TRUE, labels=names(com12))
(Cargamos () 'archivo binario ed para evitar usar comandos que aún no aprendimos; para cargar el archivo binario de Internet, use load (url (...)) . Para que las etiquetas de barra se vean mejor, aplicamos aquí el “truco” con rotación. La solución mucho más simple pero menos estética es barplot (com12, las=2).)
Intente mirar esta trama de barras durante 3 a 5 minutos, luego retírese de este libro e informe los números que se ven allí, desde el más grande hasta el más pequeño. Comparar con la respuesta del final del capítulo.
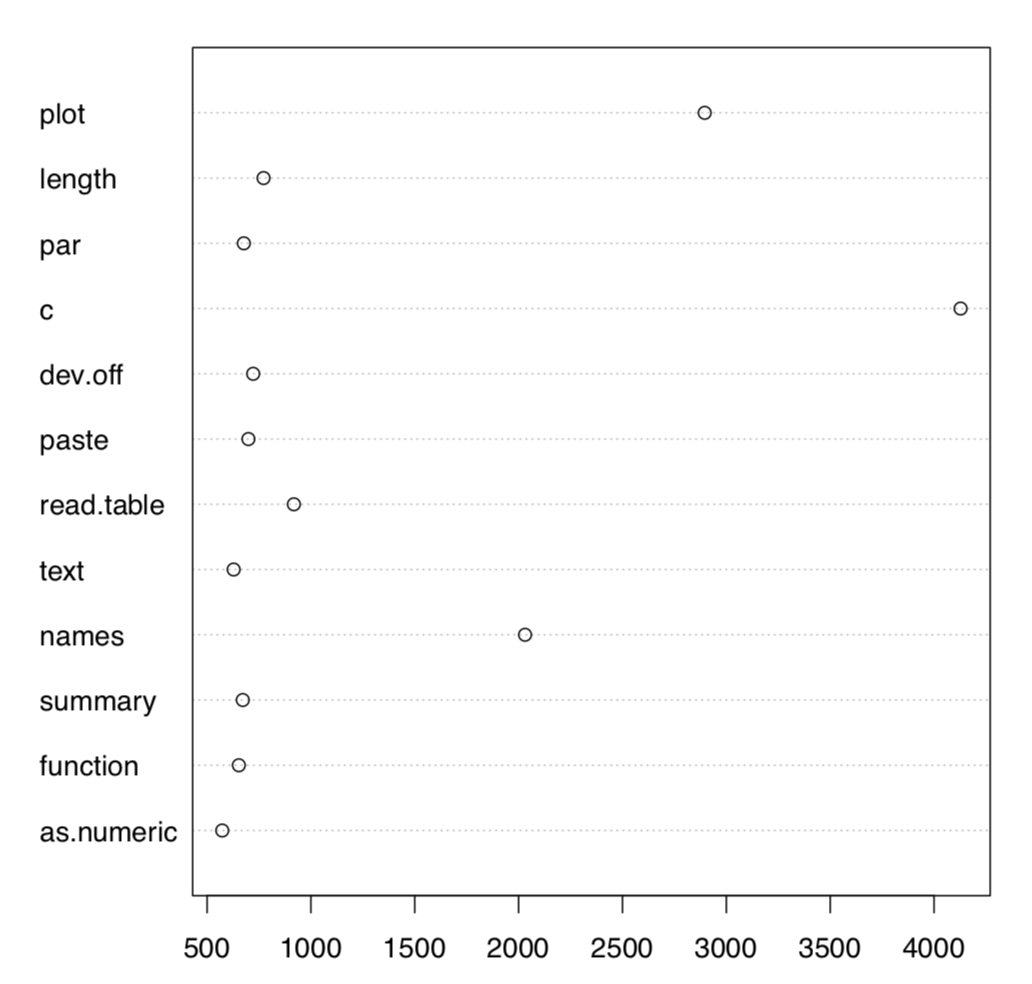
En muchos experimentos como este, los investigadores encontraron que la característica gráfica entendida con mayor precisión es la posición a lo largo del eje, mientras que la longitud, el ángulo, el área, la densidad y el color son cada vez menos apropiados. Es por ello que desde el inicio de la historia de R, se recomendaron gráficos circulares y gráficas de barras para reemplazar con dotcharts (Figura3.4.2):
Código3.4.3 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
load("data/com12.rd")
exists("com12") # check if our object is here
com12.plot <- barplot(com12, names.arg="")
dotchart(com12)
Esperamos que esté de acuerdo en que el dotchart es más fácil tanto de entender como de recordar. (Por supuesto, es posible hacer esta trama aún más comprensible con la clasificación como dotchart (rev (sort (com12))) — pruébalo tú mismo. También es posible ordenar barras, pero incluso la gráfica de barras ordenada es peor que dotchart.)
Otra trama útil para los recuentos es la nube de palabras, la imagen donde cada ítem se magnifica de acuerdo con su frecuencia. Esta idea surgió de las herramientas de minería de texto. Para hacer nubes de palabras en R, uno podría usar el paquete wordcloud (Figura3.4.3):
Código3.4.4 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
com80 <- read.table("data/com80.txt")
library(wordcloud)
set.seed(5) # freeze random number generator
Código3.4.5 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
com80 <- read.table("data/com80.txt")
wordcloud(words=com80[, 1], freq=com80[, 2], colors=brewer.pal(8, "Dark2"))
(El nuevo objeto com80 es un marco de datos con dos columnas, verifíquelo con el comando str (). Dado que wordcloud () “quiere” palabras y frecuencias por separado, suministramos columnas de com80 individualmente a cada argumento. Para seleccionar columna, usamos corchetes con dos argumentos: e.g., com80 [, 1] es la primera columna. Ver más sobre esto en la sección “Inside R”.)
Command set.seed () necesita más explicación. Congela generador de números aleatorios de tal manera que inmediatamente después de su primer uso todos los números aleatorios son iguales en diferentes computadoras. Word cloud plot usa números aleatorios, por lo tanto para tener gráficas similares entre Figure3.4.2 y su computadora, es mejor ejecutar set.seed ()
inmediatamente antes de trazar. Su argumento debe ser un solo valor entero, igual en todas las computadoras. Para reinicializar números aleatorios, ejecute set.seed (NULL).
Por cierto, el objeto NULL no es solo un vacío, es una herramienta realmente útil. Por ejemplo, es fácil eliminar columnas del marco de datos con comandos como árboles [, 3] <- NULL. Si algún comando “quiere” trazar pero no necesita esta característica, suprima el trazado con el comando pdf (file=null) (no olvide cerrar el dispositivo con dev.off ()).
Compare con sus resultados:
Código3.4.6 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
set.seed(1); rnorm(1)
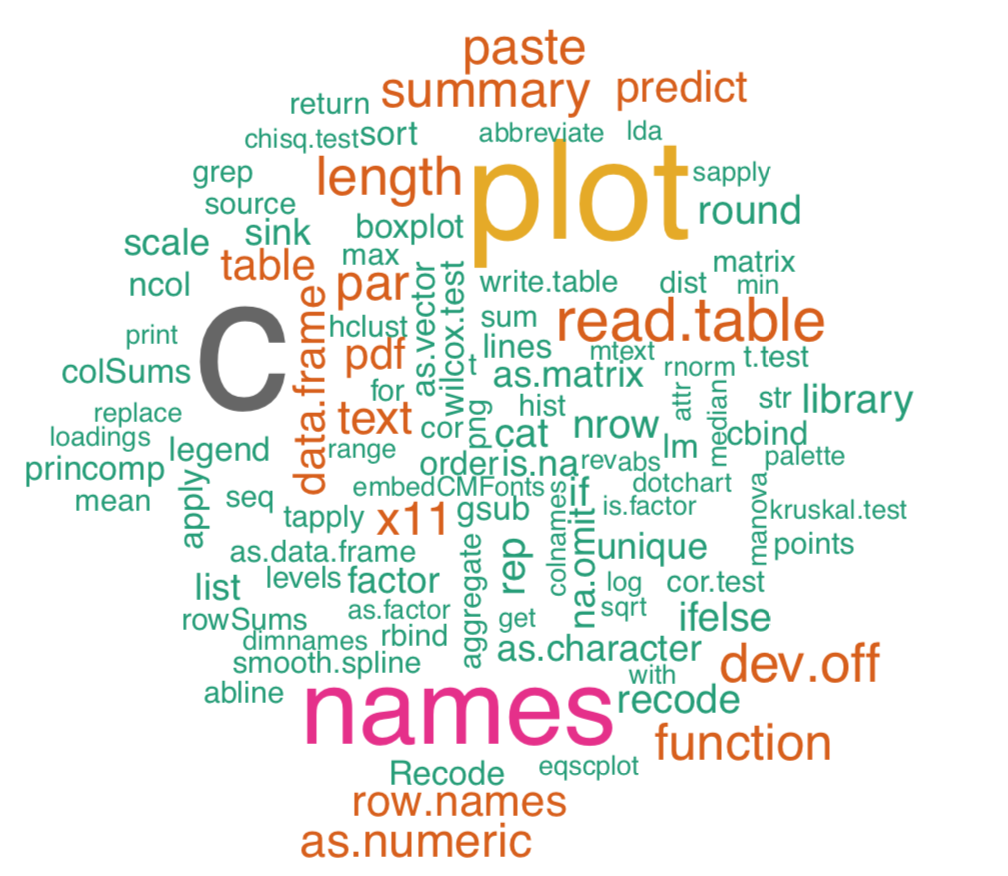
La nube de palabras es una forma de moda de mostrar recuentos pero tiene un gran menos: mientras que es posible decir qué palabra en más frecuente, es imposible decir qué tan frecuente es. Dotchart de com80 necesita más espacio (es mejor graficar es como PDF grande) pero habrá frecuencias tanto relativas como absolutas visibles. Pruébalo tú mismo:
Código3.4.7 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
com80 <- read.table("data/com80.txt")
dotchart(log(com80[, 2]), labels=com80[, 1], cex=.6)
(Utilizamos escala logarítmica para hacer que los recuentos sean menos dispersos y el parámetro cex para disminuir el tamaño de fuente).
Si bien los recuentos y porcentajes suelen provenir de datos categóricos (nominales), los rangos suelen provenir de los datos de medición, como nuestras alturas:
Código3.4.8 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
x <- c(174, 162, 188, 192, 165, 168, 172.5) x.ranks <- x names(x.ranks) <- rank(x) x.ranks sort(x.ranks) # easier to spot
(El “truco” aquí era usar nombres para representar rangos. Todos los objetos R, junto con los valores, pueden llevar nombres.)
No solo los enteros, sino también las fracciones pueden servir como rango; esto último ocurre cuando hay un número par de medidas iguales (es decir, algunos elementos están duplicados):
Código3.4.9 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
x <- c(174, 162, 188, 192, 165, 168, 172.5) x.ranks2 <- c(x, x[3]) # duplicate the 3rd item names(x.ranks2) <- rank(x.ranks2) sort(x.ranks2)
En general, las mediciones originales idénticas reciben rangos idénticos. A esta situación se le llama “empate”, al igual que en el deporte. Los lazos pueden interferir con algunas pruebas no paramétricas y otros cálculos basados en rangos:
Código3.4.10 (R):
Login with LibreOne to run this code cell interactively.
If you have already signed in, please refresh the page.
x <- c(174, 162, 188, 192, 165, 168, 172.5) x.ranks2 <- c(x, x[3]) # duplicate the 3rd item wilcox.test(x.ranks2)
(Si antes no viste las advertencias de R, recuerda que podrían aparecer aunque no haya nada malo. Por lo tanto, ignóralos si no los entiendes. Sin embargo, a veces las advertencias traen información útil.)
R siempre devuelve una advertencia si hay lazos. Es posible evitar lazos agregando pequeño ruido aleatorio con el comando jitter () (seguirán ejemplos).
Los rangos son ampliamente utilizados en las estadísticas. Por ejemplo, la medida popular de tendencia central, mediana (ver más adelante) se calcula usando rangos. Son especialmente adecuados para datos de medición clasificados y no paramétricos. Los análisis basados en rangos suelen ser más robustos pero menos sensibles.