3.7: Cambio de datos: fundamentos de las transformaciones
- Page ID
- 150005
En estudios complicados que involucran muchos tipos de datos: mediciones y rangos, porcentajes y recuentos, paramétricos, no paramétricos y nominales, es útil unificarlos. A veces tales transformaciones son fáciles. Incluso los datos nominales pueden entenderse como continuos, dada suficiente información. Por ejemplo, el sexo puede registrarse como variable continua del nivel de testosterona en sangre, posiblemente con mediciones adicionales. Otra forma, más común, es tratar los datos discretos como continuos, generalmente son seguros, pero a veces pueden llevar a sorpresas desagradables.
Otra posibilidad es transformar los datos de medición en clasificados. La función R cut () permite realizar esta operación y crear factores ordenados.
Lo que es completamente inaceptable es transformar los datos nominales comunes en filas. Si los valores no están, por su naturaleza, ordenados, imponer un orden artificial puede hacer que los resultados no tengan sentido.
Los datos a menudo se transforman para acercarlos a los parámetros paramétricos y homogeneizar las desviaciones estándar. Las distribuciones con colas largas, o solo algo en forma de campana (como en la Figura 4.2.5), podrían transformarse logarítmicas. Es quizás la transformación más común.
Incluso hay un argumento especial plot (..., log="axis”), donde “axis” debe sustituirse por x o y, presentándolo en escala logarítmica (natural). Otra variante es simplemente calcular logaritmo sobre la marcha como parcela (log (...) .
Considere algunas transformaciones ampliamente utilizadas y sus implicaciones en R (suponemos que sus mediciones se registran en los datos vectoriales):
- Logarítmico: log (datos + 1). Puede normalizar distribuciones con sesgo positivo (cola derecha), acercar las relaciones entre variables a lineales e igualar varianzas. No puede manejar ceros, por eso agregamos un solo dígito.
- Raíz cuadrada: sqrt (datos). Es similar a logarítmico en sus efectos, pero no puede manejar negativos.
- Inversa: 1/ (datos + 1). Este estabiliza las varianzas, no puede manejar ceros.
- Cuadrado: datos^2. Junto con la raíz cuadrada, pertenece a la familia de transformaciones de poder. Puede normalizar los datos con datos de sesgo negativo (cola izquierda), acercar las relaciones entre variables a lineales e igualar varianzas.
- Logit: log (p/ (1-p)). Se utiliza principalmente en proporciones para linealizar curvas en forma de S o sigmoides. Junto con logit, estos tipos de datos a veces se tratan con transformación de arcoseno que es asin (sqrt (p)). En ambos casos, p debe estar entre 0 y 1.
Mientras trabaja con múltiples variables, realice un seguimiento de sus dimensiones. Trate de no mezclarlos, registrando una variable en milímetros, y otra en centímetros. Sin embargo, en las estadísticas multivariadas incluso los datos medidos en unidades comunes pueden tener diferente naturaleza. En este caso, las variables a menudo se estandarizan, por ejemplo, se llevan a la misma media y/o a la misma varianza con la función scale (). Los datos de árboles incrustados son un buen ejemplo:
Código\(\PageIndex{1}\) (R):
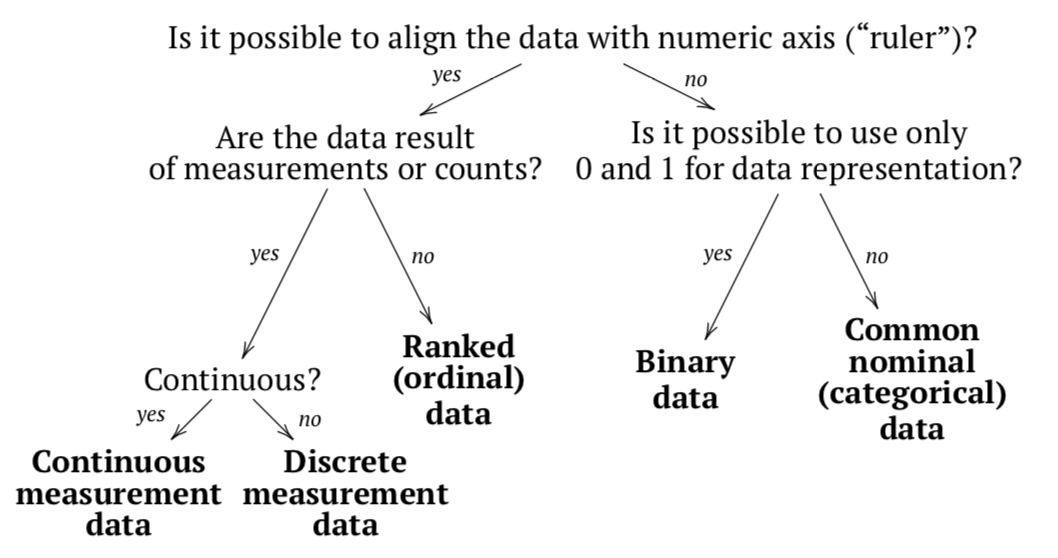
Al final de la explicación de los tipos de datos, recomendamos revisar un pequeño gráfico que podría ser útil para la determinación del tipo de datos (Figura\(\PageIndex{1}\)).