
4.1: Cómo estimar las tendencias generales
- Page ID
- 150116

Siempre es tentador describir la muestra con un solo número “para gobernarlos a todos”. O sólo unos pocos números... Esta idea está detrás de momentos centrales, dos (o a veces cuatro) números que representan la tendencia central o central de la muestra y su escala (variación, variabilidad, inestabilidad, dispersión: hay muchos sinónimos).
El tercer y cuarto momentos centrales no se utilizan frecuentemente, representan asimetría (desplazamiento, asimetría) y nitidez (“cola”, curtosis), respectivamente.
La mediana es la mejor
La media es un método paramétrico mientras que la mediana depende menos de la forma de distribución. En consecuencia, la mediana es más estable, más robusta. Volvamos a nuestros siete hipotéticos empleados. Aquí están sus salarios (miles por año):
Código\(\PageIndex{1}\) (R):
Las diferencias dramáticas en los salarios podrían explicarse por el hecho de que Alex es el custodio mientras que Kathryn es la dueña de la empresa.
Código\(\PageIndex{2}\) (R):
Podemos ver que esa media no refleja muy bien los salarios típicos, está influenciada por el salario más alto de Kathryn. La mediana hace un mejor trabajo porque se calcula de una manera radicalmente diferente de la media. La mediana es un valor que corta la mitad de la muestra ordenada. Para ilustrar el punto, hagamos otro vector, similar a nuestro salario:
Código\(\PageIndex{3}\) (R):
Vector salary1 contiene un número par de valores, ocho, por lo que su mediana se encuentra en el medio, entre dos valores centrales (21 y 22).
También hay una manera de hacer que la media sea más robusta a los valores atípicos, la media recortada que se calcula después de la eliminación de los valores marginales:
Código\(\PageIndex{4}\) (R):
Esta media recortada se calcula después de que se tomó el 10% de los datos de cada extremo y se encuentra significativamente más cerca de la mediana.
Hay otra medida de tendencia central aparte de la mediana y la media. Es modo, el valor más frecuente en la muestra. Rara vez se utiliza, y se aplica principalmente a datos nominales. Aquí hay un ejemplo (tomamos la variable sexo del último capítulo):
Código\(\PageIndex{5}\) (R):
Aquí el valor más común es el masculino\(^{[1]}\).
A menudo nos enfrentamos a la tarea de calcular la media (o mediana) para los marcos de datos. Hay al menos tres formas diferentes:
Código\(\PageIndex{6}\) (R):
La primera forma usa attach () y agrega columnas de la tabla a la lista de variables “visibles”. Ahora podemos abordar estas variables usando solo sus nombres, omitiendo el nombre del marco de datos. Si elige usar este comando, no olvide desacoplar () la tabla. De lo contrario, existe el riesgo de perder la pista de lo que está y no se adjunta. Es particularmente problemático si los nombres de las variables se repiten en diferentes marcos de datos. Tenga en cuenta que cualquier cambio realizado en las variables se olvidará después de separar ().
La segunda forma usa with ()) que es similar a adjuntar, solo aquí el apego ocurre dentro del cuerpo de la función:
Código\(\PageIndex{7}\) (R):
La tercera forma utiliza el hecho de que un marco de datos es solo una lista de columnas. Utiliza funciones de agrupación de la familia apply ()\(^{[2]}\), por ejemplo, sapply () (“apply and simplify”):
Código\(\PageIndex{8}\) (R):
¿Y si debes proporcionar un argumento a la función que está dentro de sapply ()? Por ejemplo, los datos faltantes devolverán NA sin el argumento adecuado. En muchos casos esto es posible especificar directamente:
Código\(\PageIndex{9}\) (R):
En casos más complicados, es posible que desee definir la función anónima (ver más abajo).
Cuartiles y cuantiles
Los cuartiles son útiles para describir la variabilidad de la muestra. Los cuartiles son valores cortando la muestra en puntos de 0%, 25%, 50%, 75% y 100% de la distribución total\(^{[3]}\). La mediana no es otra cosa que el tercer cuartil (50%). El primer y el quinto cuartiles son mínimos y máximos de la muestra.
El concepto de cuartiles puede ampliarse para obtener puntos de corte en cualquier intervalo deseado. Tales medidas se denominan cuantiles (de cuántica, un incremento), con muchos casos especiales, por ejemplo, percentiles para porcentajes. Los cuantiles se utilizan también para verificar la normalidad (ver más adelante). Esto calculará cuartiles:
Código\(\PageIndex{10}\) (R):
Otra forma de calcularlos:
Código\(\PageIndex{11}\) (R):
(Estas dos funciones a veces producen resultados ligeramente diferentes, pero esto es insignificante para la investigación. Para saber más, usa la ayuda. Las parcelas de caja (ver abajo) usan fivenum ().)
La tercera y más comúnmente utilizada es ejecutar summary ():
Código\(\PageIndex{12}\) (R):
summary () es genérica por lo que devuelve diferentes resultados para diferentes tipos de objetos (por ejemplo, para marcos de datos, para datos de medición y datos nominales):
Código\(\PageIndex{13}\) (R):
Además, summary () muestra el número de valores de datos faltantes:
Código\(\PageIndex{14}\) (R):
Command summary () también es muy útil en la primera etapa del análisis, por ejemplo, cuando verificamos la calidad de los datos. Muestra los valores faltantes y devuelve mínimo y máximo:
Código\(\PageIndex{15}\) (R):
Leemos el archivo de datos en una tabla y verificamos su estructura con str (). Vemos que la variable AGE (que debe ser el número) se ha convertido inesperadamente en un factor. Salida del resumen () explica por qué: una de las medidas de edad fue mal escrita como letra a. Además, uno de los nombres está vacío —al parecer, debería haber contenido NA. Por último, ¡la altura mínima es de 16.1 cm! Esto es bastante imposible incluso para los recién nacidos. Lo más probable es que el punto decimal estuviera fuera de lugar.
Variación
Las medidas paramétricas más comunes de variación son la varianza y la desviación estándar:
Código\(\PageIndex{16}\) (R):
(Como ve, la desviación estándar es simplemente la raíz cuadrada de la varianza; de hecho, esta función estaba ausente del lenguaje S.)
Las medidas de variación no paramétricas útiles son IQR y MAD:
Código\(\PageIndex{17}\) (R):
La primera medida, rango intercuartil (IQR), la distancia entre el segundo y el cuarto cuartiles. La segunda medición robusta de la dispersión es la mediana de la desviación absoluta, que se basa en la mediana de las diferencias absolutas entre cada valor y la mediana de la muestra.
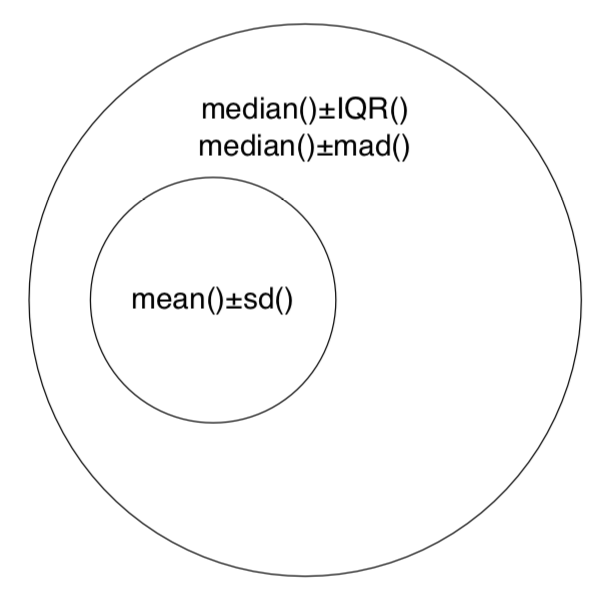
Para reportar el valor central y la variabilidad juntos, uno de los enfoques frecuentes es usar “centro ± variación”. En ocasiones, sí significan ± desviación estándar (que erróneamente llamó “SEM”, término ambiguo que debe evitarse), pero esto no es robusto. Los métodos robustos y no paramétricos son siempre preferibles, por lo tanto, “mediana ± IQR” o “mediana ± MAD” harán lo mejor:
Código\(\PageIndex{18}\) (R):
Para reportar solo la variación, hay más formas. Por ejemplo, se puede usar el intervalo donde se encuentra el 95% de la muestra:
Código\(\PageIndex{19}\) (R):
Tenga en cuenta que esto no es un intervalo de confianza porque los cuantiles y todas las demás estadísticas descriptivas son sobre muestra, ¡no sobre población! Sin embargo, bootstrap (descrito en el Apéndice) podría ayudar a usar cuantiles del 95% para estimar el intervalo de confianza.
... o 95% de rango junto con una mediana:
Código\(\PageIndex{20}\) (R):
... o dispersión de “bigotes” de la gráfica de caja:
Código\(\PageIndex{21}\) (R):
Relacionadas con las medidas de escala son máximas y mínimas. Son fáciles de obtener con las funciones range () o separadas min () y max (). Tomando solas, no son tan útiles por posibles valores atípicos, pero junto con otras medidas podrían incluirse en el informe:
Código\(\PageIndex{22}\) (R):
(Aquí se utilizaron bisagras de diagrama de caja para el intervalo principal).
La figura (Figura\(\PageIndex{1}\)) resume las formas más importantes de reportar tendencia central y variación con el mismo diagrama de Euler que se utilizó para mostrar la relación entre enfoques paramétricos y no paramétricos (Figura 3.1.2).
Para comparar la variabilidad de caracteres (especialmente medidos en diferentes unidades) se puede utilizar un coeficiente de variación adimensional. Tiene un cálculo sencillo: desviación estándar dividida por media y multiplicada por 100%. Aquí están los coeficientes de variación para las características de los árboles de un bui db">trees):
Código\(\PageIndex{23}\) (R):
(Para simplificar las cosas, usamos ColMeans () que calculaba medias para cada columna. Proviene de una familia de comandos similares con nombres autoexplicativos: rowMeans (), ColSams () y rowSams ().)