4.2: Gráficas 1-Dimensionales
- Page ID
- 150130

Nuestra firma tiene apenas siete trabajadores. ¿Cómo analizar los datos más grandes? ¡Imaginemos primero que nuestra hipotética empresa prospera y contrató a mil nuevos trabajadores! Los agregamos a nuestros siete puntos de datos, con sus salarios extraídos aleatoriamente del rango intercuartil de la muestra original (Figura\(\PageIndex{1}\)):
Código\(\PageIndex{1}\) (R): Boxplots
En un código anterior también vemos un ejemplo de generación de datos. La función sample () dibuja valores aleatoriamente de una distribución o intervalo. Aquí usamos replace=true, ya que necesitábamos escoger muchos valores de una muestra mucho más pequeña. (El argumento replace=false puede ser necesario para la imitación de un juego de cartas, donde cada carta solo puede ser extraída de una baraja una vez). Tenga en cuenta que el muestreo es aleatorio y por lo tanto cada iteración dará resultados ligeramente diferentes.
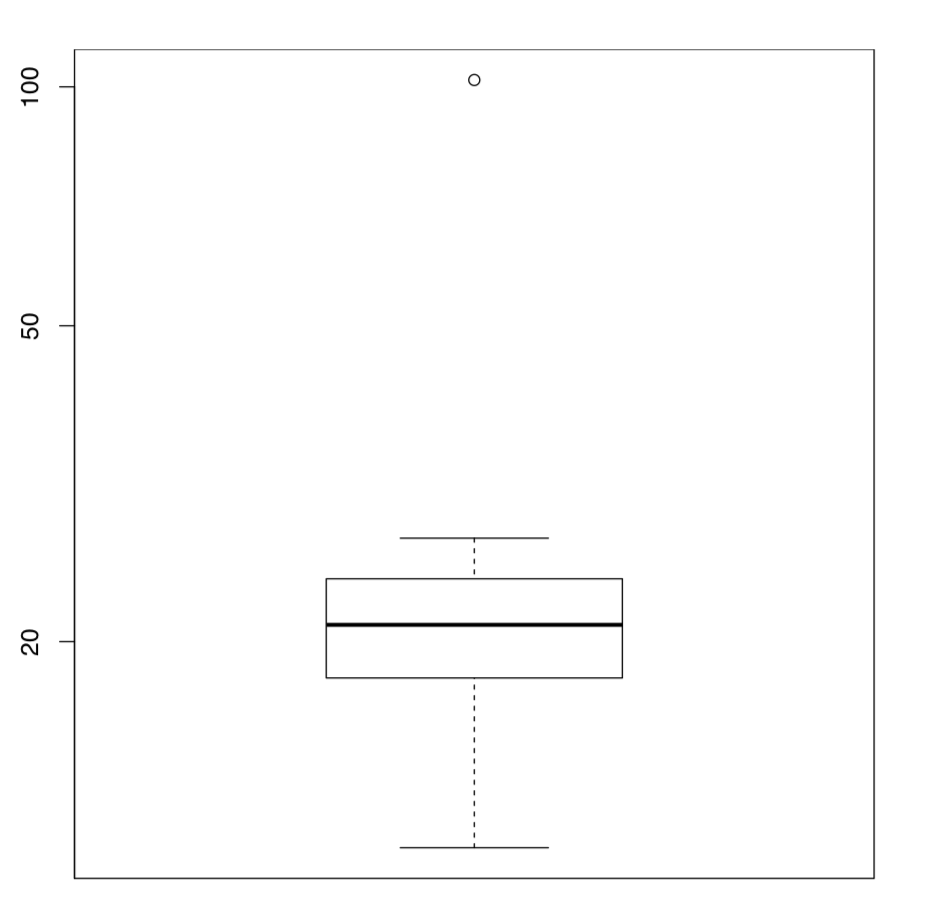
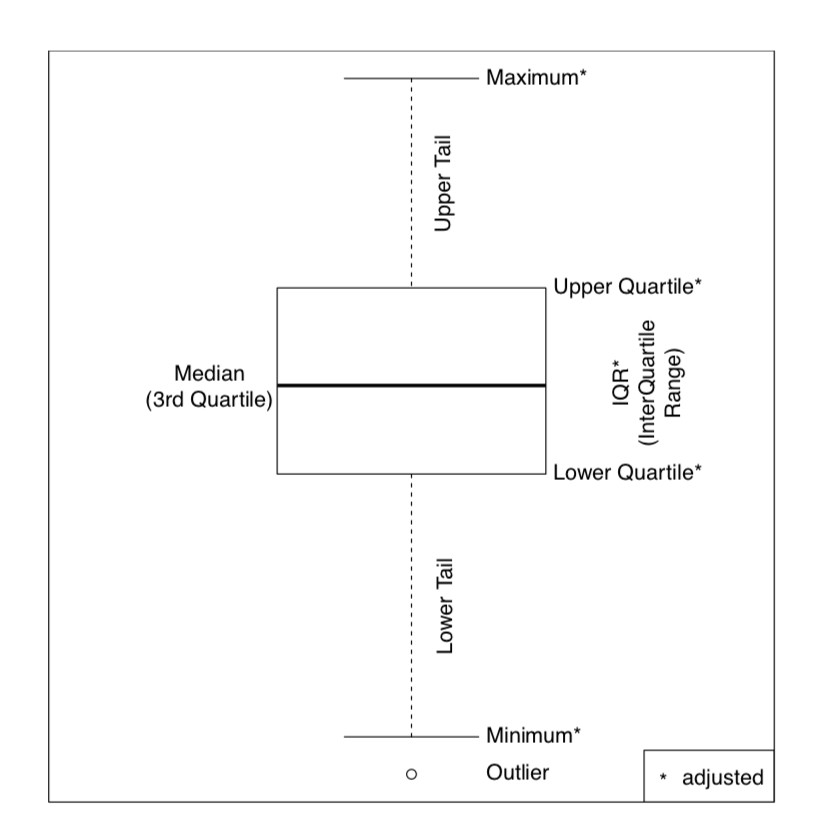
Echemos un vistazo a la trama. Esta es la trama de caja (trama de “caja y bigotes”). El salario de Kathryn es el punto más alto. Es tan alto, de hecho, que tuvimos que agregar el parámetro log="y” para visualizar mejor el resto de los valores. La caja (rectángulo principal) en sí está unida por el segundo y cuarto cuartiles, de manera que su altura es igual a IQR. La línea gruesa en el medio es una mediana. Por defecto, los “bigotes” se extienden hasta el punto de datos más extremo que no es más de 1.5 veces el rango intercuartil de la caja. Los valores que se encuentran más lejos se dibujan como puntos separados y se consideran valores atípicos. El esquema (Figura\(\PageIndex{2}\)) podría ayudar en la comprensión de las gráficas de caja.
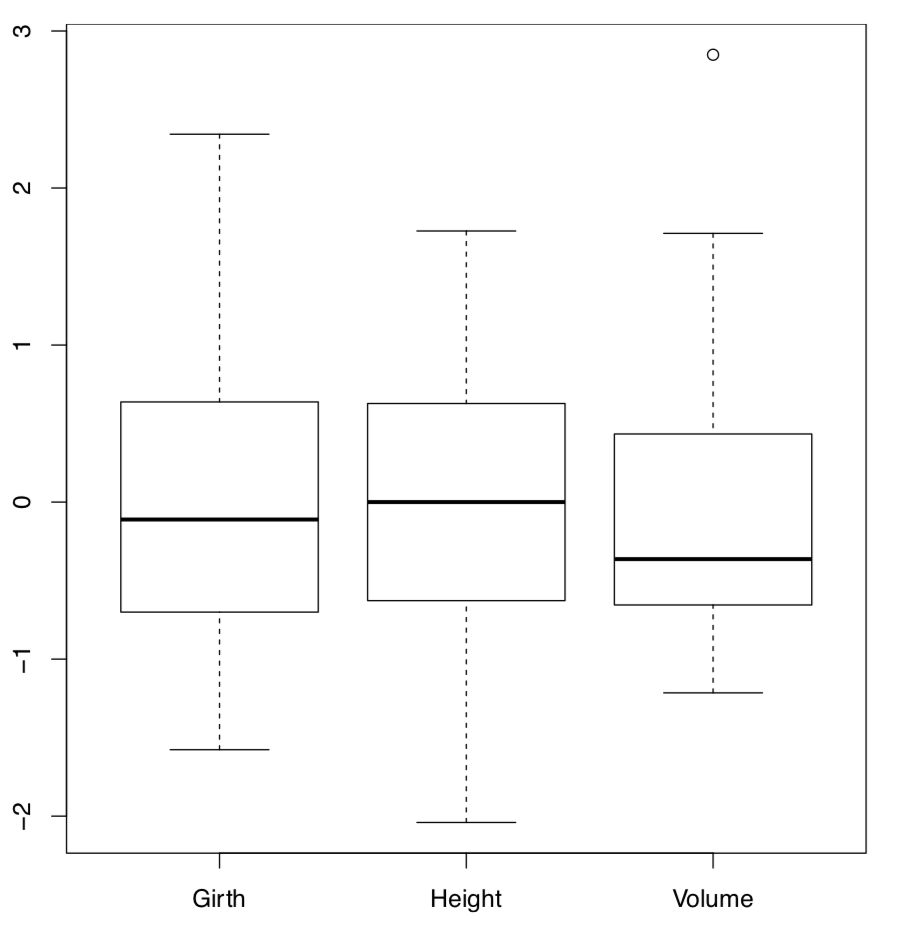
Los números que hacen la gráfica de caja pueden ser devueltos con el comando fivenum (). La representación de boxplot fue creada por un famoso matemático estadounidense John W. Tukey como una manera rápida, poderosa y consistente de reflejar las principales características independientes de la distribución de la muestra. En R, boxplot () se vectoriza para que podamos dibujar varias gráficas de caja a la vez (Figura\(\PageIndex{3}\)):
Código\(\PageIndex{2}\) (R): Boxplots
(Los parámetros de los árboles se midieron en diferentes unidades, por lo tanto, los escalamos ().)
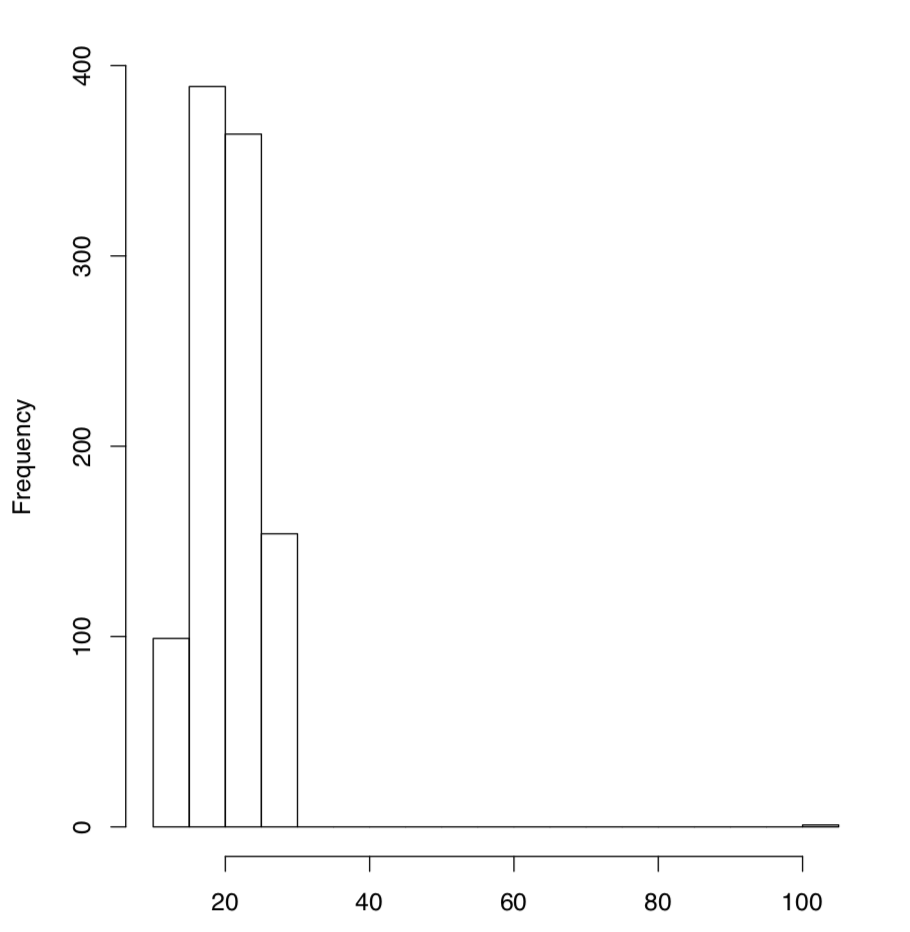
El histograma es otra representación gráfica de la muestra donde el rango se divide en intervalos (bins), y se dibujan barras consecutivas con su altura proporcional al recuento de valores en cada bin (Figura\(\PageIndex{4}\)):
Código\(\PageIndex{3}\) (R): Histograms
(Por defecto, el comando hist () habría dividido el rango en 10 bins, pero aquí necesitábamos 20 y por lo tanto configurarlos manualmente. El histograma es a veces una forma bastante críptica de mostrar los datos. Los comandos Histp () e Histr () del asmisc.r trazarán histogramas junto con porcentajes en la parte superior de cada barra, o superpuestos con curva normal (o densidad, ver más abajo), respectivamente. Por favor pruébalos tú mismo.)
Un análogo numérico de un histograma es la función cut ():
Código\(\PageIndex{4}\) (R):
Existen otras funciones gráficas, conceptualmente similares a los histogramas. La primera es la parcela de tallo y hoja. stem () es una especie de pseudografía, histograma de texto. Veamos cómo trata el salario original del vector:
Código\(\PageIndex{5}\) (R): stem-and-leaf plot
La barra | símbolo es un “tallo” de la gráfica. Los números delante de él son dígitos iniciales de los valores brutos. Como recuerda, nuestros datos originales oscilaron entre 11 y 102, por lo tanto, obtuvimos dígitos iniciales de 1 a 10. Cada número a la izquierda proviene del siguiente dígito de un dato. Cuando tenemos varios valores con idéntico dígito inicial, como 11 y 19, colocamos sus últimos dígitos en una secuencia, como “hojas”, a la izquierda del “tallo”. Como ves, hay dos valores entre 10 y 20, cinco valores entre 20 y 30, etc. Aparte de una apariencia similar a un histograma, esta función realiza un ordenamiento eficiente.
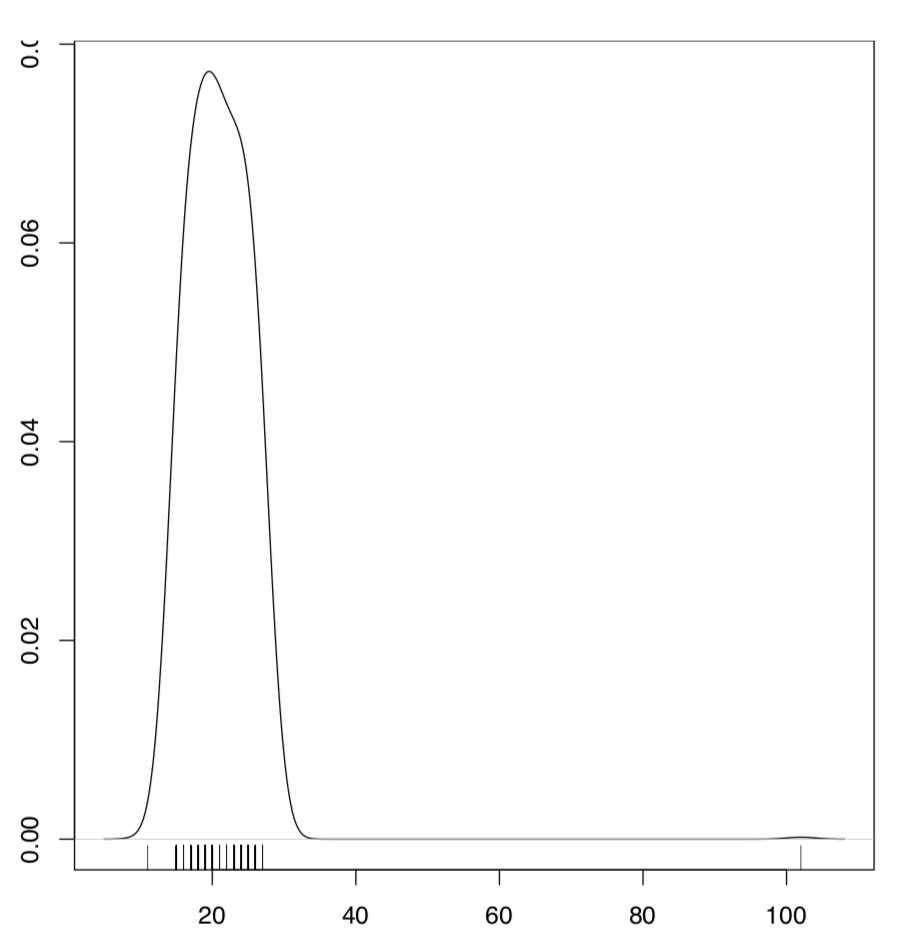
Otro instrumento univariado requiere cálculos más sofisticados. Se trata de una gráfica de densidad de distribución, gráfica de densidad (Figura\(\PageIndex{5}\)):
CodeBox (R)\(\PageIndex{6}\): Gráficas de densidad
Código\(\PageIndex{6}\) (R): Density Plots
(Se utilizó una alfombra de función gráfica adicional () que suministra una parcela existente con una “regla” que marca las áreas de mayor densidad de datos).
Aquí el histograma se suaviza, se convierte en una función continua. El grado al que se “redondea” depende del parámetro ajuste. Aparte de las gráficas de caja y una variedad de histogramas y similares, los paquetes R y externos proporcionan muchos más instrumentos para el trazado univariado.
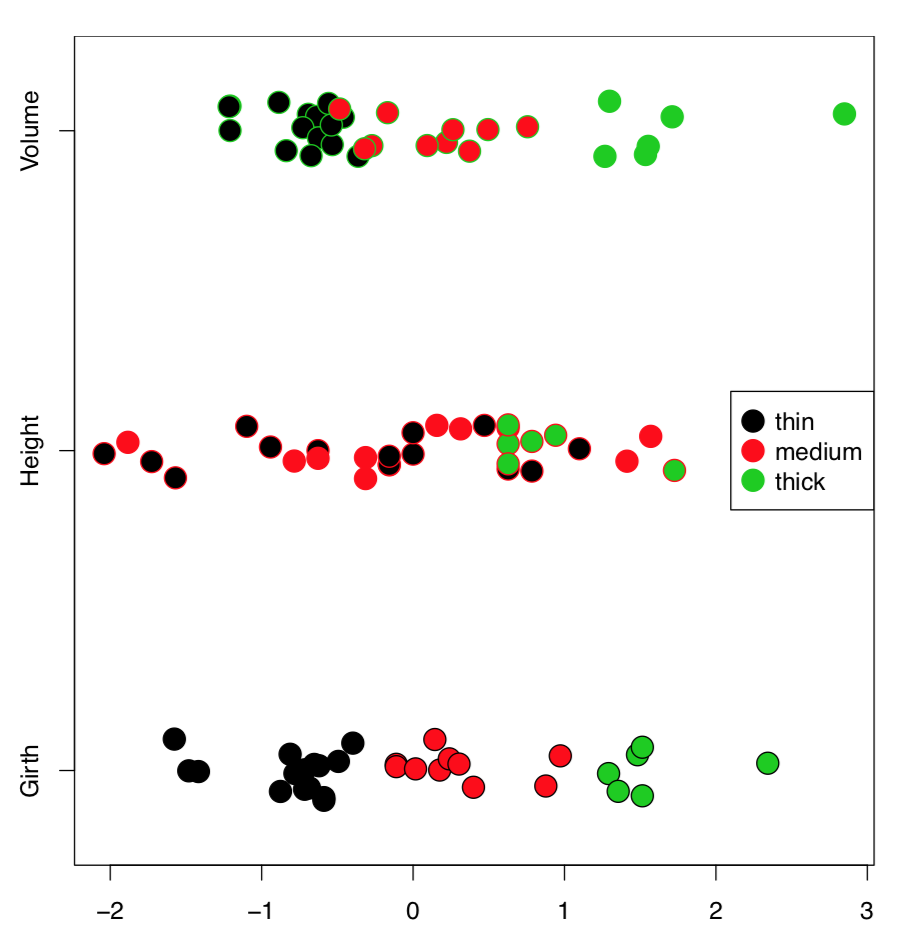
Uno de los más simples es el stripchart. Para hacer que el stripchart sea más interesante, lo complicamos a continuación usando su capacidad para mostrar puntos de datos individuales:
Código\(\PageIndex{7}\) (R): stripchart
(Por defecto, el gráfico de tiras es horizontal. Utilizamos method="jitter” para evitar el sobretrazado, y también escalamos todos los caracteres para hacer comparables sus distribuciones. Una de las características del stripchart es que el argumento col colorea columnas mientras que el argumento bg (que funciona solo para pch de 21 a 25) colorea filas. Dividimos árboles en 3 clases de grosor, y aplicamos estas clases como puntos de fondo. Tenga en cuenta que si los puntos de datos se muestran con múltiples colores y/o múltiples tipos de puntos, la leyenda siempre es necesaria. ')
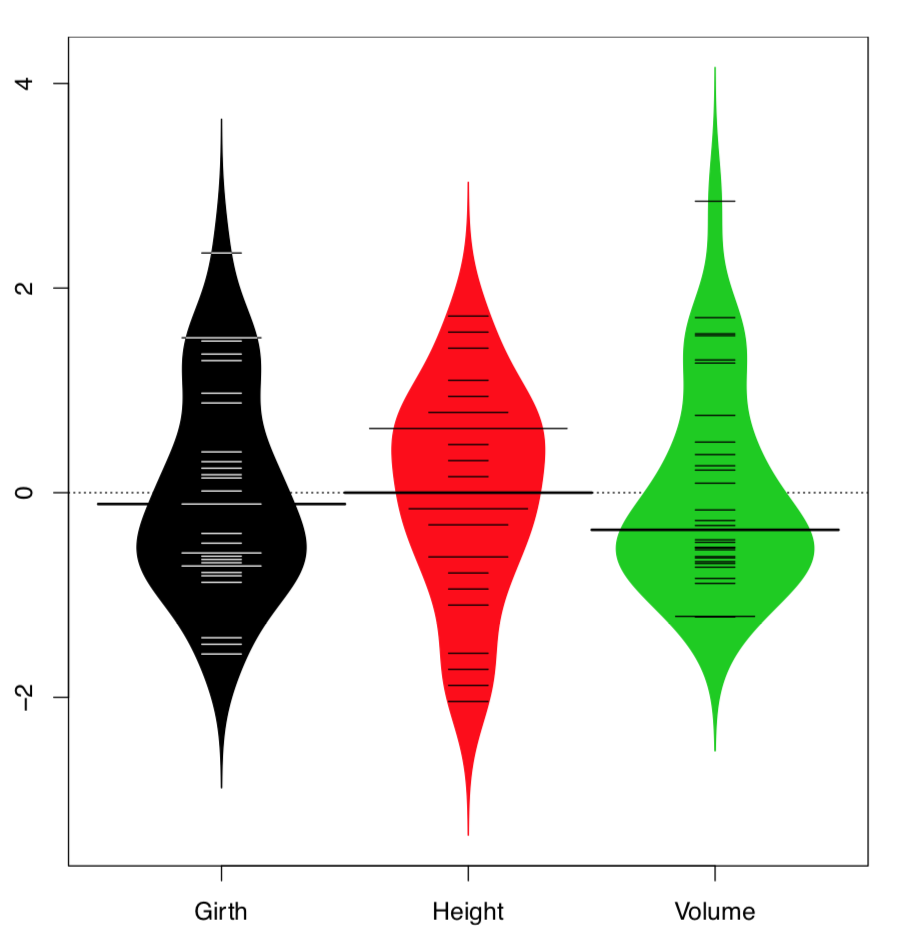
La parcela de abeja requiere el paquete externo. Es similar al stripchart pero cuenta con varios métodos avanzados para dispersar puntos, además de una capacidad para controlar el tipo de puntos individuales (Figura\(\PageIndex{7}\)):
Código\(\PageIndex{8}\) (R): Beeswarm plots
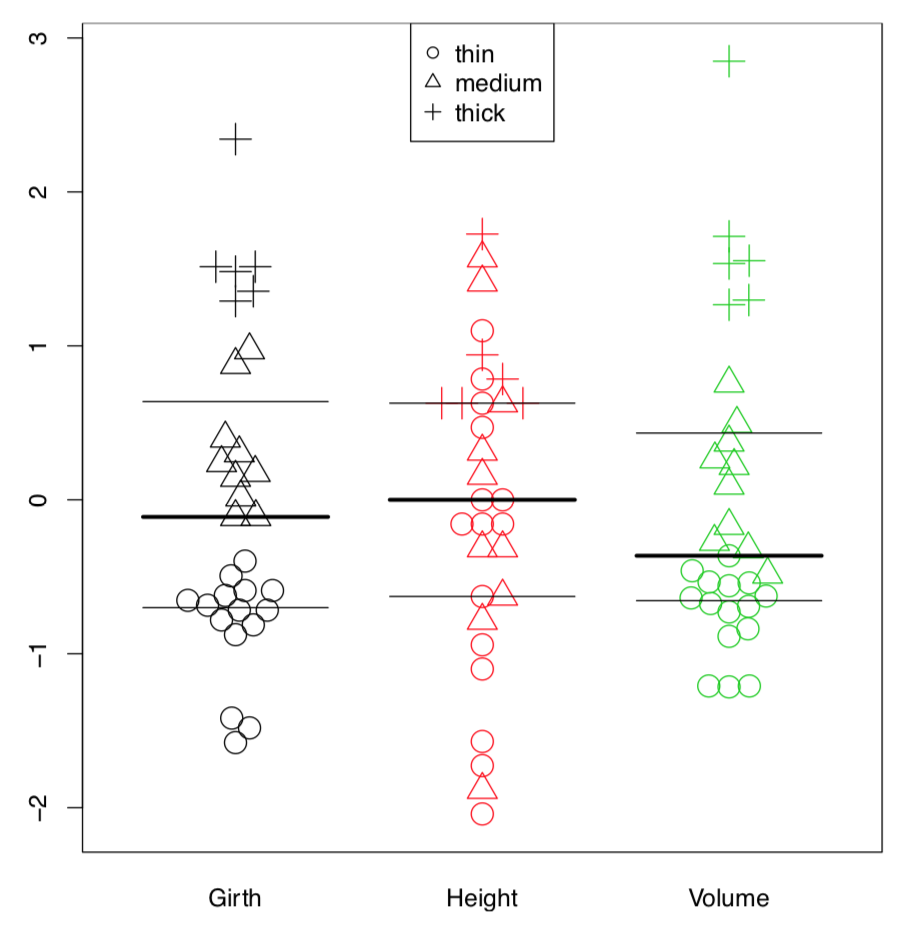
(Aquí con el comando bxplot () agregamos líneas boxplot a una gráfica de colmena para visualizar cuartiles y medianas. Para superponer, usamos un argumento add=true.)
Y una trama unidimensional más útil. Es similar tanto a la gráfica de caja como a la gráfica de densidad (Figura\(\PageIndex{8}\)):
Código\(\PageIndex{1}\) (R): Bean plots