
6.4: Respuestas a los ejercicios
- Page ID
- 150158

Correlación y modelos lineales
Respuesta a la pregunta de los rasgos humanos. Inspeccionar los datos, cargarlos y verificar el objeto:
Código\(\PageIndex{1}\) (R):
Los datos son binarios, por lo que la correlación de Kendall es más natural:
Código\(\PageIndex{2}\) (R):
Visualizaremos la correlación con la Pleiad (), una de sus ventajas es mostrar qué correlaciones están conectadas, agrupadas, las llamadas “pléyadas de correlación”:
Código\(\PageIndex{3}\) (R):
(Mira en la página de título para ver correlaciones. Una pleíada, la barbilla, la lengua y el pulgar es la más aparente.)
Respuesta a la pregunta de la dependencia lineal entre estatura y peso para los datos artificiales. La correlación está presente pero la dependencia es débil (Figura\(\PageIndex{1}\)):
Código\(\PageIndex{4}\) (R):
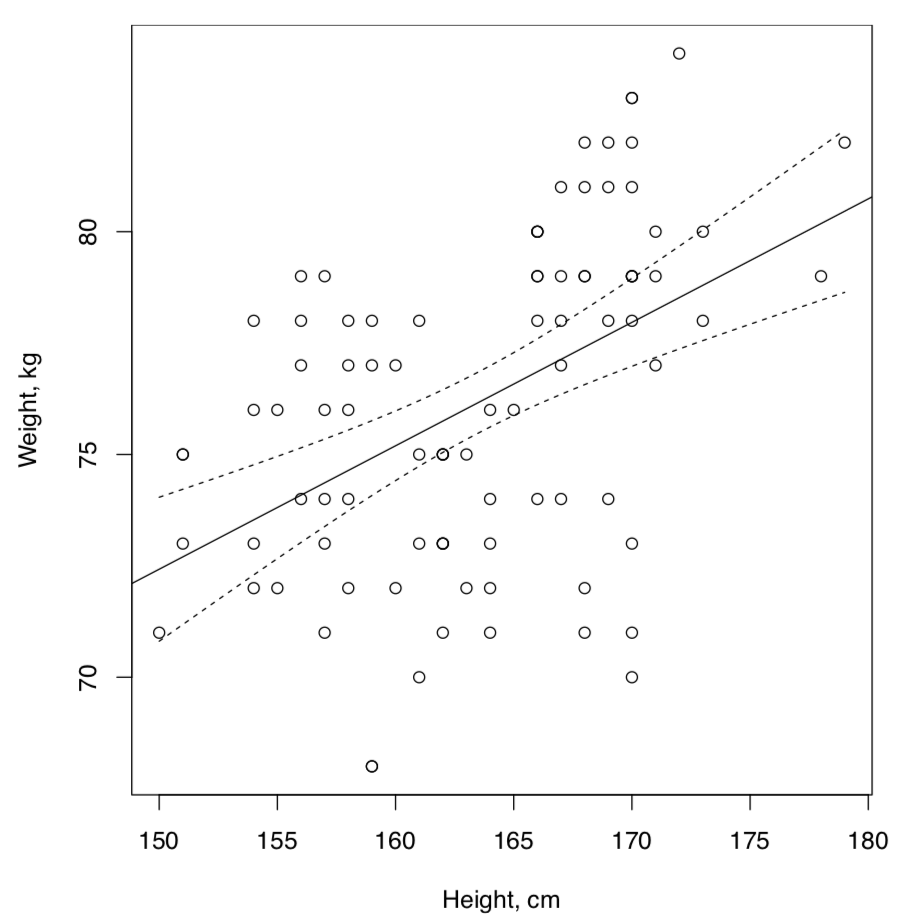
La conclusión sobre la dependencia débil se hizo debido a la baja R-cuadrado lo que significa que la variable predictora, la altura, no explica gran parte de la variable dependiente, el peso. Además, muchos residuos se encuentran fuera del IQR. Esto también es fácil de ver en la gráfica donde muchos puntos de datos están distantes de la línea de regresión e incluso de bandas de confianza del 95%.
Respuesta a la pregunta de draba de primavera. Comprobar archivo, cargar y verificar el objeto:
Código\(\PageIndex{5}\) (R):
Ahora, verifique la normalidad y las correlaciones con el método apropiado:
Código\(\PageIndex{6}\) (R):
Por tanto, FRUIT.L y FRUIT.MAXW son los mejores candidatos para el análisis de modelos lineales. Lo trazaremos primero (Figura\(\PageIndex{2}\)):
Código\(\PageIndex{7}\) (R):
(Points () es una variante “única” de pPoints () de lo anterior, y se utilizó porque hay múltiples puntos de datos superpuestos.)
Finalmente, verifique el modelo lineal y las suposiciones:
Código\(\PageIndex{8}\) (R):
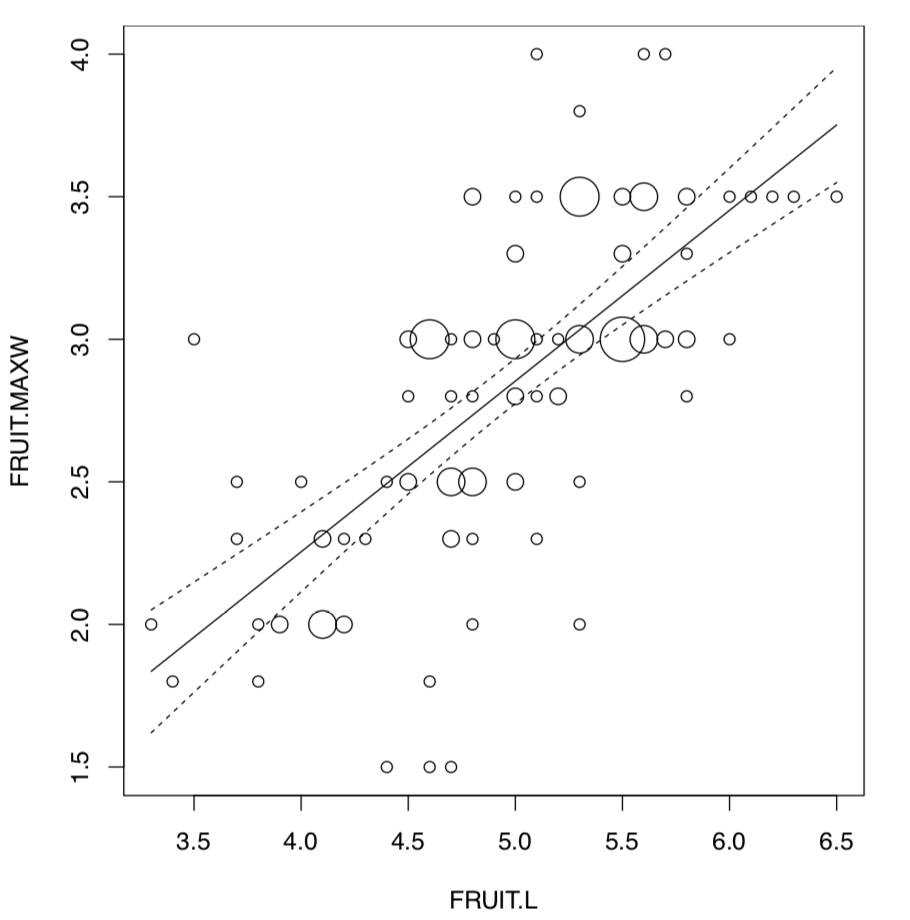
Existe un modelo confiable (valor p: < 2.2e-16) que tiene un alto valor R cuadrado (sqrt (0.4651) = 0.6819824). El coeficiente de pendiente es significativo mientras que la intercepción no lo es. La homogeneidad de los residuos es evidente, su normalidad también está fuera de discusión:
Código\(\PageIndex{9}\) (R):
Respuesta a la pregunta heterostyly. Primero, inspeccione el archivo, cargue los datos y verifíquelo:
Código\(\PageIndex{10}\) (R):
Es así como visualizar el fenómeno de heterostyly para todos los datos:
Código\(\PageIndex{11}\) (R):
(Por favor revise esta parcela usted mismo.)
Ahora necesitamos visualizar las relaciones lineales de interrogación. Hay muchos puntos de datos superpuestos, así que la mejor manera es emplear la función pPoints () (Figura\(\PageIndex{3}\)):
Código\(\PageIndex{12}\) (R):
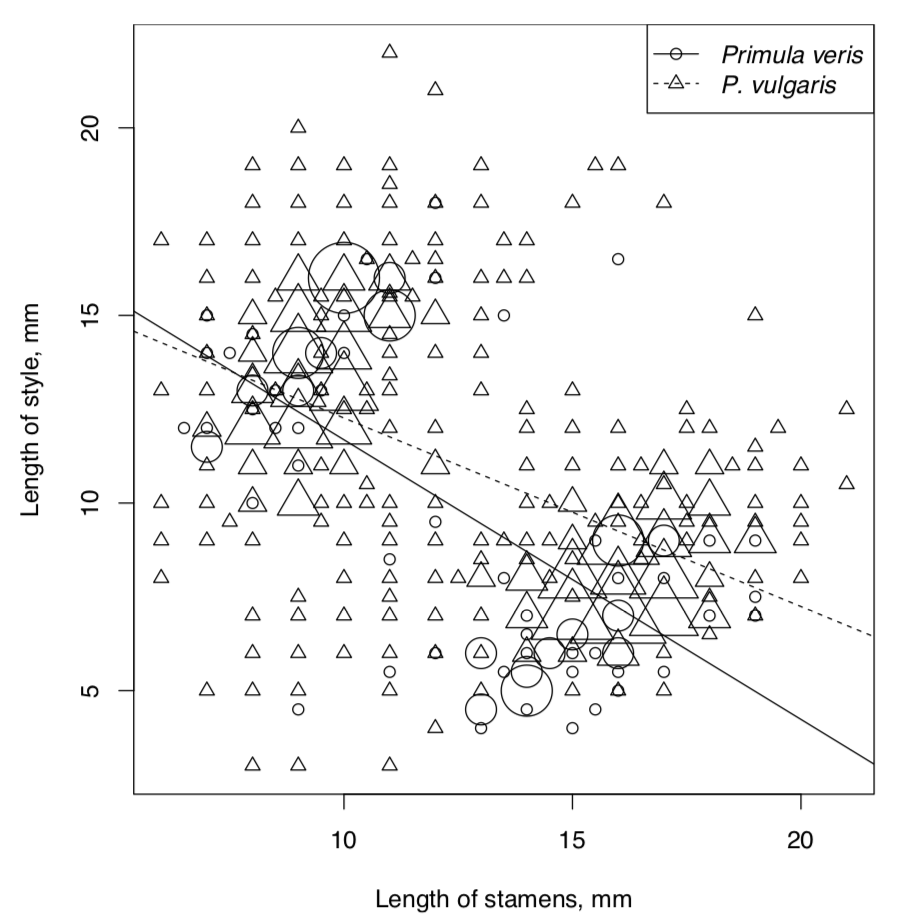
Ahora a los modelos. Supondremos que la longitud de los estambres es la variable independiente. Explore, verifique suposiciones y AIC para el modelo completo:
Código\(\PageIndex{13}\) (R):
Modelo reducido (aditivo):
Código\(\PageIndex{14}\) (R):
El modelo completo es mejor, probablemente debido a interacciones fuertes. Para verificar las interacciones gráficamente es posible también con la gráfica de interacción que tratará la variable independiente como factor:
Código\(\PageIndex{15}\) (R):
Esta parcela técnica (compruébalo tú mismo) muestra las diferencias confiables entre líneas de diferentes especies. Estas diferencias son mayores cuando los estambres son más largos. Esta parcela es más adecuada para el complejo ANOVA pero como ves, funciona también para modelos lineales.
Respuesta a la pregunta sobre las poblaciones de rocío solar (Drosera). Primero, inspeccione el archivo, luego cárguelo y verifique la estructura del objeto:
Código\(\PageIndex{16}\) (R):
Como se requiere para calcular la correlación, verificar primero la normalidad:
Código\(\PageIndex{17}\) (R):
Bueno, a estos datos solo podemos aplicar métodos no paramétricos:
Código\(\PageIndex{18}\) (R):
(Tenga en cuenta que se empleó “por pares”, hay muchos NA).
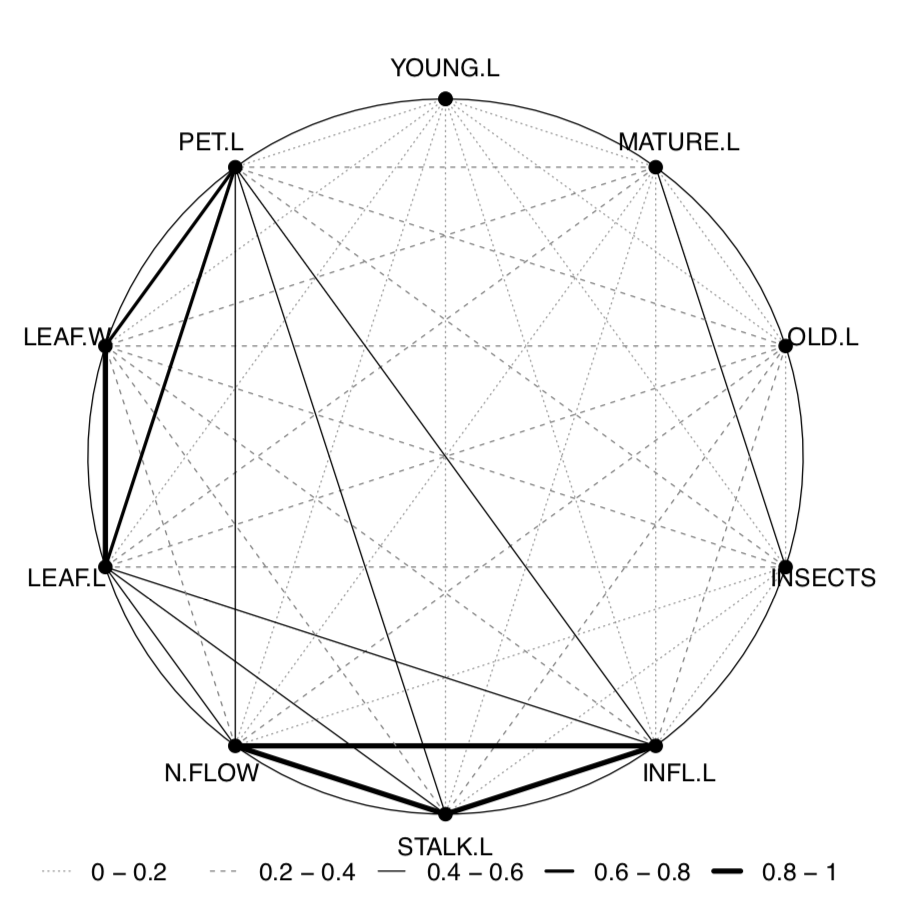
La última parcela (Figura\(\PageIndex{4}\)) muestra dos pleíadas de correlación más importantes: una relacionada con el tamaño de la hoja y otra con inflorescencia.
Como sabemos ahora qué caracteres están más correlacionados, se procede al modelo lineal. Dado que en el desarrollo del tallo de sol se formó primero, aceptemos STALK.L como variable independiente (influencia), e INFL.L como variable dependiente (respuesta):
Código\(\PageIndex{19}\) (R):
Modelo confiable con alto R-cuadrado. Sin embargo, la normalidad de los residuos no es perfecta (por favor revise las parcelas modelo usted mismo).
Ahora al análisis de la longitud de la hoja. Determinar cuáles son las tres poblaciones más grandes y subconjuntos de los datos:
Código\(\PageIndex{20}\) (R):
Ahora necesitamos trazarlos y verificar si hay diferencias visuales:
Código\(\PageIndex{21}\) (R):
Sí, probablemente existan (por favor revise la parcela usted mismo).
Vale la pena mirar en similitud de rangos:
Código\(\PageIndex{22}\) (R):
El estadístico de rango robusto, MAD (mediana de desviación absoluta) muestra que las variaciones son similares. También se realizó el análogo no paramétrico de la prueba de Bartlett para ver la significancia estadística de esta similitud. Sí, las varianzas son estadísticamente similares.
Como tenemos tres poblaciones para analizar, necesitaremos algo parecido a Anova, pero no paramétrico:
Código\(\PageIndex{23}\) (R):
Sí, hay al menos una población donde la longitud de la hoja es diferente de todas las demás. Para ver cual, necesitamos una prueba post hoc, por pares:
Código\(\PageIndex{24}\) (R):
La población N1 es la más divergente mientras que Q1 no es realmente diferente de L.
Regresión logística
Respuesta a la pregunta sobre demostración de objetos. Vamos a ir de la misma manera que en el ejemplo sobre programadores. Después de cargar los datos, los adjuntamos por simplicidad:
Código\(\PageIndex{25}\) (R):
Compruebe el modelo:
Código\(\PageIndex{26}\) (R):
(Al llamar a las variables, tomamos en cuenta el hecho de que R asigna nombres como V1, V2, V3 etc. a columnas “anónimas”.)
Como se puede ver, el modelo es significativo. Significa que algo de aprendizaje se lleva a cabo dentro del experimento.
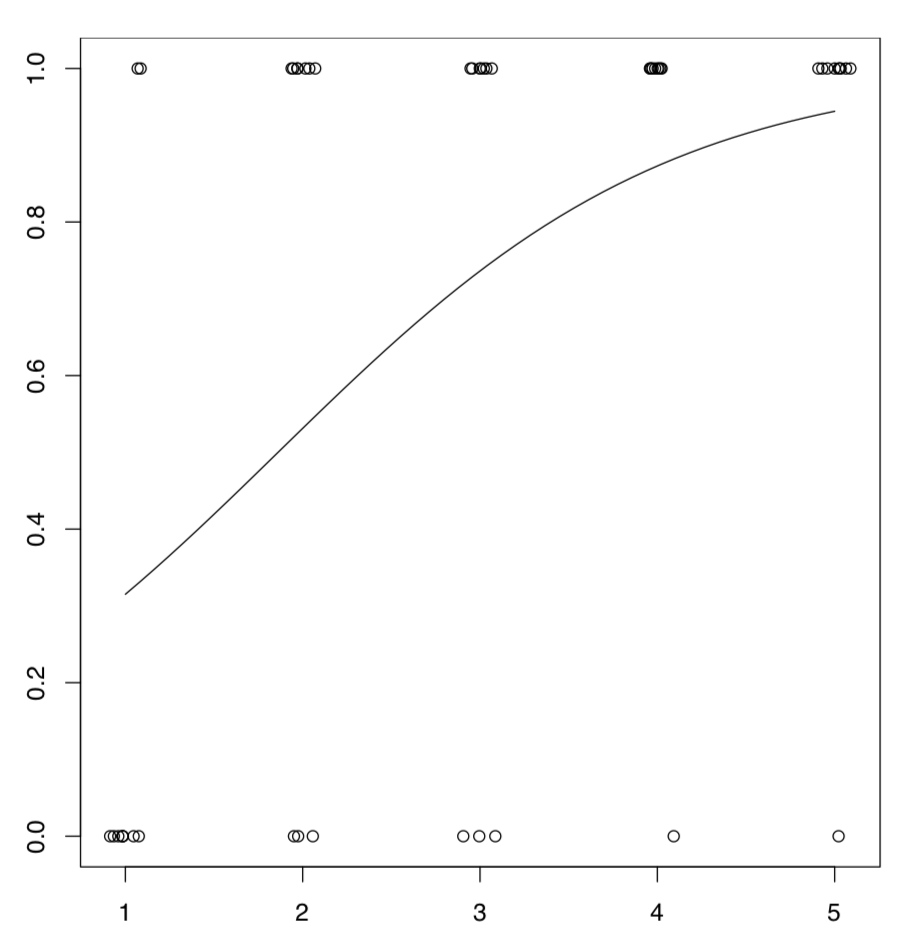
Es posible representar gráficamente el modelo logístico (Figura\(\PageIndex{5}\)):
Código\(\PageIndex{27}\) (R):
Usamos la función predict () para calcular las probabilidades de éxito para intentos no existentes, y también agregamos pequeño ruido aleatorio con función jitter () para evitar la superposición.
Respuesta a las preguntas de enebro. Comprobar archivo, cargarlo, verificar el objeto:
Código\(\PageIndex{28}\) (R):
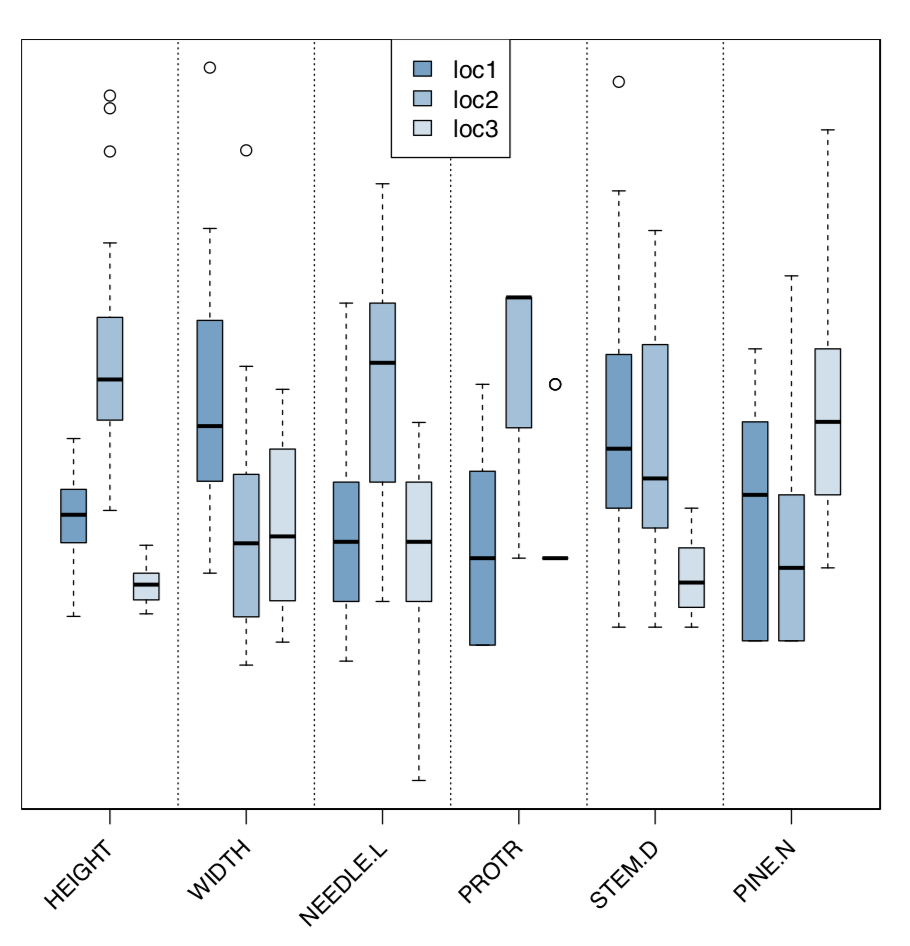
Analizar gráficamente los caracteres morfológicos y ecológicos (Figura\(\PageIndex{6}\)):
Código\(\PageIndex{29}\) (R):
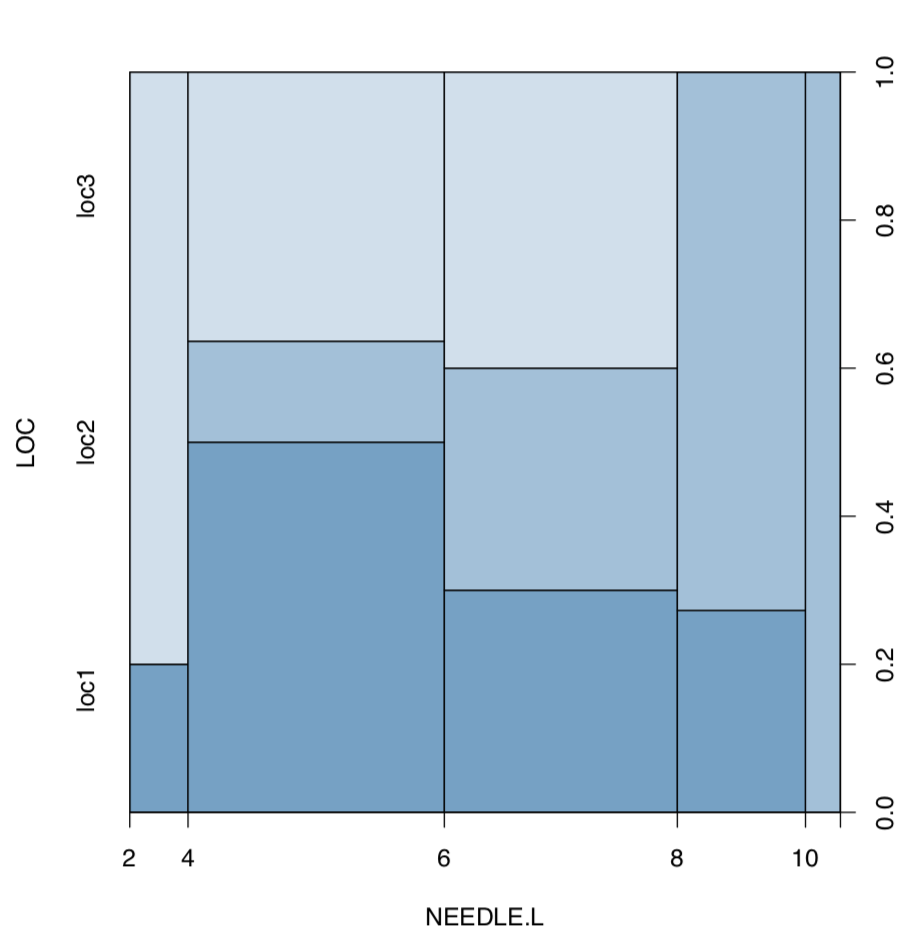
Ahora trazar la longitud de las agujas contra la ubicación (Figura\(\PageIndex{7}\)):
Código\(\PageIndex{30}\) (R):
(Como ve, la gráfica de columna vertebral funciona con datos de medición).
Dado que hay un carácter de medición y varias ubicaciones, la más adecuada es la aproximación similar a la de Anova. Primero tenemos que verificar las suposiciones:
Código\(\PageIndex{31}\) (R):
Código\(\PageIndex{32}\) (R):
(Obsérvese cómo calculamos eta-cuadrado, el tamaño del efecto de ANOVA. Como ves, esto podría hacerse a través del modelo lineal.)
Hay diferencia significativa entre la segunda y otras dos ubicaciones.
Y al segundo problema. Primero, hacemos una nueva variable basada en la expresión lógica de diferencias de caracteres:
Código\(\PageIndex{33}\) (R):
Hay ambas “especies” en los datos. Ahora, trazamos densidad condicional y analizamos regresión logística:
Código\(\PageIndex{34}\) (R):
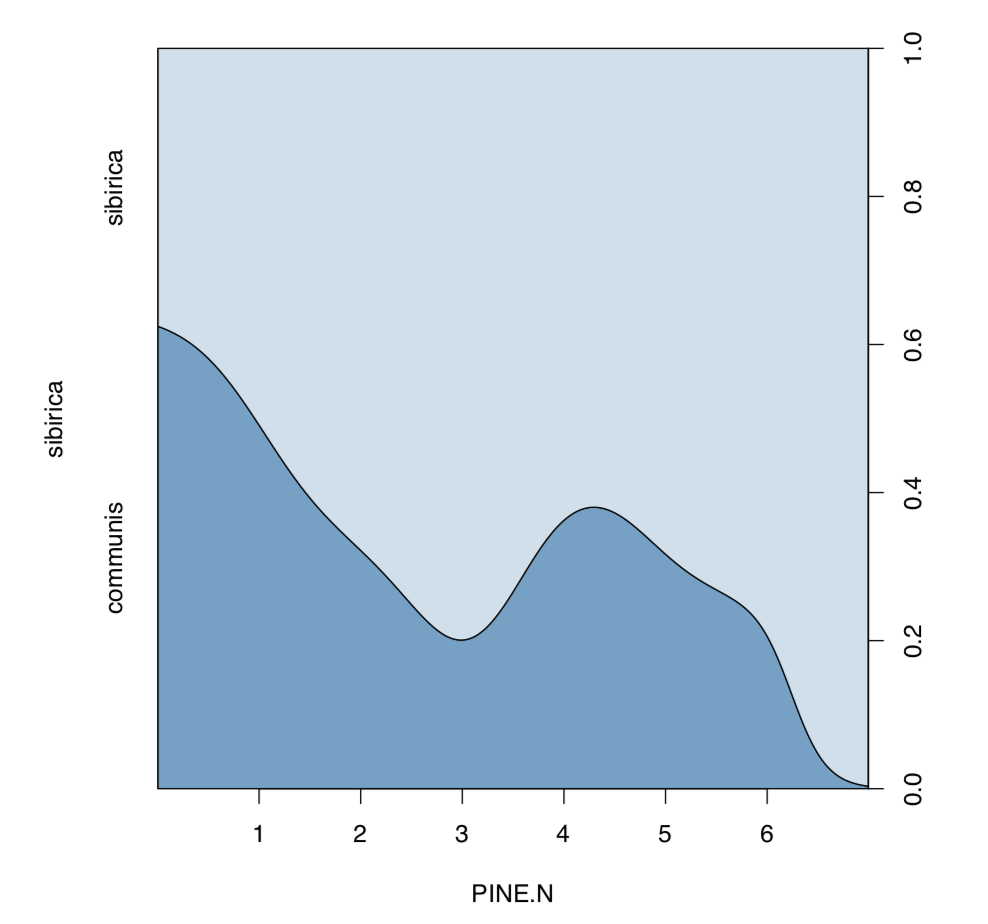
La gráfica de densidad condicional (Figura\(\PageIndex{8}\)) muestra una tendencia aparente y el resumen del modelo genera significancia para el coeficiente de pendiente.
En la página siguiente, hay una tabla (Tabla\(\PageIndex{1}\)) con una clave que podría ayudar a elegir el método inferencial correcto si se conoce el número de muestras y el tipo de los datos.
| Tipo de datos | Una variable | Dos variables | Muchas variables |
|---|---|---|---|
| Medición, normalmente distribuida | prueba t |
Diferencia: prueba t (emparejada y no emparejada), prueba F (escala) Tamaño del efecto: d de Cohen, K de Lyobishchev Relación: correlación, modelos lineales |
Modelos lineales, ANOVA, prueba unidireccional, prueba Bartlett (escala) Post hoc: prueba de pares, Tukey HSD Tamaño del efecto: R-cuadrado |
| Medición y clasificación | Prueba de Wilcoxon, prueba Shapiro-Wilk |
Diferencia: prueba de Wilcoxon (emparejado y no emparejado), prueba de signo, prueba irder de rango robusto, prueba de Ansari Bradley (escala) Tamaño del efecto: Delta del acantilado, K de Lyobishchev Relación: correlación no paramétrica |
Modelos lineales, LOESS, prueba de Kruskal-Wallis, prueba de Friedman, prueba de Fligner-Killeen (escala) Post hoc: prueba de Wilcoxon por pares, prueba de orden de rango robusta por pares Tamaño del efecto: R-cuadrado |
| Categórico | Prueba de proporciones de una muestra, prueba de bondad de ajuste |
Asociación: prueba de Chi-cuadrado, prueba exacta de Fisher, prueba de proporciones, prueba G, prueba de McNemar (pareado) Tamaño del efecto: V de Cramer, T de Tschuprow, ratio de probabilidades |
Pruebas de asociación (ver a la izquierda); modelos lineales generalizados de familia binomial (= regresión logística) Post hoc: prueba de mesa por pares |
Tabla\(\PageIndex{1}\) Clave de los métodos estadísticos inferenciales más importantes (excepto multivariantes). Después de acotar la búsqueda con un par de métodos, proceda al texto principal.