
6.3: Probabilidad del éxito- regresión logística
- Page ID
- 150156

Existen algunos métodos analíticos que trabajan con variables categóricas. Prácticamente, estamos restringidos aquí con pruebas de proporción y chi-cuadrado. Sin embargo, el objetivo a veces es más complicado ya que es posible que queramos verificar no solo la presencia de la correspondencia sino también sus características, algo así como el análisis de regresión sino para los datos nominales. En lenguaje de fórmulas, esto podría describirse como
factor ~ influencia
A continuación se muestra un ejemplo usando datos de entrevistas de contratación. Se pidió a los programadores con diferentes meses de experiencia profesional que escribieran un programa en papel. Entonces el programa se ingresó en la memoria de una computadora y si funcionaba, el caso se marcó con “S” (éxito) y “F” (falla) de lo contrario:
Código\(\PageIndex{1}\) (R):
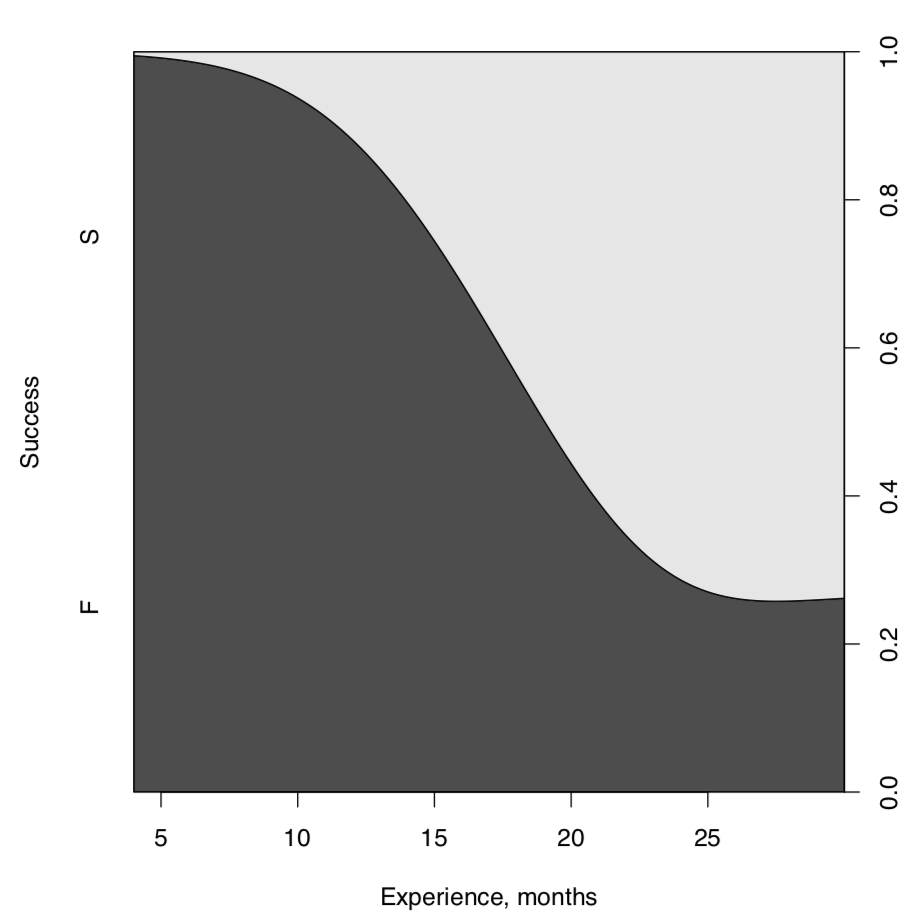
Es más o menos obvio que los programadores más experimentados tienen más éxito. Esto incluso es posible verificarlo visualmente, con cdplot () (Figura\(\PageIndex{2}\)):
Código\(\PageIndex{2}\) (R):
Pero, ¿es posible determinar numéricamente la dependencia entre los años de experiencia y el éxito de la programación? Las tablas de contingencia no son una buena solución porque V1 es una variable de medición. La regresión lineal no funcionará porque la respuesta aquí es un factor. Pero hay una solución. Podemos investigar el modelo donde la respuesta no es un éxito/fracaso sino la probabilidad de éxito (que, como todas las probabilidades es una variable de medición que cambia de 0 a 1):
Código\(\PageIndex{3}\) (R):
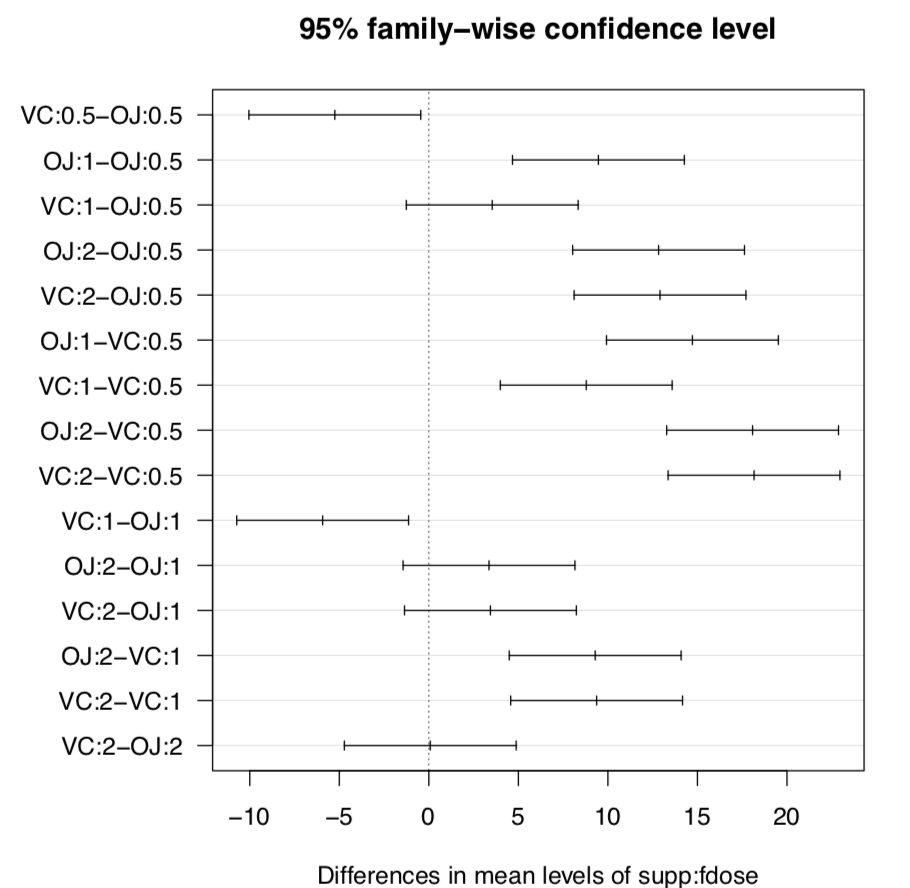
No profundizando en los detalles, podemos ver aquí que ambos parámetros de la regresión son significativos ya que los valores p son pequeños. Esto es suficiente para decir que la experiencia influye en el éxito de la programación.
El archivo seeing.txt provino de los resultados del siguiente experimento. A las personas se les mostraron algunos objetos por el corto tiempo, y posteriormente se les pidió que describieran estos objetos. La primera columna del archivo de datos contiene el ID de persona, en segundo lugar, el número de objeto (cinco objetos se mostraron a cada persona en secuencia) y la tercera columna es el éxito/fracaso de la descripción (en formato binario 0/1). ¿Existe dependencia entre el número de objeto y el éxito?
La salida de summary.glm () contiene el valor AIC. Se acepta que el AIC más pequeño corresponde con el modelo más óptimo. Para demostrarlo, volveremos al ejemplo de intoxicación del capítulo anterior. ¿Tomates o ensalada?
Código\(\PageIndex{4}\) (R):
Al principio, creamos el modelo de regresión logística. Dado que “necesita” la respuesta binaria, restamos el valor de ILL de 2 por lo que la enfermedad se codificó como 0 y ninguna enfermedad como 1. La función I () se utilizó para evitar que la resta sea interpretada como una fórmula modelo, y nuestro símbolo menos solo tenía significado aritmético. En el siguiente paso, usamos update () para modificar el modelo inicial quitando los tomates, luego retiramos la ensalada (los puntos significan que usamos todas las influencias y respuestas iniciales). Ahora a la AIC:
Código\(\PageIndex{5}\) (R):
El modelo sin tomates pero con ensalada es el más óptimo. Significa que lo más probable es que el agente envenenador fuera solo la ensalada César.
Ahora bien, en aras de la completitud, los lectores podrían tener dudas si hay métodos similares a la regresión logística pero que utilizan no dos sino muchos niveles de factores como respuesta. ¿Y métodos que utilizan variables clasificadas (ordinales) como respuesta? (Como recordatorio, la variable de medición como respuesta es una propiedad de regresión lineal y similar). Sus nombres son regresión multinomial y regresión ordinal, y existen funciones apropiadas en varios paquetes R, por ejemplo, nnet, rms y ordinal.
El archivo juniperus.txt en el repositorio abierto contiene mediciones de caracteres morfológicos y ecológicos en varias poblaciones árticas de enebros (Juniperus). Analice cómo se distribuyen las mediciones entre las poblaciones y verifique específicamente si la longitud de la aguja es diferente entre las ubicaciones.
Otro problema es que los enebros de menor tamaño (altura menor a 1 m) y con agujas más cortas (menos de 8 mm) fueron frecuentemente separados del enebro común (Juniperus communis) en otra especie, J. sibirica. Por favor verifique si las plantas con caracteres J. sibirica están presentes en los datos, y la probabilidad de ser J. sibirica depende de la cantidad de pinos sombreados en las inmediaciones (carácter PINE.N).