
7.4: Aprendizaje semi-supervisado
- Page ID
- 149988

No existe una distinción profunda entre métodos supervisados y no supevisados, algunos de los no supervisados (como SOM o PCA) podrían usar entrenamiento mientras que algunos supervisados (LDA, Random Forest, particionamiento recursivo) son útiles directamente como visualizaciones.
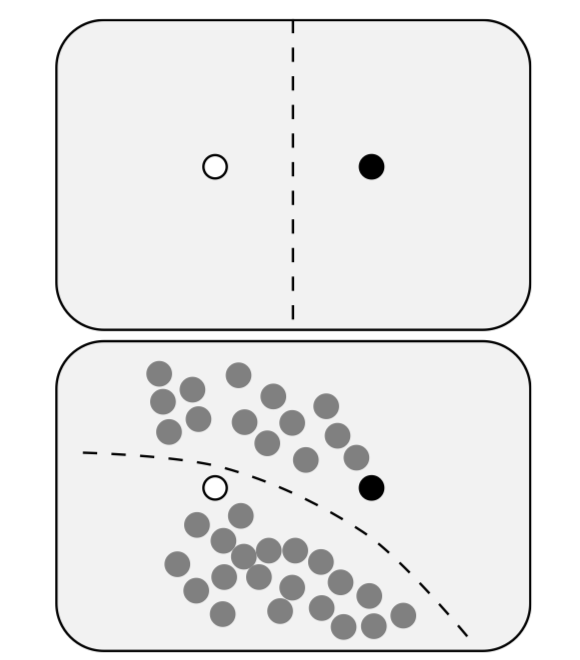
Y hay un aprendizaje intermedio semisupervisado. Toma en cuenta tanto las características de datos como el etiquetado de datos (Figura\(\PageIndex{2}\)).
Una de las características más importantes de SSL es la capacidad de trabajar con la muestra de entrenamiento muy pequeña. Muchas ideas realmente brillantes están incrustadas en SSL, aquí ilustramos dos de ellas. El autoaprendizaje es cuando la clasificación se desarrolla en múltiples ciclos. En cada ciclo, los puntos de prueba que son más seguros, se etiquetan y se agregan al conjunto de entrenamiento:
Código\(\PageIndex{1}\) (R):
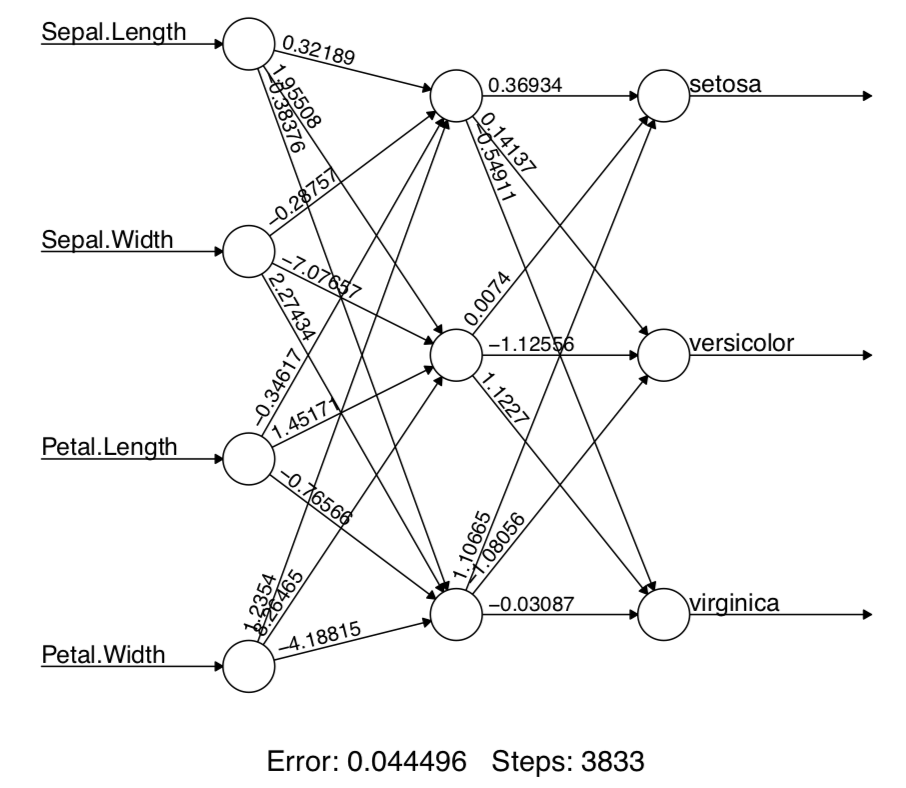
Como ves, con solo 5 puntos de datos (aproximadamente 3% de los datos vs 33% de los datos en iris.train), el autoinclinamiento semi-supervisado (basado en el incremento del gradiente en este caso) alcanzó 73% de precisión.
Otro enfoque semi-supervisado se basa en la teoría de grafos y utiliza la propagación de etiquetas gráficas:
Código\(\PageIndex{2}\) (R):
La idea de este algoritmo es similar a lo que se mostró en la ilustración (Figura\(\PageIndex{2}\)) anterior. La propagación de etiquetas con 10 puntos supera a Randon Forest (ver arriba) que utilizó 30 puntos.