
5.7: Limpieza y puesta en orden de datos con R
- Page ID
- 150535

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Ahora que conoces un poco sobre el tidyverse, veamos las diversas herramientas que proporciona para trabajar con datos. Utilizaremos como ejemplo un análisis de si las actitudes sobre la estadística son diferentes entre los diferentes grupos del curso estudiantil en la clase.
5.7.1 Datos de actitud estadística de la encuesta del curso
Estos datos se recolectaron utilizando la escala Actitudes hacia la Estadística (ATS) (de https://www.stat.auckland.ac.nz/~iase/cblumberg/wise2.pdf).
El ATS de 29 ítems tiene dos subescalas. La subescala Actitudes hacia el Campo consta de los siguientes 20 ítems, con ítems de clave inversa indicados por una “(R)”: 1, 3, 5, 6 (R), 9, 10 (R), 11, 13, 14 (R), 16 (R), 17, 19, 20 (R), 21, 22, 23, 24, 26, 28 (R), 29
La subescala Actitudes hacia el curso consta de los siguientes 9 ítems: 2 (R), 4 (R), 7 (R), 8, 12 (R), 15 (R), 18 (R), 25 (R), 27 (R)
Para nuestros propósitos, simplemente combinaremos los 29 artículos juntos, en lugar de separarlos en estas subescalas.
Nota: He eliminado los datos de los alumnos de posgrado y de los alumnos de 5+ años, ya que esos serían muy fácilmente identificables dado lo pocos que hay.
Primero guardemos la ruta del archivo a los datos.
attitudeData_file <- 'data/statsAttitude.txt'A continuación, carguemos los datos del archivo usando la función tidyverse read_tsv (). Hay varias funciones disponibles para leer en diferentes formatos de archivo como parte del paquete readr tidyverse.
attitudeData <- read_tsv(attitudeData_file)
glimpse(attitudeData)## Observations: 148
## Variables: 31
## $ `What year are you at Stanford?` <dbl> …
## $ `Have you ever taken a statistics course before?` <chr> …
## $ `I feel that statistics will be useful to me in my profession.` <dbl> …
## $ `The thought of being enrolled in a statistics course makes me nervous.` <dbl> …
## $ `A good researcher must have training in statistics.` <dbl> …
## $ `Statistics seems very mysterious to me.` <dbl> …
## $ `Most people would benefit from taking a statistics course.` <dbl> …
## $ `I have difficulty seeing how statistics relates to my field of study.` <dbl> …
## $ `I see being enrolled in a statistics course as a very unpleasant experience.` <dbl> …
## $ `I would like to continue my statistical training in an advanced course.` <dbl> …
## $ `Statistics will be useful to me in comparing the relative merits of different objects, methods, programs, etc.` <dbl> …
## $ `Statistics is not really very useful because it tells us what we already know anyway.` <dbl> …
## $ `Statistical training is relevant to my performance in my field of study.` <dbl> …
## $ `I wish that I could have avoided taking my statistics course.` <dbl> …
## $ `Statistics is a worthwhile part of my professional training.` <dbl> …
## $ `Statistics is too math oriented to be of much use to me in the future.` <dbl> …
## $ `I get upset at the thought of enrolling in another statistics course.` <dbl> …
## $ `Statistical analysis is best left to the "experts" and should not be part of a lay professional's job.` <dbl> …
## $ `Statistics is an inseparable aspect of scientific research.` <dbl> …
## $ `I feel intimidated when I have to deal with mathematical formulas.` <dbl> …
## $ `I am excited at the prospect of actually using statistics in my job.` <dbl> …
## $ `Studying statistics is a waste of time.` <dbl> …
## $ `My statistical training will help me better understand the research being done in my field of study.` <dbl> …
## $ `One becomes a more effective "consumer" of research findings if one has some training in statistics.` <dbl> …
## $ `Training in statistics makes for a more well-rounded professional experience.` <dbl> …
## $ `Statistical thinking can play a useful role in everyday life.` <dbl> …
## $ `Dealing with numbers makes me uneasy.` <dbl> …
## $ `I feel that statistics should be required early in one's professional training.` <dbl> …
## $ `Statistics is too complicated for me to use effectively.` <dbl> …
## $ `Statistical training is not really useful for most professionals.` <dbl> …
## $ `Statistical thinking will one day be as necessary for efficient citizenship as the ability to read and write.` <dbl> …En este momento los nombres de las variables son difíciles de manejar, ya que incluyen el nombre completo del ítem; así es como Google Forms almacena los datos. Cambiemos los nombres de las variables para que sean algo más legibles. Cambiaremos los nombres a “atsname () y paste0 (). name () es bastante autoexplicativo: se asigna un nuevo nombre a un nombre antiguo o a una posición de columna. La función paste0 () toma una cadena junto con un conjunto de números y crea un vector que combina la cadena con el número.
nQuestions <- 29 # other than the first two columns, the rest of the columns are for the 29 questions in the statistics attitude survey; we'll use this below to rename these columns based on their question number
# use rename to change the first two column names
# rename can refer to columns either by their number or their name
attitudeData <-
attitudeData %>%
rename( # rename using columm numbers
# The first column is the year
Year = 1,
# The second column indicates whether the person took stats before
StatsBefore = 2
) %>%
rename_at(
# rename all the columns except Year and StatsBefore
vars(-Year, -StatsBefore),
#rename by pasting the word "stat" and the number
funs(paste0('ats', 1:nQuestions))
)
# print out the column names
names(attitudeData)## [1] "Year" "StatsBefore" "ats1" "ats2" "ats3"
## [6] "ats4" "ats5" "ats6" "ats7" "ats8"
## [11] "ats9" "ats10" "ats11" "ats12" "ats13"
## [16] "ats14" "ats15" "ats16" "ats17" "ats18"
## [21] "ats19" "ats20" "ats21" "ats22" "ats23"
## [26] "ats24" "ats25" "ats26" "ats27" "ats28"
## [31] "ats29"#check out the data again
glimpse(attitudeData)## Observations: 148
## Variables: 31
## $ Year <dbl> 3, 4, 2, 1, 2, 3, 4, 2, 2, 2, 4, 2, 3…
## $ StatsBefore <chr> "Yes", "No", "No", "Yes", "No", "No",…
## $ ats1 <dbl> 6, 4, 6, 3, 7, 4, 6, 5, 7, 5, 5, 4, 2…
## $ ats2 <dbl> 1, 5, 5, 2, 7, 5, 5, 4, 2, 2, 3, 3, 7…
## $ ats3 <dbl> 7, 6, 5, 7, 2, 4, 7, 7, 7, 5, 6, 5, 7…
## $ ats4 <dbl> 2, 5, 5, 2, 7, 3, 3, 4, 5, 3, 3, 2, 3…
## $ ats5 <dbl> 7, 5, 6, 7, 5, 4, 6, 6, 7, 5, 3, 5, 4…
## $ ats6 <dbl> 1, 4, 5, 2, 2, 4, 2, 3, 1, 2, 2, 3, 1…
## $ ats7 <dbl> 1, 4, 3, 2, 4, 4, 2, 2, 3, 2, 4, 2, 4…
## $ ats8 <dbl> 2, 1, 4, 3, 1, 4, 4, 4, 7, 3, 2, 4, 1…
## $ ats9 <dbl> 5, 4, 5, 5, 7, 4, 5, 5, 7, 6, 3, 5, 5…
## $ ats10 <dbl> 2, 3, 2, 2, 1, 4, 2, 2, 1, 3, 3, 1, 1…
## $ ats11 <dbl> 6, 4, 6, 2, 7, 4, 6, 5, 7, 3, 3, 4, 2…
## $ ats12 <dbl> 2, 4, 1, 2, 5, 7, 2, 1, 2, 4, 4, 2, 4…
## $ ats13 <dbl> 6, 4, 5, 5, 7, 3, 6, 6, 7, 5, 2, 5, 1…
## $ ats14 <dbl> 2, 4, 3, 3, 3, 4, 2, 1, 1, 3, 3, 2, 1…
## $ ats15 <dbl> 2, 4, 3, 3, 5, 6, 3, 4, 2, 3, 2, 4, 3…
## $ ats16 <dbl> 1, 3, 2, 5, 1, 5, 2, 1, 2, 3, 2, 2, 1…
## $ ats17 <dbl> 7, 7, 5, 7, 7, 4, 6, 6, 7, 6, 6, 7, 4…
## $ ats18 <dbl> 2, 5, 4, 5, 7, 4, 2, 4, 2, 5, 2, 4, 6…
## $ ats19 <dbl> 3, 3, 4, 3, 2, 3, 6, 5, 7, 3, 3, 5, 2…
## $ ats20 <dbl> 1, 4, 1, 2, 1, 4, 2, 2, 1, 2, 3, 2, 3…
## $ ats21 <dbl> 6, 3, 5, 5, 7, 5, 6, 5, 7, 3, 4, 6, 6…
## $ ats22 <dbl> 7, 4, 5, 6, 7, 5, 6, 5, 7, 5, 5, 5, 5…
## $ ats23 <dbl> 6, 4, 6, 6, 7, 5, 6, 7, 7, 5, 3, 5, 3…
## $ ats24 <dbl> 7, 4, 4, 6, 7, 5, 6, 5, 7, 5, 5, 5, 3…
## $ ats25 <dbl> 3, 5, 3, 3, 5, 4, 3, 4, 2, 3, 3, 2, 5…
## $ ats26 <dbl> 7, 4, 5, 6, 2, 4, 6, 5, 7, 3, 4, 4, 2…
## $ ats27 <dbl> 2, 4, 2, 2, 4, 4, 2, 1, 2, 3, 3, 2, 1…
## $ ats28 <dbl> 2, 4, 3, 5, 2, 3, 3, 1, 1, 4, 3, 2, 2…
## $ ats29 <dbl> 4, 4, 3, 6, 2, 1, 5, 3, 3, 3, 2, 3, 2…Lo siguiente que tenemos que hacer es crear una identificación para cada individuo. Para ello, usaremos la función rownames_to_column () del tidyverse. Esto crea una nueva variable (que nombramos “ID”) que contiene los nombres de fila del marco de datos; thsee son simplemente los números 1 a N.
# let's add a participant ID so that we will be able to identify them later
attitudeData <-
attitudeData %>%
rownames_to_column(var = 'ID')
head(attitudeData)## # A tibble: 6 x 32
## ID Year StatsBefore ats1 ats2 ats3 ats4 ats5
## <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 3 Yes 6 1 7 2 7
## 2 2 4 No 4 5 6 5 5
## 3 3 2 No 6 5 5 5 6
## 4 4 1 Yes 3 2 7 2 7
## 5 5 2 No 7 7 2 7 5
## 6 6 3 No 4 5 4 3 4
## # … with 24 more variables: ats6 <dbl>, ats7 <dbl>,
## # ats8 <dbl>, ats9 <dbl>, ats10 <dbl>, ats11 <dbl>,
## # ats12 <dbl>, ats13 <dbl>, ats14 <dbl>, ats15 <dbl>,
## # ats16 <dbl>, ats17 <dbl>, ats18 <dbl>, ats19 <dbl>,
## # ats20 <dbl>, ats21 <dbl>, ats22 <dbl>, ats23 <dbl>,
## # ats24 <dbl>, ats25 <dbl>, ats26 <dbl>, ats27 <dbl>,
## # ats28 <dbl>, ats29 <dbl>Si miras de cerca los datos, puedes ver que algunos de los participantes tienen algunas respuestas faltantes. Podemos contarlos para cada individuo y crear una nueva variable para almacenar esta en una nueva variable llamada NumNA usando mutate ().
También podemos crear una tabla que muestre cuántos participantes tienen un número particular de valores de NA. Aquí usamos dos comandos adicionales que aún no has visto. La función group_by () le dice a otras funciones que hagan sus análisis mientras divide los datos en grupos basados en una de las variables. Aquí vamos a querer resumir el número de personas con cada número posible de NA, así vamos a agrupar las respuestas por la variable NumNA que estamos creando en el primer comando aquí.
La función summary () crea un resumen de los datos, con las nuevas variables basadas en los datos que se alimentan. En este caso, solo queremos contar el número de sujetos en cada grupo, lo que podemos hacer usando la función especial n () de dpylr.
# compute the number of NAs for each participant
attitudeData <-
attitudeData %>%
mutate(
numNA = rowSums(is.na(.)) # we use the . symbol to tell the is.na function to look at the entire data frame
)
# present a table with counts of the number of missing responses
attitudeData %>%
count(numNA)## # A tibble: 3 x 2
## numNA n
## <dbl> <int>
## 1 0 141
## 2 1 6
## 3 2 1Podemos ver en la tabla que sólo hay unos pocos participantes a los que les faltan datos; a seis personas les falta una respuesta, y a una le faltan dos respuestas. Busquemos a esos individuos, usando el comando filter () de dplyr. filter () devuelve el subconjunto de filas de un marco de datos que coinciden con una prueba en particular, en este caso, si NumNA es > 0.
attitudeData %>%
filter(numNA > 0)## # A tibble: 7 x 33
## ID Year StatsBefore ats1 ats2 ats3 ats4 ats5
## <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 42 2 No NA 2 7 5 6
## 2 55 1 No 5 3 7 4 5
## 3 90 1 No 7 2 7 5 7
## 4 113 2 No 5 7 7 5 6
## 5 117 2 Yes 6 6 7 4 6
## 6 137 3 No 7 5 6 5 6
## 7 139 1 No 7 5 7 5 6
## # … with 25 more variables: ats6 <dbl>, ats7 <dbl>,
## # ats8 <dbl>, ats9 <dbl>, ats10 <dbl>, ats11 <dbl>,
## # ats12 <dbl>, ats13 <dbl>, ats14 <dbl>, ats15 <dbl>,
## # ats16 <dbl>, ats17 <dbl>, ats18 <dbl>, ats19 <dbl>,
## # ats20 <dbl>, ats21 <dbl>, ats22 <dbl>, ats23 <dbl>,
## # ats24 <dbl>, ats25 <dbl>, ats26 <dbl>, ats27 <dbl>,
## # ats28 <dbl>, ats29 <dbl>, numNA <dbl>Existen técnicas elegantes para tratar de adivinar el valor de los datos faltantes (conocidos como “imputación”) pero como el número de participantes a los que les faltan valores es pequeño, simplemente dejemos a esos participantes de la lista. Podemos hacer esto usando la función drop_na () del paquete tidyr, otro paquete tidyverse que proporciona herramientas para limpiar datos. También eliminaremos la variable NumNA, ya que ya no la necesitaremos después de eliminar los sujetos con respuestas faltantes. Hacemos esto usando la función select () del paquete dplyr tidyverse, que selecciona o elimina columnas de un marco de datos. Al poner un signo menos frente a NumNA, le estamos diciendo que elimine esa columna.
select () y filter () son similares - select () trabaja en columnas (es decir, variables) y filter () trabaja en filas (es decir, observaciones).
# this is equivalent to drop_na(attitudeData)
attitudeDataNoNA <-
attitudeData %>%
drop_na() %>%
select(-numNA)
glimpse(attitudeDataNoNA)## Observations: 141
## Variables: 32
## $ ID <chr> "1", "2", "3", "4", "5", "6", "7", "8…
## $ Year <dbl> 3, 4, 2, 1, 2, 3, 4, 2, 2, 2, 4, 2, 3…
## $ StatsBefore <chr> "Yes", "No", "No", "Yes", "No", "No",…
## $ ats1 <dbl> 6, 4, 6, 3, 7, 4, 6, 5, 7, 5, 5, 4, 2…
## $ ats2 <dbl> 1, 5, 5, 2, 7, 5, 5, 4, 2, 2, 3, 3, 7…
## $ ats3 <dbl> 7, 6, 5, 7, 2, 4, 7, 7, 7, 5, 6, 5, 7…
## $ ats4 <dbl> 2, 5, 5, 2, 7, 3, 3, 4, 5, 3, 3, 2, 3…
## $ ats5 <dbl> 7, 5, 6, 7, 5, 4, 6, 6, 7, 5, 3, 5, 4…
## $ ats6 <dbl> 1, 4, 5, 2, 2, 4, 2, 3, 1, 2, 2, 3, 1…
## $ ats7 <dbl> 1, 4, 3, 2, 4, 4, 2, 2, 3, 2, 4, 2, 4…
## $ ats8 <dbl> 2, 1, 4, 3, 1, 4, 4, 4, 7, 3, 2, 4, 1…
## $ ats9 <dbl> 5, 4, 5, 5, 7, 4, 5, 5, 7, 6, 3, 5, 5…
## $ ats10 <dbl> 2, 3, 2, 2, 1, 4, 2, 2, 1, 3, 3, 1, 1…
## $ ats11 <dbl> 6, 4, 6, 2, 7, 4, 6, 5, 7, 3, 3, 4, 2…
## $ ats12 <dbl> 2, 4, 1, 2, 5, 7, 2, 1, 2, 4, 4, 2, 4…
## $ ats13 <dbl> 6, 4, 5, 5, 7, 3, 6, 6, 7, 5, 2, 5, 1…
## $ ats14 <dbl> 2, 4, 3, 3, 3, 4, 2, 1, 1, 3, 3, 2, 1…
## $ ats15 <dbl> 2, 4, 3, 3, 5, 6, 3, 4, 2, 3, 2, 4, 3…
## $ ats16 <dbl> 1, 3, 2, 5, 1, 5, 2, 1, 2, 3, 2, 2, 1…
## $ ats17 <dbl> 7, 7, 5, 7, 7, 4, 6, 6, 7, 6, 6, 7, 4…
## $ ats18 <dbl> 2, 5, 4, 5, 7, 4, 2, 4, 2, 5, 2, 4, 6…
## $ ats19 <dbl> 3, 3, 4, 3, 2, 3, 6, 5, 7, 3, 3, 5, 2…
## $ ats20 <dbl> 1, 4, 1, 2, 1, 4, 2, 2, 1, 2, 3, 2, 3…
## $ ats21 <dbl> 6, 3, 5, 5, 7, 5, 6, 5, 7, 3, 4, 6, 6…
## $ ats22 <dbl> 7, 4, 5, 6, 7, 5, 6, 5, 7, 5, 5, 5, 5…
## $ ats23 <dbl> 6, 4, 6, 6, 7, 5, 6, 7, 7, 5, 3, 5, 3…
## $ ats24 <dbl> 7, 4, 4, 6, 7, 5, 6, 5, 7, 5, 5, 5, 3…
## $ ats25 <dbl> 3, 5, 3, 3, 5, 4, 3, 4, 2, 3, 3, 2, 5…
## $ ats26 <dbl> 7, 4, 5, 6, 2, 4, 6, 5, 7, 3, 4, 4, 2…
## $ ats27 <dbl> 2, 4, 2, 2, 4, 4, 2, 1, 2, 3, 3, 2, 1…
## $ ats28 <dbl> 2, 4, 3, 5, 2, 3, 3, 1, 1, 4, 3, 2, 2…
## $ ats29 <dbl> 4, 4, 3, 6, 2, 1, 5, 3, 3, 3, 2, 3, 2…Pruebe lo siguiente por su cuenta: Usando el marco de datos AttitudeData, elimine los valores NA, cree una nueva variable llamada misterio que contenga un valor de 1 para cualquiera que haya respondido 7 a la pregunta ats4 (“Las estadísticas me parecen muy misteriosas”). Crear un resumen que incluya el número de personas que reportaron 7 sobre esta pregunta, y la proporción de personas que reportaron 7.
5.7.1.1 Datos ordenados
Estos datos están en un formato que cumple con los principios de “datos ordenados”, los cuales establecen lo siguiente:
- Cada variable debe tener su propia columna.
- Cada observación debe tener su propia fila.
- Cada valor debe tener su propia celda.
Esto se muestra gráficamente la siguiente figura (de Hadley Wickham, desarrollador del “tidyverse”):
[Seguir tres reglas hace que un conjunto de datos esté ordenado: las variables están en columnas, las observaciones están en filas y los valores están en celdas..]
En nuestro caso, cada columna representa una variable: ID identifica qué estudiante respondió, Year contiene su año en Stanford, StatsBefore contiene si han tomado o no estadísticas antes, y ats1 a ats29 contienen sus respuestas a cada ítem en la escala ATS . Cada observación (fila) es una respuesta de un estudiante individual. Cada valor tiene su propia celda (por ejemplo, los valores de Year y StatsBeFOE se almacenan en celdas separadas en columnas separadas).
Para un ejemplo de datos que NO están ordenados, eche un vistazo a estos datos Belief in Hell - haga clic en la pestaña “Tabla” para ver los datos.
- Cuáles son las variables
- ¿Por qué estos datos no están ordenados?
5.7.1.2 Datos de recodificación
Ahora tenemos datos ordenados; sin embargo, algunos de los ítems ATS requieren recodificación. Específicamente, algunos de los ítems necesitan ser “codificados de forma inversa”; estos ítems incluyen: ats2, ats4, ats6, ats7, ats10, ats12, ats14, ats15, ats16, ats18, ats20, ats25, ats27 y ats28. Las respuestas en bruto para cada ítem están en la escala 1-7; por lo tanto, para los ítems codificados inversos, necesitamos revertirlos restando la puntuación en bruto de 8 (de tal manera que 7 se convierte en 1 y 1 se convierte en 7). Para recodificar estos elementos, usaremos la función tidyverse mutate (). Es una buena idea a la hora de recodificar para preservar las variables originales sin procesar y crear nuevas variables recodificadas con diferentes nombres.
Hay dos formas en las que podemos usar la función mutate () para recodificar estas variables. La primera forma es más fácil de entender como un nuevo código, pero menos eficiente y más propenso al error. Específicamente, repetimos el mismo código para cada variable que queremos revertir el código de la siguiente manera:
attitudeDataNoNA %>%
mutate(
ats2_re = 8 - ats2,
ats4_re = 8 - ats4,
ats6_re = 8 - ats6,
ats7_re = 8 - ats7,
ats10_re = 8 - ats10,
ats12_re = 8 - ats12,
ats14_re = 8 - ats14,
ats15_re = 8 - ats15,
ats16_re = 8 - ats16,
ats18_re = 8 - ats18,
ats20_re = 8 - ats20,
ats25_re = 8 - ats25,
ats27_re = 8 - ats27,
ats28_re = 8 - ats28
) ## # A tibble: 141 x 46
## ID Year StatsBefore ats1 ats2 ats3 ats4 ats5
## <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 3 Yes 6 1 7 2 7
## 2 2 4 No 4 5 6 5 5
## 3 3 2 No 6 5 5 5 6
## 4 4 1 Yes 3 2 7 2 7
## 5 5 2 No 7 7 2 7 5
## 6 6 3 No 4 5 4 3 4
## 7 7 4 Yes 6 5 7 3 6
## 8 8 2 Yes 5 4 7 4 6
## 9 9 2 Yes 7 2 7 5 7
## 10 10 2 Yes 5 2 5 3 5
## # … with 131 more rows, and 38 more variables: ats6 <dbl>,
## # ats7 <dbl>, ats8 <dbl>, ats9 <dbl>, ats10 <dbl>,
## # ats11 <dbl>, ats12 <dbl>, ats13 <dbl>, ats14 <dbl>,
## # ats15 <dbl>, ats16 <dbl>, ats17 <dbl>, ats18 <dbl>,
## # ats19 <dbl>, ats20 <dbl>, ats21 <dbl>, ats22 <dbl>,
## # ats23 <dbl>, ats24 <dbl>, ats25 <dbl>, ats26 <dbl>,
## # ats27 <dbl>, ats28 <dbl>, ats29 <dbl>, ats2_re <dbl>,
## # ats4_re <dbl>, ats6_re <dbl>, ats7_re <dbl>,
## # ats10_re <dbl>, ats12_re <dbl>, ats14_re <dbl>,
## # ats15_re <dbl>, ats16_re <dbl>, ats18_re <dbl>,
## # ats20_re <dbl>, ats25_re <dbl>, ats27_re <dbl>,
## # ats28_re <dbl>La segunda forma es más eficiente y toma avanzacambio del uso de “verbos con alcance” (https://dplyr.tidyverse.org/reference/scoped.html), que permiten aplicar el mismo código a varias variables a la vez. Debido a que no tienes que seguir repitiendo el mismo código, es menos probable que cometas un error:
ats_recode <- #create a vector of the names of the variables to recode
c(
"ats2",
"ats4",
"ats6",
"ats7",
"ats10",
"ats12",
"ats14",
"ats15",
"ats16",
"ats18",
"ats20",
"ats25",
"ats27",
"ats28"
)
attitudeDataNoNA <-
attitudeDataNoNA %>%
mutate_at(
vars(ats_recode), # the variables you want to recode
funs(re = 8 - .) # the function to apply to each variable
)Siempre que hacemos una operación como esta, es bueno verificar que realmente funcionó correctamente. Es fácil cometer errores en la codificación, por lo que es importante verificar tu trabajo lo mejor que puedas.
Podemos seleccionar rápidamente un par de columnas sin procesar y recodificadas de nuestros datos y asegurarnos de que las cosas parecen haber ido de acuerdo al plan:
attitudeDataNoNA %>%
select(
ats2,
ats2_re,
ats4,
ats4_re
)## # A tibble: 141 x 4
## ats2 ats2_re ats4 ats4_re
## <dbl> <dbl> <dbl> <dbl>
## 1 1 7 2 6
## 2 5 3 5 3
## 3 5 3 5 3
## 4 2 6 2 6
## 5 7 1 7 1
## 6 5 3 3 5
## 7 5 3 3 5
## 8 4 4 4 4
## 9 2 6 5 3
## 10 2 6 3 5
## # … with 131 more rowsAsegurémonos también de que no haya respuestas fuera de la escala 1-7 que esperamos, y asegurémonos de que nadie especificó un año fuera del rango 1-4.
attitudeDataNoNA %>%
summarise_at(
vars(ats1:ats28_re),
funs(min, max)
)## # A tibble: 1 x 86
## ats1_min ats2_min ats3_min ats4_min ats5_min ats6_min
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1 2 1 2 1
## # … with 80 more variables: ats7_min <dbl>, ats8_min <dbl>,
## # ats9_min <dbl>, ats10_min <dbl>, ats11_min <dbl>,
## # ats12_min <dbl>, ats13_min <dbl>, ats14_min <dbl>,
## # ats15_min <dbl>, ats16_min <dbl>, ats17_min <dbl>,
## # ats18_min <dbl>, ats19_min <dbl>, ats20_min <dbl>,
## # ats21_min <dbl>, ats22_min <dbl>, ats23_min <dbl>,
## # ats24_min <dbl>, ats25_min <dbl>, ats26_min <dbl>,
## # ats27_min <dbl>, ats28_min <dbl>, ats29_min <dbl>,
## # ats2_re_min <dbl>, ats4_re_min <dbl>,
## # ats6_re_min <dbl>, ats7_re_min <dbl>,
## # ats10_re_min <dbl>, ats12_re_min <dbl>,
## # ats14_re_min <dbl>, ats15_re_min <dbl>,
## # ats16_re_min <dbl>, ats18_re_min <dbl>,
## # ats20_re_min <dbl>, ats25_re_min <dbl>,
## # ats27_re_min <dbl>, ats28_re_min <dbl>, ats1_max <dbl>,
## # ats2_max <dbl>, ats3_max <dbl>, ats4_max <dbl>,
## # ats5_max <dbl>, ats6_max <dbl>, ats7_max <dbl>,
## # ats8_max <dbl>, ats9_max <dbl>, ats10_max <dbl>,
## # ats11_max <dbl>, ats12_max <dbl>, ats13_max <dbl>,
## # ats14_max <dbl>, ats15_max <dbl>, ats16_max <dbl>,
## # ats17_max <dbl>, ats18_max <dbl>, ats19_max <dbl>,
## # ats20_max <dbl>, ats21_max <dbl>, ats22_max <dbl>,
## # ats23_max <dbl>, ats24_max <dbl>, ats25_max <dbl>,
## # ats26_max <dbl>, ats27_max <dbl>, ats28_max <dbl>,
## # ats29_max <dbl>, ats2_re_max <dbl>, ats4_re_max <dbl>,
## # ats6_re_max <dbl>, ats7_re_max <dbl>,
## # ats10_re_max <dbl>, ats12_re_max <dbl>,
## # ats14_re_max <dbl>, ats15_re_max <dbl>,
## # ats16_re_max <dbl>, ats18_re_max <dbl>,
## # ats20_re_max <dbl>, ats25_re_max <dbl>,
## # ats27_re_max <dbl>, ats28_re_max <dbl>attitudeDataNoNA %>%
summarise_at(
vars(Year),
funs(min, max)
)## # A tibble: 1 x 2
## min max
## <dbl> <dbl>
## 1 1 45.7.1.3 Diferentes formatos de datos
En ocasiones necesitamos reformatear nuestros datos para analizarlos o visualizarlos de una manera específica. Dos funciones tidyverse, recopilar () y spread (), nos ayudan a hacer esto.
Por ejemplo, digamos que queremos examinar la distribución de las respuestas en bruto a cada uno de los elementos ATS (es decir, un histograma). En este caso, necesitaríamos que nuestro eje x fuera una sola columna de las respuestas en todos los ítems de ATS. Sin embargo, actualmente las respuestas para cada ítem se almacenan en 29 columnas diferentes.
Esto significa que necesitamos crear una nueva versión de este conjunto de datos. Contará con cuatro columnas: - ID - Año - Pregunta (para cada uno de los ítems ATS) - ResponseRaw (para la respuesta en bruto a cada uno de los ítems ATS)
Así, queremos cambiar el formato del conjunto de datos de ser “ancho” a ser “largo”.
Cambiamos el formato a “wide” usando la función de recopilar ().
() toma una serie de variables y las reforma en dos variables: una que contiene los valores de las variables, y otra llamada la “clave” que nos dice de qué variable proviene el valor. En este caso, queremos que reformatee los datos para que cada respuesta a una pregunta ATS esté en una fila separada y la columna clave nos indique a qué pregunta ATS corresponde. ¡Es mucho mejor ver esto en la práctica que explicar con palabras!
attitudeData_long <-
attitudeDataNoNA %>%
select(-ats_recode) %>% #remove the raw variables that you recoded
gather(
key = question, # key refers to the new variable containing the question number
value = response, # value refers to the new response variable
-ID, -Year, -StatsBefore #the only variables we DON'T want to gather
)
attitudeData_long %>%
slice(1:20)## # A tibble: 20 x 5
## ID Year StatsBefore question response
## <chr> <dbl> <chr> <chr> <dbl>
## 1 1 3 Yes ats1 6
## 2 2 4 No ats1 4
## 3 3 2 No ats1 6
## 4 4 1 Yes ats1 3
## 5 5 2 No ats1 7
## 6 6 3 No ats1 4
## 7 7 4 Yes ats1 6
## 8 8 2 Yes ats1 5
## 9 9 2 Yes ats1 7
## 10 10 2 Yes ats1 5
## 11 11 4 No ats1 5
## 12 12 2 No ats1 4
## 13 13 3 Yes ats1 2
## 14 14 1 Yes ats1 6
## 15 15 2 No ats1 7
## 16 16 4 No ats1 7
## 17 17 2 No ats1 7
## 18 18 2 No ats1 6
## 19 19 1 No ats1 6
## 20 20 1 No ats1 3glimpse(attitudeData_long)## Observations: 4,089
## Variables: 5
## $ ID <chr> "1", "2", "3", "4", "5", "6", "7", "8…
## $ Year <dbl> 3, 4, 2, 1, 2, 3, 4, 2, 2, 2, 4, 2, 3…
## $ StatsBefore <chr> "Yes", "No", "No", "Yes", "No", "No",…
## $ question <chr> "ats1", "ats1", "ats1", "ats1", "ats1…
## $ response <dbl> 6, 4, 6, 3, 7, 4, 6, 5, 7, 5, 5, 4, 2…Digamos que ahora queríamos deshacer la recopilación () y devolver nuestro conjunto de datos a formato amplio. Para ello, usaríamos la función spread ().
attitudeData_wide <-
attitudeData_long %>%
spread(
key = question, #key refers to the variable indicating which question each response belongs to
value = response
)
attitudeData_wide %>%
slice(1:20)## # A tibble: 20 x 32
## ID Year StatsBefore ats1 ats10_re ats11 ats12_re
## <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1 3 Yes 6 6 6 6
## 2 10 2 Yes 5 5 3 4
## 3 100 4 Yes 5 6 4 2
## 4 101 2 No 4 7 2 4
## 5 102 3 Yes 5 6 5 6
## 6 103 2 No 6 7 5 7
## 7 104 2 Yes 6 5 5 3
## 8 105 3 No 6 6 5 6
## 9 106 1 No 4 4 4 4
## 10 107 2 No 1 2 1 1
## 11 108 2 No 7 7 7 7
## 12 109 2 No 4 4 4 6
## 13 11 4 No 5 5 3 4
## 14 110 3 No 5 7 4 4
## 15 111 2 No 6 6 6 3
## 16 112 3 No 6 7 5 7
## 17 114 2 No 5 4 4 3
## 18 115 3 No 5 7 5 1
## 19 116 3 No 5 6 5 5
## 20 118 2 No 6 6 6 1
## # … with 25 more variables: ats13 <dbl>, ats14_re <dbl>,
## # ats15_re <dbl>, ats16_re <dbl>, ats17 <dbl>,
## # ats18_re <dbl>, ats19 <dbl>, ats2_re <dbl>,
## # ats20_re <dbl>, ats21 <dbl>, ats22 <dbl>, ats23 <dbl>,
## # ats24 <dbl>, ats25_re <dbl>, ats26 <dbl>,
## # ats27_re <dbl>, ats28_re <dbl>, ats29 <dbl>,
## # ats3 <dbl>, ats4_re <dbl>, ats5 <dbl>, ats6_re <dbl>,
## # ats7_re <dbl>, ats8 <dbl>, ats9 <dbl>Ahora que hemos creado una versión “larga” de nuestros datos, están en el formato adecuado para crear la trama. Usaremos la función tidyverse ggplot () para crear nuestro histograma con geom_histograma.
attitudeData_long %>%
ggplot(aes(x = response)) +
geom_histogram(binwidth = 0.5) +
scale_x_continuous(breaks = seq.int(1, 7, 1))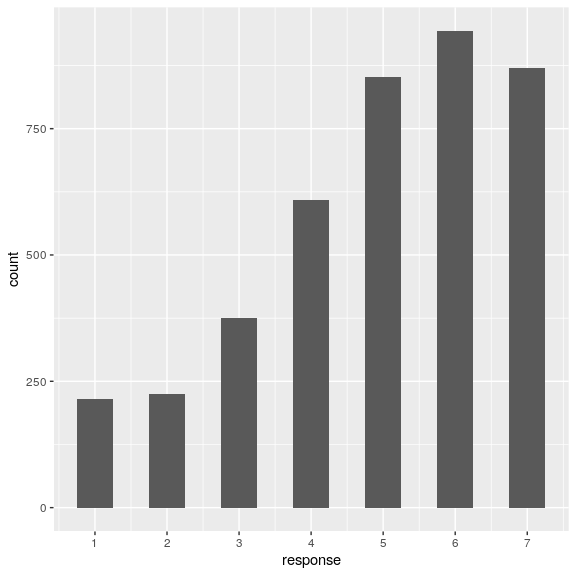
Parece que las respuestas fueron bastante positivas en general.
También podemos agregar las respuestas de cada participante a cada pregunta durante cada año de su estudio en Stanford para examinar la distribución de las respuestas medias de ATS entre las personas por año.
Usaremos las funciones group_by () y summary () para agregar las respuestas.
attitudeData_agg <-
attitudeData_long %>%
group_by(ID, Year) %>%
summarize(
mean_response = mean(response)
)
attitudeData_agg## # A tibble: 141 x 3
## # Groups: ID [141]
## ID Year mean_response
## <chr> <dbl> <dbl>
## 1 1 3 6
## 2 10 2 4.66
## 3 100 4 5.03
## 4 101 2 5.10
## 5 102 3 4.66
## 6 103 2 5.55
## 7 104 2 4.31
## 8 105 3 5.10
## 9 106 1 4.21
## 10 107 2 2.45
## # … with 131 more rowsPrimero usemos el argumento geom_density en ggplot () para ver las respuestas medias entre las personas, ignorando el año de respuesta. El argrumento de densidad es como un histograma pero suaviza un poco las cosas.
attitudeData_agg %>%
ggplot(aes(mean_response)) +
geom_density()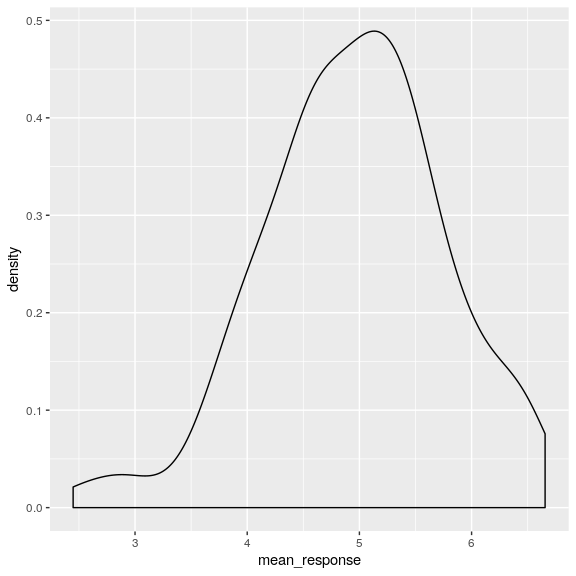
Ahora también podemos mirar la distribución para cada año.
attitudeData_agg %>%
ggplot(aes(mean_response, color = factor(Year))) +
geom_density()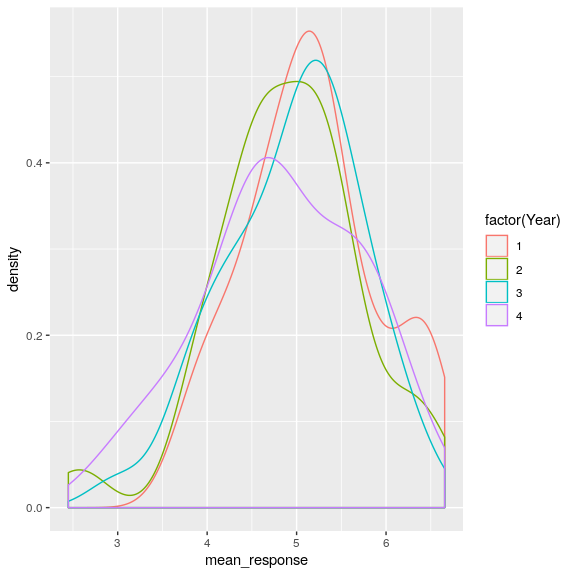
O mira las tendencias en las respuestas a lo largo de los años.
attitudeData_agg %>%
group_by(Year) %>%
summarise(
mean_response = mean(mean_response)
) %>%
ggplot(aes(Year, mean_response)) +
geom_line()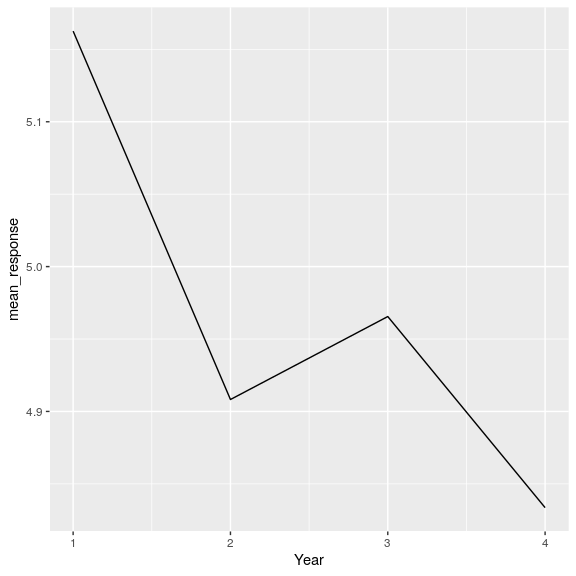
Esto parece una caída precipitada, pero ¿cómo podría ser engañosa?