
1: Datos e Información
- Page ID
- 88160

Datos e Información
David DiBiase
1.1. Visión general
Cuando empecé a escribir este texto en 1997, mi oficina estaba al otro lado de la calle (y, afortunadamente, a favor del viento) de la central eléctrica de Penn State. La energía utilizada para calentar y enfriar mi oficina todavía se produce allí quemando carbón extraído de las crestas cercanas. La combustión transforma la energía potencial almacenada en el carbón en electricidad, lo que resuelve el problema de una oficina que de otro modo estaría demasiado fría o demasiado caliente. Desafortunadamente, la propia solución causa otro problema, a saber, las emisiones de dióxido de carbono y otras sustancias más nocivas a la atmósfera. Existen medios más limpios para generar electricidad, por supuesto, pero ellos también implican transformar la energía de una forma a otra. Y los métodos más limpios cuestan más de lo que la mayoría de nosotros estamos dispuestos o capaces de pagar.
Me parece que una central eléctrica a carbón es una analogía bastante buena para un sistema de información geográfica. Para el caso, el SIG es comparable a cualquier fábrica o máquina que transforme una materia prima en algo más valioso. Los datos son molienda para el molino GIS. El SIG es como la maquinaria que transforma los datos en la mercancía, la información, que se necesita para resolver problemas o crear oportunidades. Y los problemas que el propio proceso de fabricación crea incluyen incertidumbres resultantes de imperfecciones en los datos, mal uso intencional o no intencional de la maquinaria, y cuestiones éticas relacionadas con para qué se utiliza la información, y quién tiene acceso a ella.
Este texto explora la naturaleza de la información geográfica. Estudiar la naturaleza de algo es investigar sus características y cualidades esenciales. Para comprender la naturaleza de la energía producida en una central eléctrica de carbón, se deben estudiar las propiedades, morfología y distribución geográfica del carbón. Por el mismo razonamiento creo que un buen enfoque para entender la información que produce el SIG es investigar las propiedades de los datos geográficos y las tecnologías e instituciones que los producen.
Objetivos
El objetivo del Capítulo 1 es situar los SIG en una empresa más grande conocida como Ciencia y Tecnología de la Información Geográfica (GIS&T), y en lo que el Departamento de Trabajo de Estados Unidos llama la “industria geoespacial”. En particular, los alumnos que completen exitosamente el Capítulo 1 deberán ser capaces de:
- Definir un sistema de información geográfica;
- Reconocer y nombrar las operaciones básicas de bases de datos a partir de descripciones
- Reconocer y nombrar enfoques básicos de representación geográfica a partir de descripciones verbales;
- Identificar y explicar al menos tres propiedades distintivas de los datos geográficos; y
- Describa los tipos de preguntas que SIG puede ayudar a responder.
1.2. Lista de comprobación
La siguiente lista de verificación es para estudiantes de Penn State que están registrados para clases en las que se les ha asignado este texto, así como cuestionarios y proyectos asociados en el sistema de gestión de cursos ANGEL. Puede resultarle útil imprimir primero esta página para que pueda seguir las instrucciones.
Lista de verificación del Capítulo 1 (solo para estudiantes registrados)
| Paso | Actividad | Acceso/Direcciones |
|---|---|---|
| 1 | Leer Capítulo 1 | Esta es la segunda página del Capítulo 1. Haga clic en los enlaces en la parte inferior de la página para continuar o para volver a la página anterior, o para ir a la parte superior del capítulo. También puedes navegar por el texto a través de los enlaces del menú del GEOG 482 de la izquierda. |
| 2 | Envíe cuestionarios a medida que los encuentre en el capítulo. Las pancartas azules denotan cuestionarios de práctica que no están calificados. Banderas rojas señalan cuestionarios graduados. (Tenga en cuenta que el Capítulo 1 no incluye un cuestionario calificado). | Ir a ANGEL > [la sección de tu curso] > Pestaña Lecciones > Carpeta Capítulo 1 > [quiz] |
| 3 | Realiza actividades de “Prueba esto” a medida que las encuentres en el capítulo. Las actividades de “Prueba esto” no están calificadas. | Se proporcionan instrucciones para cada actividad. |
| 4 | Leer comentarios y preguntas publicadas por compañeros de estudios. Agrega comentarios y preguntas propias, si las hubiere. | Los comentarios y preguntas pueden ser publicados en cualquier página del texto, o en un foro de discusión específico del Capítulo en ANGEL. |
1.3. Datos
“Después de más de 30 años, seguimos enfrentándonos al mismo gran reto al que siempre han enfrentado los profesionales del SIG: Debes tener buenos datos. Y los buenos datos son caros y difíciles de crear”. (Wilson, 2001, p. 54)
Los datos consisten en símbolos que representan mediciones de fenómenos. Las personas crean y estudian datos como un medio para ayudar a comprender cómo funcionan los sistemas naturales y sociales. Dichos sistemas pueden ser difíciles de estudiar porque están formados por muchos fenómenos interactuantes que a menudo son difíciles de observar directamente, y porque tienden a cambiar con el tiempo. Intentamos hacer que los sistemas y fenómenos sean más fáciles de estudiar midiendo sus características en ciertos momentos. Porque no es práctico medirlo todo, en todas partes, en todo momento, medimos selectivamente. La precisión con la que los datos reflejan los fenómenos que representan depende de cómo, cuándo, dónde y qué aspectos de los fenómenos se midieron. Todas las mediciones, sin embargo, contienen cierta cantidad de error.
Las mediciones de las ubicaciones y características de los fenómenos se pueden representar con varios tipos diferentes de símbolos. Por ejemplo, las imágenes de la superficie terrestre, incluyendo fotografías y mapas, están compuestas por símbolos gráficos. Las descripciones verbales de los límites de propiedad se registran en escrituras utilizando símbolos alfanuméricos. Las ubicaciones determinadas por los sistemas de posicionamiento satelital se reportan como pares de números llamados coordenadas. Como probablemente sepa, todos estos diferentes tipos de datos (imágenes, palabras y números) se pueden representar en computadoras en forma digital. Obviamente, los datos digitales pueden almacenarse, transmitirse y procesarse de manera mucho más eficiente que sus homólogos físicos que se imprimen en papel. Estas ventajas sentaron las bases para el desarrollo y la adopción generalizada de SIG.
1.4. Información
La información son datos que han sido seleccionados o creados en respuesta a una pregunta. Por ejemplo, la ubicación de un edificio o una ruta son datos, hasta que sean necesarios para despachar una ambulancia en respuesta a una emergencia. Cuando se utiliza para informar a quienes necesitan saber “¿dónde está la emergencia y cuál es la ruta más rápida entre aquí y allá? ,” los datos se transforman en información. La transformación implica la capacidad de hacer la pregunta correcta y la capacidad de recuperar datos existentes, o generar nuevos datos a partir de los antiguos, que ayudan a las personas a responder la pregunta. Cuanto más compleja es la pregunta y más ubicaciones involucradas, más difícil se vuelve producir información oportuna solo con mapas en papel.
Curiosamente, el valor potencial de los datos no se pierde necesariamente cuando se utilizan. Los datos pueden transformarse en información una y otra vez, siempre que los datos se mantengan actualizados. Dado el rápido aumento de la accesibilidad de las computadoras y las redes de comunicaciones en Estados Unidos y en el extranjero, no es sorprendente que la información se haya convertido en una mercancía, y que la capacidad de producirla se haya convertido en una industria de gran crecimiento.
1.5. Sistemas de Información
Los sistemas de información son herramientas informáticas que ayudan a las personas a transformar los datos en información.
Como usted sabe, muchos de los problemas y oportunidades que enfrentan las agencias gubernamentales, negocios y otras organizaciones son tan complejos, e involucran tantas ubicaciones, que las organizaciones necesitan asistencia para crear información útil y oportuna. Para eso están los sistemas de información.
Permítame un ejemplo fantasioso. Supongamos que ha lanzado un nuevo negocio que fabrica segadoras de césped con energía solar. Estás planeando una campaña de correo directo para llevar este nuevo producto revolucionario a la atención de los posibles compradores. Pero como es una pequeña empresa, no puedes permitirte patrocinar comerciales de televisión de costa a costa, o enviar folletos por correo a más de 100 millones de hogares estadounidenses. En cambio, planea dirigirse a los clientes más probables: aquellos que son conscientes del medio ambiente, tienen ingresos familiares más altos que el promedio y que viven en áreas donde hay suficiente agua y sol para apoyar el césped y la energía solar.
Afortunadamente, hay muchos datos disponibles para ayudarte a definir tu lista de correo. Los ingresos de los hogares se reportan rutinariamente a los bancos y otras instituciones financieras cuando las familias solicitan hipotecas, préstamos y tarjetas de crédito. Los gustos personales relacionados con temas como el medio ambiente se reflejan en comportamientos como las suscripciones a revistas y las compras con tarjeta de crédito. Empresas como Claritas amontonan esos datos y los transforman en información creando “segmentos de estilo de vida”, categorías de hogares que tienen ingresos y gustos similares. Su compañía de cortadora de césped solar puede comprar información del segmento de estilo de vida por código postal de 5 dígitos, o incluso por códigos ZIP+4, que designan hogares individuales.
Es asombroso cómo empresas como Claritas pueden crear información valiosa a partir de los millones y millones de transacciones que se registran todos los días. Sus productos son posibles por el hecho de que los datos originales existen en forma digital, y porque las empresas han desarrollado sistemas de información que les permiten transformar los datos en información que empresas como la suya valoran. El hecho de que los productos de información de estilo de vida a menudo se entreguen por áreas geográficas, como los códigos postales, habla del atractivo de los sistemas de información geográfica.
PRUEBA ESTO
Prueba la demo de lo que Claritas solía llamar la herramienta “Estás donde vives”. The Nielson Company ha adquirido Claritas y la herramienta ahora se llama “MyBestSegments”. Dirija su navegador a la página Mis mejores segmentos. Haga clic en el botón etiquetado como “Búsqueda de código postal”.
Ingresa tu código postal y luego elige un sistema de segmentación. ¿Los segmentos de estilo de vida, que figuran a la izquierda, parecen precisos para tu comunidad? Si no vives en Estados Unidos, prueba el código postal de Penn State, 16802.
¿La segmentación del mercado coincide con tus expectativas? Los estudiantes registrados son bienvenidos a publicar comentarios directamente en esta página.
1.6. Bases de datos, cartografía y SIG
Uno de nuestros objetivos en este primer capítulo es poder definir un sistema de información geográfica. Aquí hay una definición tentativa: Un SIG es una herramienta basada en computadora que se utiliza para ayudar a las personas a transformar datos geográficos en información geográfica.
La definición implica que un SIG es de alguna manera diferente de otros sistemas de información, y que los datos geográficos son diferentes de los datos no geográficos. Consideremos las diferencias a continuación.
1.7. Sistemas de Gestión de Bases de
Claritas y empresas similares utilizan sistemas de gestión de bases de datos (DBMS) para crear los “segmentos de estilo de vida” a los que me referí en la sección anterior. Los conceptos básicos de bases de datos son importantes ya que SIG incorpora gran parte de la funcionalidad del DBMS
Los datos digitales se almacenan en computadoras como archivos. A menudo, los datos están dispuestos en forma tabular. Por esta razón, a los archivos de datos se les suele llamar tablas. Una base de datos es una colección de tablas. Las empresas y agencias gubernamentales que atienden a grandes clientes, como empresas de telecomunicaciones, aerolíneas, firmas de tarjetas de crédito y bancos, confían en extensas bases de datos para sus operaciones de facturación, nómina, inventario y mercadotecnia. Los sistemas de gestión de bases de datos son sistemas de información que las personas utilizan para almacenar, actualizar y analizar bases de datos no geográficas.
A menudo, los archivos de datos son de forma tabular, compuestos por filas y columnas. Las filas, también conocidas como registros, corresponden con entidades individuales, como cuentas de clientes. Las columnas corresponden con los diversos atributos asociados a cada entidad. Los atributos almacenados en la base de datos de cuentas de una compañía de telecomunicaciones, por ejemplo, podrían incluir nombres de clientes, números de teléfono, direcciones, cargos actuales por llamadas locales, llamadas de larga distancia, impuestos, etc.
Los datos geográficos son un caso especial: los registros corresponden con lugares, no con personas ni con cuentas. Las columnas representan los atributos de los lugares. Los datos de la siguiente tabla, por ejemplo, consisten en registros para los condados de Pensilvania. Las columnas contienen atributos seleccionados de cada condado, incluyendo el código de identificación del condado, nombre y población de 1980.
| Código FIPS | Condado | 1980 Pop |
|---|---|---|
| 42001 | Condado de Adams | 78274 |
| 42003 | Condado de Allegheny | 1336449 |
| 42005 | Condado de Armstrong | 73478 |
| 42007 | Condado de Beaver | 186093 |
| 42009 | Condado de Bedford | 47919 |
| 42011 | Condado de Berks | 336523 |
| 42013 | Condado de Blair | 130542 |
| 42015 | Condado de Bradford | 60967 |
| 42017 | Condado de Bucks | 541174 |
| 42019 | Condado de Butler | 152013 |
| 42021 | Condado de Cambria | 163062 |
| 42023 | Condado de Cameron | 5913 |
| 42025 | Condado de Carbon | 56846 |
| 42027 | Condado de Centro | 124812 |
El contenido de un archivo en una base de datos.
El ejemplo es un archivo muy simple, pero muchas bases de datos de atributos geográficos son de hecho muy grandes (Estados Unidos está compuesto por más de 3,000 condados, casi 50,000 distritos censales, alrededor de 43 mil áreas de código postal de cinco dígitos y muchas decenas de miles más de áreas de código ZIP+4). Las grandes bases de datos consisten no solo en muchos datos, sino también en muchos archivos. A diferencia de una hoja de cálculo, que realiza cálculos solo en datos que están presentes en un solo documento, los sistemas de administración de bases de datos permiten a los usuarios almacenar datos en, y recuperar datos de, muchos archivos separados. Por ejemplo, supongamos que un analista deseara calcular el cambio poblacional para los condados de Pensilvania entre los censos de 1980 y 1990. Lo más probable es que los datos de población de 1990 existieran en un archivo separado, así:
| Código FIPS | 1990 Pop |
|---|---|
| 42001 | 84921 |
| 42003 | 1296037 |
| 42005 | 73872 |
| 42007 | 187009 |
| 42009 | 49322 |
| 42011 | 352353 |
| 42013 | 131450 |
| 42015 | 62352 |
| 42017 | 578715 |
| 42019 | 167732 |
| 42021 | 158500 |
| 42023 | 5745 |
| 42025 | 58783 |
| 42027 | 131489 |
Otro archivo en una base de datos. Un sistema de gestión de bases de datos (DBMS) puede relacionar este archivo con el anterior ilustrado anteriormente porque comparten la lista de atributos llamada “Código FIPS”.
Si dos archivos de datos tienen al menos un atributo común, un DBMS puede combinarlos en un solo archivo nuevo. El atributo común se llama clave. En este ejemplo, la clave fue el código FIPS del condado (FIPS significa Estándar Federal de Procesamiento de Información). El DBMS permite a los usuarios producir nuevos datos así como recuperar datos existentes, como sugiere el nuevo atributo “% Change” en la siguiente tabla.
| FIPS | Condado | 1980 | 1990 | % Cambio |
|---|---|---|---|---|
| 42001 | Adams | 78274 | 84921 | 8.5 |
| 42003 | Allegheny | 1336449 | 1296037 | -3 |
| 42005 | Armstrong | 73478 | 73872 | 0.5 |
| 42007 | Castor | 186093 | 187009 | 0.5 |
| 42009 | Bedford | 47919 | 49322 | 2.9 |
| 42011 | Berks | 336523 | 352353 | 4.7 |
| 42013 | Blair | 130542 | 131450 | 0.7 |
| 42015 | Bradford | 60967 | 62352 | 2.3 |
| 42017 | Bucks | 541174 | 578715 | 6.9 |
| 42019 | Mayordomo | 152013 | 167732 | 10.3 |
| 42021 | Cambria | 163062 | 158500 | -2.8 |
| 42023 | Cameron | 5913 | 5745 | -2.8 |
| 42025 | Carbono | 56846 | 58783 | 3.4 |
| 42027 | Centro | 124812 | 131489 | 5.3 |
Un nuevo archivo producido a partir de los dos archivos anteriores como resultado de dos operaciones de base de datos. Una operación fusionó el contenido de los dos archivos sin redundancia. Una segunda operación produjo un nuevo atributo —”% Change” —dividiendo la diferencia entre “1990 Pop” y “1980 Pop” por “1980 Pop” y expresando el resultado como porcentaje.
Los sistemas de administración de bases de datos son valiosos porque proporcionan medios seguros para almacenar y actualizar datos. Los administradores de bases de datos pueden proteger los archivos para que solo los usuarios autorizados puedan realizar cambios. DBMS proporciona funciones de administración de transacciones que permiten a múltiples usuarios editar la base de datos simultáneamente. Además, DBMS también proporciona medios sofisticados para recuperar datos que cumplan con los criterios especificados por el usuario. En otras palabras, permiten a los usuarios seleccionar datos en respuesta a preguntas particulares. Una pregunta que se dirige a una base de datos a través de un DBMS se llama consulta.
Las consultas de bases de datos incluyen operaciones básicas de conjuntos, incluyendo unión, intersección y diferencia. El producto de una unión de dos o más archivos de datos es un archivo único que incluye todos los registros y atributos, sin redundancia. Una intersección produce un archivo de datos que contiene solo registros presentes en todos los archivos. Una operación de diferencia produce un archivo de datos que elimina los registros que aparecen en ambos archivos originales. (Intente dibujar diagramas de Venn, círculos cruzados que muestran relaciones entre dos o más entidades, para ilustrar las tres operaciones. A continuación, compare su boceto con el ejemplo del diagrama venn.) Todas las operaciones que involucran múltiples archivos de datos se basan en el hecho de que todos los archivos contienen una clave común. La clave permite que el sistema de base de datos relacione los archivos separados. Las bases de datos que contienen numerosos archivos que comparten una o más claves se denominan bases de datos relacionales. Los sistemas de bases de datos que permiten a los usuarios producir información a partir de bases de datos relacionales se denominan sistemas de gestión de bases
Un uso común de las consultas de bases de datos es identificar subconjuntos de registros que cumplan con los criterios establecidos por el usuario. Por ejemplo, una compañía de tarjetas de crédito tal vez desee identificar todas las cuentas vencidas de 30 días o más. Un asesor fiscal del condado puede necesitar enumerar todas las propiedades no evaluadas en los últimos 10 años. O la Oficina del Censo de Estados Unidos tal vez desee identificar todas las direcciones que necesitan ser visitadas por los censistas, ya que los cuestionarios censales no se devolvieron por correo. Los proveedores de software DBMS han adoptado un lenguaje estandarizado llamado SQL (Structured Query Language) para plantear tales consultas.
PRÁCTICA
1.8. Sistemas de Mapeo
SIG (sistemas de información geográfica) surgió de la necesidad de realizar consultas espaciales sobre datos geográficos. Una consulta espacial requiere conocimiento tanto de ubicaciones como de atributos. Por ejemplo, un analista ambiental podría querer saber qué fuentes públicas de agua potable se encuentran a una milla de un derrame conocido de químicos tóxicos. O bien, se podría llamar a un planificador para identificar las parcelas de propiedad ubicadas en áreas que están sujetas a inundaciones. Para acomodar datos geográficos y consultas espaciales, los sistemas de gestión de bases de datos deben integrarse con los sistemas de mapeo. Hasta aproximadamente 1990, la mayoría de los mapas se imprimían a partir de dibujos o grabados hechos a mano. Los datos geográficos producidos por los dibujantes consistieron en marcas gráficas inscritas en papel o película. Hasta el día de hoy, la mayoría de las líneas que aparecen en los mapas topográficos publicados por el Servicio Geológico de Estados Unidos fueron originalmente grabadas a mano. Los topónimos mostrados en los mapas se colocaron con pinzas, una palabra a la vez. No hace falta decir que esos mapas eran caros de crear y de mantenerse actualizados. La informatización del proceso de elaboración de mapas tuvo un atractivo evidente.
Los sistemas CAD de diseño asistido por computadora (CAD) se desarrollaron originalmente para ingenieros, arquitectos y otros profesionales del diseño que necesitaban medios más eficientes para crear y revisar planos precisos de piezas de máquinas, planos de construcción y similares. En la década de 1980, los cartógrafos comenzaron a adoptar CAD en lugar de la redacción tradicional de mapas. Los operadores CAD codifican las ubicaciones y extensiones de carreteras, arroyos, límites y otras entidades mediante mapas de rastreo montados en tablas de dibujo electrónicas, o ingresando clave las coordenadas de ubicación, ángulos y distancias. En lugar de características gráficas, los datos CAD consisten en entidades digitales, cada una de las cuales está compuesta por un conjunto de ubicaciones de puntos. Los cálculos de distancias, áreas y volúmenes se pueden automatizar fácilmente una vez que se digitalizan las características. Desafortunadamente, los sistemas CAD normalmente no codifican datos en formas que admiten consultas espaciales. En 1988, un geógrafo llamado David Cowen ilustró los beneficios y deficiencias del CAD para la toma de decisiones espaciales. Señaló que un sistema CAD sería útil para representar las calles, los límites de las parcelas de propiedad y las huellas de edificios de un subdesarrollo residencial. Un operador CAD podría señalar una parcela en particular y resaltarla con un color o patrón seleccionado. “Sin embargo, un sistema CAD típico”, observó Cowen, “no podía sombrear automáticamente cada parcela en función de los valores de la base de datos de un asesor que contenga información sobre la propiedad, el uso o el valor”. Un sistema CAD sería de uso limitado para alguien que tuviera que tomar decisiones sobre política de uso del suelo o tasación fiscal.
Mapeo de escritorio Una etapa evolutiva en el desarrollo de SIG, los sistemas de mapeo de escritorio como Atlas*GIS combinaron algunas de las capacidades de los sistemas CAD con vínculos rudimentarios entre los datos de ubicación y los datos de atributos. Un usuario del sistema de mapeo de escritorios podría producir un mapa en el que las parcelas de propiedad se coloren automáticamente de acuerdo con varias categorías de valores de propiedad, por ejemplo. Además, si se redefinieran las categorías de valor de propiedad, la apariencia del mapa podría actualizarse automáticamente. Algunos sistemas de mapeo de escritorios incluso admiten consultas simples que permiten a los usuarios recuperar registros de un solo archivo de atributo. La mayoría de las decisiones del mundo real requieren consultas más sofisticadas que involucran múltiples archivos de datos Ahí es donde entra el SIG real.
Sistemas de información geográfica (SIG) Como se indicó anteriormente, los sistemas de información ayudan a los tomadores de decisiones al permitirles transformar datos en información útil. GIS se especializa en ayudar a los usuarios a transformar datos geográficos en información geográfica. David Cowen (1988) definió el SIG como una herramienta de soporte de decisiones que combina las capacidades de manejo de datos de atributos de los sistemas de gestión de bases de datos relacionales con las capacidades de manejo de datos espaciales de los sistemas CAD y de mapeo En particular, SIG permite a los tomadores de decisiones identificar ubicaciones o rutas cuyos atributos coinciden con múltiples criterios, aunque las entidades y atributos puedan estar codificados en muchos archivos de datos diferentes.
Los innovadores en muchos campos, incluidos ingenieros, informáticos, geógrafos y otros, comenzaron a desarrollar mapas digitales y sistemas CAD en las décadas de 1950 y 60. Uno de los primeros desafíos que enfrentaron fue convertir los datos gráficos almacenados en mapas en papel en datos digitales que pudieran ser almacenados y procesados por computadoras digitales. Se desarrollaron varios enfoques diferentes para representar ubicaciones y extensiones en forma digital. Las dos estrategias de representación predominantes se conocen como “vector” y “ráster”.
1.9. Estrategias de Representación para Mapeo
Recordemos que los datos consisten en símbolos que representan mediciones. Los datos geográficos digitales se codifican como símbolos alfanuméricos que representan ubicaciones y atributos de ubicaciones medidas en o cerca de la superficie de la Tierra. Ningún conjunto de datos geográficos representa todas las ubicaciones posibles, por supuesto. La Tierra es demasiado grande, y el número de ubicaciones únicas es demasiado grande. De la misma manera que la opinión pública se mide a través de encuestas, los datos geográficos se construyen midiendo muestras representativas de ubicaciones. Y así como las encuestas de opinión serias se basan en principios sólidos de muestreo estadístico, también los datos geográficos representan la realidad midiendo muestras cuidadosamente elegidas de ubicaciones. Los datos vectoriales y ráster son, en esencia, dos estrategias de muestreo distintas.
El enfoque vectorial implica ubicaciones de muestreo a intervalos a lo largo de entidades lineales (como carreteras), o alrededor del perímetro de entidades de área (como parcelas de propiedad). Cuando están conectados por líneas, los puntos muestreados forman entidades de línea y entidades poligonales que se aproximan a las formas de sus contrapartes del mundo real.
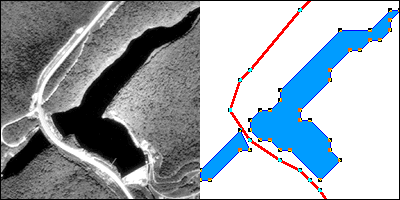
Dos fotogramas (el primero y el último) de una animación que muestra la construcción de una representación vectorial de un embalse y una carretera.
PRUEBA ESTO
Haga clic en el gráfico de arriba para descargar y ver el archivo de animación (vector.avi, 1.6 Mb) en una ventana separada de Microsoft Media Player.
Para ver la misma animación en formato QuickTime (vector.mov, 1.6 Mb), da clic aquí. Requiere el plugin QuickTime, que está disponible de forma gratuita en apple.com.
La fotografía aérea de arriba a la izquierda muestra dos entidades, un embalse y una carretera. El gráfico de arriba a la derecha ilustra cómo las entidades podrían representarse con datos vectoriales. Los cuadrados pequeños son nodos: ubicaciones de puntos especificadas por coordenadas de latitud y longitud. Los segmentos de línea conectan nodos para formar entidades de línea. En este caso, la entidad de línea coloreada en rojo representa la autopista. Las series de segmentos de línea que comienzan y terminan en el mismo nodo forman entidades poligonales. En este caso, dos polígonos (llenos de azul) representan el reservorio.
El modelo de datos vectoriales es consistente con la forma en que los topógrafos miden las ubicaciones a intervalos a medida que atraviesan un límite de propiedad. El software de dibujo asistido por computadora (CAD) utilizado por topógrafos, ingenieros y otros, almacena datos en forma vectorial. Los operadores CAD codifican las ubicaciones y extensiones de las entidades mediante mapas de rastreo montados en tablas de dibujo electrónicas, o ingresando por clave las coordenadas de ubicación, ángulos y distancias. En lugar de características gráficas, los datos CAD consisten en entidades digitales, cada una de las cuales está compuesta por un conjunto de ubicaciones de puntos.
La estrategia vectorial es muy adecuada para mapear entidades con bordes bien definidos, como carreteras o tuberías o parcelas de propiedad. Muchas de las características que se muestran en los mapas en papel, incluidas las curvas de nivel, las rutas de transporte y los límites políticos, se pueden representar de manera efectiva en forma digital utilizando el modelo de datos vectoriales.
El enfoque ráster implica atributos de muestreo a intervalos fijos. Cada muestra representa una celda en una cuadrícula en forma de tablero de ajedrez.
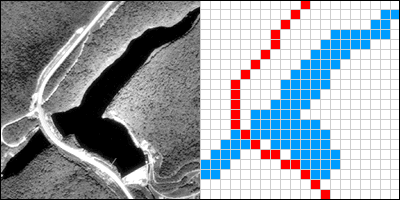
Dos fotogramas (el primero y el último) de una animación que muestra la construcción de una representación ráster de un embalse y una carretera.
PRUEBA ESTO
Haga clic en el gráfico de arriba para descargar y ver el archivo de animación (raster.avi, 0.8 Mb) en una ventana separada de Microsoft Media Player.
Para ver la misma animación en formato QuickTime (raster.mov, 0.6 Mb), da clic aquí. Requiere el plugin QuickTime, que está disponible de forma gratuita en apple.com.
El gráfico anterior ilustra una representación ráster del mismo embalse y carretera como se muestra en la representación vectorial. El área cubierta por la fotografía aérea se ha dividido en una cuadrícula. Cada celda de cuadrícula que se superpone a una de las dos entidades seleccionadas se codifica con un atributo que la asocia con la entidad que representa. Los datos ráster reales no consistirían en una imagen de celdas de cuadrícula rojas y azules, por supuesto; consistirían en una lista de números, un número por cada celda de cuadrícula, representando cada número una entidad. Por ejemplo, las celdas de cuadrícula que representan la carretera podrían codificarse con el número “1" y las celdas de cuadrícula que representan el reservorio podrían codificarse con el número “2”.
La estrategia ráster es una opción inteligente para representar fenómenos que carecen de límites claros, como la elevación del terreno, la vegetación y la precipitación. Los sistemas de imágenes digitales en el aire, que están reemplazando a las cámaras fotográficas como fuentes primarias de datos geográficos detallados, producen datos ráster al escanear la superficie de la Tierra píxel por píxel y fila por fila.
Tanto los enfoques vectoriales como rasterizados logran lo mismo: nos permiten caricaturizar la superficie de la Tierra con un número limitado de ubicaciones. Lo que distingue a ambos son las estrategias de muestreo que encarnan. El enfoque vectorial es como crear una imagen de un paisaje con fragmentos de vidrieras cortadas a varias formas y tamaños. El enfoque ráster, por el contrario, es más como crear un mosaico con mosaicos de tamaño uniforme. Ninguno de los dos es adecuado para todas las aplicaciones, sin embargo. Varias variaciones en los temas vectoriales y ráster están en uso para aplicaciones especializadas, y el desarrollo de nuevos enfoques orientados a objetos está en marcha.
PRÁCTICA
1.10. Análisis Automatizado de Mapa
Como mencioné anteriormente, la motivación original para desarrollar sistemas de mapeo por computadora fue automatizar el proceso de creación de mapas. La informatización no solo ha hecho que la elaboración de mapas sea más eficiente, también ha eliminado algunas de las barreras tecnológicas que solían impedir que las personas hicieran mapas por sí mismas. Lo que solía ser una artesanía arcana practicada por algunos especialistas se ha convertido en una aplicación “en la nube” disponible para cualquier usuario de computadoras en red. Cuando comencé a escribir este curso por primera vez en 1997, mi ejemplo fue la extensión de mapeo incluida en Microsoft Excel 97, lo que hizo que crear un mapa simple fuera tan fácil como crear una gráfica. Diez años después, ¿quién no ha usado Google Maps o MapQuest?
Por mucho que la informatización haya cambiado la forma en que se hacen los mapas, ha tenido un impacto aún mayor en cómo se pueden usar los mapas. Los cálculos de distancia, dirección y área, por ejemplo, son operaciones tediosas y propensas a errores con mapas en papel. Dado un mapa digital, dichos cálculos pueden automatizarse fácilmente. Quienes están familiarizados con los sistemas CAD lo saben por experiencia de primera mano. Los ingenieros de carreteras, por ejemplo, confían en imágenes aéreas y sistemas de mapeo digital para estimar los costos del proyecto calculando los volúmenes de roca que deben excavarse en las laderas y llenarse en valles.
La capacidad de automatizar tareas analíticas no solo alivia el tedio y reduce los errores. También nos permite realizar tareas que de otro modo parecerían poco prácticas. Considere, por ejemplo, si se le pidió que trazara en un mapa una zona de amortiguamiento de 100 metros de ancho que rodeara un arroyo protegido. Si todo lo que tuvieras que trabajar era un mapa de papel, una regla y un lápiz, podrías tener un trabajo largo en tus manos. Se podrían trazar líneas escaladas para representar 100 metros, perpendiculares al río en ambos lados, a intervalos que varían en frecuencia con la sinuosidad del arroyo. Entonces podrías trazar un perímetro que conecte los puntos finales de las líneas perpendiculares. Si tu tarea era crear cientos de esas zonas de amortiguamiento, podrías concluir que la automatización es una necesidad, no solo un lujo.
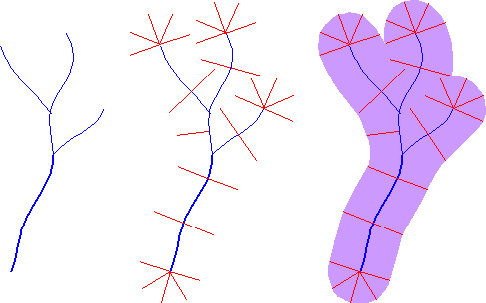
Rodeando una corriente protegida con un polígono de influencia.
Algunas tareas se pueden implementar igualmente bien en sistemas de mapeo orientados a vectores o ráster. Otras tareas se adaptan mejor a una estrategia de representación u otra. El cálculo de la pendiente, por ejemplo, o del gradiente, la dirección de la pendiente máxima a lo largo de una superficie, se logra de manera más eficiente con los datos ráster. La pendiente de una celda de cuadrícula ráster se puede calcular comparando su elevación con las elevaciones de las ocho celdas que la rodean. Los datos ráster también se prefieren para un procedimiento llamado análisis de cuenca visual que predice qué partes de un paisaje estarán a la vista, u ocultas de la vista, desde una perspectiva particular.
Algunos sistemas de mapeo proporcionan formas de analizar datos de atributos así como datos de ubicación. Por ejemplo, la extensión de mapeo de Excel que mencioné anteriormente vincula las capacidades de visualización de datos geográficos de un sistema de mapeo con las capacidades de análisis de datos de una hoja de cálculo. Como probablemente sepa, las hojas de cálculo como Excel permiten a los usuarios realizar cálculos en campos individuales, columnas o archivos completos. Un valor cambiado en un campo cambia automáticamente los valores en toda la hoja de cálculo. Se admiten funciones aritméticas, financieras, estadísticas e incluso ciertas bases de datos. Pero por muy útiles que sean las hojas de cálculo, no fueron diseñadas para proporcionar medios seguros de administrar y analizar grandes bases de datos que constan de muchos archivos relacionados, cada uno de los cuales es responsabilidad de una parte diferente de una organización. Una hoja de cálculo no es un DBMS. Y de la misma manera, un sistema de mapeo no es un SIG.
1.11. Sistemas de Información Geográfica
La discusión anterior me lleva a revisar mi definición de trabajo:
Como mencioné anteriormente, un geógrafo llamado David Cowen definió el SIG como una herramienta de soporte de decisiones que combina las capacidades de un sistema de gestión de bases de datos relacionales con las capacidades de un sistema de mapeo (1988). Cowen citó un estudio anterior de William Carstensen (1986), quien buscó establecer criterios por los cuales los gobiernos locales pudieran elegir entre los productos SIG competidores. Carstensen eligió la selección de sitios como ejemplo del tipo de tarea compleja que muchas organizaciones buscan lograr con SIG. Dada la base de datos necesaria, aconsejó a los gobiernos locales esperar que un SIG completamente funcional sea capaz de identificar parcelas de propiedad que son:
- Al menos cinco acres de tamaño;
- Vacante o en venta;
- Comercial zonificado;
- No sujeto a inundaciones;
- Ubicada a no más de una milla de una carretera de servicio pesado; y
- Situada en terreno cuya pendiente máxima es menor al diez por ciento.
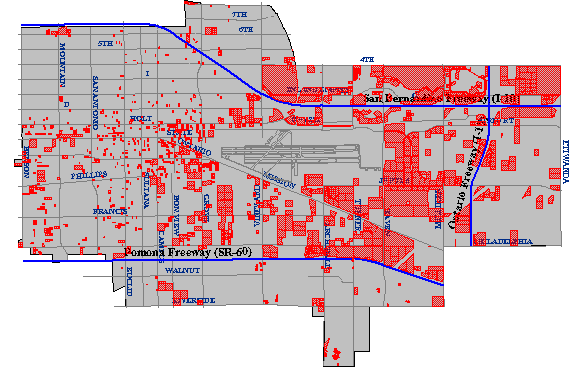
El primer criterio, identificar parcelas de cinco acres o más de tamaño, podría requerir dos operaciones. Como se describió anteriormente, un sistema de mapeo debería poder calcular automáticamente el área de una parcela. Una vez que se calcula el área y se agrega como un nuevo atributo a la base de datos, una consulta de base de datos ordinaria podría producir una lista de parcelas que satisfagan el criterio de tamaño. Las parcelas de la lista también podrían resaltarse en un mapa, como en el siguiente ejemplo.
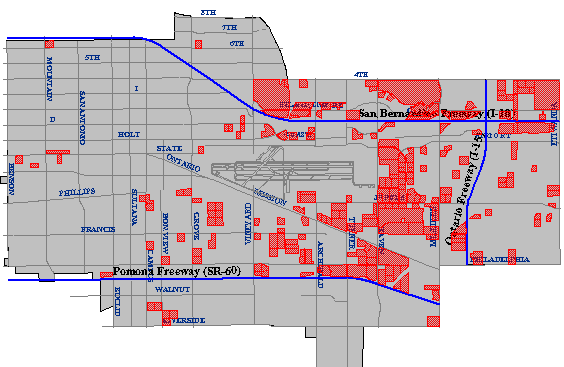
El resultado cartográfico de una consulta de base de datos que identifica todas las parcelas de propiedad mayores o iguales a cinco acres de tamaño. (Ciudad de Ontario, CA, Departamento de SIG. Usado con permiso.)
El estado de propiedad de parcelas individuales sería un atributo de una base de datos de propiedad mantenida por una oficina local de asesores fiscales. Las parcelas cuyo valor de atributo de estado de propiedad coincidiera con los criterios “vacante” o “en venta” podrían identificarse a través de otra consulta de base de datos ordinaria
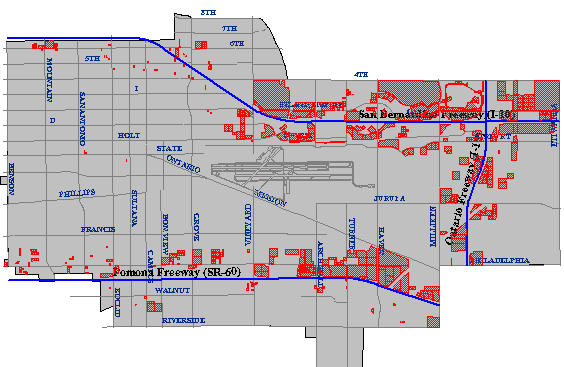
El resultado cartográfico de una operación de intersección espacial (o superposición de mapa) que identifica todas las parcelas de propiedad divididas en zonas para desarrollo comercial (C-1). (Ciudad de Ontario, CA, Departamento de SIG. Usado con permiso.)
El tercer criterio de Carstensen fue determinar qué parcelas se ubicaron dentro de áreas zonificadas para desarrollo comercial. Esto sería sencillo si se incluyeran los usos autorizados del suelo como atributo en la base de datos de parcelas de propiedad de la comunidad. Es poco probable que así sea, sin embargo, ya que la zonificación y la tributación son responsabilidades de diferentes organismos. Normalmente, las parcelas y las zonas de uso del suelo existen como mapas en papel separados. Si los mapas se prepararan a la misma escala, y si contabilizaran la forma de la Tierra de la misma manera, entonces podrían superponerse uno sobre otro sobre una mesa de luz. Si los mapas dejan pasar suficiente luz, se podrían identificar parcelas ubicadas dentro de zonas comerciales.
El enfoque SIG para una tarea como esta comienza digitalizando los mapas en papel y produciendo archivos de datos de atributos correspondientes. Cada mapa digital y archivo de datos de atributos se almacena en el SIG por separado, como capas de mapa separadas. Entonces se utilizaría un SIG completamente funcional para realizar una intersección espacial que es análoga a la superposición de los mapas en papel. La intersección espacial, también conocida como superposición de mapa, es una de las capacidades definitorias del SIG.
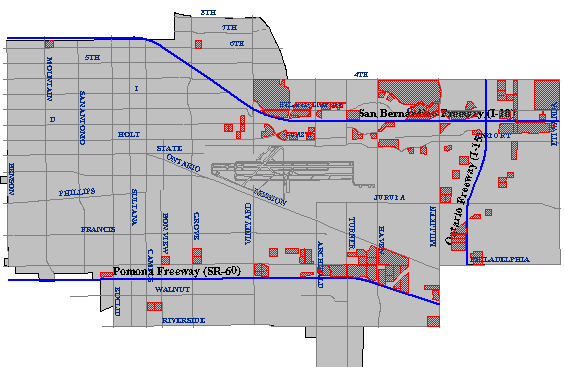
El resultado cartográfico de una operación de zona de influencia que identifica todas las parcelas de propiedad ubicadas dentro de una distancia especificada de un tipo de carretera especificado. (Ciudad de Ontario, CA, Departamento de SIG. Usado con permiso.)
Otro de los criterios de Carstensen fue identificar paquetes ubicados dentro de una milla de una carretera de servicio pesado. Tal tarea requiere un mapa digital y atributos asociados producidos de tal manera que permitan diferenciar las carreteras de servicio pesado de otras entidades geográficas. Una vez que la base de datos necesaria está en su lugar, se puede utilizar una operación de zona de influencia para crear una entidad poligonal cuyo perímetro rodea todas las entidades de “carretera de servicio pesado” a la distancia especificada. Luego se realiza una intersección espacial, aislando las parcelas dentro del búfer de las que están fuera del búfer.
Para producir una lista final de parcelas que cumplan con todos los criterios de selección de sitios, el analista SIG podría realizar una operación de intersección que cree un nuevo archivo que contenga solo aquellos registros que están presentes en todos los demás resultados intermedios.
El resultado cartográfico de la intersección de las tres figuras anteriores. Solo las parcelas que se muestran en este mapa satisfacen todos los criterios de selección del sitio. (Ciudad de Ontario, CA, Departamento de SIG. Usado con permiso.)
Creé los mapas mostrados arriba en 1998 usando el Servidor Web de Información Geográfica de la Ciudad de Ontario, California. Aunque ya no es compatible, la ciudad de Ontario fue una de las primeras de su tipo en proporcionar gran parte de la funcionalidad requerida para realizar un análisis de idoneidad del sitio en línea. Hoy en día, muchos gobiernos locales ofrecen servicios similares de mapas de Internet a contribuyentes actuales y potenciales.
PRUEBA ESTO
Encuentre una utilidad de selección de sitios en línea similar a la proporcionada anteriormente por la ciudad de Ontario. Los estudiantes registrados de Penn State pueden publicar un comentario en esta página describiendo la funcionalidad del sitio y comparándolo con las capacidades del ejemplo ilustrado anteriormente.
1.12. Ciencia y Tecnología de la Información Geográfica
En lo que va de este capítulo he tratado de darle sentido a los SIG en relación con varias tecnologías de la información, incluyendo la gestión de bases de datos, el diseño asistido por computadora y los sistemas de mapeo. En este punto me gustaría ampliar la discusión para considerar el SIG como un elemento en un campo de estudio mucho más amplio llamado “Ciencia y Tecnología de la Información Geográfica” (GIS&T). Como se muestra en la siguiente ilustración, GIS&T abarca tres subcampos que incluyen:
- Geographic Information Science, la empresa de investigación multidisciplinaria que aborda la naturaleza de la información geográfica y la aplicación de las tecnologías geoespaciales a cuestiones científicas básicas;
- Tecnología Geoespacial, el conjunto especializado de tecnologías de la información que apoyan la adquisición, gestión, análisis y visualización de datos georeferenciados, incluyendo el Sistema Mundial de Navegación por Satélite (GPS y otros), sistemas de teledetección satelital, aerotransportados y a bordo; y SIG y herramientas de software de análisis de imágenes; y
- Aplicaciones de GIS&T, los usos cada vez más diversos de la tecnología geoespacial en el gobierno, la industria y la academia. Este es el subcampo en el que trabajan la mayoría de los profesionales del SIG.
Las flechas en el siguiente diagrama reflejan las relaciones entre los tres subcampos, así como con muchos otros campos, incluyendo Geografía, Arquitectura del Paisaje, Ciencias de la Computación, Estadística, Ingeniería y muchos otros. Cada uno de estos campos ha influido, y algunos han sido influenciados por, el desarrollo de GIS&T, es importante señalar que estos campos y subcampos no se corresponden perfectamente con profesiones como analista de SIG, fotogrametrista o agrimensor. Más bien, GIS&T es un nexo de profesiones superpuestas que difieren en antecedentes, lealtades disciplinarias y estatus regulatorio.
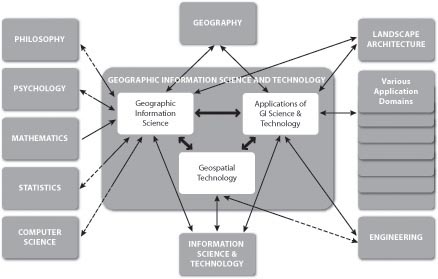
El campo de la Ciencia y Tecnología de la Información Geográfica (GIS&T) y sus relaciones con otros campos. Las relaciones bidireccionales que son medio discontinuas representan contribuciones asimétricas entre campos aliados. (© 2006 Association of American Geographers and University Consortium for Geographic Information Science. Usado con permiso. Todos los derechos reservados.)
La ilustración anterior apareció por primera vez en el Cuerpo de Conocimiento de Ciencia y Tecnología de la Información Geográfica (DiBiase, DeMers, Johnson, Kemp, Luck, Plewe y Wentz, 2006), publicado por el Consorcio Universitario para la Ciencia de la Información Geográfica (UCGIS) y la Asociación de Geógrafos Americanos ( AAG) en 2006. El Cuerpo de Conocimiento es un inventario desarrollado por la comunidad de los conocimientos y habilidades que definen el campo GIS&T. Al igual que los cuerpos de conocimiento desarrollados en Ciencias de la Computación y otros campos, el GIS&T BoK representa el dominio del conocimiento GIS&T como una lista jerárquica de áreas de conocimiento, unidades, temas y objetivos educativos. En la siguiente tabla se muestran las diez áreas de conocimiento y 73 unidades que conforman la primera edición. Se muestran en negrita veintiséis unidades “básicas” (aquellas en las que todos los egresados de un programa de grado o certificado deben poder demostrar algún nivel de dominio). No se muestran los 329 temas que conforman las unidades, ni los mil 660 objetivos educativos por los que se definen los temas. Estos aparecen en el texto completo del GIS&T BoK. Desafortunadamente, el texto completo no está disponible gratuitamente en línea. Sin embargo, un importante trabajo relacionado producido por el Departamento de Trabajo de Estados Unidos es. Vamos a echar un vistazo a eso en breve.
ÁREAS Y UNIDADES DE CONOCIMIENTO QUE COMPONEN LA 1ª EDICIÓN DEL BOK
-Área de Conocimiento AM. Métodos Analíticos
-Unidad AM1 Orígenes académicos y analíticos
-Unidad AM2 Operaciones de consulta y lenguajes de consulta
-Unidad AM3 Medidas geométricas
-Unidad AM4 Operaciones analíticas básicas
-Unidad AM5 Métodos analíticos básicos
-Unidad AM6 Análisis de superficies
-Unidad AM7 Estadística espacial
-Unidad AM8 Geoestadística
-Unidad AM9 Regresión espacial y econometría
-Unidad AM10 Minería de datos
-Unidad AM11 Análisis de redes
-Unidad AM12 Optimización y modelado de ubicación-asignación
-Área de Conocimiento CF. Fundamentos Conceptuales
-Unidad CF1 Fundamentos filosóficos
-Unidad CF2 Fundamentos cognitivos y sociales
-Unidad CF3 Dominios de información geográfica
-Unidad CF4 Elementos de información geográfica
-Unidad CF5 Relaciones
-Unidad CF6 Imperfecciones en la información geográfica
-Área de Conocimiento CV. Cartografía y Visualización
-Unidad CV1 Historia y tendencias
-Unidad CV2 Consideraciones de datos
-Unidad CV3 Principios de diseño de mapas
-Unidad CV4 Técnicas de representación gráfica
-Unidad CV5 Producción de mapas
-Unidad CV6 Uso de mapas y evaluación
-Área de Conocimiento DA. Aspectos de diseño
-Unidad DA1 El alcance del diseño de sistemas GI S&T
-Unidad DA2 Definición de proyecto
-Unidad DA3 Planificación de recursos
-Unidad DA4 Diseño de bases de datos
-Unidad DA5 Diseño de análisis
-Unidad DA6 Diseño de aplicaciones
-Unidad DA7 Sistema implementación
-Área de Conocimiento DM. Modelado de datos
-Unidad DM1 Estructuras básicas de almacenamiento y recuperación
-Unidad DM2 Sistemas de gestión de bases de datos
-Unidad DM3 Modelos de datos de teselación
-Unidad DM4 Modelos de datos vectoriales y de objetos
-Unidad DM5 Modelado 3D, temporal, y fenómenos inciertos
-Área de Conocimiento DN. Manipulación de Datos
-Unidad DN1 Transformación de representación
-Unidad DN2 Generalización y agregación
-Unidad DN3 Gestión de transacciones de datos geoespaciales
-Área de Conocimiento GC. Geocomputación
-Unidad GC1 Emergencia de geocomputación
-Unidad GC2 Aspectos computacionales y neurocomputación
-Unidad GC3 Modelos de autómatas celulares (CA)
-Unidad GC4 Heurística
-Unidad GC5 Algoritmos genéticos (GA)
-Unidad GC6 Modelos basados en agentes
-Unidad GC7 Modelado de simulación
-Unidad GC8 Incertidumbre
-Unidad GC9 Conjuntos difusos
-Área de Conocimiento GD. Datos geoespaciales
— Unidad GD1 Geometría terrestre
— Unidad GD2 Sistemas de partición terrestre
-Unidad GD3 Sistemas de georreferenciación
-Unidad GD4 Datums
-Unidad GD5 Proyecciones de mapas
-Unidad GD6 Calidad de los datos
-Unidad GD7 Topografía y GPS
-Unidad GD8 Digitalización
-Unidad GD9 Recogida de datos de campo
-Unidad GD10 Imágenes aéreas y fotogrametría
-Unidad GD11 Teledetección satelital y a bordo
-Unidad GD12 Metadatos, estándares e infraestructuras
-Área de Conocimiento GS. GIS&T y Sociedad
-Unidad GS1 Aspectos jurídicos
-Unidad GS2 Aspectos económicos
-Unidad GS3 Uso de la información geoespacial en el sector público
-Unidad GS4 La información geoespacial como propiedad
-Unidad GS5 Difusión de información geoespacial
-Unidad GS6 Aspectos éticos de la información y la tecnología geoespaciales
-Unidad GS7 SIG Crítico
-Área de Conocimiento OI. Aspectos Organizacionales e Institucionales
-Unidad OI1 Orígenes de GI S&T
-Unidad O2 Gestión de las operaciones e infraestructura del sistema GI
-Unidad OI3 Estructuras y procedimientos organizacionales
-Unidad OI4 Temas de fuerza de trabajo GI S&T
-Unidad OI5 Aspectos institucionales e interinstitucionales
-Unidad OI6 Organizaciones coordinadoras (nacionales e internacionales)
Diez áreas de conocimiento y 73 unidades que comprenden la 1ª edición del GIS&T BoK. Las unidades centrales se indican con negrita. (© 2006 Asociación de Geógrafos Americanos y Consorcio Universitario para la Ciencia de la Información Geográfica. Usado con permiso. Todos los derechos reservados.)
Observe que el área de conocimiento que incluye más unidades centrales es GD: Datos geoespaciales. Este curso se centra en las fuentes y características distintivas de los datos geográficos. Esta es una parte de la base de conocimiento que poseen los profesionales geoespaciales más exitosos. El Modelo de Competencia Tecnológica Geoespacial (GTCM) del Departamento de Trabajo destaca este y otros elementos esenciales de la base de conocimiento geoespacial. Lo consideraremos a continuación.
1.13. Competencias geoespaciales y nuestro plan de estudios
Un cuerpo de conocimiento es una forma de pensar sobre el campo GIS&T. Otra forma es como una industria conformada por agencias y firmas que producen y consumen bienes y servicios, generan ventas y (a veces) ganancias, y emplean a personas. En 2003, el Departamento de Trabajo de Estados Unidos (DoL) identificó la “tecnología geoespacial” como una de las 14 industrias tecnológicas de “alto crecimiento”, junto con la biotecnología, la nanotecnología y otras. Sin embargo, el DoL también observó que la industria de la tecnología geoespacial estaba mal definida y poco entendida por el público.
Los esfuerzos posteriores del DoL y otras organizaciones ayudaron a aclarar la naturaleza y alcance de la industria. Después de una serie de discusiones de “mesa redonda” en las que participaron líderes de opinión de la industria, la Asociación de Tecnología de la Información Geoespacial (GITA) y la Asociación de Geógrafos Americanos (AAG) presentaron la siguiente definición “concensal” a DoL en 2006:
La industria geoespacial adquiere, integra, administra, analiza, mapea, distribuye y utiliza información y conocimiento geográficos, temporales y espaciales. La industria incluye investigación básica y aplicada, desarrollo tecnológico, educación y aplicaciones para abordar la planeación, toma de decisiones y necesidades operativas de personas y organizaciones de todo tipo.
Además de la definición de industria propuesta, el informe GITA y AAG recomendaron que el DoL establezca ocupaciones adicionales en reconocimiento de las actividades y necesidades de la fuerza laboral de la industria geoespacial. En ese momento, las ocupaciones geoespaciales existentes incluían únicamente Agrimensores, Técnicos de Topografía, Técnicos de Cartografía y Cartógrafos y Fotogrammetristas. A finales de 2009, con aportes del GITA, AAG y otras partes interesadas, el DoL estableció seis nuevas ocupaciones geoespaciales: Científicos y Tecnólogos de Información Geoespacial, Técnicos en Sistemas de Información Geográfica, Científicos y Tecnólogos de Teledetección, Técnicos en Teledetección, Agricultura de Precisión Técnicos y Agrimensores Geodésicos.
PRUEBA ESTO
Investigar las ocupaciones geoespaciales en la base de datos “O*Net” del Departamento de Trabajo de Estados Unidos. Ingrese “geoespacial” en el campo de búsqueda denominado “Búsqueda rápida de ocupación”. Siga los enlaces a las descripciones de ocupación. Anote las estimaciones para el empleo 2008 y el crecimiento del empleo hasta 2018. También tenga en cuenta que, por alguna razón anómala, la palabra clave “geoespacial” no está asociada con la ocupación “Geodetic Surveyor”.
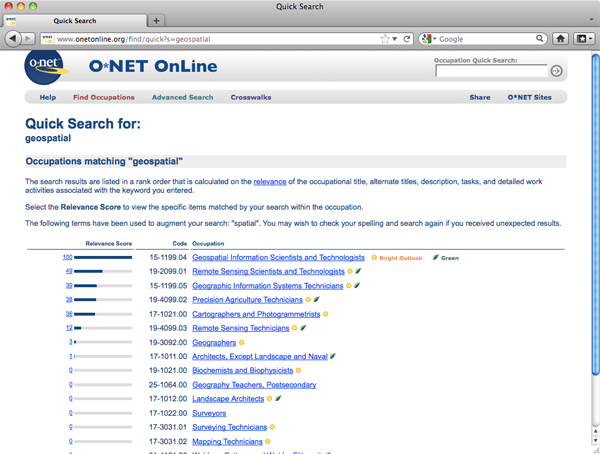
Mientras tanto, DoL inició una iniciativa de “modelado de competencias” para industrias de alto crecimiento en 2005. Su objetivo era ayudar a instituciones educativas como la nuestra a satisfacer la demanda de trabajadores tecnológicos calificados identificando lo que los trabajadores necesitan saber y ser capaces de hacer. En DoL, una competencia es “la capacidad de aplicar o utilizar un conjunto de conocimientos, habilidades y habilidades relacionados requeridos para realizar con éxito 'funciones críticas de trabajo' o tareas en un entorno de trabajo definido” (Ennis 2008). Un modelo de competencias es “una colección de competencias que juntas definen el desempeño exitoso en un entorno de trabajo particular”.
Los analistas de la fuerza laboral de DoL comenzaron a trabajar en un Modelo de Competencia Tecnológica Geoespacial (GTCM) en 2005. A partir de su investigación, un panel de profesionales y educadores consumados produjo un borrador completo del GTCM, que posteriormente revisaron en respuesta a comentarios públicos. Publicado en junio de 2010, el GTCM identifica las competencias que caracterizan a los trabajadores exitosos en la industria geoespacial. A diferencia de GIS&T Body of Knowledge, un proyecto académico destinado a definir la naturaleza y alcance del campo, el GTCM es una especificación de la industria que define lo que los trabajadores y estudiantes individuales deben aspirar a conocer y aprender.
PRUEBA ESTO
Explore el Modelo de Competencias de Tecnología Geoespacial (GTCM) en el Centro de intercambio de información sobre modelos de competencia del Departamento de Trabajo de los Estados Unidos. En “Modelos de competencia de la industria”, siga el enlace “Tecnología geoespacial”. Allí, la pirámide (como se muestra a continuación) es un mapa de imagen en el que puedes hacer clic para revelar las distintas competencias. El GTCM completo también está disponible como documento Word y archivo PDF.

El GTCM especifica varios “niveles” de competencias, pasando de general a ocupacional específica. Los niveles 1 a 3 (las capas gris y roja), llamados Competencias de Fundación, especifican los comportamientos generales del lugar de trabajo y el conocimiento que exhiben los trabajadores exitosos en la mayoría de las industrias. Los niveles 4 y 5 (amarillo) incluyen las competencias técnicas distintivas que caracterizan a una industria determinada y sus tres sectores: Posicionamiento y Adquisición de Datos, Análisis y Modelado, y Programación y Desarrollo de Aplicaciones. Por encima del Nivel 5 se encuentran los Niveles adicionales correspondientes a las competencias y requisitos específicos de la ocupación que se especifican en las descripciones de ocupación publicadas en O*NET Online, y en un Modelo de Competencias de Gestión Geoespacial que se encuentra en desarrollo a partir de enero de 2012.
Una forma en que las instituciones educativas y los estudiantes pueden usar el GTCM es como una guía para evaluar qué tan bien se alinean los planes de estudio con las necesidades de El programa Penn State Online GIS realizó dicha evaluación en 2011. Los resultados aparecen en la hoja de cálculo vinculada a continuación.
PRUEBA ESTO
Abra la hoja de cálculo de Excel adjunta para ver cómo nuestros planes de estudio GIS en línea de Penn State abordan las necesidades de la fuerza laboral identificadas en el GTCM.
La hoja se abrirá en una portada. En la parte inferior de la hoja hay pestañas que corresponden a los Niveles 1-5 del GTCM. Haga clic en las pestañas para ver la hoja de trabajo asociada con el Nivel que desea ver.
En cada hoja de trabajo Tier, las filas corresponden a las competencias GTCM. Las columnas corresponden a los cursos Penn State Online incluidos en la evaluación. Los cursos que se requieren para la mayoría de los estudiantes están resaltados en azul claro. Se pidió a los autores e instructores del curso que indicaran qué hacen realmente los estudiantes en relación con cada una de las competencias del GTCM. Use la barra de desplazamiento en el borde inferior derecho de la hoja para revelar más cursos.
Abra la película Flash adjunta para ver una demostración en video de cómo navegar por la hoja de cálculo.
Al estudiar esta hoja de cálculo, obtendrá información sobre cómo los cursos individuales y cómo el plan de estudios Penn State Online en su conjunto se relaciona con las necesidades de la fuerza laboral geoespacial. Si te interesa comparar los nuestros con los planes de estudio de otras instituciones, pregunta si han realizado una evaluación similar. Si no lo han hecho, pregunta por qué no.
Por último, no olvide que puede obtener una vista previa de gran parte de nuestros cursos en línea a través de nuestra iniciativa Open Educational Resouces.
1.14. Distinguir las propiedades de los datos geográficos
La afirmación de que la ciencia de la información geográfica es un campo de estudio distinto implica que los datos espaciales son de alguna manera datos especiales. Goodchild (1992) señala varias propiedades distintivas de la información geográfica. He parafraseado cuatro de esas propiedades a continuación. Comprenderlas, y sus implicaciones para la práctica de la ciencia de la información geográfica, es un objetivo clave de este curso.
- Los datos geográficos representan ubicaciones espaciales y atributos no espaciales medidos en ciertos momentos.
- El espacio geográfico es continuo.
- El espacio geográfico es casi esférico.
- Los datos geográficos tienden a ser espacialmente dependientes.
Consideremos cada una de estas propiedades a continuación.
1.15. Ubicaciones y atributos
Los datos geográficos representan ubicaciones espaciales y atributos no espaciales medidos en ciertos momentos. Goodchild (1992, p. 33) observa que “una base de datos espacial tiene claves duales, lo que permite acceder a los registros ya sea por atributos o por ubicaciones”. Las claves duales no son exclusivas de los datos geográficos, sino que “la clave espacial es distinta, ya que permite definir operaciones que no están incluidas en los lenguajes de consulta estándar”. En los años intermedios, los desarrolladores de software han creado variaciones en SQL que incorporan consultas espaciales. Sin embargo, la naturaleza dinámica de los fenómenos geográficos complica aún más el tema. La necesidad de plantear consultas espacio-temporales desafía a los científicos de información geográfica (GIScientists) a desarrollar formas cada vez más sofisticadas de representar fenómenos geográficos, permitiendo así a los analistas interrogar sus datos de formas cada vez más sofisticadas.
1.16. Continuidad
El espacio geográfico es continuo. Aunque las claves duales no son exclusivas de los datos geográficos, una propiedad de la clave espacial es. “Lo que distingue a los datos espaciales es el hecho de que la clave espacial se basa en dos dimensiones continuas” (Goodchild, 1992, p.33). “Continuo” se refiere al hecho de que no hay huecos en la superficie de la Tierra. A pesar de cañones, grietas e incluso cavernas, no hay ninguna posición sobre o cerca de la superficie de la Tierra que no pueda fijarse dentro de algún tipo de cuadrícula del sistema de coordenadas. Tampoco hay ningún límite teórico sobre cómo se puede especificar exactamente una posición. Dada la precisión de las modernas tecnologías de posicionamiento, el número de posiciones puntuales únicas que podrían utilizarse para definir una entidad geográfica es prácticamente infinito. Debido a que no es posible medir, y mucho menos almacenar, administrar y procesar, una cantidad infinita de datos, todos los datos geográficos son selectivos, generalizados, aproximados. Además, cuanto mayor es el territorio cubierto por una base de datos geográfica, más generalizada tiende a ser la base de datos.
Los datos geográficos se generalizan según la escala. Haga click en los botones debajo del mapa para hacer zoom y acercarse a la localidad de Gorham. (Servicio Geológico de Estados Unidos). (Nota: Deberá tener instalado el reproductor de Adobe Flash para poder completar este ejercicio. Si aún no tienes el Flash Player, puedes descargarlo de forma gratuita desde Adobe.)
Por ejemplo, la ilustración anterior muestra un pueblo llamado Gorham representado en tres mapas topográficos diferentes producidos por el Servicio Geológico de los Estados Unidos. Gorham ocupa un espacio más pequeño en el mapa a pequeña escala (1:250 ,000) que a 1:62 ,000 o a 1:24 ,000. Pero el tamaño relativo de la característica no es lo único que cambia. Observe que la forma de la entidad que representa la ciudad también cambia. Al igual que el número de características y la cantidad de detalles que se muestran dentro del límite de la ciudad y en los alrededores. El nombre de esta disminución característicamente paralela en el detalle del mapa y la escala del mapa es generalización.
Es importante darse cuenta de que la generalización ocurre no sólo en mapas impresos, sino también en bases de datos digitales. Es posible representar fenómenos con características altamente detalladas (ya sean conformadas por celdas de cuadrícula ráster de alta resolución o muchas ubicaciones de puntos) en una sola base de datos independiente de escala. En la práctica, sin embargo, las bases de datos altamente detalladas no solo son extremadamente costosas de crear y mantener, sino que también empañan los sistemas de información cuando se utilizan en análisis de grandes áreas. Por esta razón, las bases de datos geográficas generalmente se crean a varias escalas, con diferentes niveles de detalle capturados para diferentes usos previstos.
1.17. Casi esférico
El espacio geográfico es casi esférico. El hecho de que la Tierra sea casi, pero no del todo, una esfera plantea algunos problemas sorprendentemente complejos para quienes desean especificar ubicaciones con precisión.
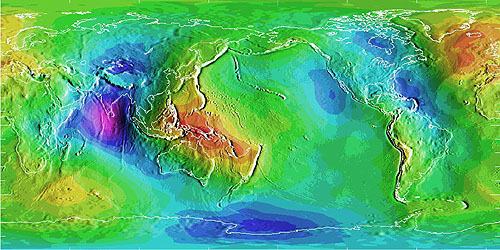
Diferencias de elevación entre un modelo geoide y un elipsoide de referencia. Las desviaciones van desde un alto de 75 metros (de color rojo, sobre Nueva Guinea) a un bajo de 104 metros (de color púrpura, en el Océano Índico). (Encuesta Geodésica Nacional, n. d.).
El sistema de coordenadas geográficas de coordenadas de latitud y longitud proporciona un medio para definir posiciones en una esfera. Imprecisiones que son inaceptables para algunas aplicaciones se arrastran, sin embargo, cuando nos enfrentamos a la forma irregular “real” de la Tierra, que se llama el geoide. Además, los cálculos de ángulos y distancia que los topógrafos y otros necesitan realizar rutinariamente son engorrosos con coordenadas esféricas.
Esa consideración, junto con la necesidad de representar la Tierra en trozos planos de papel, nos obliga a transformar el globo terráqueo en un plano, y a especificar ubicaciones en coordenadas planas en lugar de coordenadas esféricas. El conjunto de transformaciones matemáticas mediante las cuales las ubicaciones esféricas se convierten en ubicaciones en un plano, llamadas proyecciones de mapa, conducen inevitablemente a una u otra forma de imprecisión.
Todo esto es bastante problemático, pero encontramos aún más dificultades cuando buscamos definir posiciones “verticales” (elevaciones) además de posiciones “horizontales”. Quizás no hace falta decir que una elevación es la altura de una ubicación por encima de algún dato, como el nivel medio del mar. Desafortunadamente, para ser adecuado para un posicionamiento preciso, un dato debe corresponder estrechamente con la forma real de la Tierra. Lo que nos devuelve de nuevo al problema del geoide.
Consideraremos estos temas con mayor profundidad en el Capítulo 2. Por ahora, basta decir que los datos geográficos son únicos al tener que representar fenómenos que se distribuyen sobre una superficie continua y casi esférica.
1.18. Dependencia espacial
Los datos geográficos tienden a ser espacialmente dependientes. La dependencia espacial es “la propensión de que las localizaciones cercanas se influencien entre sí y posean atributos similares” (Goodchild, 1992, p.33). Es decir, para parafrasear a un famoso geógrafo llamado Waldo Tobler, mientras que todo está relacionado con todo lo demás, las cosas que están muy juntas tienden a estar más relacionadas que las cosas que están muy separadas. Las elevaciones del terreno, los tipos de suelo y las temperaturas del aire superficial, por ejemplo, tienen más probabilidades de ser similares en puntos separados a dos metros que en puntos a dos kilómetros de distancia. Una medida estadística de la similitud de atributos de ubicaciones de puntos se denomina autocorrelación espacial.
Dado que los datos geográficos son caros de crear, la dependencia espacial resulta ser una propiedad muy útil. Podemos muestrear atributos en un número limitado de ubicaciones, luego estimar los atributos de ubicaciones intermedias. El proceso de estimación de valores desconocidos a partir de valores conocidos cercanos se denomina interpolación. Los valores interpolados son confiables solo en la medida en que se pueda asumir la dependencia espacial del fenómeno. Si no pudiéramos asumir algún grado de dependencia espacial, sería imposible representar fenómenos geográficos continuos en forma digital.
PRÁCTICA
19. Datos Geográficos y Preguntas Geográficas
El objetivo último de todos los datos y tecnologías geoespaciales, después de todo, es producir conocimiento. La mayoría de nosotros estamos interesados en los datos solo en la medida en que puedan ser utilizados para ayudar a entender el mundo que nos rodea, y para tomar mejores decisiones. Los procesos de toma de decisiones varían mucho de una organización a otra. En general, sin embargo, los primeros pasos para tomar una decisión son articular las preguntas que necesitan ser respondidas, y recopilar y organizar los datos necesarios para responder a las preguntas (Nyerges & Golledge, 1997).
Los datos geográficos y las tecnologías de la información pueden ser muy eficaces para ayudar a responder a ciertos tipos de preguntas. Las costosas inversiones a largo plazo que se requieren para construir y sostener infraestructuras SIG solo pueden justificarse si las preguntas que enfrenta una organización se pueden plantear en términos que SIG está equipado para responder. Como especialista en la materia, se puede esperar que asesore a clientes y colegas sobre las fortalezas y debilidades del SIG como herramienta de apoyo a la toma de decisiones. A continuación hay ejemplos de los tipos de preguntas que son susceptibles de análisis SIG, junto con preguntas que SIG no es tan adecuado para ayudar a responder.
PREGUNTAS RELATIVAS A ENTIDADES GEOGRÁFICAS INDIVIDUALES
Las cuestiones geográficas más simples pertenecen a entidades individuales. Tales preguntas incluyen:
Preguntas sobre el espacio
- ¿Dónde se encuentra la entidad?
- ¿Cuál es su alcance?
Preguntas sobre atributos
- ¿Cuáles son los atributos de la entidad ahí ubicada?
- ¿Sus atributos coinciden con uno o más criterios?
PREGUNTAS SOBRE TIEMPO
- ¿Cuándo se midió la ubicación, extensión o atributos de la entidad?
- ¿La ubicación, extensión o atributos de la entidad ha cambiado con el tiempo?
Preguntas simples como estas se pueden responder de manera efectiva con un buen mapa impreso, por supuesto. Los SIG se vuelven cada vez más atractivos a medida que aumenta el número de personas que hacen las preguntas, especialmente si carecen de acceso a los mapas en papel requeridos.
PREGUNTAS RELATIVAS A MÚLTIPLES ENTIDADES GEOGRÁFICAS
Las preguntas más difíciles surgen cuando consideramos las relaciones entre dos o más entidades. Por ejemplo, podemos preguntar:
PREGUNTAS SOBRE RELACIONES ESPACIALES
- ¿Las entidades se contienen entre sí?
- ¿Se superponen?
- ¿Están conectados?
- ¿Están situados a cierta distancia el uno del otro?
- ¿Cuál es la mejor ruta de una entidad a la otra?
- ¿Dónde se encuentran las entidades con atributos similares?
PREGUNTAS SOBRE RELACIONES DE ATRIBUTOS
- ¿Las entidades comparten atributos que coinciden con uno o más criterios?
- ¿Los atributos de una entidad están influenciados por cambios en otra entidad?
PREGUNTAS SOBRE RELACIONES TEMPORALES
- ¿Han cambiado las ubicaciones, extensiones o atributos de las entidades con el paso del tiempo?
Los datos geográficos y las tecnologías de la información son muy adecuados para responder preguntas moderadamente complejas como estas. Los SIG son más valiosos para las grandes organizaciones que necesitan responder a tales preguntas con frecuencia.
PREGUNTAS QUE SIG NO ES ESPECIALMENTE BUENO
Aún más difíciles, sin embargo, son las preguntas explicativas —como por qué las entidades se encuentran donde están, por qué tienen los atributos que tienen y por qué han cambiado como lo han hecho. Además, las organizaciones a menudo se preocupan por preguntas predictivas, como ¿qué sucederá en esta ubicación si así sucede en esa ubicación? En general, no se puede esperar que los paquetes de software GIS comerciales proporcionen respuestas claras a preguntas explicativas y predictivas desde el primer momento. Por lo general, los analistas deben recurrir a paquetes estadísticos especializados y rutinas de simulación. La información producida por estas herramientas analíticas puede entonces ser reintroducida en la base de datos SIG, si es necesario. Los esfuerzos de investigación y desarrollo destinados a acoplar más estrechamente el software analítico con el software GIS están en marcha dentro de la comunidad GIScience. Es importante tener en cuenta que las herramientas de apoyo a la toma de decisiones como los SIG no son sustitutos de la experiencia humana, el conocimiento y el juicio.
Al inicio del capítulo sugerí que producir información analizando datos es algo así como producir energía quemando carbón. En ambos casos, la tecnología se utiliza para realizar el valor potencial de una materia prima. También en ambos casos, el proceso de producción produce algunos subproductos indeseables. De igual manera, en el proceso de respuesta a ciertas preguntas geográficas, el SIG tiende a plantear otras, como:
- Dadas las imperfecciones intrínsecas de los datos, ¿qué tan confiables son los resultados del análisis SIG?
- ¿La información producida a través del análisis SIG tiende a beneficiar sistemáticamente a algunos grupos constituyentes a expensas de otros?
- ¿Deben hacerse públicos los datos utilizados para tomar la decisión?
- ¿El uso del SIG afecta los procesos de toma de decisiones de la organización de manera beneficiosa para su administración, sus empleados y sus clientes?
Como es el caso en tantos esfuerzos, la respuesta a una pregunta geográfica suele incluir más preguntas.
PRUEBA ESTO
¿Puede citar un ejemplo de una pregunta “dura” que usted y su sistema SIG han sido llamados a abordar? Los estudiantes registrados en Penn State pueden publicar un comentario directamente en esta página.
1.20. Resumen
Es una obviedad entre los especialistas en información geográfica que la mayor parte del costo de la mayoría de los proyectos SIG está asociada con el desarrollo y mantenimiento de una base de datos adecuada. Parece apropiado, por lo tanto, que nuestro primer curso en sistemas de información geográfica se centre en las propiedades de los datos geográficos.
Comencé este primer capítulo definiendo los datos en un sentido genérico, como conjuntos de símbolos que representan mediciones de fenómenos. Yo sugerí que los datos son las materias primas a partir de las cuales se produce la información. Los sistemas de información, como los sistemas de gestión de bases de datos, son tecnologías que las personas utilizan para transformar los datos en la información necesaria para responder preguntas y tomar decisiones.
Los datos espaciales son datos especiales. Representan las ubicaciones, extensiones y atributos de objetos y fenómenos que conforman la superficie de la Tierra en momentos particulares. Los datos geográficos difieren de otros tipos de datos en que se distribuyen a lo largo de un globo continuo, casi esférico. También tienen la propiedad única de que cuanto más cerca se localicen dos entidades, más probabilidades hay de que compartan atributos similares.
SIG es un tipo especial de sistema de información que combina las capacidades de los sistemas de gestión de bases de datos con las de los sistemas de mapeo. SIG es un objeto de estudio del campo multidisciplinario poco tejido llamado Ciencia y Tecnología de la Información Geográfica. El SIG también es una profesión, una de las varias que conforman la industria geoespacial. Como dijo Yogi Berra, “En teoría, no hay diferencia entre teoría y práctica. En la práctica lo hay”. En los capítulos y proyectos que siguen, investigaremos la naturaleza de la información geográfica tanto desde el punto de vista conceptual como práctico.
COMENTARIOS Y PREGUNTAS
Los estudiantes registrados son bienvenidos a publicar comentarios, preguntas y respuestas a preguntas sobre el texto. Particularmente bienvenidos son las anécdotas que relacionan el texto del capítulo con su experiencia personal o profesional. Además, hay foros de discusión disponibles en el sistema de gestión de cursos ANGEL para comentarios y preguntas sobre temas que quizás no desees compartir con todo el mundo.
Para publicar un comentario, desplácese hacia abajo hasta el cuadro de texto debajo de “Publicar nuevo comentario” y comience a escribir en el cuadro de texto, o puede optar por responder a un hilo existente. Cuando termine de escribir, haga clic en el botón “Vista previa” o “Guardar” (Guardar enviará realmente su comentario). Una vez publicado tu comentario, podrás editarlo o eliminarlo según sea necesario. Además, podrás responder a otras publicaciones en cualquier momento.
Nota: las primeras palabras de cada comentario se convierten en su “título” en el hilo.
1.21. Bibliografía
Carstensen, L. W. (1986). Desarrollo de sistemas regionales de información territorial utilizando bases de datos relacionales y sistemas de información geográfica. Actas del AutoCarto, Londres, 507-516.
Ciudad de Ontario, California. (n.d.). Servidor web de información geográfica. Recuperado el 6 de julio de 1999 de www.ci.ontario.ca.us/gis/index.asp (desde que se retiró).
Cowen, D. J. (1988). GIS versus CAD versus DBMS: ¿Cuáles son las diferencias? Ingeniería Fotogramétrica y Teledetección 54:11, 1551-1555.
DiBiase, D. y otros doce (2010). El Nuevo Modelo de Competencias en Tecnología Geoespacial: Enfocar las necesidades de la fuerza laboral. Revista URISA 22:2, 55-72.
DiBiase, D, M. DeMers, A. Johnson, K. Kemp, A. Luck, B. Plewe, y E. Wentz (2007). Presentamos la Primera Edición del Cuerpo de Conocimiento GIS&T. Cartografía y Ciencia de la Información Geográfica, 34 (2), pp. 113-120. Informe Nacional de Estados Unidos a la Asociación Cartográfica Internacional.
Ennis, M. R. (2008). Modelos de competencias: Una revisión de la literatura y el papel de la administración del empleo y la formación (ETA) .www.careeronestop.org/competencymodel/info_documents/opdrliteraturareview.pdf.
GITA y AAG (2006). Definición y comunicación de la demanda laboral de la industria geoespacial: Informe Fase I.
Goodchild, M. (1992). Ciencia de la información geográfica. Revista Internacional de Sistemas de Información Geográfica 6:1, 31-45.
Goodchild, M. (1995). GIS e investigación geográfica. En J. Pickles (Ed.) , Verdad fundamental: las implicaciones sociales de los sistemas de información geográfica (pp. del capítulo). Nueva York: Guilford.
Sistemas Nacionales de Decisión. ¡Un código postal puede hacer que tu empresa sea mucho dinero! Recuperado el 6 de julio de 1999 delaguna.natdecsys.com/lifequiz (desde retirado).
Encuesta Geodésica Nacional. (1997). Imagen generada a partir de ondulaciones geoides de 15′x15′ que cubren el planeta Tierra. Recuperado 1999, dewww.ngs.noaa.gov/geoid/geo-index.html (desde que se retiró).
Nyerges, T. L. & Golledge, R. G. (n.d.) Plan de estudios básico del NCGIA en SIG, Centro Nacional de Información y Análisis Geográficos, Universidad de California, Santa Bárbara, Unidad 007. Recuperado el 12 de noviembre de 1997, dewww.ncgia.ucsb.edu/giscc/units/u007/u007.html (desde que se retiró).
Servicio Geológico del Departamento del Interior de Estados Unidos. (1977). [mapa]. 1:24 000. Serie de 7.5 minutos. Washington, D.C.: USDI.
Encuesta Geológica de Estados Unidos. “Bellefonte, Cuadrángulo PA” (1971). [mapa]. 1:24 000. Serie de 7.5 minutos. Washington, D.C.:USGS.
Consorcio Universitario de Ciencias de la Información Geográfica. Recuperado el 26 de abril de 2006, de http://www.ucgis.org
Wilson, J. D. (2001). Proveedores de datos de atención: Te espera una aplicación de mil millones de dólares. GeoWorld, febrero, 54.
Worboys, M. F. (1995). SIG: Una perspectiva informática. Londres: Taylor y Francis.
‹ 20. Resumen hasta Capítulo 2: Escalas y transformaciones ›