
4.6: Examinar los resultados de un solo escenario
- Page ID
- 80870

En esta sección se presenta una estrategia para examinar los resultados de simulación de un escenario de sistema único definido por un conjunto de valores de parámetros del modelo. Los resultados se examinan para comprender el comportamiento del sistema. Se utiliza evidencia estadística en forma de intervalos de confianza para confirmar que lo que se observa no se debe solo a la naturaleza aleatoria del modelo de simulación y experimento y, por lo tanto, proporciona una base válida para comprender el comportamiento del sistema.
Los resultados de la simulación se muestran y examinan utilizando gráficos e histogramas, así como estadísticas resumidas como la media, desviación estándar, mínimo y máximo. Los patrones de comportamiento del sistema se identifican si es posible. La animación se utiliza para mostrar la dinámica de tiempo de la simulación. Esto está de acuerdo con el principio 8: Mirar todos los valores simulados de las medidas de desempeño ayuda.
Cómo se logra con éxito el examen de los resultados de la simulación es un arte como se afirma en el principio 1. Así, este tema será discutido e ilustrado más a fondo en el contexto de cada estudio de aplicación.
La discusión en esta sesión se presenta en el contexto de las dos estaciones de trabajo en un modelo en serie.
4.6.1 Gráficos, Histogramas y Estadísticas de Resumen
Los valores observados para cada medida de desempeño se pueden examinar a través de gráficas, histogramas y estadísticas resumidas. Para ilustrar, cada una de estas se mostrará para el número de entidades en el búfer de la estación de trabajo A en las dos estaciones de trabajo en un modelo en serie.
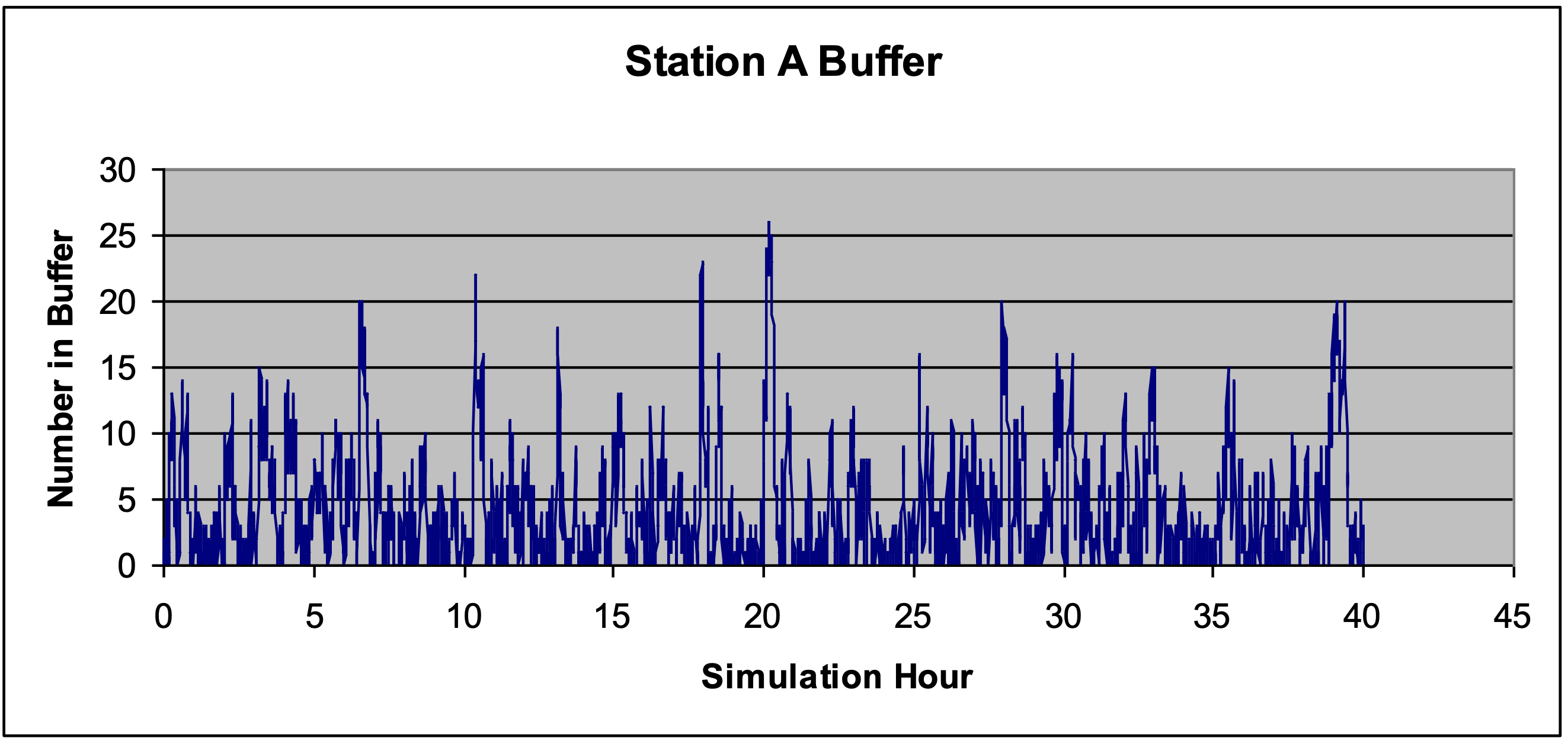
En la Figura 4-3 se muestra una gráfica de los valores observados del número en este tampón de replicar uno del experimento de simulación definido en la Tabla 4-2. El eje x es tiempo simulado y el eje y es el número en el búfer de la estación de trabajo A. Observe de la gráfica que la mayoría de las veces el número en el búfer varía entre 0 y 10. No obstante, hay varias ocasiones en las que el número en el búfer supera 20. Esto muestra una alta variabilidad en la estación de trabajo A.
Figura 4-3: Gráfica del número de entidades en el búfer de estación de trabajo A
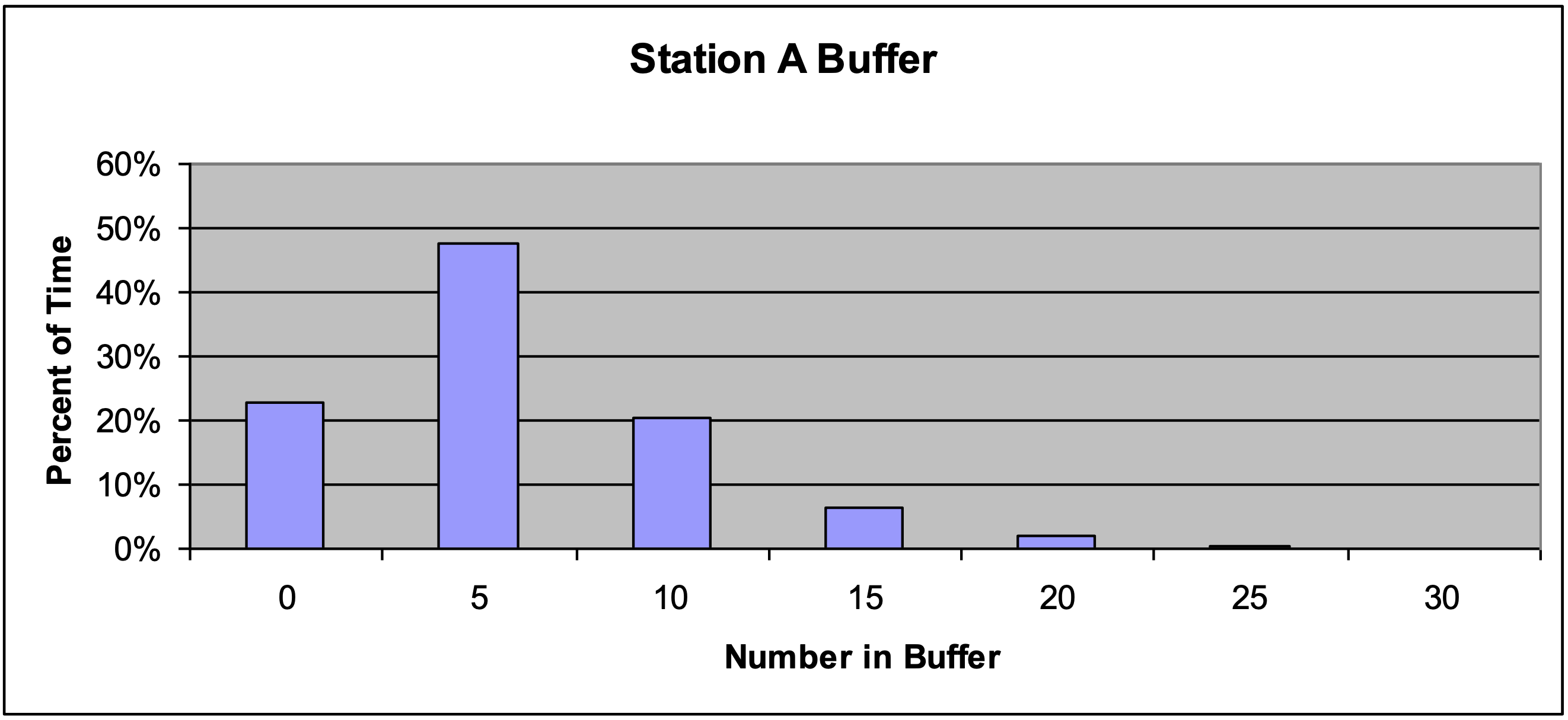
En la Figura 4-4 se muestra un histograma de las mismas observaciones. El porcentaje de tiempo que un cierto número de entidades está en el búfer se muestra en el eje y. El número de entidades se muestra en el eje x. Tenga en cuenta que alrededor del 91% de las veces hay 10 o menos entidades en el búfer de la estación de trabajo A. Sin embargo alrededor del 9% de las veces hay más de 10 entidades en el búfer.
Sería prudente examinar estas mismas gráficas de otras réplicas para ver si se observa el mismo patrón de comportamiento. Si la capacidad del software está disponible, un histograma que combine las observaciones de todas las réplicas sería de valor.
Figura 4-4: Histograma del número de entidades en el búfer de la estación de trabajo A
Los estadísticos resumidos se pueden computar a partir de las observaciones recogidas en cada réplica. Sin embargo, es probable que estas observaciones no sean independientes, por lo que su desviación estándar no es muy útil. El promedio, mínimo y máximo de las observaciones del número en el búfer de la estación de trabajo A del replicado 1 se dan en la Tabla 4-3. El número promedio de entidades es relativamente bajo pero el máximo vuelve a mostrar la alta variabilidad en el número en el búfer.
| Cuadro 4-3: Resumen de estadísticas para el número de entidades en el búfer de la estación de trabajo A — Replicar 1 | |
| Estadística | Valor |
| Promedio | 4.1 |
| Mínimo | 0 |
| Máximo | 26 |
Como se discutió anteriormente, cada réplica genera una observación independiente de cada promedio, mínimo y máximo. Supongamos que el número promedio y máximo en el búfer de la estación de trabajo A son de interés. El promedio corresponde al promedio de trabajo en proceso (WIP) en la estación de trabajo y el máximo a la capacidad de búfer necesaria en la estación de trabajo. El Cuadro 4-4 resume los resultados para 20 repeticiones. El promedio oscila entre 3.1 y 6.6 con un promedio general de 4.4. Esto demuestra que el número promedio en el búfer tiene poca variabilidad. El máximo muestra variabilidad significativa que va de 21 a 43 con un promedio de 31.
|
Cuadro 4-4: Resumen de estadísticas para el número de entidades en el búfer de la estación de trabajo A — Replicar del 1 al 20 |
||
| Replicar | Número promedio en el búfer de estación de trabajo A | Número máximo en el búfer de estación de trabajo A |
| 1 | 4.1 | 28 |
| 2 | 4.6 | 27 |
| 3 | 4.1 | 30 |
| 4 | 3.2 | 24 |
| 5 | 3.8 | 24 |
| 6 | 4.3 | 29 |
| 7 | 4.0 | 25 |
| 8 | 4.4 | 34 |
| 9 | 4.3 | 40 |
| 10 | 4.1 | 28 |
| 11 | 4.1 | 26 |
| 12 | 4.5 | 38 |
| 13 | 4.5 | 31 |
| 14 | 4.3 | 30 |
| 15 | 4.8 | 37 |
| 16 | 4.2 | 28 |
| 17 | 5.2 | 40 |
| 18 | 4.3 | 38 |
| 19 | 4.3 | 26 |
| 20 | 4.4 | 36 |
| Promedio | 4.3 | 31.0 |
| Std. Dev. | 0.39 | 5.4 |
| Mínimo | 3.2 | 24 |
| Máximo | 5.2 | 40 |
4.6.2 Intervalos de confianza
Un propósito de un experimento de simulación es estimar el valor del parámetro ta o característica del sistema de interés como el número promedio o máximo en el búfer de la estación de trabajo A. El valor real de dicho parámetro o característica es muy probablemente desconocido. Se necesita tanto un estimador de puntos como un estimador de intervalos. El estimador de puntos debe ser el punto central del intervalo.
El promedio del conjunto de observaciones independientes e idénticamente distribuidas, una de cada réplica, sirve como estimador puntual. Por ejemplo, los valores en la fila “promedio” de la Tabla 4-4 son estimadores de puntos, el primero del WIP promedio en el búfer de la estación de trabajo A y el segundo de la capacidad de búfer necesaria.
Se utilizarán los procedimientos de estimación de intervalos de confianza recomendados por la Ley (2007) para proporcionar un estimador de intervalos. Se recomienda el intervalo de confianza t dado por la ecuación 4-1.
\ begin {align} P\ left (\ bar {X} -t_ {1-\ alpha/2, n-1} *\ frac {s} {\ sqrt {n}}\ leq\ mu\ leq\ bar {X} +t_ {1-\ alfa/2, n-1} *\ frac {s} {\ sqrt {n}}\ derecha)\ aproximadamente 1- alfa\\ tag {4-1}\ end {align}
donde\(\ t_{1-\alpha / 2, n-1}\) está el punto\(\ 1-\alpha / 2\) porcentual de la distribución t de Student con n-1 grados de libertad, n es el número de réplicas,\(\ \bar{X}\) es el promedio (los valores en la fila “promedio” de la Tabla 4-4 por ejemplo), y s es la desviación estándar (los valores en la fila “std. dev.” de la Tabla 4-4 por ejemplo). El\(\ \approx\) signo significa aproximadamente. El símbolo\(\ \mu\) representa el valor real pero desconocido del parámetro del sistema o característica de interés.
El resultado de los cálculos usando la ecuación 4-1 es el intervalo que se muestra en la ecuación 4-2:
\ begin {align}\ text {(límite inferior}\ leq\ mu\ leq\ texto {límite superior) con}\ 1 -\ alfa\\ texto {confianza}\ tag {4-2}\ end {align}
donde
\ begin {align}\ text {límite inferior} =\ bar {X} -t_ {1-\ alfa/2, n-1} *\ frac {s} {\ sqrt {n}}\ tag {4-3}\ end {align}
\ begin {align}\ text {límite superior} =\ bar {X} +t_ {1-\ alfa/2, n-1} *\ frac {s} {\ sqrt {n}}\ tag {4-4}\ end {align}
Las ecuaciones 4-1 y 4-2 muestran la necesidad de distinguir entre probabilidad y confianza. Comprender esta diferencia puede requerir cierta reflexión ya que en el lenguaje cotidiano y no técnico las dos ideas se suelen utilizar indistintamente y ambas se expresan como un porcentaje.
Una declaración de probabilidad se refiere a una variable aleatoria. La ecuación 4-1 contiene las variables aleatorias\(\ \bar{X}\) y s y, por lo tanto, es una declaración de probabilidad válida. La interpretación de la ecuación 4-1 se basa en la interpretación de probabilidad de frecuencia a largo plazo y es la siguiente: Si se construye un número muy grande de intervalos de confianza utilizando la ecuación 4-1, el porcentaje de ellos que incluyen el valor real pero desconocido de\(\ \mu\) es aproximadamente\(\ 1-\alpha\). Este porcentaje se llama la cobertura.
El intervalo expresado en la ecuación 4-2 contiene dos valores numéricos: límite inferior y límite superior más la constante\(\ \mu\) cuyo valor es desconocido. Dado que no hay variables aleatorias en la ecuación 4-2, no puede ser una declaración de probabilidad. En cambio, la ecuación 4-2 se interpreta como una declaración del grado de confianza de\(\ (1-\alpha)\) que el intervalo contiene el valor del parámetro del sistema o característica de interés. Los valores típicos para\(\ (1-\alpha)\) son 90%, 95% y 99%. Un mayor nivel de confianza implica más evidencia de que el intervalo contiene el valor de\(\ \mu\).
Merecen la pena algunas reflexiones sobre cómo interpretar el nivel de confianza con respecto al tipo de evidencia aportada. Keller (2001) sugiere lo siguiente, que se utilizará en este texto.
| Cuadro 4-5. Interpretación de los valores de confianza | |
| \(\ (1-\alpha)\)Rango de confianza | Interpretación |
| \(\ (1-\alpha) \geq\)99% |
Evidencia abrumadora |
| 95%\(\ \geq(1-\alpha)>\) 99% | Evidencia fuerte |
| 90%\(\ \geq(1-\alpha)>\) 95% | Evidencia débil |
| 90%\(\ >(1-\alpha)\) | No hay pruebas |
Tenga en cuenta que cuanto mayor sea el nivel de confianza, mayor será el valor de\(\ t_{1-\alpha / 2, n-1}\) y, por lo tanto, mayor será el intervalo de confianza. Se prefiere un intervalo de confianza estrecho para que el valor de\(\ \mu\) quede delimitado con mayor precisión. No obstante, es claro que un alto nivel de confianza debe equilibrarse con el deseo de un intervalo de confianza estrecho.
Por qué la ecuación 4-1 es aproximada y no exacta es digno de discusión. Para que la ecuación 4-1 sea exacta, las observaciones en las que se basan los cálculos del intervalo de confianza deben provenir de una distribución normal además de ser independientes e idénticas distribuidas. Como se discutió anteriormente, estas dos últimas condiciones se cumplen con la definición de réplica mientras que la primera condición no puede garantizarse ya que las medidas de desempeño en una simulación se definen arbitrariamente.
Así, la ecuación 4-1 es aproximada. Aproximado significa que la cobertura producida usando la ecuación 4-1 probablemente será menor que\(\ 1-\alpha\).
Dado que la ecuación 4-2 proporciona sólo un nivel aproximado (no exacto) de confianza (no una probabilidad), es natural preguntarse por qué se debe utilizar. Law (2007) concluye que la experiencia ha demostrado que muchas simulaciones del mundo real producen observaciones del tipo para el que la ecuación 4-1 funciona bien, es decir, la cobertura producida usando la ecuación 4-1 es lo suficientemente cercana como\(\ 1-\alpha\) para ser útil en la realización de estudios de simulación. De la misma manera, Vardeman y Jobe (2001) afirman que los intervalos de confianza en general tienen un gran uso práctico, aunque no se puede hacer una declaración de probabilidad en cuanto a si un intervalo en particular contiene el valor real de la característica del sistema o parámetro de interés. Dado que los intervalos de confianza parecen funcionar bien en general y en estudios de simulación, se utilizarán a lo largo de este texto.
A modo de ejemplo, la Tabla 4-6 contiene los intervalos de confianza del 99% calculados a partir de la ecuación 4-2 para el número promedio y máximo de entidades en el búfer de la estación de trabajo A con base en los resultados mostrados en el Cuadro 4-4.
| Tabla 4-6: Intervalos de confianza del 99% para el número de entidades en el búfer de la estación de trabajo A basado en 20 réplicas | ||
| Número promedio en el búfer de estación de trabajo A | Número máximo en el búfer de estación de trabajo A | |
| Promedio | 4.3 | 31.0 |
| Std. Dev. | 0.39 | 5.4 |
| 99% CI — límite inferior | 4.0 | 27.5 |
| 99% CI — límite superior | 4.5 | 34.4 |
El intervalo de confianza para el promedio es pequeño. Sería seguro concluir que el número promedio en el búfer de la estación de trabajo A fue de 4 (en números enteros). El intervalo de confianza para el número máximo en el búfer oscila entre 27 y 34 (en números enteros). Si este rango se considera demasiado amplio para establecer un tamaño de búfer se podrían hacer réplicas adicionales, digamos otras 20.
4.6.3 Animar la dinámica del modelo
Como se discutió en el capítulo 1, los modelos de simulación y experimentos capturan la dinámica temporal de los sistemas. Sin embargo, los reportes de modelos y comportamientos experimentales suelen estar confinados a medios estáticos como reportes y presentaciones como las mostradas en las secciones anteriores. El proceso de simulación incluye expertos en sistemas y gerentes que pueden no conocer los métodos de modelado y pueden ser escépticos de que un modelo de computadora pueda representar la dinámica de un sistema complejo. Además, los sistemas complejos pueden incluir reglas de decisión complejas. Todas las consecuencias conductuales resultantes de estas reglas pueden ser difíciles de predecir.
Abordar estas preocupaciones implica responder a la pregunta: ¿Qué comportamiento del sistema se capturó en el modelo? Una forma muy efectiva de cumplir con este requisito es ver el comportamiento gráficamente. Esto se logra usando animación.
Las formas típicas de mostrar el comportamiento simulado usando animación siguen:
- Estado de un recurso con una unidad: El recurso se representa como un objeto gráfico que se asemeja físicamente a lo que modela el recurso. Por ejemplo, si el recurso modela un torno, entonces el objeto parece un torno. Cada estado del recurso corresponde a un color diferente. Por ejemplo, el amarillo corresponde a IDLE, verde a OCUPADO y rojo a BROTO. Los cambios de color durante la animación indican cambios en el estado del recurso en la simulación.
- Entidades: Una entidad se representa en el marco como un objeto gráfico que se asemeja físicamente a lo que modela la entidad. Se pueden usar diferentes colores para diferenciar entidades con diferentes características. Por ejemplo, si hay dos tipos de partes, los objetos gráficos que representan el tipo de pieza 1 pueden ser azules y los que representan el tipo de pieza 2 pueden ser blancos.
- Número de entidades en un búfer: Un objeto gráfico, que puede ser visualmente transparente, representa el búfer. Un objeto gráfico de entidad se coloca en la misma ubicación que el objeto gráfico de búfer cada vez que una entidad se une al búfer en la simulación. El objeto gráfico de búfer acomoda múltiples objetos gráficos de entidades.
- Transporte de material: Cualquier movimiento, como entre estaciones de trabajo, de entidades en la simulación se puede mostrar en la animación. La ubicación de un objeto gráfico de entidad se puede cambiar a una velocidad proporcional a la velocidad o tiempo de duración del movimiento. El movimiento del equipo de manejo de materiales se puede mostrar de manera similar. En cuanto a otros recursos, una pieza de equipo de manejo de materiales está representada por un objeto gráfico que se asemeja a esa pieza de equipo. Por ejemplo, una carretilla elevadora está representada por un objeto gráfico que parece un montacargas.
Una animación de las dos estaciones en un sistema de serie debe ser vista en este momento.