Para una\(N\) secuencia de longitud, el índice de tiempo toma los valores\(n=0,1,2,...,N-1\).
Cuando la longitud de la DFT no es primo, se\(N\) puede factorizar como\(N=N_{1}N_{2}\) y se pueden definir dos nuevas variables independientes sobre los rangos\(n_{1}=0,1,2,...,N_{1}-1\) y\(n_{2}=0,1,2,...,N_{2}-1\).
Se define un cambio lineal de variables que mapea\(n_1\) y\(n_2\) a\(n\) y se expresa por
\[n=((K_{1}n_{1}+K_{2}n_{2}))_{N} \nonumber \]
donde\(K_i\) son enteros y la notación\(((x))_N\) denota el residuo entero del\(x\) módulo\(N\). Este mapa define una relación entre todas las combinaciones posibles den1n1“role="presentation” style="position:relative;” tabindex="0"> \(n_1\)y\(n_2\) como se muestra en las ecuaciones siguientes. La pregunta de si todos los n están representados, es decir, si el mapa es uno a uno (único), ha sido respondida al mostrar que ciertos enteros\(K_i\) siempre existen de tal manera que el mapa en la siguiente ecuación es uno a uno. Se deben considerar dos casos.
Caso 1
\(N_1\)y\(N_2\) son relativamente primos, es decir, el mayor divisor común\((N_{1},N_{2})=1\)
El mapa entero de la ecuación es uno a uno si y solo si:
\[(K_{1}=aN_{2})\; \; and/or\; \; (K_{2}=bN_{1})\; \; and\; \; (K_{1},N_{1})=(K_{2},N_{2})=1 \nonumber \]
donde\(a\) y\(b\) son enteros.
Caso 2
\(N_1\)y no\(N_2\) son relativamente primos, es decir,\((N_{1},N_{2})>1\)
El mapa entero de la ecuación anterior es uno a uno si y solo si:
\[(K_{1}=aN_{2})\; \; and\; \; (K_{2}\neq bN_{1})\; \; and\; \; (a,N_{1})=(K_{2},N_{2})=1 \nonumber \]
o
\[(K_{1}\neq aN_{2})\; \; and\; \; (K_{2}=bN_{1})\; \; and\; \; (K_{1},N_{1})=(b,N_{2})=1 \nonumber \]
A partir de estas condiciones se definen dos clases de mapas de índices.
Mapa de índice tipo uno
El mapa de la ecuación anterior se llama un mapa de tipo uno cuando cuando los enteros a y b existen de tal manera que
\[K_{1}=aN_{2}\; \; and\; \; K_{2}=bN_{1}, \nonumber \]
Mapa de índice de tipo dos
El mapa de la ecuación anterior se llama un mapa de tipo dos cuando cuando existen los enteros a y b de tal manera que
\[K_{1}=aN_{2}\; \; or\; \; K_{2}=bN_{1},\; \; but\; not\; both. \nonumber \]
El tipo uno solo se puede usar si los factores de\(N\) son relativamente primos, pero el tipo dos se puede usar tanto si son relativamente primos como si no. Bien, Thomas y Winograd utilizaron el mapa tipo uno en sus algoritmos DFT. Cooley y Tukey utilizaron el tipo dos en sus algoritmos, tanto para una base fija (\(N=R^M\)) como para una base mixta.
El índice de frecuencia se define por un mapa similar a la ecuación como
\[k=((K_{3}k_{1}+K_{4}k_{2}))_{N} \nonumber \]
donde se utilizan las mismas condiciones para determinar la singularidad de este mapa en términos de los enteros\(K_3\) y\(K_4\)K3K3“role="presentación” style="position:relative;” tabindex="0">.
Las matrices bidimensionales para los datos de entrada y su DFT se definen usando estos mapas de índice para dar
\[\widehat{x}(n_{1},n_{2})=x((K_{1}n_{1}+K_{2}n_{2}))_{N} \nonumber \]
\[\widehat{X}(k_{1},k_{2})=X((K_{3}k_{1}+K_{4}k_{2}))_{N} \nonumber \]
En algunas de las siguientes ecuaciones, se omitirá la notación de reducción de residuos para mayor claridad. Estos cambios de variables aplicados a la definición de la DFT dada en la ecuación en la sección 2.1 dan:
\[C(k)=\sum_{n_{2}=0}^{N_{2}-1}\sum_{n_{1}=0}^{N_{1}-1}x(n)W_{N}^{K_{1}K_{3}n_{1}k_{1}}W_{N}^{K_{1}K_{4}n_{1}k_{2}}W_{N}^{K_{2}K_{3}n_{2}k_{1}}W_{N}^{K_{2}K_{4}n_{2}k_{2}} \nonumber \]
donde se evalúan todos los exponentes módulo\(N\)NN“role="presentación” style="position:relative;” tabindex="0">.
La cantidad de aritmética requerida para calcular la ecuación anterior es la misma que en el cálculo directo de esa ecuación. Sin embargo, debido a la naturaleza especial de la DFT, las constantes enteras\(K_i\) pueden elegirse de tal manera que los cálculos se “desacoplan” y se reduzca la aritmética. Los requisitos para ello son
\[((K_{1}K_{4}))_{N}=0\; \; and/or\; \; ((K_{2}K_{3}))_{N}=0 \nonumber \]
Cuando se aplica esta condición y las de singularidad en la ecuación, se encuentra que el siempre\(K_i\) puede elegirse de tal manera que uno de los términos en la ecuación sea cero. Si los\(N_i\) son relativamente primos, siempre es posible hacer que ambos términos sean cero. Si los no\(N_i\) son relativamente primos, solo uno de los términos se puede establecer en cero. Cuando son relativamente primos, hay una opción, es posible establecer uno o ambos a cero. Esto a su vez hace que uno o ambos de los dos\(W\) términos centrales de la ecuación se conviertan en unidad.
Un ejemplo de la FFT Cooley-Tukey radix-4 para un DFT de longitud 16 usa el mapa tipo dos con
\[K_{1}=4, K_{2}=1, K_{3}=1, K_{4}=4 \nonumber \]
dando
\[n=4n_{1}+n_{2} \nonumber \]
\[k=k_{1}+4k_{2} \nonumber \]
La reducción de residuos en la ecuación no es necesaria aquí ya que n no excede\(N\) como\(n_1\) y\(n_2\) toma sus valores. Dado que, en este ejemplo, los factores de\(N\) tienen un factor común, solo una de las condiciones en la ecuación puede sostenerse y, por lo tanto, la ecuación se convierte en
\[\widehat{C}(k_{1},k_{2})=C(k)=\sum_{n_{2}=0}^{3}\sum_{n_{1}=0}^{3}x(n)W_{4}^{n_{1}k_{1}}W_{16}^{n_{2}k_{1}}W_{4}^{n_{2}k_{2}} \nonumber \]
Tenga en cuenta que la definición de W N en la ecuación permite la forma simple de
W16K1K3=W4W16K1K3=W4“role="presentación” style="position:relative;” tabindex="0"> \[W_{16}^{K_{1}K_{3}}=W_{4} \nonumber \]
Esto tiene la forma de un DFT bidimensional con un término extra\(W_{16}\), llamado “factor de twiddle”. La suma interna sobre\(n_1\) representa cuatro DFT de longitud 4, el\(W_{16}\) término representa 16 multiplicaciones complejas y la suma externa sobre\(n_2\) representa otras cuatro DFT de longitud 4. Esta elección del\(K_i\) “desacopla” los cálculos desde la primera suma sobre\(n_1\) para\(n_2=0\) calcula la DFT de la primera fila de la matriz de datos\(\widehat{x}(n_{1},n_{2})\) y esos valores de datos nunca son necesarios en los cálculos de fila sucesivos. Los cálculos de fila son independientes, y el examen de la suma externa muestra que los cálculos de columna son igualmente independientes. Esto se ilustra en la Fig. 2.2.1 a continuación.
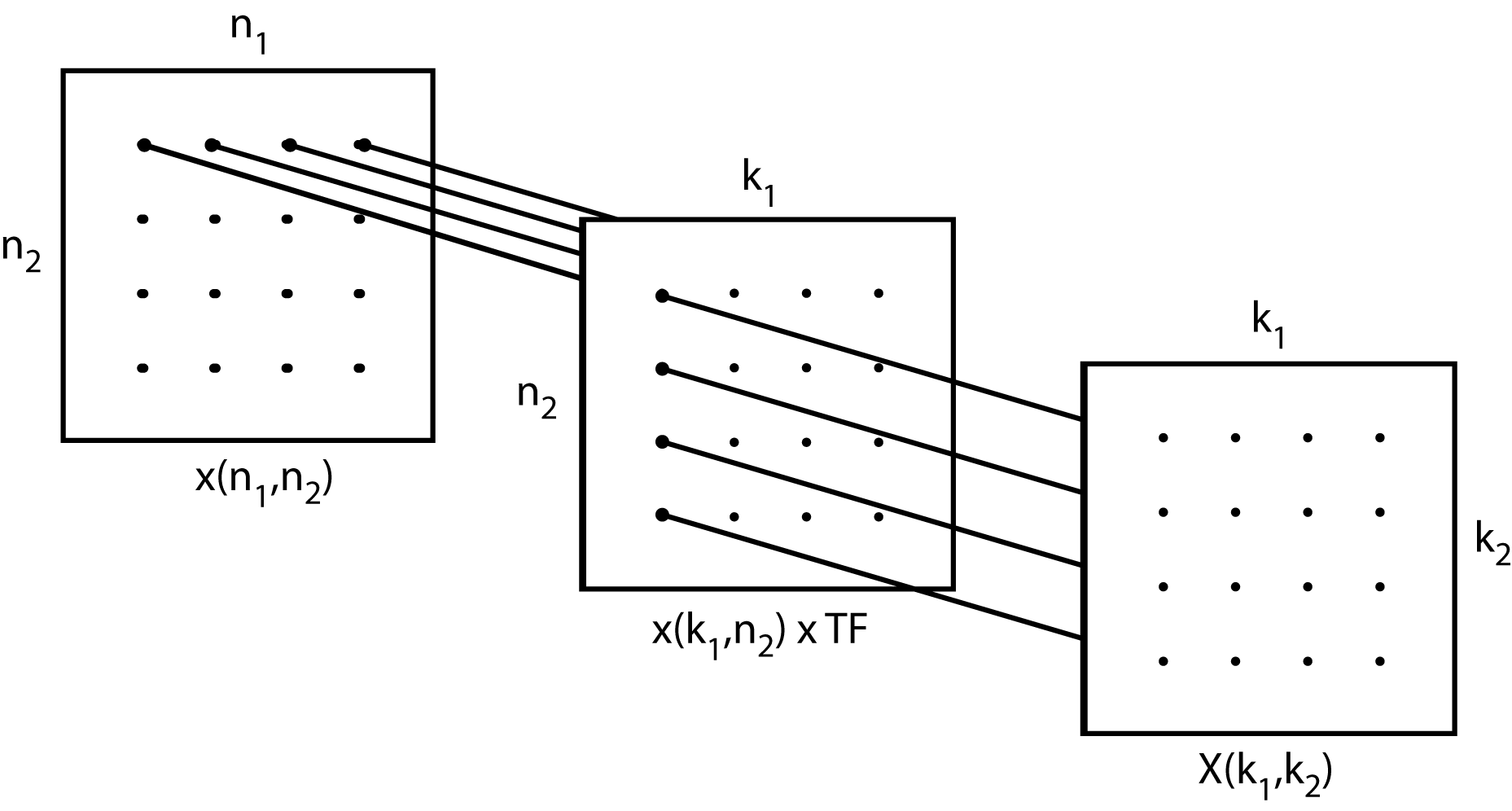
Fig. 2.2.1 Desacoplamiento de los cálculos de filas y columnas (los rectángulos son matrices de datos)
La matriz izquierda de 4 por 4 son los datos de entrada mapeados, la matriz central tiene las filas transformadas y la matriz derecha es la matriz DFT. Las DFT de fila y las DFT de columna son independientes entre sí. Los factores de twiddle (TF) que son el centro W en la ecuación, son las multiplicaciones que tienen lugar en la matriz central de la Fig. 2.2.1.
Esta característica de desacoplamiento reduce la cantidad de aritmética requerida y permite que los resultados de cada DFT de fila se escriban sobre las ubicaciones de datos de entrada, ya que esa fila de entrada no será necesaria nuevamente. Esto se llama cálculo “in place” y da como resultado un gran ahorro de requerimientos de memoria.
Un ejemplo del mapa tipo dos utilizado cuando los factores de\(N\) son relativamente primos se da para\(N=15\) como
\[n=5n_{1}+n_{2} \nonumber \]
\[k=k_{1}+3k_{2} \nonumber \]
La reducción de residuos nuevamente no es explícitamente necesaria. Aunque los factores 3 y 5 son relativamente primos, el uso del mapa tipo dos establece solo uno de los términos de la Ecuación a cero. La DFT en la ecuación se convierte en
\[X=\sum_{n_{2}=0}^{4}\sum_{n_{1}=0}^{2}xW_{3}^{n_{1}k_{1}}W_{15}^{n_{2}k_{1}}W_{5}^{n_{2}k_{2}} \nonumber \]
que tiene la misma forma que la ecuación, incluyendo la existencia de los factores de twiddle (TF). Aquí la suma interna es de cinco DFT de longitud-3, una por cada valor de\(k_1\). Esto se ilustra en la ecuación donde los rectángulos son las matrices de datos de 5 por 3 y el sistema se llama a“role="presentación” style="position:relative;” tabindex="0">base mixta” FFT.
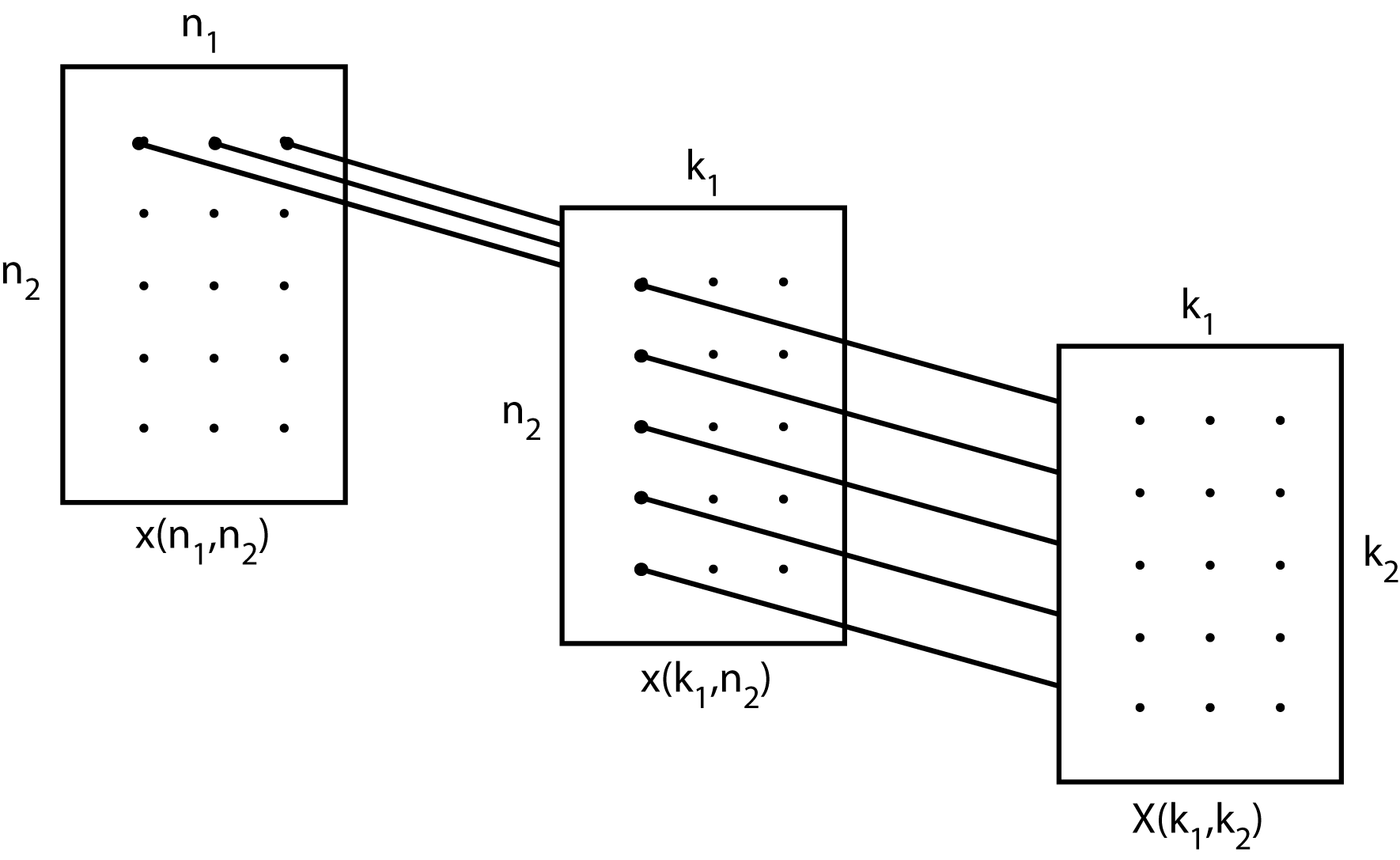
Fig. 2.2.2 Desacoplamiento de los cálculos de filas y columnas (los rectángulos son matrices de datos)
El mapa tipo uno se ilustra a continuación en el mismo ejemplo de longitud-15. Esta vez la situación de la ecuación con la condición “y” se usa en la ecuación usando un mapa de índices de
\[n=5n_{1}+3n_{2} \nonumber \]
y
\[k=10k_{1}+6k_{2} \nonumber \]
Ahora es necesaria la reducción de residuos. Dado que los factores de\(N\) son relativamente primos y se está utilizando el mapa tipo uno, ambos términos en la ecuación son cero, y la ecuación se convierte en
\[\widehat{X}=\sum_{n_{2}=0}^{4}\sum_{n_{1}=0}^{2}\widehat{x}W_{3}^{n_{1}k_{1}}W_{5}^{n_{2}k_{2}} \nonumber \]
que es similar a la ecuación, excepto que ahora el mapa tipo uno da un cálculo puro de DFT bidimensional sin TF, y las sumas se pueden hacer en cualquier orden. las cifras anteriores también describen este caso pero ahora no hay multiplicaciones de Factor Twiddle en el centro y el sistema resultante es llamado a“role="presentación” style="position:relative;” tabindex="0">algoritmo de factor primo” (PFA).
El propósito del mapeo de índices es mejorar la eficiencia aritmética. Por ejemplo, un cálculo directo de un DFT de longitud 16 requiere 16 2 o 256 multiplicaciones reales (recordar, una multiplicación compleja requiere 4 multiplicaciones reales y 2 adiciones reales) y una versión desacoplada requiere 144. Un cálculo directo de un DFT de longitud 15 requiere 225 multiplicaciones pero con un mapa tipo dos solo 135 y con un mapa de tipo uno, 120. Recordar una multiplicación compleja requiere cuatro multiplicaciones reales y dos adiciones reales.
Los algoritmos de interés práctico utilizan DFT cortos que requieren menos de\(N^2\) multiplicaciones. Por ejemplo, las DFT de longitud-4 no requieren multiplicaciones y, por lo tanto, para la DFT longitud-16, solo se deben calcular las TFs. Ese cálculo utiliza 16 multiplicaciones, muchas menos que las 256 o 144 requeridas para el cálculo directo o desacoplado.
El concepto de usar un mapa de índice también se puede aplicar a la convolución para convertir una longitud
\[N=N_{1}N_{2} \nonumber \]
convolución cíclica unidimensional en una convolución cíclica bidimensional N 1 por N 2. No hay ahorros de aritmética del mapeo solo como lo hay con el DFT, pero se pueden obtener ahorros mediante el uso de algoritmos cortos especiales a lo largo de cada dimensión. Esto se discute en Algoritmos para Datos con Restricciones.

