Objetivos de aprendizaje
- Discusión de las consideraciones involucradas en implementaciones FFT de alto rendimiento, que se centran principalmente en el acceso a la memoria y otras preocupaciones no aritméticas, como lo ilustra un estudio de caso de la biblioteca FFTW.
de Steven G. Johnson (Departamento de Matemáticas, Instituto Tecnológico de Massachusetts) y Matteo Frigo (Cilk Arts, Inc.)
Aunque hay una amplia gama de algoritmos de transformada rápida de Fourier (FFT), que involucran una gran cantidad de matemáticas desde la teoría de números hasta álgebras polinomiales, la gran mayoría de las implementaciones FFT en la práctica emplean alguna variación en el algoritmo Cooley-Tukey. El algoritmo Cooley-Tukey se puede derivar en dos o tres líneas de álgebra elemental. Se puede implementar casi con la misma facilidad, especialmente si solo se desean tamaños de potencia de dos; numerosos libros de texto populares enumeran subrutinas FFT cortas para tamaños de potencia de dos, escritas en el lenguaje du jour. Por lo tanto, la implementación del algoritmo Cooley-Tukey, al menos, parecería ser un problema largamente resuelto. En este capítulo, sin embargo, vamos a argumentar que los asuntos no son tan sencillos como podrían parecer.
Durante muchos años, la ruta principal para mejorar la FFT de Cooley-Tukey parecía ser reducciones en el recuento de operaciones aritméticas, que a menudo dominaban el tiempo de ejecución previo a la ubicuidad del hardware de punto flotante rápido (al menos en procesadores no integrados). Por lo tanto, se gastó un gran esfuerzo en encontrar nuevos algoritmos con recuentos aritméticos reducidos, desde el método de Winograd para lograr\(\Theta (n)\) multiplicaciones 1 (a costa de muchas más adiciones) hasta la variante split-radix en Cooley-Tukey que logró durante mucho tiempo el más bajo conocido recuento total de adiciones y multiplicaciones para tamaños de potencia de dos (pero recientemente se mejoró). La cuestión del recuento aritmético mínimo posible sigue siendo de interés teórico fundamental, ni siquiera se sabe si es posible mejor que\(\Theta (n\log n)\) la complejidad, ya queΩ(nregistron)Ω(nregistron)“role="presentation” style="position:relative;” tabindex="0"> los límites \(\Omega (n\log n)\)inferiores en el recuento de adiciones solo han sido probados sujetos a supuestos restrictivos sobre los algoritmos. Sin embargo, la diferencia en el número de operaciones aritméticas, para tamaños de potencia de dos\(n\), entre el algoritmo Cooley-Tukey de 1965 radix-2 (\(\sim 5n\log _2n\)) y el conteo aritmético actualmente más bajo conocido (\(\sim \frac{34}{9}n\log _2n\)) permanece solo alrededor del 25%.
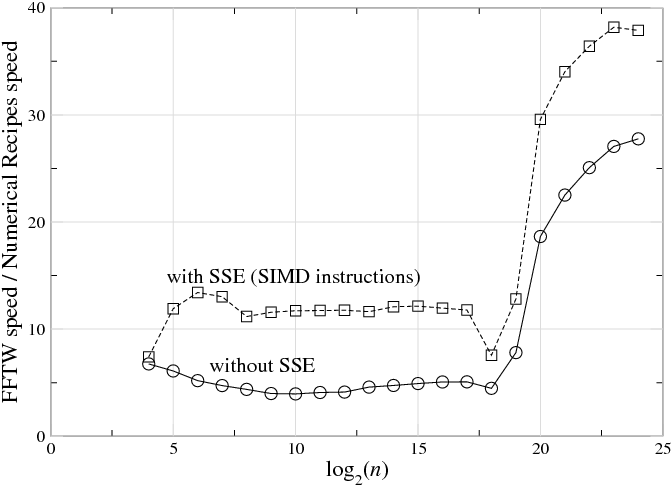
Fig. 10.1.1 La relación de velocidad (1/tiempo) entre una FFT altamente optimizada (FFTW 3.1.2) y una implementación típica de libro de texto radix-2 (Recetas numéricas en C en un Intel Core Duo de 3 GHz con el compilador Intel C 9.1.043, para DFT de datos complejos de precisión única de tamaño nn“role="presentation” style="position:relative;” tabindex="0"> \(n\), trazado versusregistro2nregistro2n“role="presentación” style="position:relative;” tabindex="0"> \(\log _2n\). La línea superior (cuadrados) muestra FFTW con instrucciones SSE SIMD habilitadas, las cuales realizan múltiples operaciones aritméticas a la vez (ver sección); la línea inferior (círculos) muestra FFTW con SSE deshabilitada, lo que requiere un número similar de instrucciones aritméticas al código del libro de texto. (Esto no pretende ser una crítica a las Recetas Numéricas —las implementaciones simples de radix-2 son razonables para la pedagogía— sino que ilustra las diferencias radicales entre implementaciones sencillas y optimizadas de algoritmos FFT, incluso con costos aritméticos similares). Para\(n\underset{\sim }{> }2^{19}\), la relación aumenta porque el código del libro de texto se vuelve mucho más lento (esto sucede cuando el tamaño de DFT excede la caché de nivel 2).
Y, sin embargo, existe una gran brecha entre esta teoría matemática básica y la práctica real: los paquetes FFT altamente optimizados suelen ser un orden de magnitud más rápidos que las subrutinas de los libros de texto, y la estructura interna para lograr este rendimiento es radicalmente diferente del libro de texto típico presentación del “mismo” algoritmo Cooley-Tukey. Por ejemplo, la Fig. 10.1.1 traza la relación de velocidades de referencia entre una FFT altamente optimizada y una implementación típica de radix-2 de libro de texto, y la primera es más rápida en un factor de 5—40 (con una relación mayor comonn“role="presentación” style="position:relative;” tabindex="0"> ncrece). Aquí, consideraremos algunas de las razones de esta discrepancia, y algunas técnicas que pueden ser utilizadas para abordar las dificultades que enfrenta una implementación práctica de FFT de alto rendimiento. 2
En particular, en este capítulo discutiremos algunas de las lecciones aprendidas y las estrategias adoptadas en la biblioteca FFTW. FFTW es una biblioteca de software libre ampliamente utilizada que calcula la transformada discreta de Fourier (DFT) y sus diversos casos especiales. Su rendimiento es competitivo incluso con programas optimizados por el fabricante, y este rendimiento es portátil gracias a la estructura de los algoritmos empleados, las técnicas de autooptimización y los núcleos altamente optimizados (codelets de FFTW) generados por un compilador de propósito especial.
Este capítulo se estructura de la siguiente manera. Primera revisión de la FFT de Cooley-Tukey revisamos brevemente las ideas básicas detrás del algoritmo Cooley-Tukey y definimos alguna terminología común, especialmente enfocándonos en los muchos grados de libertad que el algoritmo abstracto permite a las implementaciones. A continuación, en Objetivos y antecedentes del proyecto FFTW brindamos algún contexto para el desarrollo de FFTW y enfatizamos que el desempeño, si bien recibe la mayor publicidad, no es necesariamente la consideración más importante en la implementación de una biblioteca de este tipo. Tercero, en FFT y la Jerarquía de Memoria consideramos un modelo teórico básico de la jerarquía de memoria de computadora y su impacto en las elecciones de algoritmos FFT: consideraciones bastante generales empujan las implementaciones hacia grandes radices y estructura explícitamente recursiva. Desafortunadamente, las consideraciones generales no son suficientes en sí mismas, por lo que explicaremos en Composición adaptativa de algoritmos FFT cómo FFTW se autooptimiza para máquinas particulares seleccionando su algoritmo en tiempo de ejecución a partir de una composición de simples pasos algorítmicos. Además, Generating Small FFT Kernels describe la utilidad y los principios de generación automática de código utilizados para producir los bloques de construcción altamente optimizados de esta composición, los codelets de FFTW. Finalmente, consideraremos brevemente un importante tema de falta de desempeño, en Precisión numérica en FFT.
Notas al pie
1 Empleamos la notación asintótica estándar de\(O\) para límites superiores asintóticos,\(\Theta\) para límites estrechos asintóticos y\(\Omega\) para límites inferiores asintóticos
2 No abordaremos la cuestión de la paralelización en máquinas multiprocesador, lo que agrega aún mayor dificultad a la implementación de FFT, aunque los multiprocesadores son cada vez más importantes, lograr un buen rendimiento en serie es un requisito previo básico para optimizar el código paralelo, y ya es difícil ¡suficiente!

