
8.4: Algunas relaciones comunes de recurrencia
- Page ID
- 117290

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
En esta sección se pretende examinar una variedad de relaciones de recurrencia que no son lineales de orden finito con coeficientes constantes. Para cada parte de esta sección, consideraremos un ejemplo concreto, presentaremos una solución y, si es posible, examinaremos una forma más general de la relación original.
Primer ejemplo básico
Considerar la relación lineal homogénea de primer orden sin coeficientes constantes,\(S(n) - n S(n - 1) = 0\text{,}\)\(n \geq 1\text{,}\) con condición inicial\(S(0) = 1\text{.}\) Al examinar minuciosamente esta relación, vemos que el término\(n\) th es\(n\) veces el\((n - 1)^{st}\) término, que es una propiedad de\(n\) factorial. \(S(n) = n!\)es una solución de esta relación, por si\(n \geq 1\text{,}\)
\ comenzar {ecuación*} S (n) = n! = n\ cdot (n -1)! = n\ cdot S (n - 1)\ final {ecuación*}
Además, ya que\(0! = 1\text{,}\) se cumple la condición inicial. Cabe señalar que desde un punto de vista computacional, nuestra “solución” realmente no es una gran mejora ya que el cálculo exacto de\(n!\) toma\(n-1\) multiplicaciones.
Si examinamos una relación similar,\(G(k) - 2 ^k G(k - 1),\)\(k\geq 1\) con\(G(0) = 1\text{,}\) una tabla de valores para\(G\) sugiere una posible solución:
\ begin {ecuation*}\ begin {array} {ccccccc} k & 0 & 1 & 2 & 3 & 4 & 5\\ hline G (k) & 1 & 2 & 2 & 2^3 & 2^6 & 2^ {10} & 2^ {15}\\ end {array}\ end {ecuación*}
El exponente de 2 in\(G(k)\) está creciendo de acuerdo a la relación\(E(k) = E(k - 1) + k,\) con\(E(0) = 0\text{.}\) Así\(E(k)=\frac{k(k+1)}{2}\) y\(G(k) = 2^{k(k+1)/2}\text{.}\) Note que también\(G(k)\) podría escribirse en\(2^0 2^1 2^2 \cdots 2^k\text{,}\) cuanto a\(k \geq 0\text{,}\) pero esta no es una expresión de forma cerrada.
En general, la relación\(P(n) = f(n)P(n - 1)\) para\(n \geq 1\) con\(P(0) =f(0)\text{,}\) donde\(f\) es una función que se define para todos\(n\geq 0\text{,}\) tiene la “solución”
Esta forma de producto de no\(P(n)\) es una expresión de forma cerrada porque a medida\(n\) que crece, crece el número de multiplicaciones. Por lo tanto, en realidad no es una verdadera solución. A menudo, como para\(G(k)\) arriba, una expresión de forma cerrada se puede derivar de la forma del producto.
Análisis del Algoritmo de Búsqueda Binaria
Supongamos que tiene la intención de utilizar un algoritmo de búsqueda binaria (ver Subsección 8.1.3) en listas de cero o más elementos ordenados, y que los elementos se almacenan en una matriz, para que tenga fácil acceso a cada elemento. Una pregunta natural para hacer es “¿Cuánto tiempo tomará completar la búsqueda?” Cuando se hace una pregunta como esta, el tiempo al que nos referimos suele ser el llamado peor de los casos. Es decir, si tuviéramos que buscar a través de\(n\) los elementos, ¿cuál es la mayor cantidad de tiempo que necesitaremos para completar la búsqueda? Para realizar un análisis como este independiente de la computadora a utilizar, el tiempo se mide contando el número de pasos que se ejecutan. A cada paso (o secuencia de pasos) se le asigna un tiempo absoluto, o peso; por lo tanto, nuestra respuesta no será en segundos, sino en unidades de tiempo absolutas. Si a los pasos en dos algoritmos diferentes se les asignan pesos que son consistentes, entonces se pueden usar análisis de los algoritmos para comparar sus eficiencias relativas. Hay dos pasos principales que se deben ejecutar en una llamada del algoritmo de búsqueda binaria:
- Si el índice inferior es menor o igual que el índice superior, entonces se ubica el centro de la lista y su clave se compara con el valor que estás buscando.
- En el peor de los casos, el algoritmo debe ejecutarse con una lista que sea aproximadamente la mitad de grande que en la ejecución anterior. Si asumimos que el Paso 1 toma una unidad de tiempo y\(T(n)\) es el peor de los casos para una lista de\(n\) ítems, entonces
\[\label{eq:1}T(n)=1+T(\lfloor n/2 \rfloor),\quad n>0\]
Para simplificar, asumiremos que
\[\label{eq:2} T(0)=0\]
aunque las condiciones del Paso 1 deben ser evaluadas como falso si\(n = 0\text{.}\) Podría preguntarse por qué\(n/2\) se trunca en\(\eqref{eq:1}\). Si\(n\) es impar, entonces\(n = 2 k + 1\) para algunos\(k\geq 0\text{,}\) la mitad de la lista será el\((k + 1)^{st}\) ítem, y no importa a qué mitad de la lista esté dirigida la búsqueda, la lista reducida tendrá\(k = \lfloor n/2\rfloor\) ítems. Por otro lado, si\(n\) es par, entonces\(n = 2 k\) para\(k>0\text{.}\) La mitad de la lista será el\(k^{th}\) ítem, y el peor de los casos ocurrirá si nos dirigen a los\(k\) artículos que vienen después del medio (los\((2k)^{th}\) artículos\((k + 1)^{st}\) a través). Nuevamente la lista reducida tiene\(\lfloor n/2 \rfloor\) ítems.
Solución a\(\eqref{eq:1}\) y\(\eqref{eq:2}\). Para determinar\(T(n)\text{,}\) el caso más fácil es cuando\(n\) es una potencia de dos. Si calculamos\(T \left(2^m\right)\text{,}\)\(m\geq 0\), por iteración, nuestros resultados son
\ begin {ecuación*}\ begin {array} {c} T (1) = 1 + T (0) = 1\\ T (2) = 1 + T (1) = 2\\ T (4) = 1 + T (2) = 3\\ T (8) = 1 + T (4) = 4\\ final {array}\ end {ecuación*}
El patrón que se establece deja claro que\(T\left(2^m\right) = m + 1\text{.}\) Este resultado parecería indicar que cada vez que dupliques el tamaño de tu lista, el tiempo de búsqueda aumenta en una sola unidad.
Se puede obtener una solución más completa si representamos\(n\) en forma binaria. Para cada uno\(n\geq 1\text{,}\) existe un entero no negativo\(r\) tal que
\[2^{r-1}\leq n<2^{r}\]
Por ejemplo, si\(n = 21\text{,}\)\(2^4 \leq 21 < 2^5\text{;}\) por lo tanto,\(r = 5\text{.}\) Si\(n\) satisface (8.4c), su representación binaria requiere\(r\) dígitos. Por ejemplo,\(21_{\text{ten}}\) =\(10101_{\textrm{two}}\text{.}\)
En general,\(n = \left(a_1a_2\ldots a_r\right)_{\textrm{two}}\text{.}\) donde\(a_1=1\text{.}\) Tenga en cuenta que en esta forma,\(\lfloor n/2\rfloor\) es fácil de describir: es el\(r-1\) dígito número binario\(\left(a_1a_2\ldots a_{r-1}\right)_{\textrm{two}}\)
Por lo tanto,
\ begin {ecuation*}\ begin {split} T (n) &= T\ left (a_1a_2\ ldots a_r\ right)\\ & =1+ T\ left (a_1a_2\ ldots a_ {r-1}\ right)\ quad\ & =1+\ left (1+ T\ left (a_1a_2\ ldots a_ {r-2}\ right)\ right)\\ & =2+ T\ izquierda (a_1a_2\ lpuntos a_ {r-2}\ derecha)\\ &\ quad\ vdots\\ & = (r-1) + T\ izquierda (a_1\ derecha)\\ & = (r-1) +1\ quad\ textrm {desde} T (1) =1\\ & = r\ end {dividir}\ texto {.} \ end {ecuación*}
Del patrón que acabamos de establecer, se\(T(n)\) reduce a\(r\text{.}\) Una prueba inductiva formal de esta afirmación es posible. No obstante, esperamos que la mayoría de los lectores quedarían satisfechos con el argumento anterior. Se invita a cualquier escéptico a proporcionar la prueba inductiva.
Para aquellos que prefieren ver un ejemplo numérico, supongamos\(n = 21\text{.}\)
\ begin {ecuación*}\ comenzar {dividir} T (21) &= T (10101)\\ & = 1 + T (1010)\\ & = 1 + (1 + T (101))\\ & = 1 + (1 + (1 + (1 + T (10)))\\ & = 1 + (1 + (1 + (1 + (1 + T (1)))\\ & = 1 + (1 + (1 + (1 + (1 + (1 +T (0)))))\\ & = 5\ end {split}\ end {equation*}
Nuestra conclusión general es que la solución a\(\eqref{eq:1}\) y\(\eqref{eq:2}\) es que para\(n\geq 1\text{,}\)\(T(n) = r\text{,}\) donde\(2^{r-1}\leq n < 2^r\text{.}\)
Una afirmación menos engorrosa de este hecho es que\(T(n)=\left\lfloor \log_{2}n\right\rfloor +1\text{.}\) Por ejemplo,\(T(21) = \left\lfloor \log_2 21\right\rfloor + 1 = 4 + 1 = 5\text{.}\)
Revisión de Logaritmos
Cualquier discusión de logaritmos debe comenzar por establecer una base, que puede ser cualquier número positivo que no sea 1. A excepción del Teorema\(\PageIndex{2}\), nuestra base será 2. Veremos que el uso de una base diferente (10 y\(e\approx 2.171828\) son las otras comunes) sólo tiene el efecto de multiplicar cada logaritmo por una constante. Por lo tanto, la base que usas realmente no es muy importante. Nuestra elección de logaritmos base 2 es conveniente para los problemas que estamos considerando.
Definición\(\PageIndex{1}\): Base 2 Logarithm
El logaritmo base 2 de un número positivo representa un exponente y se define por la siguiente equivalencia para cualquier número real positivo\(a\text{.}\)
\ begin {ecuación*}\ log_2 a = x\ quad\ Leftrightarrow\ quad 2^x= a\ text {.} \ end {ecuación*}
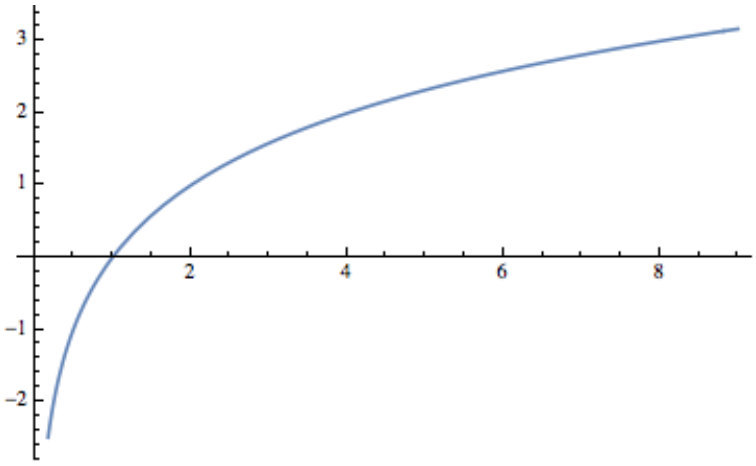 Figura\(\PageIndex{1}\): Gráfica del logaritmo, bases 2, función
Figura\(\PageIndex{1}\): Gráfica del logaritmo, bases 2, funciónPor ejemplo,\(\log_2 8 = 3\) porque\(2^3 = 8\) y\(\log_21.414\approx 0.5\) porque\(2^{0.5}\approx 1.414\text{.}\) Una gráfica de la función\(f(x) = \log_2 x\) en la Figura\(\PageIndex{1}\) muestra que si\(a < b\text{,}\) el es\(\log_2a < \log_2 b\text{;}\) decir, cuando\(x\) aumenta,\(\log_2 x\) también aumenta. No obstante, si pasamos\(x\) de\(2^{10} = 1024\) a\(2^{11} = 2048\text{,}\)\(\log_2 x\) solo aumenta de 10 a 11. Esta lenta tasa de incremento de la función logaritmo es un punto importante a recordar. Un algoritmo que actúa sobre\(n\) piezas de datos que se pueden ejecutar en unidades de\(\log_2{n}\) tiempo puede manejar conjuntos de datos significativamente más grandes que un algoritmo que se puede ejecutar en\(n/100\) o unidades de\(\sqrt{n}\) tiempo. La gráfica de\(T(n)=\left\lfloor \log_2n\right\rfloor +1\) mostraría el mismo comportamiento.
Algunas propiedades más que usaremos en discusiones posteriores que involucran logaritmos se resumen en el siguiente teorema.
Teorema\(\PageIndex{1}\): Fundamental Properties of Logarithms
Dejar\(a\) y\(b\) ser números reales positivos, y\(r\) un número real.
\[\begin{align}\label{eq:4} \log_{2}1&=0 \\ \label{eq:5} \log_{2}ab&=\log_{2}a+\log_{2}b \\ \label{eq:6} \log_{2}\frac{a}{b}&=\log_{2}a-\log_{2}b \\ \label{eq:7}\log_{2}a^{r}&=r\log_{2}a \\ \label{eq:8} 2^{\log_{2}a}&=a\end{align}\]
Definición \(\PageIndex{2}\): Logarithms Base \(b\)
Si\(b > 0\text{,}\)\(b \neq 1\text{,}\) entonces por\(a>0\text{,}\)
\ begin {ecuación*}\ log_b a = x\ Leftrightarrow b^x= a\ end {ecuación*}
Teorema\(\PageIndex{2}\): How Logarithms with Different Bases are Related
Dejar\(b>0\text{,}\)\(b \neq 1\text{.}\) Entonces para todos\(a >0\text{,}\)\(\log_b a = \frac{\log_2a}{\log_2b}\text{.}\) Por lo tanto, si los logaritmos\(b > 1\text{,}\) base b se pueden calcular a partir de logaritmos de base 2 dividiendo por el factor de escalado positivo\(\log_2b\text{.}\) Si\(b < 1\text{,}\) este factor de escalado es negativo.
- Prueba
-
Por un análogo de\(\eqref{eq:8}\), por\(a=b^{\log_b a}\text{.}\) lo tanto, si tomamos el logaritmo base 2 de ambos lados de esta igualdad obtenemos:
\ begin {ecuación*}\ log_2 a =\ log_2\ izquierda (b^ {\ log_b a}\ derecha)\ fila derecha\ log_2 a =\ log_b a\ cdot\ log_2 b\ final {ecuación*}
Por último, dividir ambos lados de la última ecuación por\(\log_2b\text{.}\)
Nota\(\PageIndex{1}\)
\(\log_{2}10 \approx 3.32192\)y\(\log_{2}e \approx 1.4427\text{.}\)
Volviendo al algoritmo de búsqueda binaria, podemos derivar la expresión final para\(T(n)\) usar las propiedades de logaritmos, incluyendo que la función logaritmo está aumentando para que las desigualdades se mantengan al tomar logaritmos de números.
\ begin {ecuation*}\ begin {split} T (n) = r &\ Leftrightarrow 2^ {r-1}\ leq n < 2^r\\ &\ Leftrightarrow\ log_2 2^ {r-1}\ leq\ log_2 n <\ log_2 2^r\ &\ Leftrightarrow r-1\ leq\ log_2 n < r\ &\ Izquierda r-1 =\ lpiso\ log_2 n\ rpiso\\ &\ Izquierda T (n) = r=\ izquierda\ lpiso\ log_2 n\ derecha\ rpiso +1\ end {split}\ end {ecuación*}
Podemos aplicar varias de estas propiedades de logaritmos para obtener una expresión alternativa para\(T(n)\text{:}\)
\ begin {equation*}\ begin {split}\ left\ lfloor\ log_2n\ right\ rfloor +1 &=\ left\ lfloor\ log_2n+1\ right\ rfloor\\ rfloor\\ & =\ left\ lfloor\ log_2n +\ log_22\ right\ rfloor\\ & =\ text {}\ left\ lfloor\ log_22n\ right\ rfloor\ end {split}\ end {ecuación*}
Si se cambia el tiempo que se asignó al Paso 1 del algoritmo de búsqueda binaria, no esperaríamos que la forma de la solución fuera muy diferente. Si\(T(n)= a + T (\lfloor n/2 \rfloor )\) con\(T(0) = c\text{,}\) entonces\(T(n) = c + a \left\lfloor \log_2{2n}\right\rfloor\text{.}\)
Otra generalización sería agregar un coeficiente a\(T(\lfloor n/2 \rfloor )\text{:}\)\(T(n)= a + b T (\lfloor n/2 \rfloor )\) con\(T(0) = c\text{,}\) donde\(a, b, c\in \mathbb{R}\text{,}\) y no\(b\neq 0\) es tan simple de derivar. Primero, si consideramos valores de\(n\) que son potencias de 2:
\ begin {ecuación*}\ begin {array} {c} T (1) = a + b T (0) = a + b c\\ T (2) =a + b (a+b c) = a + a b +c b^2\\ T (4) =a+b\ izquierda (a + a b +c b^2\ derecha) = a + a b + a b^2+ c b^2+ c b^3\\\ vdots\\ T\ izquierda (2^r\ derecha) = a + a b + a b^2+\ cdots + a b^r + c b^ {r+1}\ end {array}\ end {ecuación*}
Si no\(n\) es un poder de 2, por razonamiento que es idéntico a lo que solíamos hacer\(\eqref{eq:1}\) y\(\eqref{eq:2}\),
\ comenzar {ecuación*} T (n) =\ suma_ {k=0} ^r a b^k+ c b^ {r+1}\ final {ecuación*}
donde\(r = \left\lfloor \log_2n\right\rfloor\text{.}\)
El primer término de esta expresión es una suma geométrica, que puede escribirse en forma cerrada. \(x\)Sea esa suma:
\ begin {ecuación*}\ begin {array} {c} x =a + a b + a b^2+\ cdots + a b^r\\ b x=\ textrm {} a b + a b^2+\ cdots + a b^r + a b^ {r+1}\ end {array}\ end {equation*}
Hemos multiplicado cada término de\(x\) por\(b\) y alineado los términos idénticos en\(x\) y\(bx\text{.}\) Ahora si restamos las dos ecuaciones,
\ begin {ecuación*} x - b x = a - a b ^ {r+1}\ Fila derecha x (1-b) = a\ izquierda (1-b^ {r+1}\ derecha)\ final {ecuación*}
Por lo tanto,\(x = a\frac{b^{r+1}-1}{b-1}\text{.}\)
Una expresión de forma cerrada para\(T(n)\) es
\ begin {ecuación*} T (n) = a\ frac {b^ {r+1} -1} {b-1} +\ texto {} c b^ {r+1}\ texto {}\ texto {}\ texto {} r =\ izquierda\ lpiso\ log_2n\ derecho\ rpiso\ texto {}\ final {ecuación*}
Análisis de Burbujas Ordenar y Fusionar Ordenar
La eficiencia de cualquier algoritmo de búsqueda como la búsqueda binaria se basa en el hecho de que la lista de búsqueda se ordena de acuerdo con un valor clave y que la búsqueda se basa en el valor clave. Existen varios métodos para ordenar una lista. Un ejemplo es el tipo burbuja. Puede que estés familiarizado con este ya que es un popular “primer algoritmo de clasificación”. Un análisis de tiempo del algoritmo muestra que si\(B(n)\) es el peor de los casos el tiempo necesario para completar la clasificación de burbujas en\(n\) los ítems, entonces\(B(n) =(n-1) + B(n-1)\) y\(B(1) = 0\text{.}\) La solución de esta relación es una función cuadrática\(B(n) =\frac{1}{2}\left(n^2-n\right)\text{.}\) La tasa de crecimiento de una función cuadrática como esta es controlada por su término cuadrado. Cualquier otro término es empequeñecido por él a medida que\(n\) se hace grande. Para el tipo de burbuja, esto significa que si duplicamos el tamaño de la lista que vamos a ordenar,\(n\) cambia\(2n\) y así\(n^2\) se vuelve\(4n^2\). Por lo tanto, se cuadruplica el tiempo necesario para hacer una ordenación de burbujas. Una alternativa a la ordenación de burbujas es la clasificación por fusión. Aquí hay una versión simple de este algoritmo para ordenar\(F=\{r(1), r(2), \ldots , r(n)\}\text{,}\)\(n \geq 1\text{.}\) Si\(n = 1\text{,}\) la lista está ordenada trivialmente. Si\(n\geq 2\) entonces:
- Dividir\(F\) en\(F_1= \{r(1), \ldots , r(\lfloor n/2\rfloor )\}\) y\(F_2= \{r(\lfloor n/2\rfloor +1), \ldots ,r(n)\}\text{.}\)
- Ordenar\(F_1\) y\(F_2\) usar una clasificación por fusión.
- Fusionar las listas ordenadas\(F_1\) y\(F_2\) en una lista ordenada. Si la clasificación se va a hacer en orden descendente de valores clave, continúa eligiendo el valor clave más alto desde los frentes de\(F_1\)\(F_2\) y colocándolos en la parte posterior de\(F\text{.}\)
Tenga en cuenta que siempre\(F_1\) tendrá\(\lfloor n/2\rfloor\) ítems y\(F_2\) tendrá\(\lceil n/2\rceil\) ítems; así, si\(n\) es impar,\(F_2\) obtiene un ítem más que\(F_1\text{.}\) Supondremos que el tiempo requerido para realizar el Paso 1 del algoritmo es insignificante en comparación con los otros pasos; por lo tanto, nosotros asignará un valor de tiempo de cero a este paso. El paso 3 requiere aproximadamente\(n\) comparaciones y\(n\) movimientos de artículos desde\(F_1\) y\(F_2\) hacia\(F\text{;}\) así, su tiempo es proporcional a\(n\text{.}\) Por esta razón, asumiremos que el Paso 3 toma unidades de\(n\) tiempo. Dado que el paso 2 requiere unidades de\(T(\lfloor n/2\rfloor ) + T(\lceil n/2\rceil )\) tiempo,
\[\label{eq:9} T(n)=n+T(\lfloor n/2 \rfloor )+T(\lceil n/2 \rceil )\]
con la condición inicial
\[\label{eq:10} T(1)=0\]
En lugar de una solución exacta de estas ecuaciones, nos contentaremos con una estimación para\(T(n)\text{.}\) First, considere el caso de\(n=2^r\text{,}\)\(r \geq 1\text{:}\)
\ begin {ecuación*}\ begin {array} {c} T\ izquierda (2^1\ derecha) = T (2) = 2 +T (1) +T (1) = 2 = 1\ cdot 2\ T\ izquierda (2^2\ derecha) = T (4) =4+\ texto {} T (2) +T (2) =8 = 2\ cdot 4\ T\ izquierda (2^3\ derecha) =T (8) =8 + T (4) +T (4) =24=3\ cdot 8\\\ vdots\\ T\ izquierda (2^r\ derecha) =r 2^r= 2^r\ log_2 2^r\ end {array}\ end {ecuación*}
Por lo tanto, si\(n\) es una potencia de 2,\(T(n) = n \log_2 n\text{.}\) Ahora si, para algunos\(r \geq 2\text{,}\)\(2^{r-1}\leq n\leq 2^r\text{,}\) entonces\((r-1)2^{r-1}\leq T(n) < r 2^r\text{.}\) Esto se puede probar por inducción en\(r\text{.}\) As\(n\) aumenta de\(2^{r-1}\) a\(2^r\text{,}\)\(T(n)\) aumenta de\((r-1)2^{r-1}\) a\(r 2^r\) y es ligeramente mayor que\(\left\lfloor n \log_2n\right\rfloor\text{.}\) El la discrepancia es lo suficientemente pequeña como\(\eqref{eq:10}\) para que\(T_e(n)=\left\lfloor n \log _2n\right\rfloor\) pueda considerarse una solución de\(\eqref{eq:9}\) y con el propósito de comparar el orden de fusión con otros algoritmos. La tabla\(\PageIndex{1}\) compara\(B(n)\) con\(T_e(n)\) para los valores seleccionados de\(n\text{.}\)
Tabla\(\PageIndex{1}\): Comparación de tiempos para clasificación de burbujas y clasificación por fusión
| \(n\) | \(B(n)\) | \(T_{e}(n)\) |
|---|---|---|
| \ (n\) ">\(10\) | \ (B (n)\) ">\(45\) | \ (T_ {e} (n)\) ">\(34\) |
| \ (n\) ">\(50\) | \ (B (n)\) ">\(1225\) | \ (T_ {e} (n)\) ">\(283\) |
| \ (n\) ">\(100\) | \ (B (n)\) ">\(4950\) | \ (T_ {e} (n)\) ">\(665\) |
| \ (n\) ">\(500\) | \ (B (n)\) ">\(124750\) | \ (T_ {e} (n)\) ">\(4483\) |
| \ (n\) ">\(1000\) | \ (B (n)\) ">\(499500\) | \ (T_ {e} (n)\) ">\(9966\) |
Desplazamientos
Un desajuste es una permutación en un conjunto que no tiene “puntos fijos”. Aquí hay una definición formal:
Definición\(\PageIndex{3}\): Derangement
Un desorden de un conjunto no vacío\(A\) es una permutación de\(A\) (es decir, una biyección de\(A\) hacia\(A\)) tal que\(f(a)\neq a\) para todos\(a \in A\text{.}\)
Si\(A = \{1, 2, . . . , n\}\text{,}\) una pregunta interesante pudiera ser “Cuantos desórdenes hay de\(A\text{?}\)” Sabemos que nuestra respuesta está delimitada arriba por También\(n!\text{.}\) podemos esperar que nuestra respuesta sea bastante menor que\(n!\) ya que\(n\) es la imagen de sí misma para\((n-1)!\) de las permutaciones de \(A\text{.}\)
\(D(n)\)Sea el número de desórdenes de\(\{1, 2, . . . , n\}\text{.}\) Nuestra respuesta vendrá de descubrir una relación de recurrencia en\(D\text{.}\) Supongamos que\(n \geq 3\text{.}\) Si vamos a construir un desajuste de\(\{1, 2, \dots , n\}\text{,}\)\(f\text{,}\) entonces\(f(n) = k \neq n\text{.}\) Así, la imagen de\(n\) puede ser seleccionada en\(n-1\) diferentes maneras. No importa cuál de las\(n -1\) elecciones tomemos, podemos completar la definición\(f\) de una de dos maneras. Primero, podemos decidir hacer\(f(k) = n\text{,}\) dejando\(D(n -2)\) formas de completar la definición de\(f\text{,}\) ya que\(f\) será un desajuste de\(\{1, 2, \dots ,n\} - \{n, k\}\text{.}\) Segundo, si decidimos seleccionar\(f(k)\neq n\text{,}\) cada uno de los\(D(n - 1)\) descarrilamientos de se\(\{1, 2,\dots ,n-1\}\) puede utilizar para definir\(f\text{.}\) Si \(g\)es un desajuste de\(\{1, 2, \dots , n-1\}\) tal que\(g(p) = k\text{,}\) luego define f por
\ begin {ecuación*} f (j) =\ left\ {\ begin {array} {cc} n &\ textrm {if} j = p\\ k &\ textrm {if} j = n\\ g (j) &\ textrm {de lo contrario}\\ end {array}\ derecha. \ end {ecuación*}
Tenga en cuenta que con nuestra segunda construcción de\(f\text{,}\)\(f(f(n)) = f(k) \neq n\text{,}\) mientras que en la primera construcción,\(f(f(n)) = f(k) = n\text{.}\) Por lo tanto, no se\(f(n) = k\) puede construir ningún desajuste de\(\{1, 2, . . . , n\}\) con ambos métodos.
Para recapitular nuestro resultado, vemos que\(f\) se determina eligiendo primero una de las\(n - 1\) imágenes de\(n\) y luego construyendo el resto de\(f\) una de\(D(n - 2) + D(n -1)\) las maneras. Por lo tanto,
\[\label{eq:11} D(n)=(n-1)(D(n-2)+D(n-1))\]
Esta relación lineal homogénea de segundo orden con coeficientes variables, junto con las condiciones iniciales\(D(1) = 0\) y define\(D(2) = 1\text{,}\) completamente\(D\text{.}\) En lugar de derivar una solución de esta relación por métodos analíticos, daremos una derivación empírica de una aproximación de\(D(n)\text{.}\) Dado que los desajustes de\(\{1,2 . . . , n\}\) se extraen de un charco de\(n!\) permutaciones, veremos qué porcentaje de estas permutaciones son desajustes al enumerar los valores de\(n!\text{,}\)\(D(n)\text{,}\) y\(\frac{D(n)}{n!}\text{.}\) Los resultados que observamos indicarán que a medida que\(n\) crece,\(\frac{D(n)}{n!}\) apenas cambia en absoluto. Si este cociente se calcula a ocho decimales, para\(n \geq 12\text{,}\)\(D(n)/n! = 0.36787944\text{.}\) El recíproco de este número, que\(D(n)/n!\) parece estar tendiendo hacia, es, a ocho lugares, 2.7182818. Este número aparece en tantos lugares de las matemáticas que tiene su propio nombre,\(e\text{.}\) Una solución aproximada de nuestra relación de recurrencia en\(D\) es entonces\(D(n)\approx \frac{n!}{e}\text{.}\)
def D(n):
if n<=2:
return n-1
else:
return (n-1)*(D(n-2)+D(n-1))
list(map(lambda k:[k,D(k),(D(k)/factorial(k)).n(digits=8)],range(1,16)))
Ejercicios
Ejercicio\(\PageIndex{1}\)
Resolver las siguientes relaciones de recurrencia. Indique si su solución es una mejora con respecto a la iteración.
- \(n S(n) - S(n - 1) = 0\text{,}\)\(S(0) = 1\text{.}\)
- \(T(k) + 3k T(k - 1) = 0\text{,}\)\(T(0) = 1\text{.}\)
- \(U(k) -\frac{k-1}{k}U(k - 1) = 0\text{,}\)\(k \geq 2\text{,}\)\(U(1) = 1\text{.}\)
- Contestar
-
- \(S(n)=1/n\text{!}\)
- \(U(k)=1/k\text{,}\)una mejora.
- \(T(k)=(-3)^kk\text{!,}\)ninguna mejora.
Ejercicio\(\PageIndex{2}\)
Demostrar que si\(n \geq 0\text{,}\)\(\lfloor n/2\rfloor +\lceil n/2\rceil = n\text{.}\) (Pista: Considere los casos de\(n\) pares\(n\) e impares por separado.)
Ejercicio\(\PageIndex{3}\)
Resuelve lo más completamente posible:
- \(T(n) = 3 + T(\lfloor n/2\rfloor )\text{,}\)\(T(0) = 0\text{.}\)
- \(T(n) = 1 + \frac{1}{2}T(\lfloor n/2\rfloor )\text{,}\)\(T(0) = 2\text{.}\)
- \(V(n) = 1 + V\lfloor n/8\rfloor )\text{,}\)\(V(0) = 0\text{.}\)(Pista: Escribir\(n\) en forma octal.)
- Contestar
-
- \(\displaystyle T(n)=3\left(\left\lfloor \log_2n\right\rfloor +1\right)\)
- \(\displaystyle T(n)=2\)
- \(\displaystyle V(n)=\left\lfloor \log_8n\right\rfloor +1\)
Ejercicio\(\PageIndex{4}\)
Demostrar por inducción que si\(T(n)= 1 + T (\lfloor n/2 \rfloor )\text{,}\)\(T(0) = 0\text{,}\) y\(2^{r-1}\leq n < 2^r\),\(r \geq 1\text{,}\) entonces\(T(n) = r\text{.}\)
- Pista
-
Demostrar por inducción en\(r\text{.}\)
Ejercicio\(\PageIndex{5}\)
Utilice la sustitución\(S(n) = T(n+1)/T(n)\)\(T(n)T(n-2)=T(n-1)^2\) para resolver\(n \geq 2\text{,}\) con\(T(0) = 1\text{,}\)\(T(1) = 6\text{,}\) y\(T(n) \geq 0\text{.}\)
- Contestar
-
La sustitución indicada rinde\(S(n)=S(n+1)\text{.}\) Desde\(S(0)=T(1)/T(0)=6\text{,}\)\(S(n)=6\) para todos\(n\text{.}\) Por lo tanto\(T(n+1)=6T(n)\Rightarrow T(n)=6^n\text{.}\)
Ejercicio\(\PageIndex{6}\)
Utilice la sustitución\(G(n) =T(n)^2\)\(T(n)^2-T(n-1)^2=1\) para resolver\(n \geq 1\text{,}\) con\(T(0) = 10\text{.}\)
Ejercicio\(\PageIndex{7}\)
Resuelve lo más completamente posible:
- \(Q(n)=1+Q\left(\left\lfloor \sqrt{n}\right\rfloor \right)\text{,}\)\(n \geq 2\text{,}\)\(Q(1) = 0\text{.}\)
- \(R(n)=n +R(\lfloor n/2\rfloor )\text{,}\)\(n \geq 1\text{,}\)\(R(0) = 0\text{.}\)
- Contestar
-
- Una buena aproximación a la solución de esta relación de recurrencia se basa en la siguiente observación:\(n\) es un poder de un poder de dos; es decir,\(n\) es\(2^m\text{,}\) donde\(m=2^k\), entonces\(Q(n)=1+Q\left(2^{m/2}\right)\text{.}\) Al aplicar esta relación de recurrencia los\(k\) tiempos obtenemos\(Q(n)=k\text{.}\) Volviendo a la forma original de\(n\text{,}\)\(\log _2n=2^k\) o\(\log _2\left(\log _2n\right)=k\text{.}\) Esperaríamos que en general,\(Q(n)\) es No\(\left\lfloor \log _2\left(\log _2n\right)\right\rfloor\text{.}\) vemos ningún método elemental para llegar a una solución exacta.
- Supongamos que\(n\) es un entero positivo con\(2^{k-1} \leq n < 2^k\text{.}\) Entonces se\(n\) puede escribir en forma binaria,\(\left(a_{k-1}a_{k-2}\cdots a_2a_1a_0\right)_{\textrm{two}}\) con\(a_{k-1}=1\) y\(R(n)\) es igual a la suma\(\underset{i=0}{\overset{k-1}{\Sigma }}\)\(\left(a_{k-1}a_{k-2}\cdots a_i\right)_{\textrm{two}}\text{.}\) Si\(2^{k-1}\leq n < 2^k\text{,}\) entonces podemos estimar esta suma para que esté entre\(2n-1\) y\(2n+1\text{.}\) Por lo tanto,\(R(n)\approx 2n\text{.}\)
Ejercicio\(\PageIndex{8}\)
Supongamos que el paso 1 del algoritmo de clasificación de fusión tomó una cantidad significativa de tiempo. Supongamos que toma 0.1 unidad de tiempo, independiente del valor de\(n\text{.}\)
- Escribe una nueva relación de recurrencia para\(T(n)\) que tenga en cuenta este factor.
- Resolver para\(T\left(2^r\right)\text{,}\)\(r \geq 0\text{.}\)
- Asumiendo que la solución para potencias de 2 es una buena estimación para todos\(n\text{,}\) compara tu resultado con la solución en el texto. Como se hace grande, ¿realmente hay mucha diferencia?