
6.3: Transformación de valores de datos
- Page ID
- 115087
No es nada inusual que el analista quiera cambiar los valores que describen las relaciones entre actores, o los valores que describen los atributos de los actores. Supongamos que el atributo “género” se había ingresado en un conjunto de datos usando los valores “1" y “2", y queríamos cambiar el atributo para que fuera “Femenino” codificado como “0" y “1". O bien, supongamos que habíamos registrado la fortaleza de los lazos entre las empresas contando el número de miembros de las juntas directivas que tenían en común. Pero entonces decidimos que sólo nos interesa si hay miembros en común o no. Necesitamos cambiar los valores codificados para que sean iguales a “0" si no hay miembros de la junta en común, y “1" si los hay (independientemente de cuántos).
Al igual que los paquetes estadísticos, UCINET tiene herramientas integradas que realizan algunas de las transformaciones de datos más comunes.
Transform>Recode es una herramienta muy flexible y de propósito general para recodificar valores en cualquier estructura de datos UCINET. Su cuadro de diálogo tiene dos pestañas: "Archivos" y "Recodificar”.
En la pestaña Archivos, puede buscar un dataset de entrada, seleccionar qué matrices en el conjunto recodificar (si hay más de una), qué filas y columnas recodificar (esto es bueno si está trabajando en una colección de vectores de atributos, por ejemplo, y solo desea recodificar los seleccionados), ya sea recodificar los valores en la diagonal y el nombre del dataset de salida.
En la pestaña Recodificar, especifica lo que quiere que se haga creando reglas. Por ejemplo, si quisiera recodificar todos los valores 1, 2 y 3 para que fueran cero; y cualquier valor de 4, 5 y 6 para ser uno, crearía dos reglas. “Los valores de 1 a 3 se registran como 0”. “Los valores de 4 a 6 se recodifican como 1”. Las reglas se crean mediante el uso de herramientas integradas simples.
Casi cualquier transformación en un dataset de cualquier complejidad se puede hacer con esta herramienta. Pero, a menudo hay formas más sencillas de hacer ciertas tareas.
Transform>Reverse recodifica los valores de filas, columnas y matrices seleccionadas para que el valor más alto sea ahora el más bajo, el más bajo sea ahora el más alto y todos los demás valores se transformen linealmente. Por ejemplo, el vector 1 3 3 5 6 se convertiría en el vector 6 4 4 2 1.
Si hemos codificado una relación como “fuerza de empate” pero queremos que nuestros resultados sean sobre “debilidad de empate”, sería útil una transformación “inversa”.
Transform>Dicotomize es una herramienta que es útil para convertir datos valorados en datos binarios. Es decir, si hemos medido la fuerza de los lazos entre actores (por ejemplo, en una escala de 0 = sin empate a 5 = empate fuerte), la “dicotomizar” se puede utilizar para convertir esto en datos que representen solo la ausencia o presencia de un empate (por ejemplo, cero o uno).
¿Por qué alguien querría hacer esto? Convertir una medida ordinal o de intervalo de fuerza de relación en presencia/ausencia simple puede desechar cantidades considerables de información. Muchas de las herramientas de análisis de redes sociales fueron desarrolladas para su uso solo con datos binarios, y dan resultados engañosos (¡o ninguno en absoluto!) cuando se aplica a datos valorados. Muchas de las herramientas en UCINET que están diseñadas para datos binarios dicotomizarán arbitrariamente datos de intervalos u ordinales de formas que podrían no ser apropiadas para su problema.
Entonces, si tus datos son valorados, pero la herramienta que quieres usar requiere datos binarios, puedes convertir tus datos en una forma cero-uno seleccionando un valor de corte (también tendrás que seleccionar un “operador de corte” y decidir qué hacer con la diagonal).
Supongamos, por ejemplo, que había medido la fuerza de amarre en una escala de 0 a 3. Me gustaría que los valores 0 y 1 fueran tratados como “0" y los valores 2 y 3 tratados como “1". Seleccionaría “mayor que” como operador de corte, y seleccionaría un valor de corte de “2". El resultado sería una matriz binaria de ceros (cuando las puntuaciones originales eran 0 o 1) y unos (cuando las puntuaciones originales eran 2 o 3).
Esta herramienta puede ser particularmente útil a la hora de examinar los valores de muchas medidas de red. Por ejemplo, la distancia más corta entre dos actores (“distancia geodésica”) podría calcularse y guardarse en un archivo. Entonces podríamos querer mirar un mapa o imagen de los datos a varios niveles de distancia; primero, mostrar solo actores adyacentes (distancia = 1), luego actores que están a uno o dos pasos de distancia, etc. La herramienta “dicotomizar” podría usarse para crear las matrices necesarias.
Transform>Diagonal permite modificar los valores de los vínculos de los actores consigo mismos, o la “diagonal principal” de los conjuntos de datos de red cuadrados. El cuadro de diálogo de esta herramienta permite especificar un único valor que se va a introducir para todas las celdas de la diagonal; o bien, una lista de valores (separados por comas) para cada una de las celdas diagonales (desde el actor uno hasta el último actor listado).
Para muchos análisis de redes, los valores en la diagonal principal no son muy significativos, y es posible que desee ponerlos todos en cero o en uno, que son enfoques bastante comunes. Muchas de las herramientas para calcular medidas de red en UCINET ignorarán automáticamente la diagonal principal, o te preguntarán si incluirla o no.
En algunas ocasiones, sin embargo, es posible que desee estar seguro de que los vínculos de un actor con ellos mismos se tratan como presentes (por ejemplo, establecer valores diagonales a 1), o tratados como ausentes (por ejemplo, establecer valores diagonales a cero).
Transform>Symmetrize es una herramienta que se utiliza para convertir datos de red “dirigidos” o “asimétricos” en datos “no dirigidos” o “simétricos”.
Muchas de las medidas de las propiedades de red calculadas por la UCINET se definen solo para datos simétricos (consulte las pantallas de ayuda para obtener información sobre esto). Si pides calcular una medida que se define solo para datos simétricos, pero tus datos no son simétricos, UCINET o se negará a calcular una medida, o simetrizará los datos por ti.
Pero, hay varias formas de simetrizar los datos, y debe asegurarse de elegir un enfoque que tenga sentido para su problema particular. Las opciones que están disponibles en la herramienta Transform>Symmetrize son:
>Máximo mira cada celda en la parte superior de la matriz y la celda correspondiente en la parte inferior de la matriz (por ejemplo, la celda 2,5 se compara con la celda 5,2), e ingresa el mayor de los valores encontrados en ambas celdas (por ejemplo, 2,5 y 5,2 ahora tendrán el mismo valor de salida). Por ejemplo, supongamos que sentimos que la fuerza del empate entre el actor A y el actor B se representaba mejor como siendo el más fuerte de los lazos entre ellos (ya sea el empate de A con B, o el empate de B con A, lo que fuera más fuerte).
>Mínimo caracteriza la fuerza del empate simétrico entre A y B como el más débil de los lazos AB o BA. Esto corresponde al “eslabón más débil”, y es una opción bastante común.
>Promedio caracteriza la fuerza del empate simétrico entre A y B como el promedio simple de los lazos AB y BA. Honestamente, me cuesta pensar en un caso donde este enfoque tenga mucho sentido para las relaciones sociales.
>Suma caracteriza la fuerza del empate simétrico entre A y B como la suma de AB y BA. Esto sí tiene cierto sentido — que se incluya toda la fuerza del empate, independientemente de la dirección.
>La diferencia caracteriza la fuerza del lazo simétrico entre A y B como |AB - BA|. Entonces, las relaciones que son completamente recíprocas terminan con un valor de cero; las que son completamente asimétricas terminan con un valor igual a la relación más fuerte.
>Producto caracteriza la fuerza de la relación simétrica entre A y B como el producto de AB y BA. Si la reciprocidad es necesaria para que consideremos una relación como “fuerte” entonces ya sea “suma” o “producto” podría ser un enfoque lógico para la simetría.
>La división caracteriza la fuerza de la relación simétrica entre A y B como AB/BA. Este enfoque “penaliza” las relaciones que son igualmente recíprocas, y “premia” las relaciones que son fuertes en una dirección, pero no en la otra.
>Mitad Inferior o >Mitad Superior usa los valores en una mitad de la matriz para la otra mitad. Por ejemplo, el valor de BA se establece igual a lo que sea AB. Esta transformación, aunque pueda parecer extraña al principio, es bastante útil. Si nos interesa enfocarnos en las propiedades de red de “remitentes” elegiríamos establecer la mitad inferior igual a la mitad superior (es decir, seleccionar la mitad superior). Si nos interesara la estructura de recepción de empate, pondríamos la mitad superior igual a la inferior.
>Superior > Inferior o >Superior < Inferior (y funciones similares disponibles en el cuadro de diálogo) comparan los valores en las celdas AB y BA, y devuelven uno u otro en función de la función de prueba. Si, por ejemplo, hubiéramos seleccionado Superior > Inferior y AB = 3 y BA = 5, la función seleccionaría el valor “5", porque el valor superior (AB) no era mayor que el valor inferior (BA).
Transform>Normalizar proporciona una serie de herramientas para reescalar las puntuaciones en filas, en columnas o en ambas dimensiones de una matriz de relaciones valoradas. Un ejemplo sencillo podría ser útil.
En la figura 6.4 se muestran algunos datos (de la base de datos de comercio de productos básicos de las Naciones Unidas) sobre los flujos comerciales, valorados en dólares, de madera de coníferas entre 5 naciones principales de la cuenca del Pacífico a c. 2000.
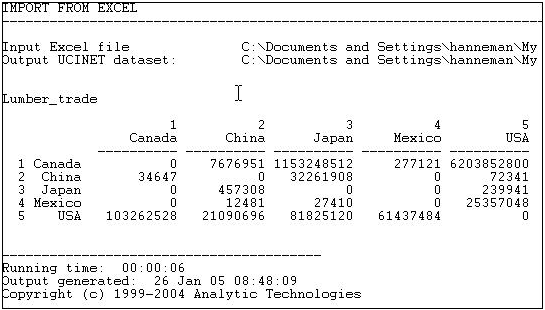
Figura 6.4: Valor de las exportaciones de madera de coníferas en cinco naciones.
Supongamos que estábamos interesados en explorar la estructura de la dependencia de los socios exportadores, la desventaja que podría enfrentar una nación para establecer precios altos cuando tiene pocos lugares alternativos para vender sus productos. Para ello, podríamos optar por “normalizar” los datos expresándolos como porcentajes de filas.Es decir, qué proporción de las exportaciones de Canadá fueron a China, Japón, etc. Usando la rutina de normalización de filas, producimos Figura 6.5.
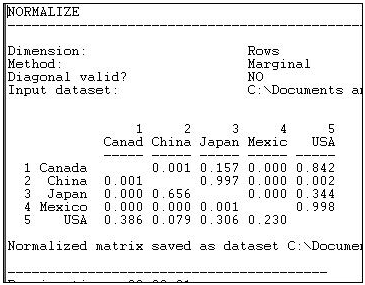
Figura 6.5: Datos normalizados de comercio de madera aserrada por fila (envío o exportación).
Graficar los datos originales del flujo comercial respondería a nuestra pregunta, pero graficar los datos normalizados de fila nos da una imagen mucho más clara de la dependencia de las exportaciones. Si estuviéramos interesados en la concentración comercial de socios de importación, podríamos normalizar los datos por columnas, produciendo la Figura 6.6.
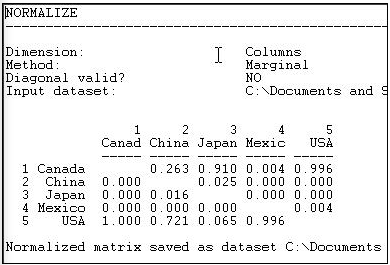
Figura 6.6: Datos normalizados de comercio de madera en columna (recepción o importación).
Vemos, por ejemplo, que todas las importaciones de Canadá son de Estados Unidos, y que prácticamente todas las importaciones de Estados Unidos son de Canadá.
La herramienta >Transform>Normalizar proporciona una serie de formas de volver a escalar los datos que se utilizan con frecuencia.
La normalización puede aplicarse a filas o columnas (como en nuestros ejemplos, anteriores), o puede aplicarse a toda la matriz (por ejemplo, reescalando todos los flujos comerciales como porcentajes de la cantidad total del flujo comercial en toda la matriz). La normalización también se puede aplicar tanto a filas como a columnas, de manera iterativa. Por ejemplo, si quisiéramos un número “promedio” para poner en cada celda de la matriz de flujo de comercio, para que tanto las filas como las columnas se sumaran a\(100\%\), podríamos aplicar el enfoque iterativo de fila y columna. Esto a veces se usa cuando queremos dar “igual peso” a cada nodo, y tomar en cuenta tanto la estructura de salida (fila) como de entrada (columna).
Hay una serie de enfoques alternativos, comúnmente utilizados, sobre cómo reescalar los datos. Nuestros ejemplos utilizan el total “marginal” (fila o columna) y establecen que la suma de las entradas en cada fila (o columna) sea igual a 1.0. Alternativamente, podríamos querer expresar cada entrada relativa a la puntuación media (por ejemplo, dividir cada elemento de la fila por el promedio de los elementos en una fila). Alternativamente, se podría reescalar dividiendo por la desviación estándar, o tanto la media como la desviación estándar (es decir, expresar los elementos como puntuaciones Z). UCINET soporta todos estos como funciones incorporadas. Además, las puntuaciones pueden normalizarse por norma euclidiana, o expresando cada elemento como porcentaje del elemento máximo en una fila.
Volver a escalar transformaciones como estas puede ser muy, muy útil para resaltar las características estructurales de los datos. Pero, obviamente diferentes enfoques normalizantes resaltan rasgos muy diferentes. Intenta pensar en cómo te diría aplicar cada una de las transformaciones disponibles para algunos datos que describen una relación que te interesa. Algunas de las transformaciones serán completamente inútiles; algunas pueden darte algunas ideas nuevas.