
6.6: Realización de nuevos tipos de gráficos a partir de gráficas existentes
- Page ID
- 115070
Convertir atributos en relaciones
Al inicio de este capítulo analizamos las “estructuras de datos” más utilizadas en el análisis de redes. Una fue la matriz cuadrada nodo por nodo, para registrar las relaciones entre pares de actores; y su forma más general de “múltiplex” para registrar múltiples relaciones entre un mismo conjunto de actores. La otra era la matriz rectangular. Esta matriz “actor por atributo” es la más utilizada para registrar información sobre las propiedades variables de cada nodo.
El análisis de redes a menudo encuentra útil ver los atributos de los actores como realmente indicativos de la presencia, ausencia o fuerza de las “relaciones” entre los actores. Supongamos que dos personas tienen el mismo género. Para el analista no de red, esto puede representar una regularidad estadística que describe las frecuencias de las puntuaciones en una variable. Sin embargo, un analista de redes podría interpretar los mismos datos de manera un poco diferente. Un analista de redes podría, en cambio, decir “estas dos personas comparten la relación de tener el mismo género”.
Ambas interpretaciones son, por supuesto, totalmente razonables. Uno enfatiza los atributos de los individuos (aquí hay dos personas, cada una es una mujer); uno enfatiza la relación entre ellos (aquí hay dos personas que se relacionan compartiendo el mismo rol social).
A menudo ocurre que los investigadores de la red, whoa re predispuestos a ver el mundo en términos “relacionales”, quieren convertir los datos de “atributo” en datos “relacionales” para sus análisis.
Data>Attribute es una herramienta que crea una matriz relacional actor por actor a partir de las puntuaciones en un solo vector de atributo. Supongamos que tenemos un vector de atributo almacenado en un archivo UCINET (otros vectores también podrían estar en el archivo, pero este algoritmo opera sobre un solo vector), que midió si cada uno de los 100 grandes donantes habían dado fondos en apoyo de (+1) o en oposición a (-1) una propuesta de boleta dada. Quienes no hicieron ninguna contribución están codificados a cero.
Nos gustaría crear una nueva matriz que identifique a parejas de actores que compartieron apoyo o oposición compartida a la iniciativa de la boleta electoral, o que tomaron posiciones opuestas. Es decir, para cada par de actores, el elemento matriz es “1" si los actores apoyaron conjuntamente o se opusieron conjuntamente a la proposición, “-1" si uno apoyaba y el otro opuesto, y cero en caso contrario (si alguno o ambos no hicieron ninguna contribución).
Usando la herramienta Data>Atributo, podemos formar una nueva matriz cuadrada (actor por actor) a partir de las puntuaciones de actores en un atributo de varias maneras. La elección de Coincidencias exactas producirá un “1" cuando dos actores tengan exactamente la misma puntuación en el atributo, y cero en caso contrario. La elección Diferencia creará una nueva matriz donde los elementos son las diferencias entre las puntuaciones de atributo de cada par de actores (alternativamente, las opciones Diferencia Absoluta o Diferencia Cuadrada producirán medidas valoradas positivamente de la distancia entre las puntuaciones de atributo de cada par de actores). La opción Suma arroja una puntuación para cada par que es igual a la suma de sus puntuaciones de atributo. En nuestro ejemplo actual, la elección de Producto (es decir, multiplicar la partitura del actor i por la puntuación del actor j, e ingresar el resultado) produciría una puntuación de “1" si dos actores compartieran apoyo u oposición, “-1" si tomaran posiciones opuestas sobre el tema, o “0" si alguno de ellos no tomar una posición.
La herramienta Data>Atributo puede ser muy útil para convertir conceptualmente los atributos en relaciones, de manera que se pueda estudiar su asociación con otras relaciones.
Datos>Afiliaciones extiende la idea de convertir atributos en relaciones al caso en el que queremos considerar a múltiples atributos. Probablemente las situaciones más comunes de este tipo son donde los múltiples “atributos” que hemos medido son “medidas repetidas” de algún tipo. Davis, por ejemplo, midió la presencia de varias personas (filas) en varios partidos (atributos o columnas). A partir de estos datos, nos podría interesar la similitud de todas las parejas de actores (¿cuántas veces donde copresentan en un mismo evento?) , o qué tan similares fueron los partidos (¿cuánto de la asistencia de cada par de partidos fueron las mismas personas?).
El ejemplo de los donantes a campañas políticas se puede ver de la misma manera. Podríamos recopilar información sobre si los donantes políticos (filas) habían dado fondos en contra o para varias propuestas de votación diferentes (columnas). A partir de esta matriz rectangular, podríamos estar interesados en formar una matriz cuadrada actor por actor (¿con qué frecuencia a cada par de actores donamos a las mismas campañas?) ; podríamos estar interesados en formar una matriz cuadrada campaña por campaña (¿qué tan similares son las campañas en términos de sus circunscripciones?).
El algoritmo Data>Afiliaciones comienza con una matriz rectangular (actor por afiliado) y le pide que seleccione si la nueva matriz va a estar formada por filas (es decir, actor por actor) o columnas (es decir, atributo por atributo).
Hay diferentes formas en las que podríamos formar las entradas de la nueva matriz. UCINET proporciona dos métodos: Cruz-Productos o Mínimos. Estos enfoques producen el mismo resultado para los datos binarios, pero diferentes resultados para los datos valorados.
Veamos primero el caso binario. Consideremos a dos actores “A” y “B” que hayan hecho contribuciones (o no) a cada una de 5 campañas políticas, como en la Figura 6.7.
| Campaña 1 | Campaña 2 | Campaña 3 | Campaña 4 | Campaña 5 | |
| A | 0 | 0 | 1 | 1 | 1 |
| B | 0 | 1 | 1 | 0 | 1 |
Figura 6.7: Donaciones de dos donantes a cinco campañas políticas (datos binarios)
El método Cross-Products multiplica cada una de las puntuaciones de A por la puntuación correspondiente para B, y luego suma a través de las columnas (si estuviéramos creando una matriz campaña por campaña, la lógica es exactamente la misma, pero operaría multiplicando columnas y sumando entre filas). Aquí, esto da como resultado:\(\left( 0 * 0 \right) + \left( 0 * 1 \right) + \left( 1 * 1 \right) + \left( 1 * 0 \right) + \left( 1 * 1 \right) = 2\). Es decir, los actores A y B tienen dos instancias donde ambos apoyaron una campaña.
El método Mínimos examina las entradas de A y B para la Campaña 1, y selecciona la puntuación más baja (cero). Luego hace esto para las otras campañas (resultando en 0, 1, 0, 1) y sumas. Con los datos binarios, los resultados serán los mismos por cualquiera de los dos métodos.
Con datos valorados, los métodos no producen los mismos resultados; obtienen ideas bastante diferentes.
Supongamos que habíamos medido si A y B apoyaban (+1), no tomaron posición en (0), u opusieron (-1) cada una de las cinco campañas. Este es el dato “valorado” más simple posible, pero las ideas se mantienen para escalas valoradas con rangos más amplios, y con todos los valores positivos, también. Ahora, nuestros datos podrían parecerse a los de la Figura 6.8.
| Campaña 1 | Campaña 2 | Campaña 3 | Campaña 4 | Campaña 5 | |
| A | -1 | 0 | 1 | -1 | 1 |
| B | -1 | 1 | 1 | 0 | -1 |
Figura 6.8: Donaciones de dos donantes a favor o en contra de cinco campañas políticas (datos valorados)
Tanto A como B tomaron la misma posición en dos temas (ambos se opusieron en uno, ambos apoyando a otro). En dos campañas (2, 4), una no tomó posición. En el tema número 5, los dos actores tomaron posiciones opuestas.
El método Cross-Products rinde:\(\left( -1 * -1 \right) + \left( 0 * 1 \right) + \left( 1 * 1 \right) + \left( -1 * 0 \right) + \left( 1 * -1 \right)\). Es decir: 1 + 0 + 1 + 0 + -1, o 1. Los dos actores tienen un acuerdo “neto” de 1 (tomaron la misma posición en dos temas, pero posiciones opuestas en un tema).
El método Mínimos rinde: -1 + 0 + 1 - 1 - 1 o -2. En este ejemplo, esto es difícil de interpretar, pero puede verse como el número neto de veces que cualquiera de los miembros de la pareja se opuso a un tema. El método minimums produce resultados que son más fáciles de interpretar cuando todos los valores son positivos. Supongamos que recodificamos los datos para que sean: 0 = opuesto, 1 = neutro y 2 = favor. El método de mínimos produciría entonces 0 + 1 + 2 + 0 + 0 = 3. Esto podría ser visto como la medida en que la pareja de actores apoyaron conjuntamente las cinco campañas.
Convertir las relaciones en atributos
Supongamos que tenemos una relación dirigida simple, representada como una matriz como en la Figura 6.9.
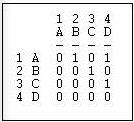
Figura 6.9: Matriz de ejemplo de linegrama
Esto es más fácil de ver como gráfica, como en la Figura 6.10.
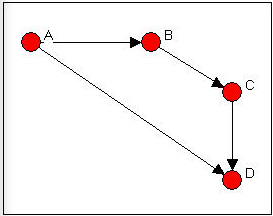
Figura 6.10: Gráfico de ejemplo de linegrama
Ahora supongamos que estamos realmente interesados en describir y pensar sobre las relaciones, y las relaciones entre las relaciones -más que los actores, y las relaciones entre ellos-. Eso suena raro, me doy cuenta. Déjame ponerlo de otra manera. Podemos pensar en la gráfica de la Figura 6.5 compuesta por cuatro relaciones (A a B, B a C, C a D y A a C). Estas relaciones están conectadas al tener actores en común (por ejemplo, las relaciones A a B y B a C tienen al actor B en común). Es decir, podemos pensar en las relaciones como “adyacentes” cuando comparten actores, así como podemos pensar en que los actores son adyacentes cuando comparten relaciones.
Transform>Incidencia es un algoritmo que cambia la forma en que vemos una gráfica dirigida de “actores conectados por relaciones” a “relaciones conectadas por actores”. Esto a veces es sólo un truco semántico. Pero, a veces es más que eso, nuestra teoría de la estructura social puede ser en realidad una sobre qué relaciones están conectadas, no qué actores están conectados. Si aplicamos el algoritmo Transform>Incidencia a los datos de las Figuras 6.4 y 6.5, obtenemos el resultado en la Figura 6.11.

Figura 6.11: Matriz de incidencia de la Figura 6.10
Cada fila es un actor. Cada columna es ahora una relación (las relaciones se numeran del 1 al 4). Una entrada positiva indica que un actor es la fuente de una relación dirigida. Por ejemplo, el actor A es el origen de la relación “1" que conecta A con B, y es una fuente de la relación “2" que conecta al actor A con el actor D. Una entrada negativa indica que un actor es el “sumidero” o receptor de una relación dirigida. Por ejemplo, el actor C es el receptor en relación “3" (que conecta al actor B con el actor C), y la fuente de relación “4" (que conecta al actor C con el actor D).
La matriz de “incidencia” aquí muestra entonces cómo los actores están conectados con las relaciones. Al examinar las filas, podemos caracterizar cuánto, y de qué manera los actores están incrustados en las relaciones. Un actor puede tener pocas entradas - un casi aislado; otro puede tener muchas entradas negativas y pocas positivas - un “tomador” en lugar de un “dador”. Al examinar las columnas, obtenemos una descripción de qué actores están conectados, de qué manera, por cada una de las relaciones en la gráfica.
Centrándose en las relaciones, en lugar de en los actores
Convertir una matriz de adyacencia actor por actor en un gráfico de incidencia actor por relación nos lleva a enfocarnos en las relaciones más que en los actores. Podemos ir más allá.
Transform>Linegraph convierte una matriz actor por actor (como la Figura 6.4) en una matriz completa relación por relación. La Figura 6.12 muestra los resultados de aplicarlo a los datos de ejemplo.
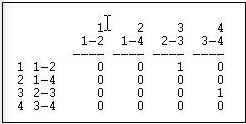
Figura 6.12: Matriz de linegrafía
Nuevamente tenemos una matriz cuadrada. Esta vez, sin embargo, describe qué relaciones en la gráfica son “adyacentes a” qué otras relaciones. Dos relaciones son adyacentes si comparten un actor. Por ejemplo, la relación “1" (el empate entre los actores 1 y 2, o A y B) es adyacente a la relación “3" (el vínculo entre los actores 2 y 3, o B y C). Tenga en cuenta que la “adyacencia” aquí es direccional - la relación 1 es una fuente de relación 3. También podríamos aplicar este enfoque a gráficas simétricas o simples para describir qué relaciones son simplemente adyacentes de manera no dirigida.
Un rápido vistazo a la matriz de linegramas es sugerente. Es muy escaso en este ejemplo -la mayoría de las relaciones no son fuentes de otras relaciones. El grado máximo de cada entrada es 1 - ninguna relación es la fuente de relaciones múltiples. Si bien puede haber un actor clave o central (A), no está tan claro que haya una sola relación central.
Para ser totalmente honestos, la mayoría de los analistas de redes sociales piensan (la mayor parte del tiempo) en actores conectados con actores por relaciones, en lugar de relaciones que conectan actores, o relaciones que conectan relaciones. Pero cambiar nuestro punto de vista para poner las relaciones primero, y los actores en segundo lugar es, en muchos sentidos, una forma más distintivamente “sociológica” de mirar las redes. La transformación de los datos de actor por actor en datos relación por relación puede arrojar algunas ideas interesantes sobre las estructuras sociales.