
17.2: Estructuras de Datos Bipartitas
- Page ID
- 115242
La forma más común de almacenar datos de 2 modos es una matriz de datos rectangular de actores (filas) por eventos (columnas). La Figura 17.1 muestra una parte del conjunto de datos de valor que usaremos aquí (Data>Display).
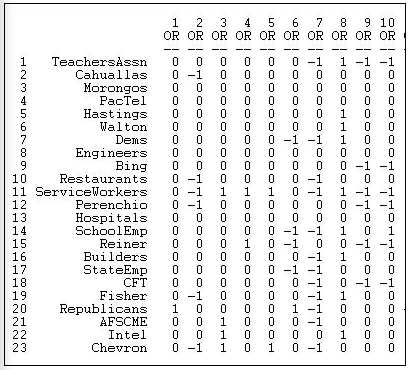
Figura 17.1: Matriz rectangular de datos de donaciones políticas de California
La Asociación de Maestros de California, por ejemplo, dio donaciones en oposición a las iniciativas de la 7ª, 9ª y décima boleta, y una donación de apoyo a la 8ª.
Un enfoque muy común y muy útil para los datos de dos modos es convertirlos en dos conjuntos de datos monomodo y examinar las relaciones dentro de cada modo por separado. Por ejemplo, podríamos crear un conjunto de datos de vínculos actor por actor, midiendo la fuerza del vínculo entre cada par de actores por el número de veces que contribuyeron del mismo lado de las iniciativas, sumado a lo largo de las 40 iniciativas. También podríamos crear un conjunto de datos unimodal de vínculos iniciativa por iniciativa, codificando la fuerza de la relación como el número de donantes que cada par de iniciativas tenía en común. La herramienta Data>Afiliaciones se puede utilizar para crear conjuntos de datos unimodal a partir de una matriz de datos rectangular de dos modos. La Figura 17.2 muestra un cuadro de diálogo típico.
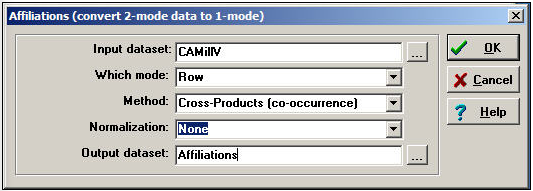
Figura 17.2: Diálogo de Datos>Afiliaciones para crear relaciones actor por actor de donantes de California
Aquí hay varias opciones.
Hemos seleccionado el modo fila (actores) para este ejemplo. Para crear un conjunto de datos unimodal iniciativa por iniciativa, habríamos seleccionado la columna.
Existen dos métodos alternativos:
El método cross-product toma cada entrada de la fila para el actor A, y la multiplica por la misma entrada para el actor B, y luego suma el resultado. Por lo general, este método se utiliza para datos binarios porque el resultado es un recuento de co-ocurrencia. Con datos binarios, cada producto es 1 solo si ambos actores estuvieron “presentes” en el evento, y la suma entre eventos arroja el número de eventos en común, una medida valorada de fortaleza.
Nuestro ejemplo es un poco más complicado porque hemos aplicado el método de productos cruzados a datos valorados. Aquí, si ninguno de los actores donó a una iniciativa (0 * 0 = 0), o si uno donó y el otro no (0 * -1 o 0 * +1 = 0), no hay empate. Si ambos donaron en la misma dirección (-1 * -1 o +1 * +1 = 1), hay empate positivo. Si ambos donaron, pero en direcciones opuestas (+1 * -1 = -1), hay un empate negativo. La suma de los productos cruzados es un recuento valorado de la preponderancia de vínculos positivos o negativos.
El método de mínimos examina las entradas de los dos actores en cada evento y selecciona el valor mínimo. Para los datos binarios, el resultado es el mismo que el método cross-product (si ambos, o cualquiera de los actores es cero, el mínimo es cero; solo si ambos son uno es el mínimo). Para los datos valorados, el método de mínimos es esencialmente decir: el empate entre los dos actores es igual al más débil de los lazos de los dos actores con el evento. Este enfoque se usa comúnmente cuando los datos originales se miden como valorados.
La Figura 17.3 muestra el resultado de aplicar el método de productos cruzados a nuestros datos valorados.
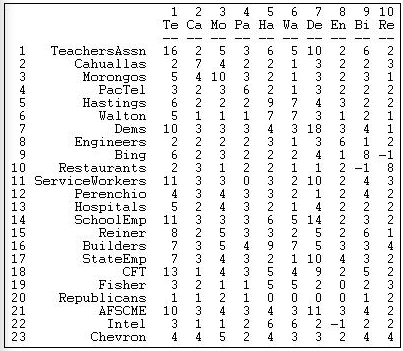
Figura 17.3: Fortalezas de amarre actor por actor (Figura 17.2)
La asociación de profesores participó en 16 campañas (el producto cruzado de la fila cuenta consigo mismo el número de eventos). La asociación tomó la misma posición en temas que el partido Demócrata (actor 7) diez veces más que tomar posición opuesta (o nula). La asociación de restaurantes (nodo 10) tomó una posición opuesta a la del Sr. Bing (nodo 9) con mayor frecuencia que la posición de apoyo (o ninguna). Usando este algoritmo, hemos capturado mucha, pero no toda la información en los datos originales. Una puntuación de -1, por ejemplo, podría ser el resultado de que dos actores tomaran posiciones opuestas en un solo tema; o bien, podría significar que ambos actores tomaron posiciones sobre varios temas -y, en suma, discreparon una vez más de lo que acordaron.
Las matrices unimodales resultantes de actores por actores y eventos por eventos son ahora matrices valoradas que indican la fuerza del empate basado en la co-ocurrencia. Cualquiera de los métodos para el análisis monomodo ahora se puede aplicar a estas matrices para estudiar microestructura o macro estructura.
Los datos de dos modos a veces se almacenan de una segunda forma, llamada matriz “bipartita”. Una matriz bipartita se forma agregando las filas como columnas adicionales y las columnas como filas adicionales. Por ejemplo, una matriz bipartita de los datos de nuestros donantes tendría 68 filas (los 23 actores seguidos de las 45 iniciativas) y 68 columnas (los 23 actores seguidos de las 45 iniciativas). Los dos bloques actor por evento de la matriz son idénticos a la matriz original; los dos nuevos bloques (actores por actores y eventos por eventos) generalmente se codifican como ceros. La herramienta Transform>Bipartite convierte matrices rectangulares de dos modos en matrices bipartitas de dos modos. La Figura 17.4 muestra un diálogo típico.
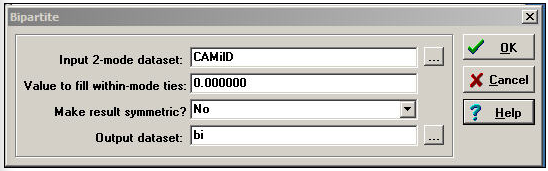
Figura 17.4: Diálogo de Transform>Datos de donaciones políticas bipartitas para California
El valor para llenar los lazos dentro del modo suele ser cero, por lo que los actores están conectados solo por la copresencia en eventos, y los eventos están conectados solo por tener actores en común.
Una vez que los datos se han puesto en forma de matriz bipartita cuadrada, se pueden aplicar muchos de los algoritmos discutidos en otras partes de este texto para datos unimodales. Se necesita considerable precaución en la interpretación, porque la red que se está analizando es una red muy inusual en la que las relaciones son lazos entre nodos en diferentes niveles de análisis. En cierto sentido, los actores y eventos están siendo tratados como objetos sociales en un solo nivel de análisis, y se pueden explorar propiedades como la centralidad y la conexión. Este tipo de análisis es relativamente raro, pero sí tiene algunas posibilidades creativas interesantes.
Más comúnmente, buscamos mantener a los actores y eventos “separados” pero “conectados” y buscar patrones en cómo los actores vinculan los eventos y cómo los eventos vinculan a los actores. Examinaremos algunas técnicas para esta tarea más adelante en este capítulo. Sin embargo, un buen primer paso en cualquier análisis de red es visualizar los datos.