
17.3: Centralidades y Coreness
- Page ID
- 115750
La excentricidad de los nodos discutidos anteriormente se puede utilizar para detectar qué nodos son más centrales en una red. Esto puede ser útil porque, por ejemplo, si envías un mensaje desde uno de los nodos centrales con mínima excentricidad, el mensaje llegará a cada nodo de la red en el menor periodo de tiempo.
Mientras tanto, hay varias otras mediciones más basadas estadísticamente de centralidades de nodos, cada una de las cuales tiene algunos beneficios, dependiendo de la pregunta que se quiera estudiar. Aquí hay un resumen de algunas de esas medidas de centralidad:
Centralidad de grado
\[c_{D}(i) = \frac{deg(i)}{n-1} \label{(17.19)} \]
La centralidad del grado es simplemente un grado de nodo normalizado, es decir, el grado real dividido por el grado máximo posible\((n−1)\). Para las redes dirigidas, puede definir la centralidad en el grado y la centralidad fuera de grado por separado.
Centralidad entre
\[c_{B}(i) =\frac{1}{(n-1)(n-2)} \sum_{j\neq{i}, k \neq{i}, j \neq{k}}{\frac{N_{sp}(j \rightarrow^{i}{k})}{N_{sp}(j \rightarrow {k})}} \label{(17.20)} \]
donde\(N_{sp}(j → k)\) es el número de rutas más cortas de nodo\(j\) a nodo\(k\), y\(N_{sp}(j →^{i}− k)\) es el número de las rutas más cortas de nodo\(j\) a nodo\(k\) que pasan por nodo\(i\). La centralidad entre un nodo es la probabilidad de que la ruta más corta entre dos nodos elegidos aleatoriamente pase por ese nodo. Esta métrica también se puede definir para bordes de una manera similar, lo que se denomina entre bordes.
Centralidad de cercanía
\[C_{c}(i) =( \frac{\sum_{j}{d(i \rightarrow{j})}}{n-1})^{-1} \label{(17.21)} \]
Esta es una inversa de la distancia promedio desde el nodo\(i\) a todos los demás nodos. Si\(c_{C}(i) = 1\), eso significa que puede llegar a cualquier otro nodo desde el nodo\(i\) en un solo paso. Para las redes dirigidas, también se puede definir otra centralidad de cercanía mediante el intercambio\(i\) y\(j\) en la fórmula anterior para medir qué tan accesible\(i\) es el nodo desde otros nodos.
Centralidad Eigenvector
\[c_{E}(i) =v_{i} \qquad{(i-th \ element \ of \ the \ dominant \ eigenvector \ v \ of \ the \ network’s \ adjacency \ matrix)} \label{(17.22)} \]
La centralidad del vector propio mide la “importancia” de cada nodo considerando cada borde entrante al nodo como un “endoso” de su vecino. Esto difiere de la centralidad de grado porque, en el cálculo de la centralidad de los vectores propios, los endosos provenientes de nodos más importantes cuentan como más. Otra interpretación completamente diferente, pero matemáticamente equivalente, de la centralidad de los vectores propios es que cuenta el número de caminatas desde cualquier nodo en la red que llegan al nodo\(i\) en\(t\) pasos, con\(t\) llevado al infinito. Por lo general,\(v\) el vector propio se elige para ser un vector unitario no negativo\((v_{i} ≥ 0,|v| = 1)\).
PageRank
\[c_{P}(i) =v_{i} \qquad{(i-th \ element \ of \ the \ dominant \ eigenvector \ v \ of \ the \ following \ transition \ probability \ matrix)} \label{(17.23)} \]
\[T =\alpha{AD}^{-1} + (1 -\alpha) \frac{J}{n} \label{(17.24)} \]
donde\(A\) está la matriz de adyacencia de la red,\(D^{−1}\) es una matriz diagonal cuyo\(i\) -ésimo componente diagonal es\(1/deg(i)\),\(J\) es una matriz\(n×n\) todo uno, y\(α\) es el parámetro de amortiguación (\(α = 0.85\)se usa comúnmente por defecto).
PageRank es una variación de la centralidad del vector propio que fue desarrollada originalmente por Larry Page y Sergey Brin, los fundadores de Google, a finales de los noventa [74, 75] para clasificar las páginas web. PageRank mide la probabilidad asintótica de que un andador aleatorio en la red esté parado en el nodo\(i\), asumiendo que el andador se mueve a un vecino elegido aleatoriamente con probabilidad\(α\), o salta a cualquier nodo de la red con probabilidad\(1−α\), en cada paso de tiempo. Por lo general, el vector propio v se elige para ser una distribución de probabilidad, es decir,\( \sum_{i} {v_{i}} = 1\).
Obsérvese que todas estas medidas de centralidad dan un valor normalizado entre 0 y 1, donde 1 significa perfectamente central mientras que 0 significa completamente periférico. En la mayoría de los casos, los valores están en algún punto intermedio. Las funciones para calcular estas medidas de centralidad también están disponibles en NetworkX (las salidas se omiten en el código a continuación para ahorrar espacio):

Si bien esas medidas de centralidad suelen estar correlacionadas, capturan diferentes propiedades de cada nodo. Qué centralidad se debe utilizar depende del problema que esté abordando. Por ejemplo, si solo quieres encontrar a la persona más popular en una red social, solo puedes usar la centralidad de grado. Pero si se quiere encontrar a la persona más eficiente para difundir un rumor a toda la red, la centralidad de cercanía probablemente sería una métrica más apropiada de usar. O bien, si quieres encontrar a la persona más efectiva para monitorear y manipular la información que fluye dentro de la red, la centralidad entre las personas sería más apropiada, asumiendo que la información recorre los caminos más cortos entre las personas. La centralidad del vector propio y el PageRank son útiles para generar una clasificación razonable de nodos en una red compleja compuesta por bordes dirigidos.
Visualice la gráfica del Club de Karate utilizando cada una de las medidas de centralidad anteriores para colorear los nodos, y luego comparar las visualizaciones para ver cómo se correlacionan esas centralidades.
Genere (1) una red aleatoria Erd"os-R'enyi, (2) una red zmall-world de Watts-Strogat y (3) una red Barab'asi-Albert sin escalas de tamaño y densidad comparables, y obtenga la distribución de las centralidades de nodo de su elección para cada red. Luego compara esas distribuciones de centralidad para encontrar cuál es más/menos heterogénea.
Demostrar que PageRank con\(α = 1\) es esencialmente lo mismo que el grado de centralidad para redes no dirigidas.
Un enfoque poco diferente para caracterizar la centralidad de los nodos es calcular su coreza. Esto se puede lograr mediante el siguiente algoritmo simple:
1. Vamos\(k = 0\).
2. Elimine repetidamente todos los nodos cuyo grado sea\(k\) o menor, hasta que no existan dichos nodos. A esos nodos eliminados se les da una coreness\(k\).
3. Si aún quedan nodos en la red,\(k\) aumente en 1, y luego vuelva al paso anterior.
La Figura 17.3.1 muestra un ejemplo de este cálculo. Al final del proceso, vemos un clúster de nodos cuyos grados son al menos el valor final de\(k\). A este clúster se le llama\(k\) -core, que puede considerarse la parte central de la red.
En NetworkX, puedes calcular las corenses de los nodos usando la función core_number. Además, el\(k\) -core de la red se puede obtener usando la función k_core. Aquí hay un ejemplo:
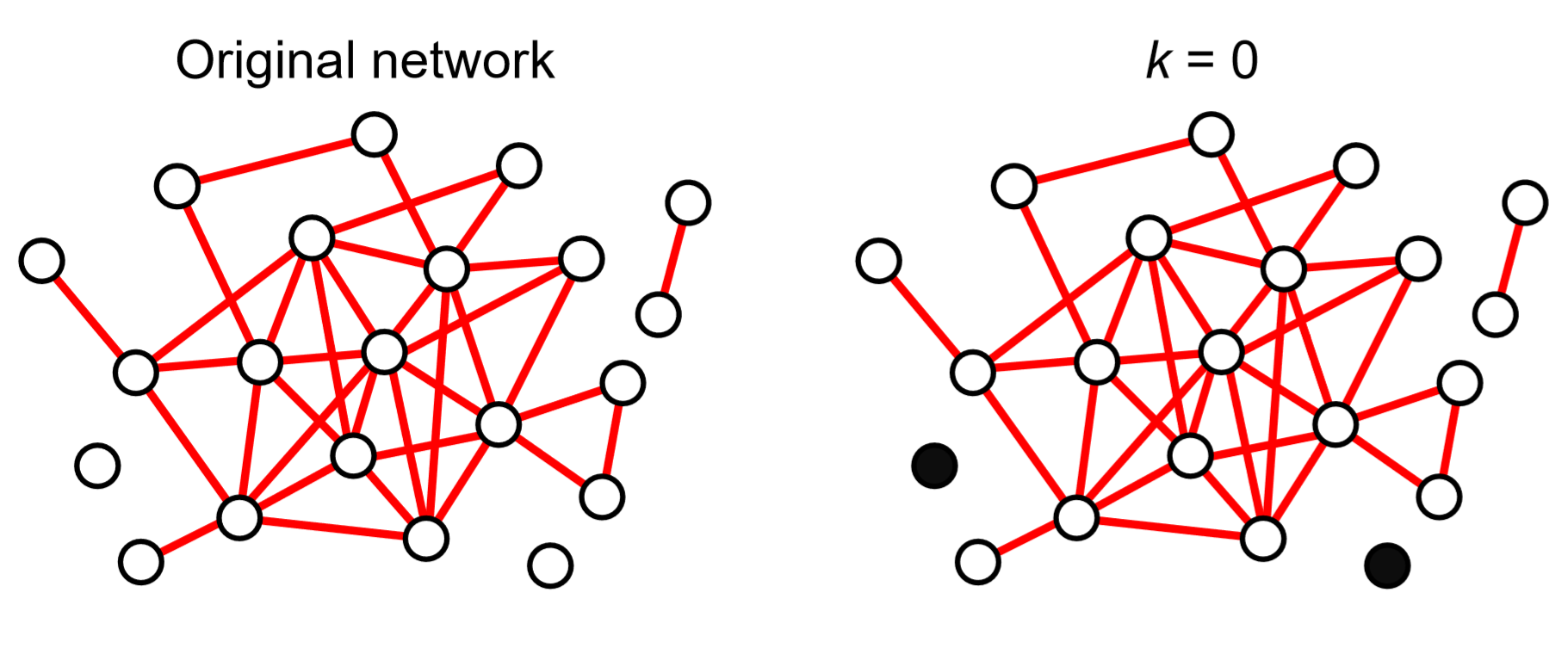
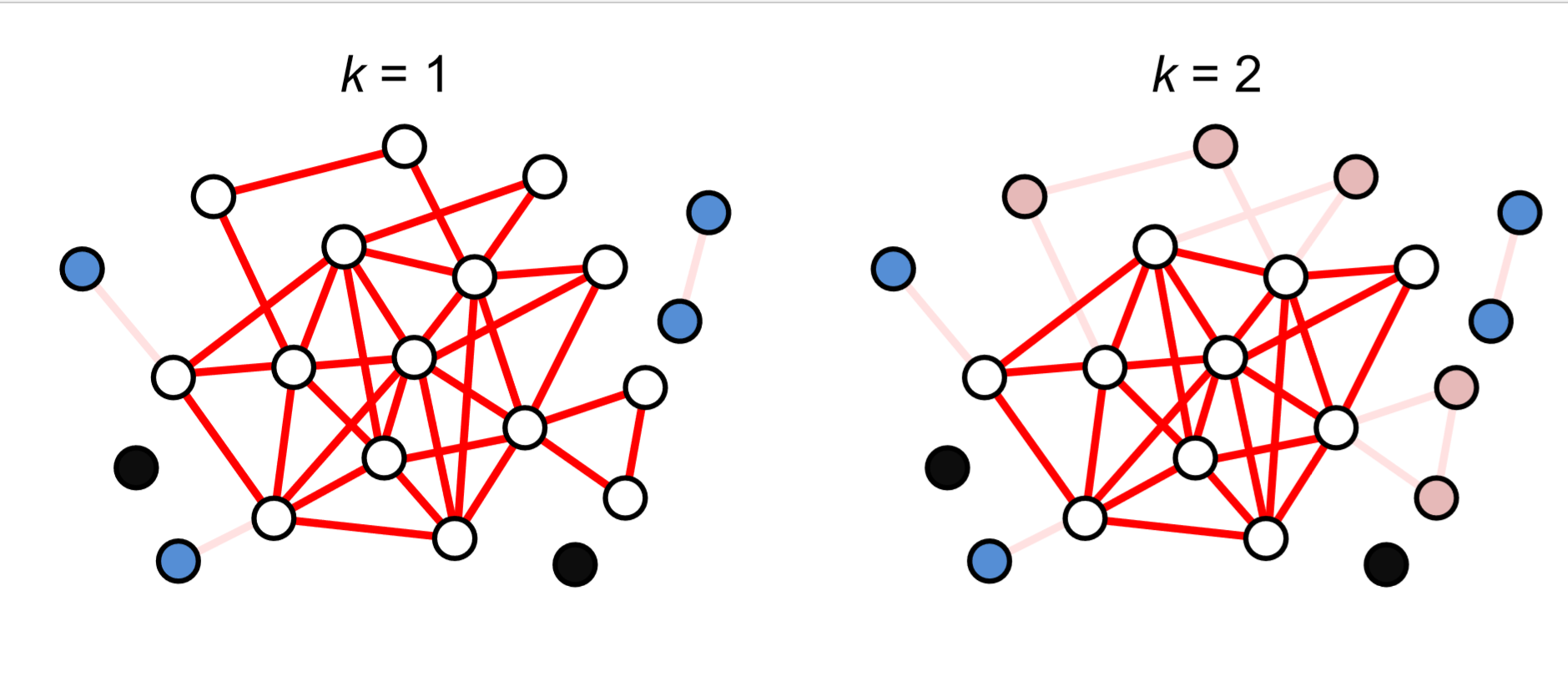
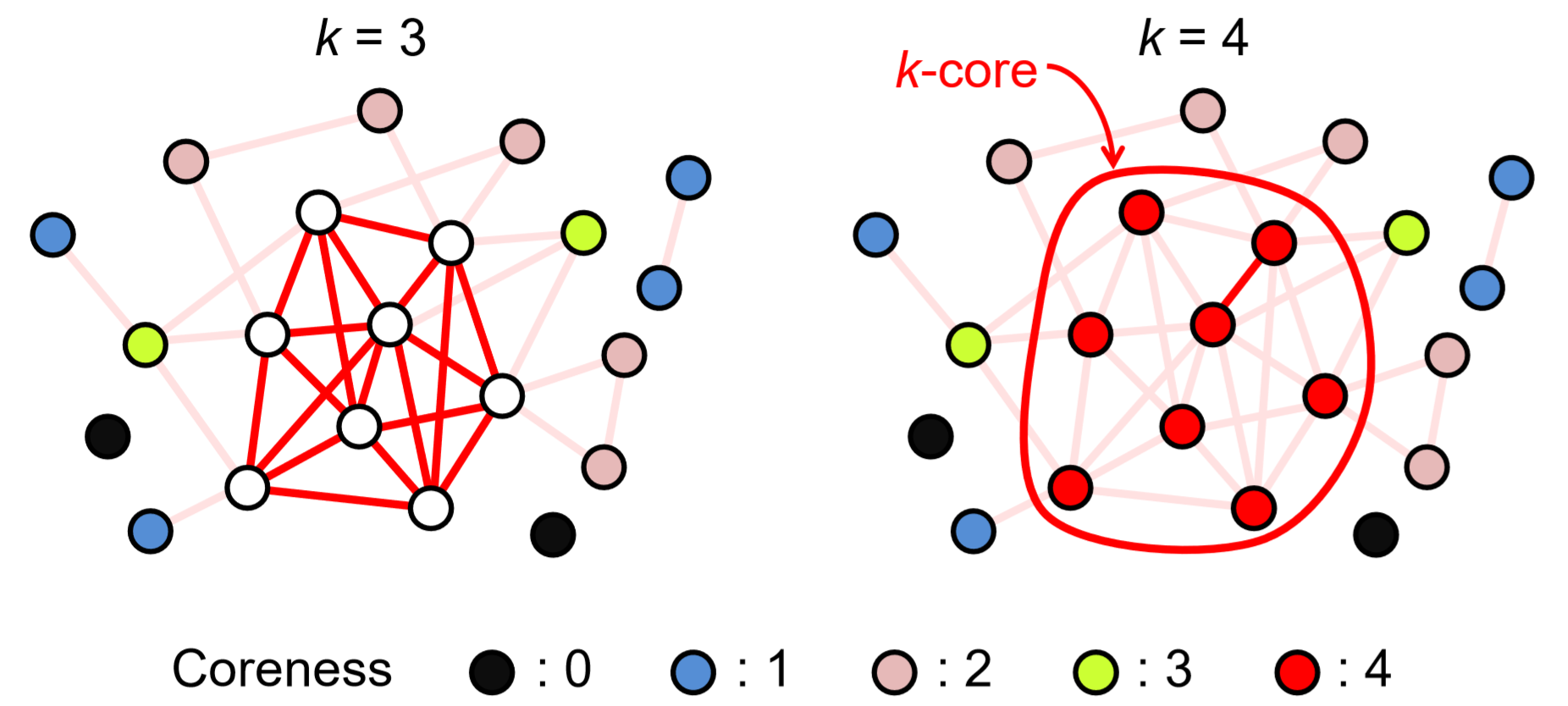

El\(k\) núcleo resultante de la gráfica del Club de Karate se muestra en la Fig. 17.3.2.
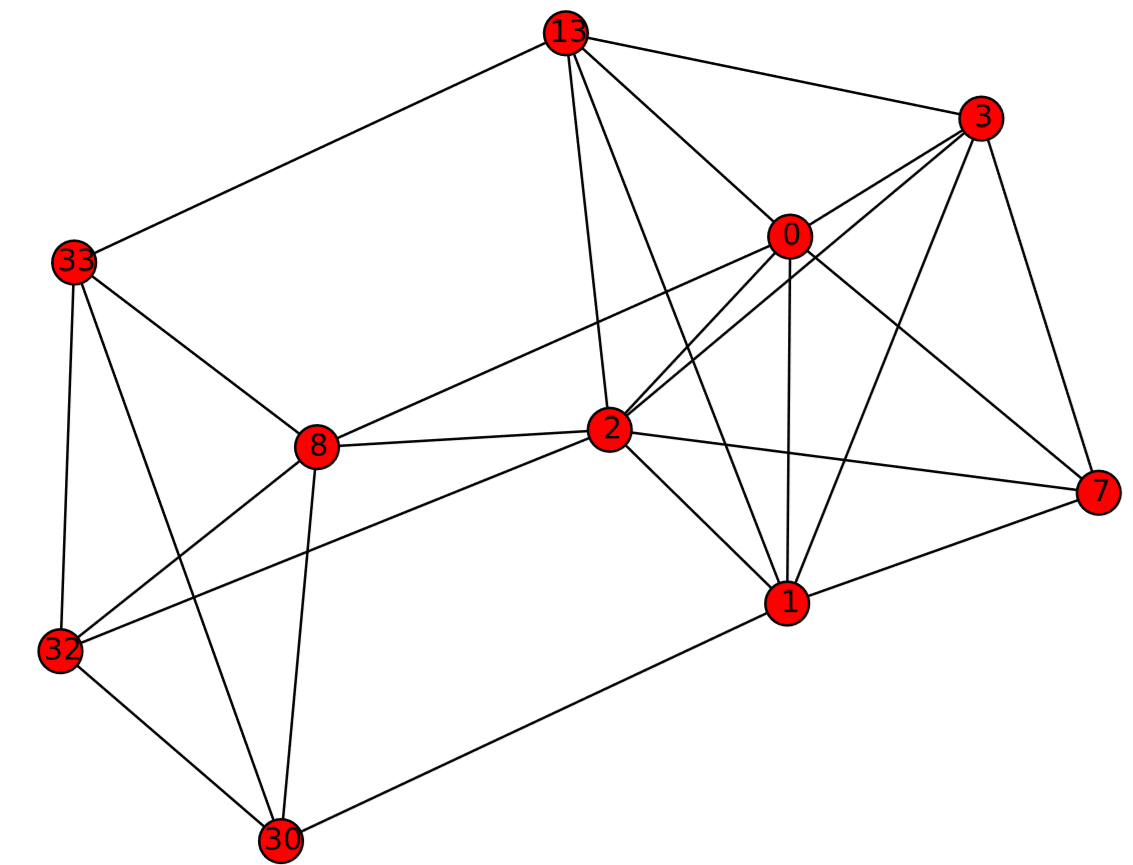
Una ventaja de usar coreness sobre otras medidas de centralidad es su escalabilidad. Debido a que el algoritmo para calcularlo es tan sencillo, el cálculo de la coreness de los nodos en una red muy grande es mucho más rápido que otras medidas de centralidad (a excepción de la centralidad de grado, que obviamente también es muy rápida).
Importe un gran conjunto de datos de red de su elección desde el sitio web de Network Data de Mark Newman: http://www-personal.umich.edu/~mejn/netdata/
Calcular la coreza de todos sus nodos y dibujar su histograma. Comparar la velocidad de cálculo con, digamos, el cálculo de la centralidad entre medias. Visualice también el\(k\) núcleo -core de la red.