
7: Interludio - Recopilación y gestión de datos
- Page ID
- 107781

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Los datos son información. Los datos son el resultado de los esfuerzos de alguien para registrar y almacenar información, a menudo para brindar una oportunidad de información. Se puede utilizar para descubrir patrones, probar hipótesis y apoyar argumentos, entre otras cosas. Pero los propios números a menudo no pueden transmitir mucho significado —es a través de la manipulación e interpretación de los datos que esos usos pueden realizarse. Por lo tanto, debemos ser conscientes de cómo se estructuran y gestionan los datos, para que puedan ser manipulados e interpretados para revelar insights. Si los datos están mal estructurados y gestionados, los riesgos pueden ser grandes. Con optimismo, corremos el riesgo de perder mucho tiempo tratando de reestructurar los datos para permitir el tipo de análisis que deseamos realizar; peor aún, corremos el riesgo de comprometer la integridad o, Dios no lo quiera, la pérdida completa de datos a través de una mala estructuración y mala gestión.
Primero, dejemos claro lo que se entiende por estructura de datos y gestión de datos:
• La estructura de datos se refiere a la organización y disposición de los datos a medida
que se almacenan. Ya sea escrito a mano en cuadernos o almacenado en hojas de cálculo o archivos de texto, los datos suelen tener una arquitectura que refleja las intenciones (o ignorancia) del gestor de datos o algunas veces los protocolos de su organización o institución.
• La gestión de datos es el conjunto de prácticas orientadas a preservar la calidad, integridad y accesibilidad de los datos. Esto puede incluir todas las fases del uso de datos, desde la recopilación y manipulación hasta el almacenamiento, el uso compartido y el archivado.
Hay algunos grandes recursos para la gestión de datos por ahí en diversas formas, incluyendo algunos orientados a los biólogos. Algunos grandes son:
Carpintería de Datos https://www.datacarpentry.org Wickham, H., 2014, Tidy Data. Revista de Software Estadístico 59 (10). Saltz, J.H. y J.M. Stanton, 2017, Introducción a la ciencia de datos, Sage publ.
7.1 ¿Para quién son los datos?
A menos que trabaje con información altamente clasificada o patentada y se le requiera proteger y codificar sus datos, es probable que necesite que los datos sean fácilmente entendidos y utilizables, no solo para usted sino para otros con los que trabaja o para el público en general\(^{1}\). Pero también necesitamos darnos cuenta de que los humanos que necesitan darle sentido a los datos estarán utilizando herramientas como computadoras para facilitar este enfoque. Por lo tanto, la estructura de datos también necesita adaptarse a las demandas del hardware y software de computadora en el que se utiliza, así como de los humanos. Así, los datos deben organizarse de manera lógica, autoconsistente y deben ir acompañados de documentación que ayude a explicar el contenido y contexto de los datos. De igual manera, el archivo de datos accesibles, en principio, permite a colegas y competidores probar, verificar, reproducir y/o comparar resultados con los suyos, asegurando que los avances científicos que usted realice con la ayuda de sus datos también puedan conducir al avance de la ciencia y la gestión de manera más amplia.
\(^{1}\)Muchas agencias gubernamentales de financiamiento como la National Science Foundation, el Departamento de Agricultura de los Estados Unidos y los Institutos Nacionales de Salud requieren ahora que los investigadores desarrollen un plan de gestión de datos que incluya estrategias para estructurar, archivar e indexar datos en repositorios de acceso público .
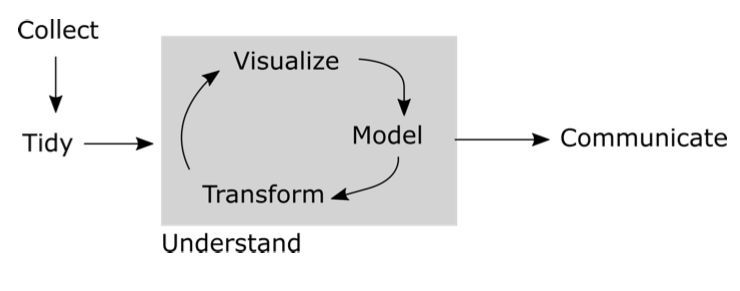
Figura 7.1: Un flujo de trabajo típico para los datos. Después de Grosemund y Wickham, 2017, R para Data Science, O'Reilly.
Considere el flujo de trabajo esquemático ilustrado en la Figura 7.1. Una vez recopilados, los datos deben organizarse y formatearse de manera que facilite su análisis en una computadora. Un término popular para los datos que están formateados para simplificar la manipulación por computadora son los datos ordenados (más sobre esto a continuación). Cuando se completa este proceso, los datos pueden ser analizados según sea necesario para abordar el problema o hipótesis en cuestión. Este proceso de dar sentido a los datos puede entonces producir un resultado que necesita ser comunicado a los humanos. Cuando los datos son presentados por el ojo y el cerebro humanos, la organización y estructura deben reflejar las expectativas y la capacidad de atención de los humanos. A menos que el conjunto de datos sea pequeño, los datos brutos o transformados pueden no ser apropiados para mostrar. En cambio, los datos resumidos son más apropiados, ya sea en formato narrativo, de tabla o gráfico.
7.2 Datos ordenados
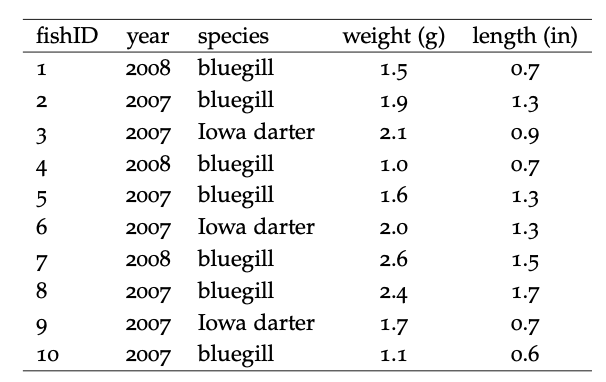
Para entender la importancia del orden, tal vez sea útil considerar datos desordenados o torpes. A continuación se muestra una porción de una tabla de datos que contiene los pesos y longitudes de peces pequeños capturados durante una encuesta poblacional de Inch Lake, Wisconsin. Vamos a desempacar este conjunto de datos. Se enumeran dos especies de peces diferentes, una observada tanto en 2007 como en 2008, y otra solo en 2007. Se proporcionan longitudes y anchos para todos los peces medidos, pero hay diferentes números de

Tabla 7.1: Una porción de un conjunto de datos desordenado.
peces en cada columna. También hay un valor índice en la primera columna que facilita el recuento del número de peces de cada especie capturados en cada año. Esto es razonablemente sencillo para que un humano lo interprete, particularmente si se nos dice que L corresponde a una longitud en pulgadas y W corresponde al peso en gramos. Sin embargo, un conjunto de datos más grande organizado como esta tabla sería miserable de analizar por una variedad de razones, entre ellas:
• las columnas no tienen el mismo número de valores
• la misma especie tiene datos en múltiples columnas
• dos variables (largo y ancho) se listan juntas dentro de cada columna, con números y letras mezcladas
Una pregunta instructiva para hacer es cuántas variables hay aquí. Notamos que los datos abarcan varios años, por lo que el año podría ser una variable. También hay múltiples especies aquí, por lo que las especies podrían verse como una variable. Entonces el largo y el ancho deben ser variables cada uno. Finalmente, si queremos tener un índice o número de identificación para cada pez, esa podría ser una quinta variable\(^{3}\). En general, los datos ordenados se organizan en una matriz rectangular en la que cada columna representa una variable y cada fila una observación. En la mayoría de los casos, la primera fila contiene encabezados de columna descriptivos pero simples. Esta simple receta parece poco amenazante, pero a menudo es sorprendente lo penetrantes que son los datos desordenados.
\(^{3}\)Si hay múltiples conjuntos de datos derivados del mismo grupo de peces, asignar un número de ID de pez sería una forma sencilla de conectar estos conjuntos de datos utilizando métodos de base de datos.
Entonces, con cinco variables, ¿cuántas observaciones tenemos? Cada pez representa una observación, con un número de identificación único, año de captura, especie, peso y longitud. Del Cuadro 7.2, parece haber diez peces listados entre las tres columnas. así ya que cada pez es una observación. De acuerdo con los principios de datos ordenados, entonces, debería haber diez filas de datos con valores en cada una de las cinco columnas. A continuación se muestra una representación ordenada de este conjunto de datos. Esta tabla ahora está organizada de una manera que se puede ordenar, filtrar y resumir fácilmente en estadísticas comunes y paquetes de software computacional.
Los datos ordenados tienen:
• una columna por cada variable
• una fila por cada observación
• una fila de encabezado
7.3 Gestión de datos
Debido a que los datos suelen ser el resultado duramente ganado de observaciones y mediciones costosas y que consumen mucho tiempo, su manejo debe ser deliberado y cuidadoso. Los datos bien administrados se pueden almacenar, recuperar, analizar y utilizar para desarrollar conocimientos o ayudar en las decisiones de gestión sin comprometer los datos en sí, y sin gastar tiempo y energía innecesarios en la decodificación e interpretación de los datos sin procesar. Por lo tanto, una gestión adecuada implica no solo una estructura cuidadosa como se describió anteriormente, sino también un almacenamiento bien organizado y documentación completa.
Cuadro 7.2: Los datos de la Tabla 7.2 se transformaron en un conjunto de datos ordenado.
Primero, los datos sin procesar importantes deben almacenarse de manera redundante. Si solo está en copia impresa (por ejemplo, en cuadernos de campo), considere escanear o transcribir los datos impresos para preservar una versión digital que pueda ser respaldada regularmente. Cuando los datos resultan de investigaciones originales que se pueden compartir, se pueden cargar a los datos Se debe archivar un conjunto completo de datos y nunca modificarse, mientras que la reducción y el análisis de datos se realizan en copias de los datos sin procesar formateados.
\(^{4}\)Los repositorios de datos como el Portal de Datos LTER requieren datos formateados y metadatos para garantizar la accesibilidad a largo plazo y la documentación adecuada.
Cuando el análisis o reducción ocurre mucho más tarde que el tiempo de recolección y almacenamiento, o es realizado por una persona o grupo diferente al investigador que recabó los datos, es esencial la documentación o metadatos adecuados. Los metadatos pueden incluir descripciones narrativas de dónde se recopilaron los datos, cuándo y cómo se recopilaron, y deben incluir referencias o enlaces a cualquier investigación publicada o disponible públicamente o información derivada de los datos. Los metadatos siempre deben incluir un diccionario de datos, describiendo completamente las cantidades representadas por cada una de las variables recopiladas (es decir, nombre de la variable, símbolo, unidades y declaración de procedimiento). Estas pautas garantizan que los datos permanezcan seguros, útiles y accesibles.