
5.7: Determinando estructuras desconocidas
- Page ID
- 2348

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Now it is finally time to put together all that we have studied about NMR, IR, UV-Vis, and MS, and learn how to actually figure out the structure of an organic molecule 'from scratch' - starting, in other words, with nothing but raw experimental data. For this exercise, we will imagine that we have been given a vial containing a pure sample of an unknown organic compound, and that this compound to our knowledge has never before been synthesized, isolated, or characterized - we are the first to get our hands on it. Can we figure out its structure? (In reality, the examples that we use here are well-known compounds - but for now, just play along!).
Before we start analyzing spectroscopic data, we need one very important piece of information about our compound - its molecular formula. This can be determined through the combined use of mass spectrometry and combustion analysis. We will not go into the details of combustion analysis - for now, it is enough to know that this technique tells us the mass percent of each element in the compound. Because molecular oxygen is involved in the combustion reaction, oxygen in the sample is not measured directly - but we assume that if the mass percentages do not add up to 100%, the remainder is accounted for by oxygen.
When we obtain our unknown compound, one of the first things we will do is to send away a small quantity to an analytical company specializing in combustion analysis. They send us back a report stating that our compound is composed, by mass, of 52.0% carbon, 38.3% chlorine, and 9.7% hydrogen. This adds up to 100%, so our compound does not contain any oxygen atoms.
In order to determine the molecular formula of our compound from this data, we first need to know its molar mass. This piece of information, as you recall from chapter 4, we determine by looking at the 'molecular ion peak' in the mass spectrum of our compound. In this example, we find that our MS data shows a molecular ion peak at m/z = 92, giving us a molar mass of 92 g/mole (remember that in the MS experiment, charge (z) is almost always equal to 1, because we are looking at +1 cations).
So, one mole of our compound is 92g. How many moles of carbon atoms are in one mole of the compound? Simple: 52% of 92g is 47.8g. So in one mole of our compound, there is about 48 g of carbon, which means four moles of carbon. With similar calculations, we find that one mole of our compound contains nine hydrogens and one chlorine. Therefore our molecular formula is C4H9Cl. This formula has an index of hydrogen deficiency value (IHD, section 1.3D) of zero, meaning that our compound contains no multiple bonds or rings. We are off to a good start! Now, let's look at the data we get from NMR:
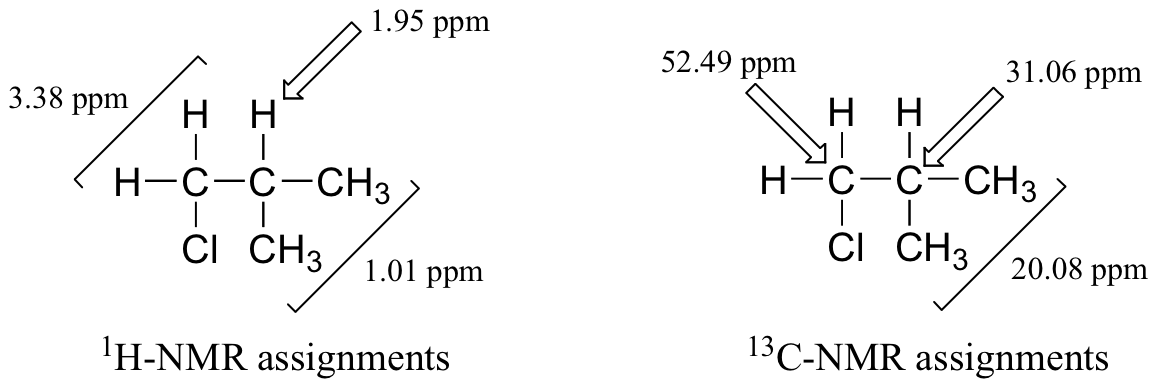
1H-NMR:
3.38 ppm (2H, d, J = 6.13 Hz)
1.95 ppm (1H, m)
1.01 ppm (6H, d, J = 6.57)
In case you can't decipher the above, here's some help. The spectrum contains three signals. The downfield signal, with a chemical shift of 3.38 ppm, integrates to two hydrogens, and is a doublet with a coupling constant of J = 6.13 Hz. The middle signal at 1.95 ppm is a multiplet (meaning we are not trying to analyze the complex splitting pattern), and integrates to one hydrogen. Finally, the upfield signal at 1.01 ppm integrates to six hydrogens, and is a doublet with J = 6.57 Hz). Now, on to the 13C-NMR data:
13C-NMR:
52.49 ppm (CH2)
31.06 ppm (CH)
20.08 ppm (CH3)
The process of piecing together an organic structure is very much like putting together a puzzle. In every case we start the same way, determining the molecular formula and the IHD value. After that, there is no set formula for success- what we need to do is figure out as much as we can about individual pieces of the molecule from the NMR (and often IR, MS, or UV-Vis) data, and write these down. Eventually, hopefully, we will be able to put these pieces together in a way that agrees with all of our empirical data. Let's give it a go.
We see that there are only three signals in each NMR spectrum, but four carbons in the molecule, which tells us that two of the carbons are chemically equivalent. The fact that the signal at 1.01 ppm in the proton spectrum corresponds to six hydrogens strongly suggests that the molecule has two equivalent methyl (CH3) groups. Because this signal is a doublet, there must be a CH carbon bound to each of these two methyl groups. Taken together, this suggests:
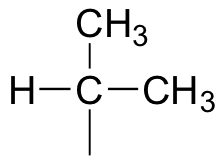
The 1H-NMR signal at 3.38 ppm must be for hydrogens bound to the carbon which is in turn bound to the chlorine (we infer this because this signal is the furthest downfield in the spectrum, due to the deshielding effect of the electronegative chlorine). This signal is for two hydrogens, and is a doublet, meaning that these two hydrogens have a single hydrogen for a neighbor.
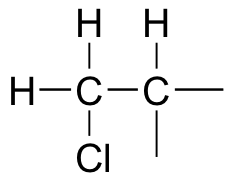
Putting all this together, we get 1-chloro-2-methylpropane.
Congratulations - you've solved your first organic structure!
Exercise 5.15:
Three compounds, both of which have the same combustion analysis results as 1-chloro-2-methylpropane, produce the following NMR data. Assign structures to the three compounds. Integration data has been omitted in order to make the problem more challenging.
Compound A: (2-chloro-2-methylpropane)
1H-NMR: 1.62 ppm (s)
13C NMR: 67.14 ppm (C), 34. 47 ppm (CH3)
| Compound B: (1-chlorobutane) 1H-NMR: 3.42 ppm (t) 1.68 ppm (m) 1.41 ppm (sextet) 0.92 ppm (t) 13C-NMR: 44.74 ppm (CH2) 34.84 ppm (CH2) 20.18 (CH2) 13.34 (CH3) | Compound C: (2-chlorobutane) 1H-NMR: 3.97 ppm (sextet) 1.71 (m) 1.50 (d) 1.02 (t) 13C-NMR: 60.34 ppm (CH) 33.45 (CH2) 24.94 (CH3) 11.08 (CH3) |
Let's try another problem, this time incorporating IR information. The following data was obtained for a pure sample of an unknown organic compound:
Combustion analysis:
C: 85.7%
H: 6.67%
MS: Molecular ion at m/z = 210, base peak at m/z = 167.
1H-NMR:
7.5-7.0 ppm (m, 10H)
5.10 ppm (s, 1H)
2.22 ppm (s, 3H)
13C-NMR:
206.2 (C) 128.7 (CH) 30.0 (CH3)
138.4 (C) 127.2 (CH)
129.0 (CH) 65.0 (CH)
IR: strong absorbance near 1720 cm-1
Our molecular weight is 210, and we can determine from combustion analysis that the molecular formula is C15H14O (the mass percent of oxygen in the compound is assumed to be 100 - 85.7 - 6.67 = 7.6 %). This gives us IHD = 9.
Because we have ten protons with signals in the aromatic region (7.5-7.0 ppm), we are probably dealing with two phenyl groups, each with one substituted carbon.
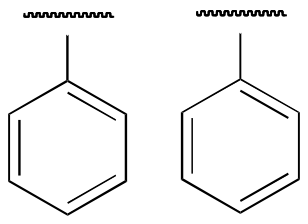
This accounts for 12 carbons, 10 hydrogens, and 8 IHD units. Notice that the carbon spectrum has only six peaks - and only four peaks in the aromatic region! This indicates that the two phenyl groups are equivalent.
The IR spectrum has a characteristic carbonyl absorption band, so that accounts for the oxygen atom in the molecular formula, the one remaining IHD unit, and the 13C-NMR signal at 206.2 ppm.
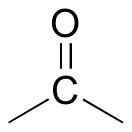
Now we only have two carbons and four hydrogens left to account for. The proton spectrum tells us we have a methyl group (the 2.22 ppm singlet) that is not split by neighboring protons - this chemical shift value is in the range of a methyl group adjacent to a carbonyl.
Finally, there is one last proton at 5.10 ppm, also a singlet. Putting the puzzle together, the only possibility that fits is 1,1-diphenyl-2-propanone:
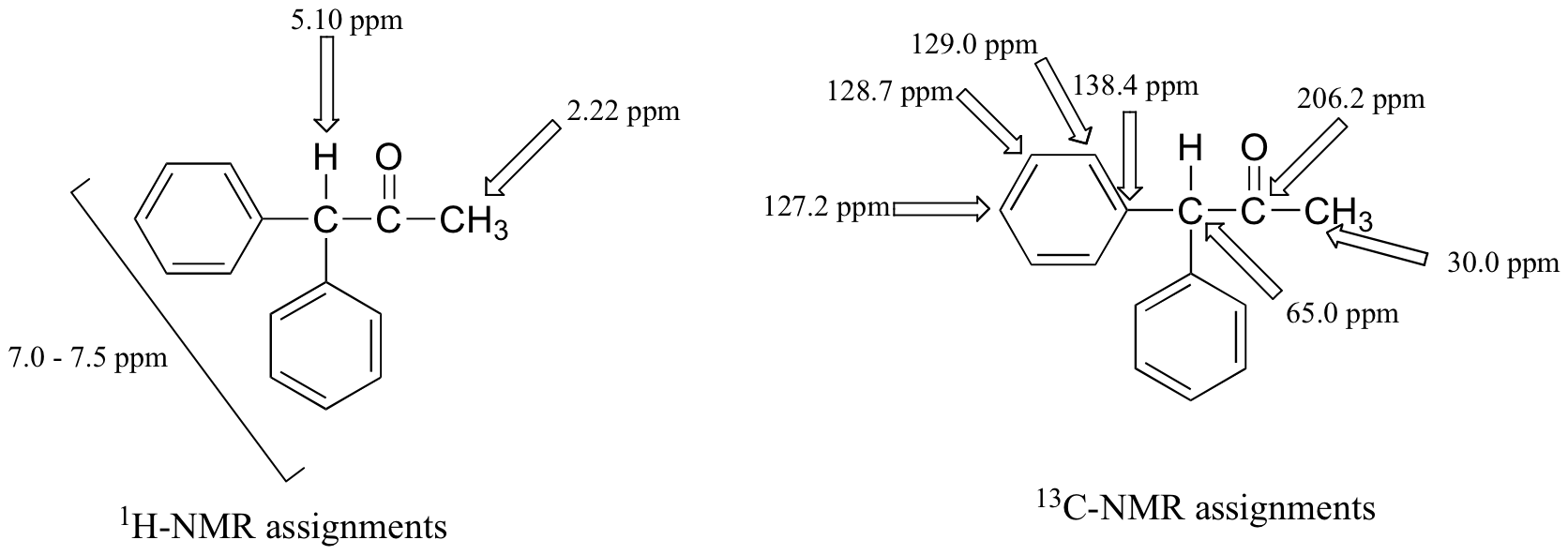
The base peak at m/z = 167 in the mass spectrum comes from loss of the acetyl group (see section 4.4B)

Exercise 5.16: Speculate as to why it is the fragment at m/z = 167 that forms the most abundant (base) peak in the mass spectrum of 1,1-diphenyl-2-propanone.