3.1: Tipos de Visualizaciones
- Page ID
- 69220

Supongamos que queremos estudiar la composición de paquetes de 1.69-oz (47.9-g) de M&Ms lisos. Obtenemos 30 bolsas de M&Ms (diez de cada una de las tres tiendas) y retiramos las M&Ms de cada bolsa una por una, registrando el número de M&Ms azules, marrones, verdes, naranjas, rojas y amarillas. También registramos el número de M&Ms amarillos M&Ms en los primeros cinco caramelos extraídos de cada bolsa, y registrar el peso neto real de los M&Ms en cada bolsa. \(\PageIndex{1}\)En la tabla se resumen los datos recopilados sobre estas muestras. La identificación de la bolsa identifica el orden en que se abrieron y analizaron las bolsas.
| bolsa | tienda | azul | marrón | verde | naranja | rojo | amarillo | Amarillo_First_Cinco | net_weight |
|---|---|---|---|---|---|---|---|---|---|
| 1 | CVS | 3 | 18 | 1 | 5 | 7 | 23 | 2 | 49.287 |
| 2 | CVS | 3 | 14 | 9 | 7 | 8 | 15 | 0 | 48.870 |
| 3 | Target | 4 | 14 | 5 | 10 | 10 | 16 | 1 | 51.250 |
| 4 | Kroger | 3 | 13 | 5 | 4 | 15 | 16 | 0 | 48.692 |
| 5 | Kroger | 3 | 16 | 5 | 7 | 8 | 18 | 1 | 48.777 |
| 6 | Kroger | 2 | 12 | 6 | 10 | 17 | 7 | 1 | 46.405 |
| 7 | CVS | 13 | 11 | 2 | 8 | 6 | 17 | 1 | 49.693 |
| 8 | CVS | 13 | 12 | 7 | 10 | 7 | 8 | 2 | 49.391 |
| 9 | Kroger | 6 | 17 | 5 | 4 | 8 | 16 | 1 | 48.196 |
| 10 | Kroger | 8 | 13 | 2 | 5 | 10 | 17 | 1 | 47.326 |
| 11 | Target | 9 | 20 | 1 | 4 | 12 | 13 | 3 | 50.974 |
| 12 | Target | 11 | 12 | 0 | 8 | 4 | 23 | 0 | 50.081 |
| 13 | CVS | 3 | 15 | 4 | 6 | 14 | 13 | 2 | 47.841 |
| 14 | Kroger | 4 | 17 | 5 | 6 | 14 | 10 | 2 | 48.377 |
| 15 | Kroger | 9 | 13 | 3 | 8 | 14 | 8 | 0 | 47.004 |
| 16 | CVS | 8 | 15 | 1 | 10 | 9 | 15 | 1 | 50.037 |
| 17 | CVS | 10 | 11 | 5 | 10 | 7 | 13 | 2 | 48.599 |
| 18 | Kroger | 1 | 17 | 6 | 7 | 11 | 14 | 1 | 48.625 |
| 19 | Target | 7 | 17 | 2 | 8 | 4 | 18 | 1 | 48.395 |
| 20 | Kroger | 9 | 13 | 1 | 8 | 7 | 22 | 1 | 51.730 |
| 21 | Target | 7 | 17 | 0 | 15 | 4 | 15 | 3 | 50.405 |
| 22 | CVS | 12 | 14 | 4 | 11 | 9 | 5 | 2 | 47.305 |
| 23 | Target | 9 | 19 | 0 | 5 | 12 | 12 | 0 | 49.477 |
| 24 | Target | 5 | 13 | 3 | 4 | 15 | 16 | 0 | 48.027 |
| 25 | CVS | 7 | 13 | 0 | 4 | 15 | 16 | 2 | 48.212 |
| 26 | Target | 6 | 15 | 1 | 13 | 10 | 14 | 1 | 51.682 |
| 27 | CVS | 5 | 17 | 6 | 4 | 8 | 19 | 1 | 50.802 |
| 28 | Kroger | 1 | 21 | 6 | 5 | 10 | 14 | 0 | 49.055 |
| 29 | Target | 4 | 12 | 6 | 5 | 13 | 14 | 2 | 46.577 |
| 30 | Target | 15 | 8 | 9 | 6 | 10 | 8 | 1 | 48.317 |
Habiendo recopilado nuestros datos, los examinamos a continuación en busca de posibles problemas, como valores faltantes (¿Olvidamos registrar el número de M&Ms marrones en alguna de nuestras muestras?) , por errores introducidos cuando registramos los datos (¿El punto decimal se registra incorrectamente para alguno de los pesos netos?) , o por resultados inusuales (¿Es realmente el caso de que esta bolsa solo tenga M&M de color amarillo?). También examinamos nuestros datos para identificar observaciones interesantes que tal vez deseemos explorar (Parece que la mayoría de los pesos netos son mayores que el peso neto enumerado en los paquetes individuales. ¿Por qué podría ser esto? ¿La diferencia es significativa?) Cuando nuestro conjunto de datos es pequeño generalmente podemos identificar posibles problemas y observaciones interesantes sin mucha dificultad; sin embargo, para un conjunto de datos grande, esto se convierte en un desafío. En lugar de tratar de examinar los valores individuales, podemos ver nuestros resultados visualmente. Si bien puede ser difícil encontrar un punto de datos único e impar cuando tenemos que revisar individualmente 1000 muestras, a menudo salta cuando miramos los datos usando uno o más de los enfoques que exploraremos en este capítulo.
Gráficas de puntos
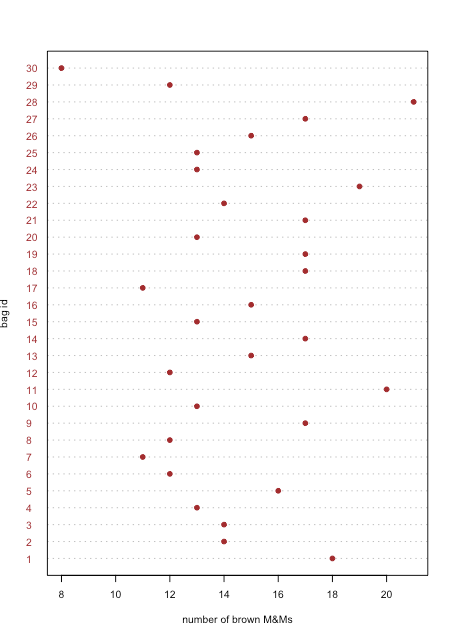
Una gráfica de puntos muestra datos para una variable, con el valor de cada muestra trazado en el eje x. Los puntos individuales se organizan a lo largo del eje y con la primera muestra en la parte inferior y la última muestra en la parte superior. La figura\(\PageIndex{1}\) muestra una gráfica de puntos para el número de M&Ms marrones en las 30 bolsas de M&Ms de Table\(\PageIndex{1}\). La distribución de puntos aparece aleatoria ya que no existe correlación entre el id de muestra y el número de M&Ms marrones. Nos sorprendería que descubriéramos que los puntos estaban dispuestos de la parte inferior izquierda a la parte superior derecha ya que esto implica que el orden en que abrimos las bolsas determina si éstas tienen muchos o unos pocos M&Ms marrones.
Gráficos de franjas
Una gráfica de puntos proporciona una manera rápida de darnos la confianza de que nuestros datos están libres de patrones inusuales, pero a costa del espacio porque usamos el eje y para incluir el id de muestra como variable. Un gráfico de tiras usa el mismo eje x que una gráfica de puntos, pero no usa el eje y para distinguir entre muestras. Debido a que todas las muestras con el mismo número de M&Ms marrones aparecerán en el mismo lugar, haciendo imposible distinguirlas unas de otras, apilamos los puntos verticalmente para extenderlos, como se muestra en la Figura\(\PageIndex{2}\).
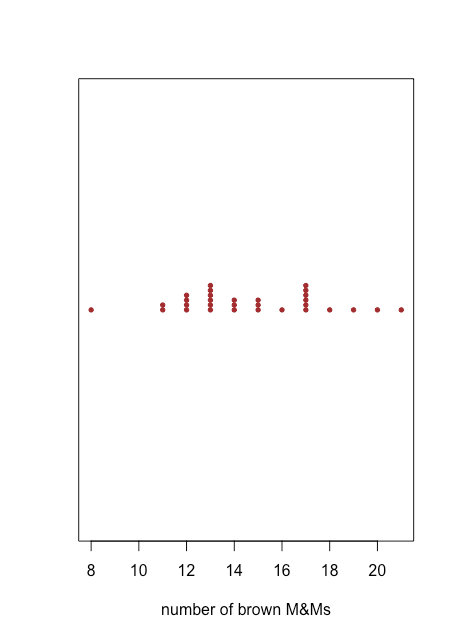
Tanto la gráfica de puntos en la Figura\(\PageIndex{1}\) como la gráfica de tiras en la Figura\(\PageIndex{2}\) sugieren que hay una menor densidad de puntos en el límite inferior y el límite superior de nuestros resultados. Vemos, por ejemplo, que solo hay una bolsa cada una con 8, 16, 18, 19, 20 y 21 M&Ms marrones, pero hay seis bolsas cada una con 13 y 17 M&Ms marrones.
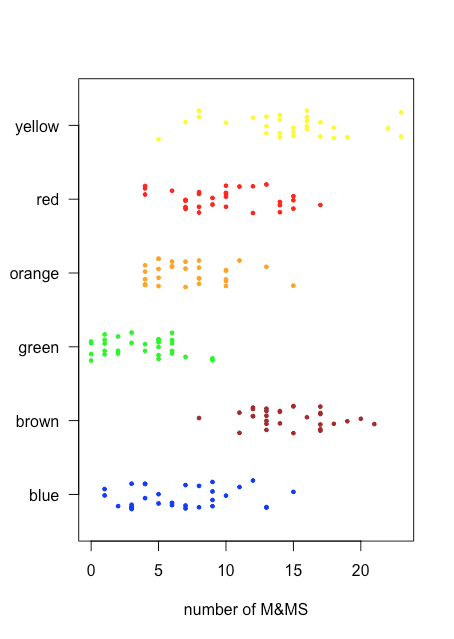
Debido a que un gráfico de tiras no utiliza el eje y para proporcionar información categórica significativa, podemos mostrar fácilmente varios diagramas de tira a la vez. La figura\(\PageIndex{3}\) muestra esto para los datos de la Tabla\(\PageIndex{1}\). En lugar de apilar los puntos individuales, los fluctuamos aplicando un pequeño desplazamiento aleatorio a cada punto. Entre las cosas que aprendemos de este stripchart están que solo las M&Ms marrones y amarillas tienen recuentos superiores a 20 y que solo las M&Ms azules y verdes tienen recuentos de tres o menos M&Ms.
Parcelas de Caja y Bigotes
El diagrama de franjas en la Figura\(\PageIndex{3}\) es fácil de examinar porque el número de muestras, 30 bolsas y el número de M&Ms por bolsa es lo suficientemente pequeño como para que podamos ver los puntos individuales. A medida que aumenta la densidad de puntos, un diagrama de franjas se vuelve menos útil. Una gráfica de caja y bigotes proporciona una vista similar pero se enfoca en los datos en términos del rango de valores que abarcan el 50% medio de los datos.
En la figura se\(\PageIndex{4}\) muestra la gráfica de caja y bigotes para M&Ms marrones usando los datos de la Tabla\(\PageIndex{1}\). Las 30 muestras individuales se superponen como un diagrama de franjas. La caja central divide el eje x en tres regiones: bolsas con menos de 13 M&Ms marrones (siete muestras), bolsas con entre 13 y 17 M&Ms marrones (19 muestras) y bolsas con más de 17 M&Ms marrones (cuatro muestras). Los límites de la caja están establecidos para que incluya al menos el 50% medio de nuestros datos. En este caso, la caja contiene 19 de las 30 muestras (63%) de las bolsas, ya que al mover cualquiera de los extremos de la caja hacia el centro se obtiene una caja que incluye menos del 50% de las muestras. La diferencia entre el límite superior de la caja (19) y su límite inferior (13) se denomina rango intercuartílico (IQR). La línea gruesa en el cuadro es la mediana, o valor medio (más sobre esto y el IQR en el siguiente capítulo). Las líneas discontinuas en cada extremo de la caja se llaman bigotes, y se extienden hasta el resultado más grande o menor que se encuentra dentro\(\pm 1.5 \times \text{IQR}\) del borde derecho o izquierdo de la caja, respectivamente.
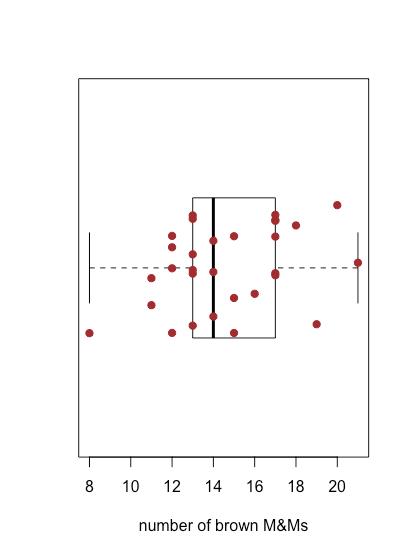
Debido a que una gráfica de caja y bigotes no utiliza el eje y para proporcionar información categórica significativa, podemos mostrar fácilmente varias parcelas en el mismo marco. La figura\(\PageIndex{5}\) muestra esto para los datos de la Tabla\(\PageIndex{1}\). Tenga en cuenta que cuando un valor cae fuera de un bigote, como es el caso aquí para las M&Ms amarillas, se marca mostrándolo como un círculo abierto.
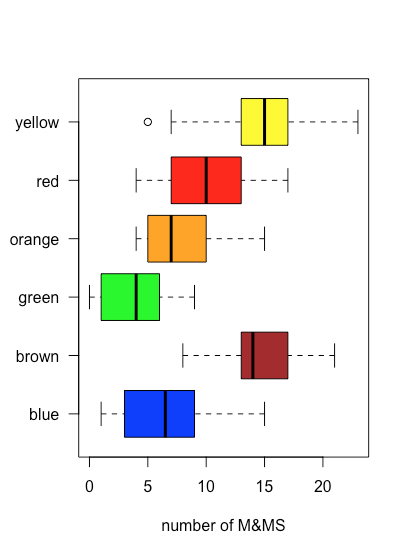
Un uso de una gráfica de caja y bigotes es examinar la distribución de las muestras individuales, particularmente con respecto a la simetría. A excepción de la muestra única que cae fuera de los bigotes, la distribución de M&Ms amarillos aparece simétrica: la mediana está cerca del centro de la caja y los bigotes se extienden por igual en ambas direcciones. La distribución de las M&Ms naranjas es asimétrica: la mitad de las muestras tienen 4—7 M&Ms (solo cuatro resultados posibles) y la mitad tienen 7—15 M&Ms (nueve posibles resultados), lo que sugiere que la distribución está sesgada hacia números más altos de M&Ms naranjas (ver Capítulo 5 para más información sobre las distribución de muestras).
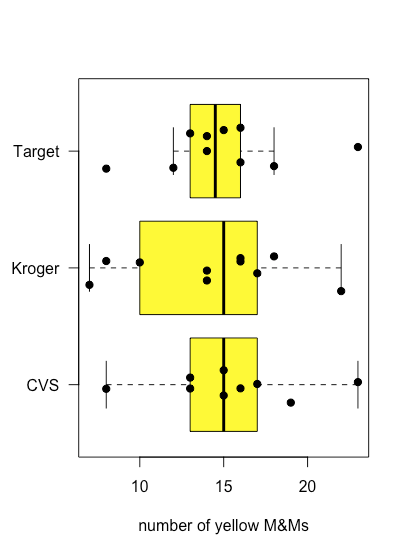
La figura\(\PageIndex{6}\) muestra parcelas de caja y bigotes para M&Ms amarillas agrupadas según la tienda donde se compraron las bolsas de M&Ms. Aunque las parcelas de caja y bigotes son bastante diferentes en términos de los tamaños relativos de las cajas y la longitud relativa de los bigotes, las gráficas de puntos sugieren que la distribución de los datos subyacentes es relativamente similar en que la mayoría de las bolsas contienen 12—18 M&M amarillos y solo unas pocas bolsas se desvían de estos límites. Estas observaciones son tranquilizadoras porque no esperamos que la elección de tienda afecte la composición de las bolsas de M&Ms. Si viéramos evidencia de que la elección de tienda afectó nuestros resultados, entonces miraríamos más de cerca las bolsas mismas para evidencia de una variable mal controlada, como el tipo (Did we comprar accidentalmente bolsas de mantequilla de maní M&Ms en una tienda?) o el número de lote del producto (¿Cambió el fabricante la composición de colores entre lotes?).
Parcelas de Barras
Aunque una gráfica de puntos, una gráfica de franjas y una gráfica de caja y bigotes proporcionan alguna evidencia cualitativa de cómo se distribuyen los valores de una variable, tendremos más que decir sobre la distribución de datos en el Capítulo 5, son menos útiles cuando necesitamos una imagen más cuantitativa de la distribución. Para ello podemos utilizar una gráfica de barras que muestre un recuento de cada resultado discreto. La figura\(\PageIndex{7}\) muestra gráficas de barras para M&Ms naranja y amarillo usando los datos de la Tabla\(\PageIndex{1}\).
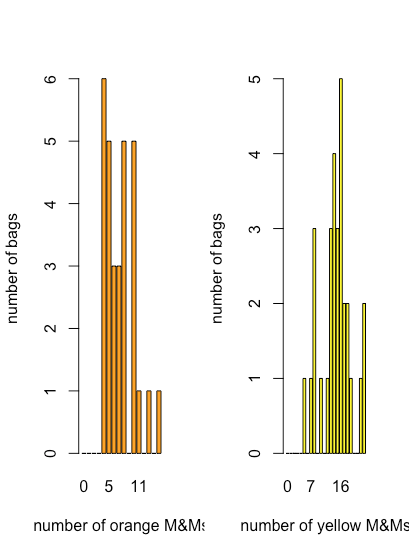
Aquí vemos que el número más común de M&Ms naranjas por bolsa es de cuatro, que también es el menor número de M&Ms naranjas por bolsa, y que hay una disminución general en el número de bolsas a medida que aumenta el número de M&M naranjas por bolsa. Para los M&Ms amarillos, el número más común de M&Ms por bolsa es de 16, que cae cerca de la mitad del rango de M&Ms amarillos.
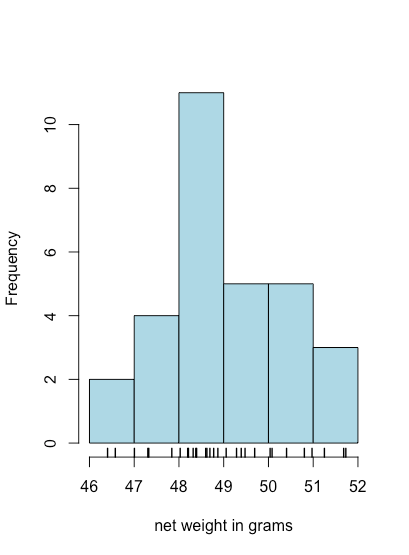
Histogramas
Una gráfica de barras es una forma útil de observar la distribución de resultados discretos, como los recuentos de M&Ms naranjas o amarillas, pero no es útil para datos continuos donde cada resultado es único. Un histograma, en el que mostramos el número de resultados que caen dentro de una secuencia de bins igualmente espaciados, proporciona una vista que es similar a la de una gráfica de barras pero que funciona con datos continuos. La figura\(\PageIndex{8}\), por ejemplo, muestra un histograma para los pesos netos de las 30 bolsas de M&Ms en la Tabla\(\PageIndex{1}\). Los valores individuales se muestran mediante las marcas hash verticales en la parte inferior del histograma.