
20.19: Almacenamiento de Información
- Page ID
- 75153

¿Cómo pueden las moléculas de ADN y ARN actuar como planos para la fabricación de proteínas? Los detalles exactos fueron desentrañados a principios de la década de 1960 principalmente por Marshall Nirenberg (nacido en 1927) en los Institutos Nacionales de Salud y H. G. Khorana (nacido en 1922) en la Universidad de Wisconsin, obra que les valió el premio Nobel en 1968. Mostraron que cada aminoácido en una proteína está determinado por un codón específico de tres bases nitrogenadas en la cadena de ADN o ARN. Los detalles de este código genético se dan en la siguiente tabla. Como ejemplo de cómo funciona este código, tomemos la sección de ARN que se muestra en la Figura 3 sobre Estructura de ácidos nucleicos. Esto tiene la secuencia UCAUGG. Esto es parte de las instrucciones para construir una cadena polipeptídica que contenga el aminoácido serina (UCA) seguido del aminoácido triptófano (UGG).
Tabla\(\PageIndex{1}\) El Código Genético para ARN
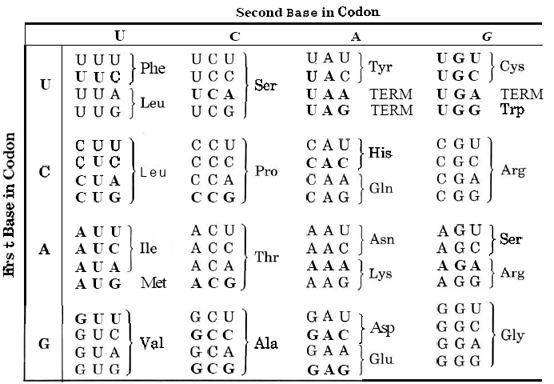
(a) Un codón de terminación se indica por TERM. (b) AUG, el codón para metionina es también el codón de iniciación. Toda la síntesis de proteínas comienza en este codón, aunque esta metionina inicial a menudo se elimina durante el procesamiento postranscripcional.
Hay tres características adicionales del código genético. Primero, AUG, el codón para metionina también sirve como codón de iniciación, y, con ayuda de otras señales, es donde comienza la sítesis de proteínas. Una segunda característica es que la lectura de ARN para la síntesis de proteínas va desde el extremo 5' de carbono del ácido nucleico hasta el extremo 3' de carbono. Una característica final importante del código genético es la existencia de tres codones de terminación. Estos corresponden a una instrucción para terminar una cadena polipeptídica. Cómo funcionan estas características se ilustra mejor con un ejemplo.
Decodificar el fragmento de ARN
5' A C C U U A U G A C G C C U G U C C A U U A A A C G A U 3'
Solución
Primero, debemos decidir en qué dirección leer el código de ARN. La síntesis va del extremo 5' al extremo 3', por lo que este segmento se lee de izquierda a derecha. Si se hubiera mostrado 3' a 5', habríamos necesitado leerlo de derecha a izquierda.
Segundo, necesitamos buscar un codón de iniciación, AUG. Este codón aparece comenzando en la sexta letra en. Así, podemos dividir la secuencia así, con el codón de inicio en negrita:
- AC|CUU| AUG |ACG|CCU|GUC|CAU|UAA|CGA|U
Tercero, veamos si hay un codón de parada en esta secuencia. Bastante seguro, el quinto codón después del codón de inicio, UAA es un codón de parada. Así, toda la secuencia a traducir, en negrita:
- AC|CUU| AGO|ACG|CCU|GUC|CAU|UAA |CGA|U
que se traduce en la secuencia de aminoácidos:
- Met-Thr-Pro-Val-su-Stop
Observe en el ejemplo, que si no hubiéramos comenzado con el codón de iniciación, se habría formado una proteína completamente diferente. Mira lo que hubiera pasado si simplemente hubiéramos comenzado al principio de la secuencia:
- ACC|UUA|UGA |CGC|CUG|UCC|AUU|AAC|GAU|
un codón de parada aparece en un nuevo lugar, y el protien traducido es:
- Thr-Leu-stop
Esto resalta la importancia del marco de lectura, el lugar donde empiezan a leerse los codones. Observe que, dado que los codones tienen una longitud de 3 bases, cualquier secuencia tiene tres marcos de lectura diferentes. Sin el codón de iniciación, no habría manera de identificar el marco de lectura correcto. Además del codón de iniciación AUG, otro elemento regula la iniciación. En bacterias, una secuencia de bases antes del codón de iniciación, llamada secuencia Shine-Dalgarno precede al codón AUG, especificando dónde comenzar la traducción. Una configuración diferente ocurre en los eucariotas. Se forma un complejo de iniciación, pero en lugar de tener una secuencia específica conectada al codón de iniciación, el complejo se desliza a lo largo de la cadena de ARNm, hasta que encuentra el codón de iniciación AUG. [2]
- ↑ Nelson, D.L., Cox, M.M. Lehninger Principios de Bioquímica (<sup>5ª</sup> ed). Nueva York: W.H. Freeman and Company, 2008. pp. 1070-1072.
- ↑ Nelson, D.L., Cox, M.M. Lehninger Principios de Bioquímica (<sup>5ª</sup> ed). Nueva York: W.H. Freeman and Company, 2008. pp. 1088-1090.