
25.13: Biosíntesis de Proteínas
- Page ID
- 72666

Uno de los problemas más interesantes y básicos relacionados con la síntesis de proteínas en células vivas es cómo se induce a los aminoácidos componentes a unirse en las secuencias que son específicas para cada tipo de proteína. También existe el problema relacionado de cómo se perpetúa la información sobre las secuencias de aminoácidos en cada nueva generación de células. Ahora sabemos que las sustancias responsables del control genético en plantas y animales están presentes y se originan a partir de los cromosomas de los núcleos celulares. El análisis químico de los cromosomas ha revelado que están compuestos por moléculas gigantes de desoxirribonucleoproteínas, que son ácidos desoxirribonucleicos (ADN) unidos a proteínas. Dado que se sabe que el ADN más que el componente proteico de una nucleoproteína contiene la información genética para la biosíntesis de enzimas y otras proteínas, nos interesará principalmente el ADN y primero discutiremos su estructura. Parte o tal vez la totalidad de un ADN en particular es el equivalente químico del gen mendeliano, la unidad de herencia.
La estructura del ADN
El papel del ADN en las células vivas es análogo al de una cinta perforada utilizada para controlar el funcionamiento de un torno automático de torreta - el ADN suministra la información para el desarrollo de las células, incluyendo la síntesis de las enzimas necesarias y las réplicas de sí mismas que se requieren para la reproducción por célula división. Obviamente, no esperaríamos que el ADN de un tipo de organismo fuera el mismo que el ADN de otro tipo de organismo. Por lo tanto, es imposible ser muy específico sobre la estructura del ADN sin ser específico sobre el organismo del que se deriva. Sin embargo, las características estructurales básicas del ADN son las mismas para muchos tipos de células, y principalmente nos ocuparemos de estas características básicas en la siguiente discusión.
En primer lugar, las moléculas de ADN son bastante grandes, lo suficientemente como para permitirles ser vistas individualmente en fotografías tomadas con microscopios electrónicos. Los pesos moleculares varían considerablemente, pero valores de 1,000,000 a 4,000,000,000 son típicos. La difracción de rayos X indica que el ADN está compuesto por dos moléculas de cadena larga retorcidas una alrededor de la otra para formar una hélice bicatenaria de aproximadamente\(20 \: \text{Å}\) un diámetro. La disposición se muestra esquemáticamente en\(12\):
Como veremos, los componentes de las cadenas son tales que las hebras pueden mantenerse unidas de manera eficiente por enlaces de hidrógeno. De acuerdo con esta estructura, se ha encontrado que, cuando el ADN se calienta aproximadamente\(80^\text{o}\) en condiciones adecuadas, las hebras de la hélice se desenrollan y se disocian en dos fragmentos enrollados aleatoriamente. Además, cuando el material disociado se deja enfriar lentamente en las condiciones adecuadas, los fragmentos se recombinan y regeneran la estructura helicoidal.
Estudios químicos muestran que las hebras de ADN tienen la estructura de un polímero de cadena larga hecho de restos alternos de fosfato y azúcar que portan bases nitrogenadas,\(13\):

El azúcar es\(D\) -2-desoxirribofuranosa\(14\), y cada residuo de azúcar está unido a dos grupos fosfato por medio de enlaces éster que involucran los grupos 3 y 5-hidroxilo:

El esqueleto del ADN es así un éster de polifosfato de un 1,3-diol:

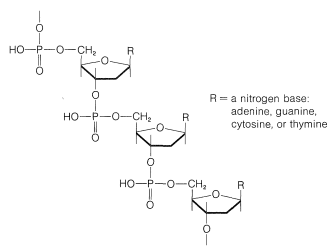
Cada uno de los residuos de azúcar del ADN está unido en la posición 1 de una de cuatro bases: citosina,\(15\); timina,\(16\); adenina,\(17\); y guanina,\(18\). Las cuatro bases son derivados de pirimidina o purina, siendo ambas bases heterocíclicas nitrogenadas:
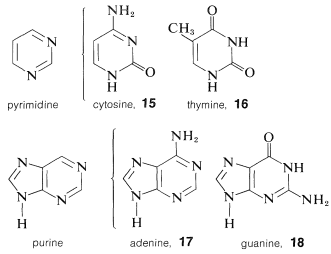
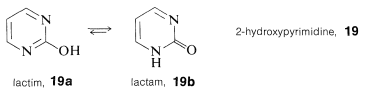
A diferencia de los fenoles (Sección 26-1), el análisis estructural de muchos de los compuestos aza-aromáticos sustituidos con hidroxi se complica por isomería del tipo ceto-enol, a veces llamado isomerismo láctico-lactama. Para 2-hidroxipirimidina,\(19\), estos isómeros son\(19a\) y\(19b\), y la forma lactama es más estable, como también es cierto para la citosina,\(15\), timina,\(16\), y el anillo de pirimidina de guanina,\(18\).
En aras de la simplicidad en la ilustración\(\ce{N}\) de la formación de glucósidos en el ADN, mostraremos el tipo de enlace involucrado solo para los componentes de azúcar y base (es decir, la estructura de nucleósidos de desoxirribosa). La unión de 2-desoxirribosa es a través de un\(\ce{NH}\) grupo para formar el\(\beta\)\(\ce{N}\) -desoxirribofuranósido (Sección 20-5):
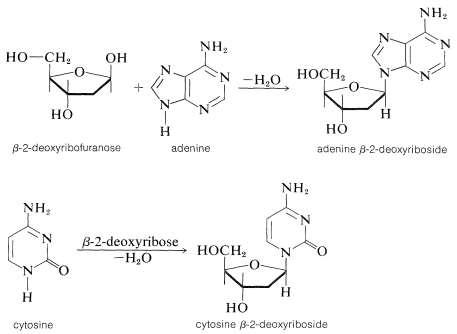
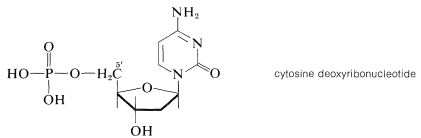
La esterificación del grupo 5'-hidroxilo de nucleósidos de desoxirribosa, tales como citosina desoxirriósido, con ácido fosfórico da los nucleótidos correspondientes:\(^{11}\)
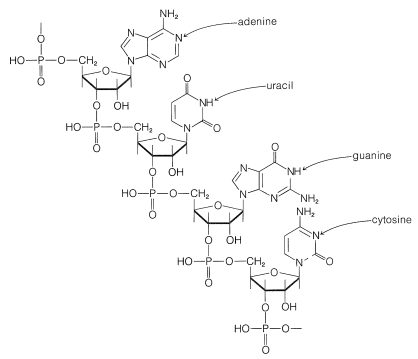
El número de unidades de nucleótidos en una cadena de ADN varía de aproximadamente 3,000 a 10,000,000 Aunque no se conoce la secuencia de las bases de purina y pirimidina en las cadenas, existe una sorprendente equivalencia entre los números de ciertas de las bases independientemente del origen del ADN. Así, el número de grupos adenina (A) es igual al número de grupos de timina (T), y el número de grupos guanina (G) es igual al número de grupos de citosina (C): A = T y G = C. Las bases del ADN por lo tanto son medias purinas y mitad pirimidinas. Además, aunque las proporciones de A a G y T a C son constantes para una especie dada, varían ampliamente de una especie a otra.
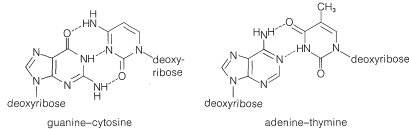
La equivalencia entre las bases purina y pirimidina en el ADN fue contabilizada por J. D. Watson y F. Crick (1953) a través de la sugerencia de que las dos cadenas se construyen de manera que, cuando se tuercen juntas en la estructura helicoidal, se forman enlaces de hidrógeno que involucran adenina en una cadena y timina en la otra, o citosina en una cadena y guanina en la otra. Así, cada adenina ocurre emparejada con una timina y cada citosina con una guanina y se dice que las hebras tienen estructuras complementarias. Los enlaces de hidrógeno postulados se muestran en la Figura 25-22, y la relación de las bases con las hebras en la Figura 25-23.

Control Genético y Replicación del ADN
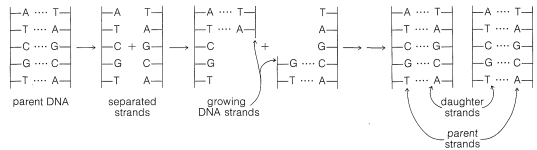
Ahora está bien establecido que el ADN proporciona la receta genética que determina cómo se reproducen las células. En el proceso de división celular, también se reproduce el ADN mismo y así perpetúa la información necesaria para regular la síntesis de enzimas específicas y otras proteínas de la estructura celular. Al replicarse antes de la división celular, la doble hélice del ADN evidentemente separa al menos parcialmente en dos cadenas (ver Figura 25-24). Cada una de las partes separadas sirve como guía (molde) para el ensamblaje de una secuencia complementaria de nucleótidos a lo largo de su longitud. En última instancia, se forman dos nuevas cadenas dobles de ADN, cada una de las cuales contiene una hebra del ADN parental.
La información genética inherente al ADN depende de la disposición de las bases (A, T, G y C) a lo largo del esqueleto fosfato-carbohidrato, es decir, de la disposición de los cuatro nucleótidos específicos del ADN. Así, la secuencia A-G-C en un punto particular transmite un mensaje diferente al de la secuencia G-A-C.
Es bastante seguro que el código involucra una secuencia particular de tres nucleótidos por cada aminoácido. Así, la secuencia A-A-A codifica lisina y U-C-G codifica serina. Se conocen las secuencias o codones para los veinte aminoácidos.
Papel del ARN en la síntesis de proteínas
Es claro que el ADN no juega un papel directo en la síntesis de proteínas y enzimas debido a que la mayor parte de la síntesis de proteínas tiene lugar fuera del núcleo celular en el citoplasma celular, que no contiene ADN. Además, se ha demostrado que la síntesis de proteínas puede ocurrir en ausencia de un núcleo celular o, igualmente, en ausencia de ADN. Por lo tanto, el código genético en el ADN debe transmitirse selectivamente a otras sustancias que transportan información desde el núcleo hasta los sitios de síntesis de proteínas en el citoplasma. Estas otras sustancias son los ácidos ribonucleicos (ARN), que son moléculas poliméricas similares en estructura al ADN, excepto que la\(D\) 2-desoxirribofuranosa es reemplazada por\(D\) -ribofuranosa y la base timina es reemplazada por uracilo, como se muestra en la Figura 25-25.

El ARN también difiere del ADN en que no hay las mismas regularidades en la composición general de sus bases y generalmente consiste en una sola cadena de polinucleótidos. Existen diferentes tipos de ARN, que cumplen diferentes funciones. Acerca\(80\%\) del ARN en una célula se localiza en el citoplasma en racimos estrechamente asociados con proteínas. Estas partículas de ribonucleoproteína específicamente se llaman ribosomas, y los ribosomas son los sitios de la mayor parte de la síntesis de proteínas en la célula. Además del ARN ribosómico (ARNr), existen ácidos ribonucleicos llamados ARN mensajero (ARNm), que transmiten instrucciones sobre qué proteína hacer. Además, existen ácidos ribonucleicos llamados ARN de transferencia (ARNt), que en realidad guían a los aminoácidos en su lugar en la síntesis de proteínas. Ahora se sabe mucho sobre la estructura y función del ARNt.
Las principales características estructurales de las moléculas de ARNt se muestran esquemáticamente en la Figura 25-26. Algunas de las características importantes de las moléculas de ARNt se resumen de la siguiente manera.
1. Hay al menos un ARNt particular para cada aminoácido.
2. Las moléculas de ARNt tienen cadenas simples con 73-93 ribonucleótidos. La mayoría de las bases de ARNt son adenina (A), citosina (C), guanina (G) y uracilo (U). También hay una serie de bases inusuales que son derivados metilados de A, C, G y U.
3. El patrón trébol foliar de la Figura 25-26 muestra la estructura general del ARNt. Hay regiones de la cadena donde las bases son complementarias entre sí, lo que hace que se pliegue en dos regiones de doble hélice. La cadena tiene tres curvas o bucles que separan las regiones helicoidales.
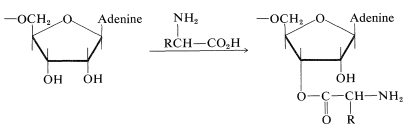
4. El residuo 5'-terminal generalmente es un nucleótido guanina; se fosforila en el 5'-\(\ce{OH}\). El término en el extremo 3' tiene la misma secuencia de tres nucleótidos en todos los ARNt, es decir, CCA. El 3'-\(\ce{OH}\) de la adenosina en este agrupamiento es el punto de unión del ARNt a su aminoácido específico:
 \(\tag{25-9}\)
\(\tag{25-9}\)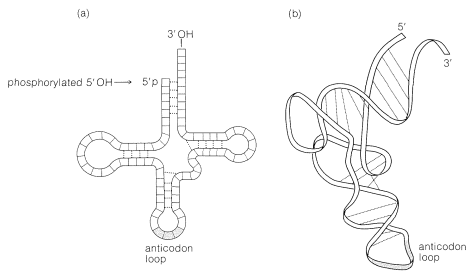
Con esta información sobre la estructura del ARNt, podemos proceder a una discusión sobre las características esenciales de la síntesis bioquímica de proteínas.
La información que determina la secuencia de aminoácidos en una proteína a sintetizar está contenida en el ADN de un núcleo celular como una secuencia particular de nucleótidos derivados de adenina, guanina, timina y citosina. Para cada aminoácido particular hay una secuencia de tres nucleótidos llamada codón.
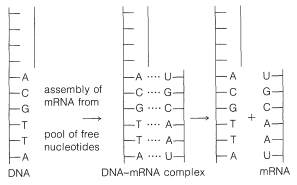
La información sobre la estructura de la proteína se transmite desde el ADN en el núcleo celular al citoplasma donde la proteína es ensamblada por ARN mensajero. Este ARN mensajero, o al menos parte de él, se ensambla en el núcleo con una secuencia de bases que es complementaria a la secuencia de bases en el ADN parental. El mecanismo de ensamblaje es similar a la replicación del ADN excepto que la timina (T) es reemplazada por uracilo (U). El uracilo es complementario a la adenina en la cadena del ADN (ver Figura 25-27). Después de ensamblar el ARNm, se transporta al citoplasma donde se une a los ribosomas.
Los aminoácidos en el citoplasma no formarán polipéptidos a menos que se activen por la formación de ésteres con moléculas de ARNt apropiadas. Los enlaces éster son a través del 3'-\(\ce{OH}\) del nucleótido de adenosina terminal (Ecuación 25-9) y se forman solo bajo la influencia de una enzima sintetasa que es específica para el aminoácido particular. La energía para la formación de ésteres proviene de la hidrólisis de ATP (Secciones 15-5F y 20-10). El producto se llama aminoacil-ARNt.
Los aminoacil-ARNt forman cadenas polipeptídicas en el orden especificado por los codones del ARNm unido a los ribosomas (ver Figura 25-28). El orden de incorporación de los aminoácidos depende del reconocimiento de un codón en ARNm por el anticodón correspondiente en ARNt por un apareamiento de bases complementarias del tipo A\(\cdots\) U y C\(\cdots\) G. Las dos primeras bases del codón reconocen solo sus bases complementarias en el anticodón, pero hay es cierta flexibilidad en la identidad de la tercera base. Así, el ARNt de fenilalanina tiene el anticodón A-A-G y responde a los codones U-U-C y U-U-U, pero no U-U-A o U-U-G:
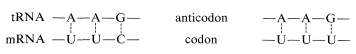
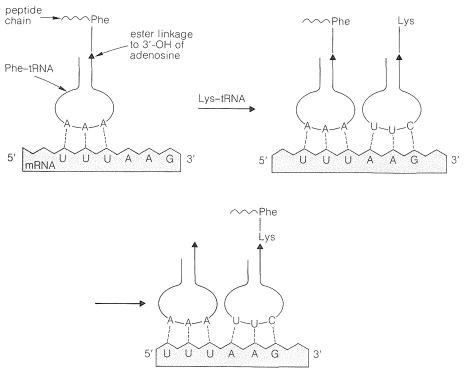
Los codones del ARNm en los ribosomas se leen desde el extremo 5' al 3'. Así, el polinucleótido sintético (5') A-A-A- (A-A-A)\(_n\) -A-A-C (3') contiene el código para lisina (A-A-A) y asparagina (A-A-C); el polipéptido real obtenido usando este ARNm en un sistema libre de células fue Lys- (Lys)\(_n\) -Asn, y no Asn- (Lys)\(_n\) -Lys.
El inicio de la síntesis de proteínas es señalado por interacciones específicas codon-anticodón. La terminación también es señalada por un codón en el ARNm, aunque la señal de parada no es reconocida por el ARNt, sino por proteínas que luego desencadenan la hidrólisis de la cadena polipeptídica completa a partir del ARNt. Aún no está claro cómo se logran las estructuras secundaria y terciaria de las proteínas, pero ciertamente el mecanismo de síntesis proteica, que hemos esbozado aquí, requiere de pocas modificaciones para dar cuenta de la formación preferencial de conformaciones particulares.
\(^{11}\)Las posiciones en el anillo de azúcar son cebadas para diferenciarlas de las posiciones de la base nitrogenada.
Colaboradores y Atribuciones
- John D. Robert and Marjorie C. Caserio (1977) Basic Principles of Organic Chemistry, second edition. W. A. Benjamin, Inc. , Menlo Park, CA. ISBN 0-8053-8329-8. This content is copyrighted under the following conditions, "You are granted permission for individual, educational, research and non-commercial reproduction, distribution, display and performance of this work in any format."