
1.23: Ácidos nucleicos
- Page ID
- 74331

Funciones del ADN
La última vez examinamos cómo podría descubrirse la secuencia de aminoácidos de un péptido o proteína. También aprendimos cómo se puede llevar a cabo una síntesis química de un péptido pequeño.
Hoy estudiaremos la química de la molécula que lleva la información necesaria para dirigir la biosíntesis de proteínas y péptidos. Esto es ADN, y aprenderemos que la estructura del ADN proporciona una justificación muy fuerte para su función.
Primero, pensemos un poco en lo que necesita hacer una “molécula de herencia”. Debe almacenar una inmensa cantidad de información —las instrucciones para sintetizar todas las proteínas necesarias para el funcionamiento exitoso de un organismo vivo. Debe ser capaz de transmitir esa información fielmente, con una tasa de error extremadamente baja, al sistema de síntesis de proteínas, tanto a las células hijas tras la división celular, como a una generación futura tras la reproducción del organismo.
Antes del descubrimiento de la estructura del ADN, había mucha especulación con respecto a posibles moléculas que pudieran cumplir con estos requisitos. Las proteínas mismas fueron consideradas seriamente como candidatas, ya que son estables, pueden ser lo suficientemente grandes como para contener una gran cantidad de información, y ciertamente están íntimamente involucradas en la biología. La información podría estar codificada en la secuencia de aminoácidos en una proteína, al igual que la información en una palabra se codifica en una secuencia de letras. Podríamos pensar en los aminoácidos como un alfabeto de 20 caracteres, con el que podríamos hacer un número muy grande de palabras, oraciones, párrafos, libros, etc.
Cuando la estructura del ADN fue establecida por James Watson y Francis Crick en 1953 quedó inmediatamente claro que tenía las características necesarias para cumplir con las especificaciones de una molécula de herencia. Es un polímero que puede ser extremadamente largo. (El ADN en la molécula única que compone un cromosoma humano tiene aproximadamente 12 cm. de largo.) Esto proporciona la capacidad de almacenar grandes cantidades de información. Al igual que una proteína, este esqueleto polimérico lleva un alfabeto. En este caso, el alfabeto consta de sólo cuatro letras, A, C, G y T. Veamos los detalles.
Columna principal de polímero de ADN
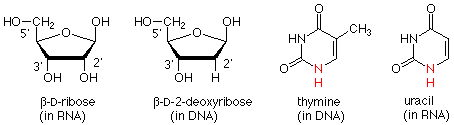
La cadena principal polimérica se compone de dos tipos de estructura. Una es una modificación de la ribosa de azúcar. La modificación es que el grupo OH en el carbono próximo al carbono anomérico ha sido reemplazado por un hidrógeno. Esto se llama 2-desoxi-D-ribosa.
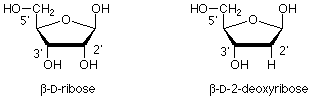
Estas unidades de 2-desoxirribosa están unidas entre sí por ésteres de fosfato que unen el oxígeno 3' de un azúcar con el oxígeno 5' del siguiente. (Los “primos” 'están ahí para diferenciar los átomos en el anillo de azúcar de los que están en las bases, que vamos a tomar a continuación). Esto nos da una “columna vertebral” para el ADN que se ve así:
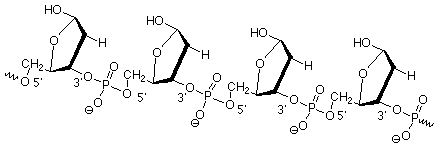
Las moléculas del “alfabeto”, A, C, G y T, están unidas a esta cadena principal en los carbonos anoméricos (1'). Recordemos que estos carbonos son aquellos en los que otros grupos pueden unirse por reacciones como las que convierten los hemiacetales en acetales. A continuación veremos las estructuras de estas moléculas, que se llaman bases ya que contienen átomos de nitrógeno que las hacen levemente básicas.
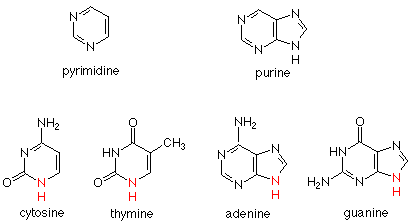
Las Bases A, C, G y T
Dos estructuras anulares se encuentran en las bases. C (citosina) y T (timina) tienen un solo anillo de seis miembros, llamado anillo de pirimidina. A (adenina) y G (guanidina) tienen dos anillos unidos entre sí. Esta unidad se llama anillo de purina. C y T se llaman bases de pirimidina; A y G se llaman bases purinas. Aquí están las estructuras:
En cada una de estas bases hay una amina secundaria cuyo nitrógeno forma un enlace con el carbono anomérico de una desoxirribosa en la cadena principal del ADN. Podemos relacionar la química de la formación de este vínculo con la formación de un glucósido (acetal) a partir de glucosa (hemiacetal) y un alcohol. La diferencia es que en el caso actual el nucleófilo es el nitrógeno de amina secundaria de una base más que el oxígeno de un alcohol. Un ejemplo de cuatro bases unidas de esta manera es:

La “palabra” aquí es CACT. Recordemos que el esqueleto del ADN es muy largo, y es claro que incluso con solo un alfabeto de cuatro letras, una gran cantidad de información puede ser transportada por el ADN
Replicación: dos ADN de uno
El siguiente problema es la transmisión de la información a una célula hija, a una generación sucesiva, o a la maquinaria de síntesis de proteínas de una célula. La otra característica clave de la estructura del ADN descubierta por Watson y Crick es que las moléculas de ADN vienen en pares, retorcidas juntas en la “doble hélice” (Figs. 19.8, 19.9; pp. 541,2 en Brown). Cada una de estas moléculas es una sola cadena larga, mantenida unida por los enlaces covalentes a lo largo de su cadena principal. Las conexiones entre las cadenas de ADN se realizan mediante enlaces de hidrógeno entre las bases. Los enlaces de hidrógeno (como aprendimos cuando estudiamos aminas) son mucho más débiles que los enlaces covalentes, pero como hay muchos de ellos conectando las dos cadenas de ADN en la doble hélice, sirven muy bien para mantener esa estructura hasta que hay una necesidad de separación de las dos cadenas.
No sólo los enlaces de hidrógeno mantienen unidas las cadenas, también son muy específicos en qué bases están conectadas por los enlaces de hidrógeno. La adenina (A) forma dos enlaces de hidrógeno solo con la timina (T). La guanidina (G) forma tres enlaces de hidrógeno solo con la citosina (C).
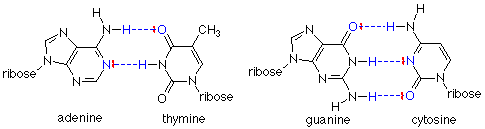
En cada caso, el enlace de hidrógeno se forma entre el extremo positivo de hidrógeno de un enlace N-H polar y un par de electrones en un nitrógeno o un oxígeno carbonilo. Estos pares de bases “complementarios” también tienen otra característica importante: una base purina (adenina o guanidina) siempre se une a una base de pirimidina (citosina o timina). Esto significa que la distancia entre las dos hebras es siempre la misma (tres anillos y los enlaces de hidrógeno). Los enlaces de hidrógeno entre dos bases purinas, por ejemplo, pondrían cuatro anillos en el par de bases, y el ajuste sería pobre. Puedes intentar armar otros patrones de enlaces de hidrógeno, pero estos dos son los que mejor se ajustan.
Watson y Crick se dieron cuenta de que la especificidad de este esquema de emparejamiento de bases era la clave para la replicación del ADN y la transmisión de información de una generación a la siguiente. Esto se hace en tres pasos. Primero, la doble hélice se separa en las cadenas de ADN individuales rompiendo sucesivamente los enlaces de hidrógeno entre los pares de bases.
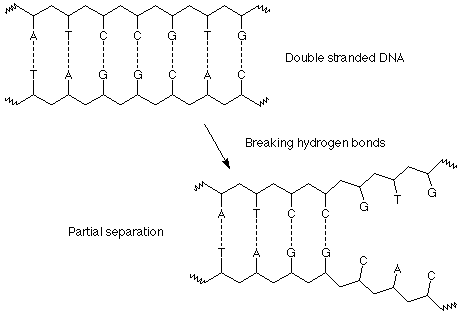
Segundo, a medida que se expone un segmento de ADN “desenrollado”, las bases de la solución lo encuentran, se alinean con las bases complementarias en las cadenas de ADN expuestas y forman los pares de bases adecuados, A con T y C con G. Estas bases ya están unidas a los grupos ribosa y fosfato necesarios en moléculas llamadas nucleótidos, de manera que a medida que se alinean en la disposición adecuada, los materiales para la formación de la columna vertebral de un nuevo polímero estén en las ubicaciones adecuadas.
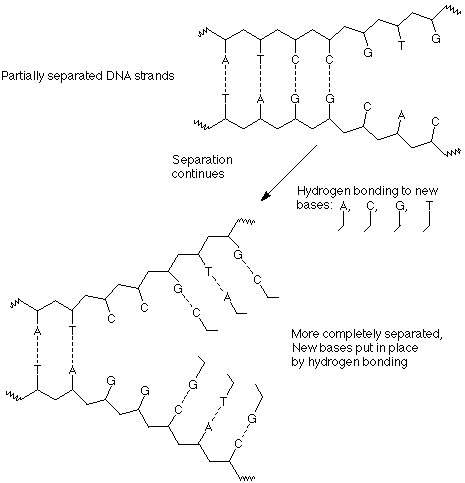
En tercer lugar, a medida que avanza la separación y los enlaces de hidrógeno con nuevas bases, los nucleótidos individuales se unen entre sí mediante la formación de nuevos enlaces entre un fosfato de un nucleótido y el grupo 3' OH del siguiente nucleótido.
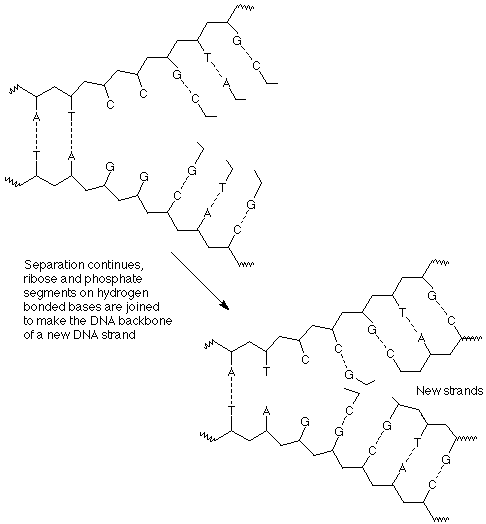
El resultado de estos procesos es que cada hebra de la doble hélice de ADN original se ha utilizado como plantilla sobre la cual se ha construido una copia de su pareja anterior. Ahora hay dos dobles hélices idénticas que son las mismas que las originales.
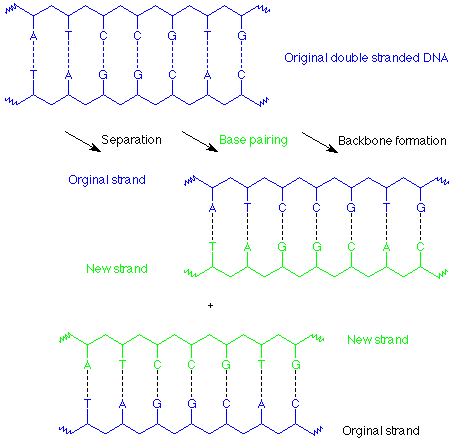
Esto se conoce como replicación. En la división celular cada una de estas copias de ADN pasaría a formar parte de una de las células hijas. Cada paso en este proceso es asistido y controlado por enzimas, y también hay una función de “corrección” involucrada para que pares de bases no coincidentes (como un par A-G) se escindan y reparen.
Transcripción y Traducción - ADN a ARNm a Proteína
Existen dos procesos sucesivos mediante los cuales se utiliza la información contenida en una cadena de ADN para determinar la secuencia de aminoácidos de una proteína. En la primera de ellas, llamada transcripción, se realiza una copia de la cadena de ADN, pero en este caso la copia es ARN. Hay dos diferencias estructurales entre ADN y ARN. En el ARN el azúcar es ribosa (con el grupo 2' OH) mientras que en el ADN es 2-desoxirribosa (sin el grupo 2' OH). También, donde T (timina) ocurriría en el ADN, U (uracilo) ocurre en el ARN.
El proceso de transcripción mediante el cual se realiza una copia de ARN es muy similar al proceso por el cual se replica el ADN. En este caso, solo se produce un desenrollamiento parcial de la hélice de ADN, y las bases apropiadas enlazan hidrógeno al ADN separado, U con A, C con G. Los nucleótidos de ARN que ahora se alinean en el molde de ADN se unen luego para formar la cadena de ARN, que es una copia de la cadena de ADN que fue no la plantilla, y es complementaria a la hebra que se utilizó como plantilla.
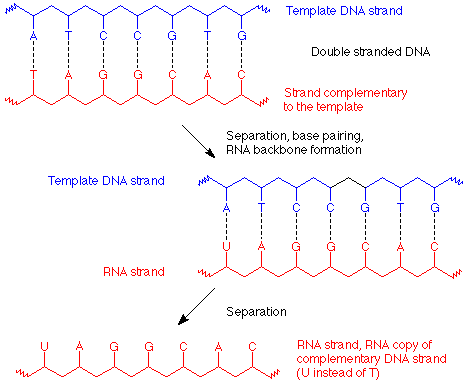
De esta manera se hace una cadena de ARN que lleva el mensaje genético (llamado “mensajero” o ARNm) a la maquinaria de síntesis de proteínas (llamada ribosoma). Su secuencia de bases especifica la secuencia de aminoácidos en la proteína a elaborar. Los códigos para cada aminoácido utilizan tres bases seguidas y se dan en la tabla 19.3 (p 547 de Brown). Dado que hay 64 formas de hacer “palabras” de tres letras (llamadas codones) con un alfabeto de cuatro letras, muchos aminoácidos están codificados por más de una “palabra”.
En el ribosoma, los codones del ARNm se emparejan con anticodones (A con U, G con C) en moléculas de ARN de transferencia (ARNt). Cada molécula de ARNt lleva el aminoácido apropiado a la enzima que los une para producir la proteína. Este proceso se llama traducción. No veremos en detalle el proceso de vinculación, pero sí incluye pasos de protección y activación muy parecidos a la síntesis química que estudiamos anteriormente.
El flujo de información en el proceso global es: La secuencia de codones en el ADN determina la secuencia de codones en ARNm. La secuencia de codones en el ARNm determina el orden en que se alinean las moléculas de ARNt. El orden de la alineación de ARNt determina la secuencia en la que se unen los aminoácidos para producir la proteína.