
1.4: Introducción a las Tablas 2 x 2, Diseño de Estudios Epidemiológicos y Medidas de Asociación
- Page ID
- 121625

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
Después de leer este capítulo, podrás hacer lo siguiente:
- Interpretar los datos encontrados en una tabla de 2 x 2
- Comparar y contrastar los 4 tipos más comunes de estudios epidemiológicos: estudios de cohortes, ensayos controlados aleatorios, estudios de casos y controles y estudios transversales
- Calcular e interpretar medidas relativas de asociación (cocientes de riesgo, ratios de tasa, odds ratios)
- Explicar qué medidas se prefieren para qué diseños de estudio y por qué
- Discutir las diferencias entre las medidas absolutas y relativas de asociación
En epidemiología, a menudo nos preocupa el grado en que una exposición particular podría causar (o prevenir) una enfermedad en particular. Como se detalla más adelante en el capítulo 10, es difícil afirmar efectos causales a partir de un solo estudio epidemiológico; por lo tanto, decimos en cambio que las exposiciones y enfermedades están (o no) estadísticamente asociadas. Esto significa que la exposición se distribuye desproporcionadamente entre individuos con y sin la enfermedad. El grado en que se asocian las exposiciones y los resultados de salud se transmite a través de una medida de asociación. Qué medida de asociación elegir depende de si se está trabajando con datos de incidencia o prevalencia, lo que a su vez depende del tipo de diseño de estudio utilizado. Por lo tanto, este capítulo proporcionará un breve esquema de diseños de estudios epidemiológicos comunes entretejidos con una discusión de la (s) medida (s) apropiada (s) de asociación para cada uno. En el capítulo 9, volveremos a estudiar diseños para una discusión más profunda de sus fortalezas y debilidades.
Primer Paso Necesario: Notación 2 x 2
Antes de entrar en diseños de estudio y medidas de asociación, es importante comprender la notación utilizada en epidemiología para transmitir datos de exposición y enfermedad: la tabla 2 x 2. Una tabla 2 x 2 (o tabla dos por dos) es un resumen compacto de datos para 2 variables de un estudio, a saber, la exposición y el resultado de salud. Digamos que hacemos un estudio de 10 personas sobre el tabaquismo y la hipertensión, y recolectamos los siguientes datos, donde Y indica que sí y N indica no:
| Participante # | ¿Fumador? | ¿Hipertensión? |
|---|---|---|
| 1 | Y | Y |
| 2 | Y | N |
| 3 | Y | Y |
| 4 | Y | Y |
| 5 | N | N |
| 6 | N | Y |
| 7 | N | N |
| 8 | N | N |
| 9 | N | Y |
| 10 | N | N |
Se puede ver que tenemos 4 fumadores, 6 no fumadores, 5 individuos con hipertensión, y 5 sin. En este ejemplo, fumar es la exposición y la hipertensión es el resultado de salud, por lo que decimos que los 4 fumadores están “expuestos” (E+), los 6 no fumadores están “no expuestos” (E−), las 5 personas con hipertensión están “enfermas” (D+), y las 5 personas sin hipertensión son “no enfermas” (D−). Esta información se puede organizar en una tabla de 2×2:
| D+ | D- | |
|---|---|---|
| E+ | 3 | 1 |
| E- | 2 | 4 |
La tabla 2×2 resume la información de la tabla más larga anterior para que pueda ver rápidamente que 3 individuos estuvieron expuestos y enfermos (personas 1, 3 y 4); un individuo estuvo expuesto pero no enfermo (persona 2); dos individuos no estaban expuestos pero enfermos (personas 6 y 9); y los 4 restantes los individuos no estuvieron expuestos ni enfermos (personas 5, 7, 8 y 10). Aunque realmente no importa si la exposición o la enfermedad se coloca a la izquierda o en la parte superior de una tabla de 2 × 2, la convención en epidemiología es tener exposición a la izquierda y enfermedad en la parte superior.
Al discutir tablas 2 x 2, los epidemiólogos utilizan la siguiente taquigrafía para referirse a células específicas:
| D+ | D- | |
|---|---|---|
| E+ | A | B |
| E- | C | D |
A menudo es útil calcular los totales de margen para una tabla de 2 x 2:
| D+ | D- | Total | |
| E+ | 3 | 1 | 4 |
| E- | 2 | 4 | 6 |
| Total | 5 | 5 | 10 |
O bien:
| D+ | D- | Total | |
| E+ | A | B | A+B |
| E- | C | D | C+D |
| Total | A+C | B+D | A+B+C+D |
Los totales de margen a veces son útiles a la hora de calcular diversas medidas de asociación (y para comprobarse con los datos originales).
Variables continuas versus categóricas
Las variables continuas son cosas como la edad o la altura, donde los valores posibles para una persona dada son infinitos, o cercanos a ella. Las variables categóricas son cosas como la religión o el color favorito, donde hay una lista discreta de posibles respuestas. Las variables dicotómicas son un caso especial de variable categórica donde solo hay 2 respuestas posibles. Es posible dicotomizar una variable continua—si tienes una variable de “edad”, podrías dividirla en “vieja” y “joven”. No obstante, no siempre es recomendable hacer esto porque se pierde mucha información. Además, ¿cómo se decide dónde dicotomizar? ¿El “viejo” comienza a los 40, o 65? Los epidemiólogos suelen preferir dejar variables continuas continuas para evitar tener que hacer estas llamadas de juicio.
Sin embargo, tener variables dicotómicas (una persona está expuesta o no, enferma o no) hace que las matemáticas sean mucho más fáciles de entender. Para los fines de este libro, entonces, asumiremos que todos los datos de exposición y enfermedad pueden ser significativamente dicotomizados y colocados en tablas 2×2.
Estudios que utilizan datos de incidencia
Cohortes
Hay 4 tipos de estudios epidemiológicos que serán cubiertos en este libro, [1] dos de los cuales recopilan datos de incidencia: estudios prospectivos de cohortes y ensayos controlados aleatorios. Dado que estos diseños de estudio utilizan datos de incidencia, instantáneamente conocemos 3 cosas sobre estos tipos de estudio. Uno, estamos buscando nuevos casos de enfermedad. Dos, hay así algún seguimiento longitudinal que debe ocurrir para permitir que estos nuevos casos se desarrollen. Tres, debemos comenzar con aquellos que estaban en riesgo (es decir, sin la enfermedad o resultado de salud) como nuestra línea de base.
El procedimiento para un estudio prospectivo de cohortes (en lo sucesivo denominado solo un “estudio de cohorte”, aunque ver el recuadro de recuadro sobre estudios de cohortes retrospectivos más adelante en este capítulo) comienza con la población objetivo, que contiene tanto individuos enfermos y no enfermos:
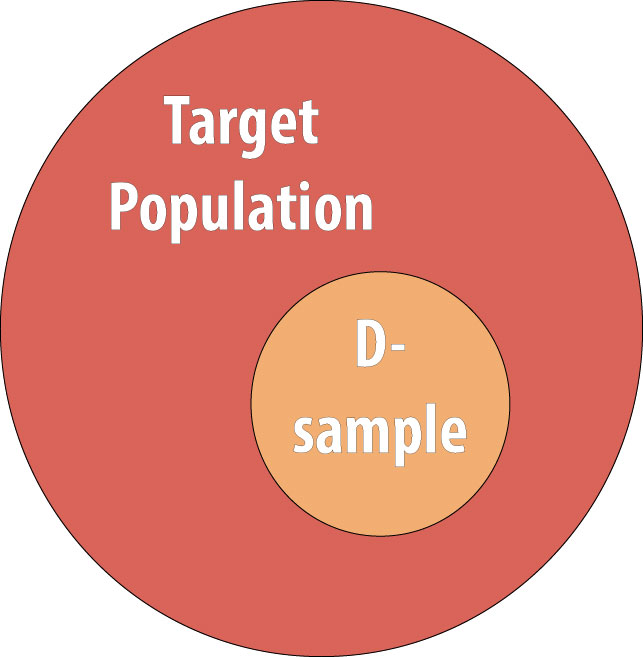
Como se discute en el capítulo 1, rara vez realizamos estudios sobre poblaciones enteras porque son demasiado grandes para que sea logísticamente factible estudiar a todos en la población. Por lo tanto, dibujamos una muestra y realizamos el estudio con los individuos de la muestra. Para un estudio de cohorte, ya que vamos a estar calculando la incidencia, debemos comenzar con individuos que están en riesgo del desenlace. Así, se extrae una muestra no enferma de la población objetivo:
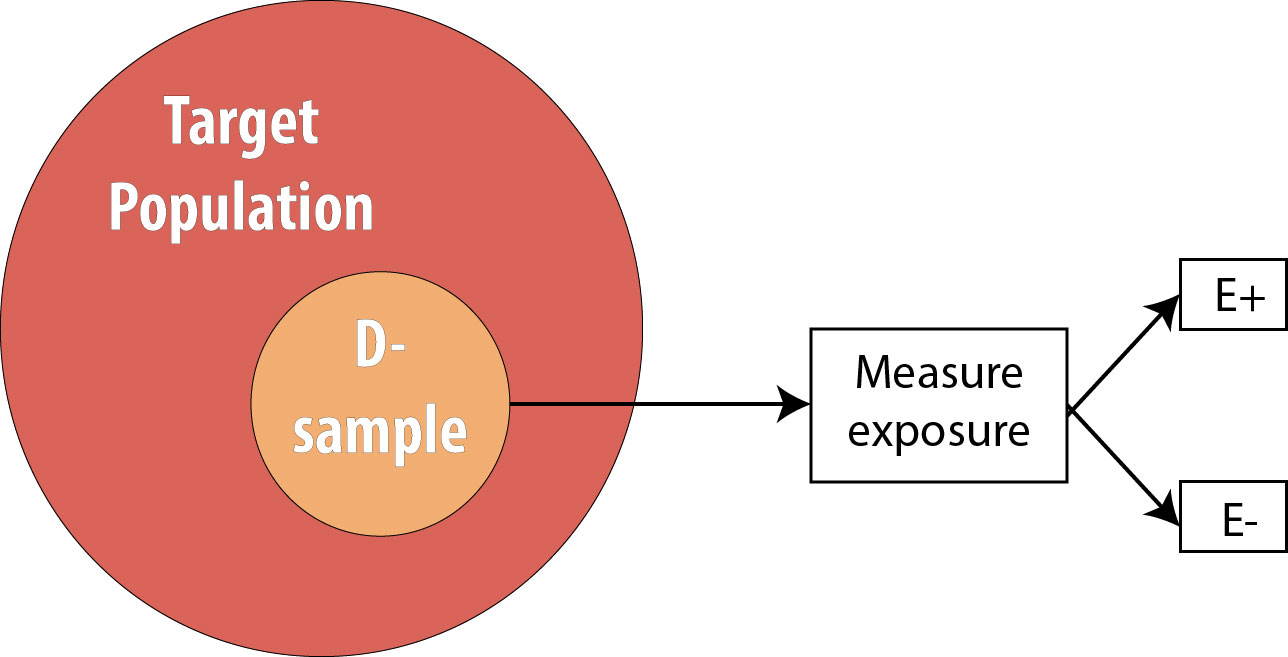
El siguiente paso es evaluar el estado de exposición de los individuos de nuestra muestra y determinar si están expuestos o no:
Después de evaluar qué participantes fueron expuestos, nuestra tabla 2 x 2 (usando el ejemplo de datos de tabaquismo/HTN de 10 personas desde arriba) se vería así:
| D+ | D- | Total | |
| E+ | 0 | 4 | 4 |
| E- | 0 | 6 | 6 |
| Total | 0 | 10 | 10 |
Por definición, al inicio de un estudio de cohortes, todos siguen en riesgo de desarrollar la enfermedad, y por lo tanto no hay individuos en la columna D+. En este ejemplo hipotético, con base en los datos anteriores, observaremos 5 casos de hipertensión incidente a medida que avanza el estudio, pero al inicio, ninguno de estos casos ha ocurrido todavía.
Luego seguimos a los participantes en nuestro estudio durante cierto tiempo y observamos los casos de incidentes a medida que surgen.

Como se menciona en el capítulo 2, la duración del seguimiento varía según el proceso de la enfermedad en cuestión. Para una pregunta de investigación sobre la exposición infantil y el cáncer de inicio tardío, la duración del seguimiento sería de décadas. Para un brote de enfermedad infecciosa, la duración del seguimiento puede ser cuestión de días o incluso horas, dependiendo del periodo de incubación de la enfermedad en particular.
Suponiendo que estamos calculando proporciones de incidencia (que utilizan el número de personas en riesgo en el denominador) en nuestra cohorte, nuestra tabla 2×2 al final del estudio de fumado/HTN se vería así:
| D+ | D- | Total | |
| E+ | 3 | 1 | 4 |
| E- | 2 | 4 | 6 |
| Total | 5 | 5 | 10 |
Es importante reconocer que cuando los epidemiólogos hablan de una tabla de 2×2 a partir de un estudio de cohorte, se refieren a la tabla 2×2 al final del estudio, la tabla 2×2 desde el inicio fue mucho menos interesante, ¡ya que la columna D+ estaba vacía!
A partir de esta tabla 2×2, podemos calcular una serie de medidas útiles, detalladas a continuación.
Ejemplo\(\PageIndex{1}\): Calculating the Risk Ratio from the Hypothetical Smoking/Hypertension Cohort Study
Podemos comenzar calculando la incidencia global de la enfermedad en nuestra muestra (supongamos que nuestro estudio fumado/HTN incluyó 10 años de seguimiento):
\[\text { Incidence proportion = population at risk at baseline }=\frac{5}{10}\]
Esto es 50 casos por cada 100 personas en 10 años
Usando la notación ABCD para una tabla de 2 x 2, la fórmula para la proporción de incidencia general es:
También podemos calcular la incidencia solo entre individuos expuestos:
\[I_{E+}=\frac{A}{(A+B)}=\frac{3}{4}=75 \text { per } 100 \text { in } 10 \text { years }\]
Así mismo, podemos calcular la incidencia solo entre individuos no expuestos:
\[\mathrm{I}_{\mathrm{E}-}=\frac{C}{(C+D)}=\frac{2}{6}=33 \text { per } 100 \text { in } 10 \text { years }\]
Recordemos que nuestro objetivo original con el estudio de cohortes fue ver si la exposición está asociada con la enfermedad. Por lo tanto, necesitamos comparar el I E+ con el I E-. La forma más común de hacer esto es calcular su relación combinada:
\[\text { Risk Ratio }=\frac{I_{E+}}{I_{E-}}=\frac{75 \text { per } 100 \text { in } 10 \text { years }}{33 \text { per } 100 \text { in } 10 \text { years }}=2.27\]
Usando la notación ABCD, la fórmula para RR es:
\[RR=\frac{\frac{A}{(A+B)}}{\frac{C}{(C+D)}}\]
Tenga en cuenta que los ratios de riesgo (RR) no tienen unidades, ya que las unidades dependientes del tiempo para las 2 incidencias cancelan.
Si el RR es mayor a 1, significa que observamos más enfermedad en el grupo expuesto que en el grupo no expuesto. De igual manera, si el RR es menor de 1, significa que observamos menos enfermedad en el grupo expuesto que en el grupo no expuesto. Si asumimos causalidad, una exposición con un RR < 1 está previniendo la enfermedad, y una exposición con un RR > 1 es causante de enfermedad. El valor nulo para una razón de riesgo es de 1.0, lo que significaría que no se observó asociación entre la exposición y la enfermedad. Se puede ver cómo sería este el caso—si la incidencia fuera idéntica en los grupos expuestos y no expuestos, entonces el RR sería 1, ya que x dividido por x es 1.
Debido a que el valor nulo es 1.0, se debe tener cuidado si se usan las palabras mayor o menor al interpretar RR. Por ejemplo, un RR de 2.0 significa que la enfermedad es dos veces más común, o dos veces más alta, en los expuestos en comparación con los no expuestos, no es que sea 2 veces más común, o 2 veces mayor, que sería un RR de 3.0 (ya que el valor nulo es 1, no 0). Si no ves la distinción entre estos, no te preocupes, solo memoriza y usa la frase plantilla a continuación, y tu interpretación será correcta.
La interpretación correcta de un RR es:
Usando nuestro ejemplo de fumado/HTN:
La frase clave es veces más alta; con ella, la oración plantilla funciona independientemente de que el RR esté por encima o por debajo de 1. Para un RR de 0.5, decir “0.5 veces más alto” significa que se multiplica el riesgo en los no expuestos por 0.5 para obtener el riesgo en los expuestos, produciendo una menor incidencia en los expuestos, como se espera con un RR < 1.
Si nuestro estudio de cohorte utilizó un enfoque persona-tiempo, la tabla 2 x 2 al final del estudio tendría una columna para la suma del tiempo-persona en riesgo (PTAR):
| D+ | D- | Total | σ PTAR | |
| E+ | 3 | 1 | 4 | 27.3 PY |
| E- | 2 | 4 | 6 | 52.9 PY |
| Total | 5 | 5 | 10 | 80.2 PY |
Ejemplo\(\PageIndex{2}\): Calculating the Rate Ratio from the Hypothetical Smoking/Hypertension Cohort Study
Utilizando un denominador persona-tiempo, la tasa de incidencia para el estudio general es:
Asimismo, la tasa de incidencia entre las personas expuestas es:
Y la incidencia entre las personas no expuestas es:
Nuevamente tomamos la relación de incidencia en los expuestos a incidencia en los no expuestos, esta vez calculando una razón de tasa (también abreviado RR):
Como al usar proporciones de incidencia, las unidades se cancelan, y nos quedamos con solo un número.
La interpretación es la misma que sería para la relación de riesgo; solo hay que sustituir la tasa de palabras por la palabra riesgo:
Observe que la frase de interpretación aún incluye la duración del estudio, aunque algunos individuos (los 4 que desarrollaron hipertensión) fueron censurados antes de ese tiempo. Esto se debe a que saber durante cuánto tiempo se siguió a las personas (y así se les dio tiempo para desarrollar la enfermedad) sigue siendo importante a la hora de interpretar los hallazgos. Como se discute en el capítulo 2, 100 años de persona-tiempo pueden acumularse en cualquier número de formas diferentes; saber que la duración del estudio fue de 10 años (en lugar de 1 año o 50 años) podría marcar la diferencia en términos de cómo (o si) se aplican los hallazgos en la práctica.
“Riesgo Relativo”
Tanto la razón de riesgo como la razón de tasas se abrevian RR. Esta abreviatura (y la relación de riesgo y/o razón de tasas) a menudo es referida por los epidemiólogos como riesgo relativo. Este es un ejemplo de léxico inconsistente en el campo de la epidemiología; en este libro, uso la relación de riesgo y la razón de tasas por separado (en lugar del riesgo relativo como término general) porque es útil, en mi opinión, para distinguir entre estudios que utilizan la población en riesgo vs. aquellos que utilizan un enfoque de tiempo de persona en riesgo. Independientemente, una medida de asociación llamada RR siempre se calcula como incidencia en los expuestos dividida por incidencia en los no expuestos.
Estudios de Cohortes Retrospectivos
A lo largo de este libro, me centraré en estudios prospectivos de cohortes. También se puede realizar un estudio de cohorte retrospectivo, mencionado aquí porque los médicos de salud pública y clínicos encontrarán estudios de cohortes retrospectivos en la literatura. En teoría, se realiza un estudio de cohorte retrospectivo exactamente igual que un estudio de cohorte prospectivo: uno comienza con una muestra no enferma de la población objetivo, determina quién estuvo expuesto y “sigue” la muestra por x días/meses/años, buscando casos incidentes de enfermedad. La diferencia es que, para un estudio retrospectivo de cohortes, todo esto ya ha sucedido, y se reconstruye esta información utilizando registros existentes. La forma más común de realizar estudios de cohortes retrospectivos es mediante el uso de registros de empleo (que a menudo tienen descripciones de puestos útiles para suponer exposición, por ejemplo, el gerente de piso probablemente estuvo expuesto a cualquier producto químico que estuviera en el piso de la fábrica, mientras que los oficiales de recursos humanos probablemente no lo estaban), médicos registros u otros conjuntos de datos administrativos (por ejemplo, registros militares).
Continuando con nuestro ejemplo de cohorte de 10 años de fumado/HTN, se podría hacer una cohorte retrospectiva usando registros médicos de la siguiente manera:
- Volver a todos los registros de hace 10 años y determinar quiénes ya tenían hipertensión (estas personas no están en riesgo y por lo tanto no son elegibles) o de otra manera no cumple con los criterios de inclusión de la muestra
- Determinar, entre los que estaban en riesgo hace 10 años, qué individuos eran fumadores
- Determinar qué miembros de la muestra desarrollaron hipertensión arterial durante los 10 años intermedios
Las cohortes retrospectivas se analizan al igual que las cohortes prospectivas, es decir, calculando ratios de tasa o ratios de riesgo. Sin embargo, para los estudiantes principiantes de epidemiología, las cohortes retrospectivas a menudo se confunden con estudios de casos y controles; por lo tanto, nos centraremos exclusivamente en cohortes prospectivas para el resto de este libro. (De hecho, de vez en cuando incluso científicos experimentados se confunden acerca de la diferencia e!) i
Ensayos Controlados Aleatorizados
El procedimiento para un ensayo controlado aleatorio (ECA) es exactamente el mismo que el procedimiento para una cohorte prospectiva, con una excepción: en lugar de permitir que los participantes se autoseleccionen en grupos “expuestos” y “no expuestos”, el investigador en un ECA asigna aleatoriamente a algunos participantes (generalmente la mitad) a “expuestos” y la otra mitad a “sin exponer”. En otras palabras, el estado de exposición se determina completamente por casualidad. Este es el tipo de estudio que requiere la Administración de Alimentos y Medicamentos para la aprobación de nuevos medicamentos: la mitad de los participantes en el estudio son asignados aleatoriamente al nuevo medicamento y la mitad al medicamento antiguo (o a un placebo, si el medicamento está destinado a tratar algo previamente intratable). El diagrama para un ECA es el siguiente:

Tenga en cuenta que la única diferencia entre un ECA y una cohorte prospectiva es el primer recuadro: en lugar de medir las exposiciones existentes, ahora le decimos a las personas si van a estar expuestas o no. Todavía estamos midiendo la enfermedad incidente y, por lo tanto, seguimos calculando la relación de riesgo o la razón de tasas.
Estudios Observacionales versus Experimentales
Los estudios de cohortes son una subclase de estudios observacionales, lo que significa que el investigador se limita a observar lo que sucede en la vida real: las personas en el estudio se autoseleccionan para estar expuestas o no dependiendo de sus preferencias personales y circunstancias de vida. Luego, el investigador mide y registra el nivel de exposición de una persona determinada. Los estudios transversales y de casos y controles también son observacionales. Los ensayos controlados aleatorios, por otro lado, son estudios experimentales: el investigador está realizando un experimento que implica decirle a las personas si estarán expuestas a una afección o no (por ejemplo, a un nuevo medicamento).
Estudios que utilizan datos de prevalencia
Seguir a los participantes mientras esperan casos incidentes de enfermedad es costoso y requiere mucho tiempo. A menudo, los epidemiólogos necesitan una respuesta más rápida (y más barata) a su pregunta sobre una combinación particular de exposición/enfermedad. En cambio, se podrían aprovechar los casos prevalentes de enfermedad, que por definición ya han ocurrido y por lo tanto no requieren esperar. Hay 2 diseños de este tipo que cubriré: estudios transversales y estudios de casos y controles. Para ambos, ya que no estamos utilizando casos de incidentes, no podemos calcular el RR, porque no tenemos datos de incidencia. En su lugar, calculamos la razón de probabilidades (OR).
Transversal
Los estudios transversales a menudo se denominan estudios instantáneos o de prevalencia: se toma una “instantánea” en un momento determinado, determinando quién está expuesto y quién está enfermo simultáneamente. El siguiente es un visual:

Tenga en cuenta que la muestra ya no está compuesta completamente por aquellos en riesgo porque estamos usando casos prevalentes, por lo que, por definición, alguna proporción de la muestra estará enferma al inicio del estudio. Como se mencionó, no podemos calcular el RR en este escenario, así que en su lugar calculamos el OR.
Ejemplo\(\PageIndex{3}\): Calculating the Odds Ratio from the Hypothetical Smoking/Hypertension Cross-Sectional Study
La fórmula para OR para un estudio transversal es:
\[\mathrm{OR}=\frac{\text { odds of disease in the exposed group }}{\text { odds of disease in the unexposed group }} \nonumber\]
Las probabilidades de un evento se definen estadísticamente como el número de personas que experimentaron un evento dividido por el número de personas que no lo experimentaron. Usando notación 2 × 2, la fórmula para OR es:
\[\mathrm{OR}=\frac{\frac{A}{B}}{\frac{C}{D}}=\frac{A D}{B C} \nonumber\]
Para nuestro ejemplo de fumado/HTN, si asumimos que esos datos provienen de un estudio transversal, el OR sería:
\[\mathrm{OR}=\frac{\frac{3}{1}}{\frac{2}{4}}=\frac{3 * 4}{2 * 1}=6.0 \nonumber\]
Nuevamente no hay unidades.
La interpretación de un OR es la misma que la de un RR, con la palabra odds sustituida por riesgo:
Obsérvese que ahora ya no mencionamos el tiempo, ya que estos datos provienen de un estudio transversal, que no implica tiempo. Al igual que con la interpretación de las RR, las OR mayores de 1 significan que la exposición es más común entre los enfermos, y las OR menores de 1 significan que la exposición es menos común entre los enfermos. El valor nulo vuelve a ser 1.0.
Para tablas 2 x 2 de estudios transversales, se puede calcular adicionalmente la prevalencia general de la enfermedad como
Finalmente, algunos autores se referirán a la OR en un estudio transversal como la razón de probabilidades de prevalencia, presumiblemente, solo como recordatorio de que se realizan estudios transversales sobre casos prevalentes. El cálculo de tal medida es exactamente el mismo que el OR presentado anteriormente.
O versus RR
Como puede ver en los datos de ejemplo (hipotéticos) de este capítulo, el OR siempre estará más lejos del valor nulo que el RR. Cuanto más común es la enfermedad, más esto es cierto. Si la enfermedad tiene una prevalencia de alrededor del 5% o menos, entonces la OR sí proporciona una aproximación cercana al RR; sin embargo, a medida que la enfermedad en cuestión se vuelve más común (como en este ejemplo, con una prevalencia de hipertensión del 40%), la OR se desvía cada vez más del RR.
Ocasionalmente, verá un estudio de cohorte (o muy raramente, un ECA) que reporta el OR en lugar del RR. Técnicamente esto no es correcto, porque las cohortes y ECA utilizan casos de incidentes, por lo que la mejor opción para una medida de asociación es el RR. Sin embargo, una técnica de modelado estadístico común, la regresión logística, calcula automáticamente las OR. Si bien es posible retrocalcular el RR a partir de estos números, muchas veces los investigadores no se molestan y en cambio solo reportan el OR. Esto es problemático por un par de razones: primero, es más fácil para los cerebros humanos interpretar los riesgos en lugar de las probabilidades y, por lo tanto, los riesgos deben usarse cuando sea posible; y segundo, los estudios de cohortes y ECA casi siempre tienen resultados relativamente comunes (ver capítulo 9), por lo que informar el OR hace que parezca como si la exposición es un problema mayor (o una mejor solución, si OR < 1) de lo que “realmente” es.
Caso-Control
El último tipo de estudio epidemiológico que se utiliza comúnmente es el estudio de casos y controles. También comienza con casos prevalentes y, por lo tanto, es más rápido y económico que los diseños longitudinales (cohorte prospectivo o ECA). Para realizar un estudio de casos y controles, primero se extrae una muestra de individuos enfermos (casos):
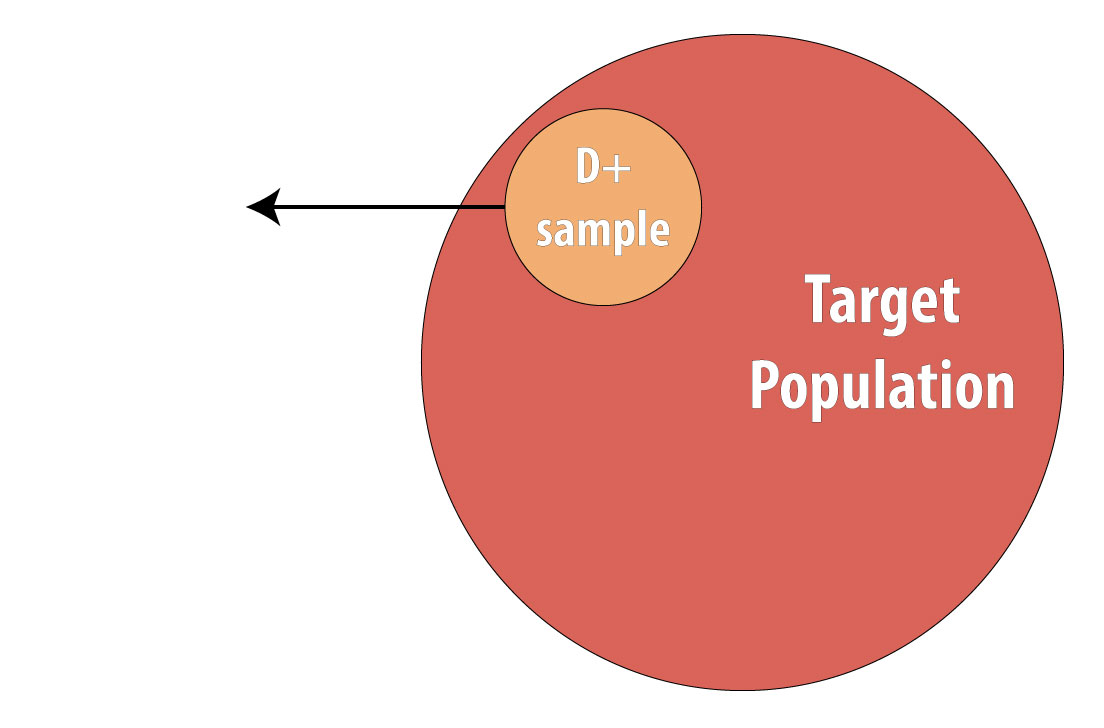
Luego una muestra de individuos no enfermos (controles):

Ante todo, señalar que tanto los casos como los controles provienen de una misma población subyacente. Esto es extremadamente importante, no sea que un investigador realice un estudio sesgado de casos y controles (ver capítulo 9 para más información sobre esto). Después del muestreo de casos y controles, se miden las exposiciones en algún momento del pasado. Esto podría ser ayer (por una enfermedad transmitida por los alimentos) o hace décadas (para la osteoporosis):

Nuevamente, no podemos calcular la incidencia porque estamos utilizando casos prevalentes, por lo que calculamos el OR de la misma manera que anteriormente. La interpretación es idéntica, pero ahora debemos referirnos al periodo de tiempo porque miramos explícitamente los datos de exposición pasada:
Tenga en cuenta, sin embargo, que no se puede calcular la prevalencia general de la muestra usando una tabla de 2 × 2 de un estudio de casos y controles, porque establecemos artificialmente la prevalencia en nuestra muestra (generalmente en 50%) eligiendo deliberadamente individuos que estaban enfermos para nuestros casos.
Exposición OR versus enfermedad OR
Técnicamente, para un estudio de casos y controles, se calcula la OR de la enfermedad en lugar de la exposición OR (que se presenta en estudios transversales). Es decir, ya que en los estudios de casos y controles comenzamos con la enfermedad, estamos calculando las probabilidades de estar expuestos entre quienes están enfermos en comparación con las probabilidades de estar expuestos entre quienes no están enfermos:
\[\mathrm{OR}_{\text {disease }}=\frac{(A / C)}{(B / D)}=\frac{A D}{B C}\]
La relación de probabilidades de exposición, recordará, calcula las probabilidades de estar enfermo entre quienes están expuestos, en comparación con las probabilidades de estar enfermos entre quienes no están expuestos:
\[\mathrm{OR}_{\text {exposure }}=\frac{(A / B)}{(C / D)}=\frac{A D}{B C}\]
En las clases avanzadas de epidemiología, se espera que se aprecien los matices de esta diferencia y se articule la justificación detrás de ella. Sin embargo, dado que tanto la exposición como la razón de probabilidades de la enfermedad se simplifican a la misma ecuación final, aquí no vamos a diferenciar entre ellas. La interpretación es la misma: un OR > 1 significa que la enfermedad es más común en el grupo expuesto (o la exposición es más común en el grupo enfermo, lo mismo), y un OR < 1 significa que la enfermedad es menos común en el grupo expuesto (o la exposición es menos común en el grupo enfermo, nuevamente, lo mismo).
Diferencia de riesgo
RR y OR se conocen como medidas relativas o de relación de asociación por razones obvias. Estas medidas pueden ser engañosas, sin embargo, si los riesgos absolutos (incidencias) son pequeños. [2] Por ejemplo, si se realizó un estudio de cohorte, y los investigadores observaron una incidencia en los expuestos de 1 por 1,000,000 en 20 años y una incidencia en los no expuestos, y una incidencia en los no expuestos de 2 por 1,000,000 en 20 años, el RR sería de 0.5: hay una reducción del 50% en la enfermedad en el grupo expuesto. ¡Rompe la intervención de salud pública! Sin embargo, esta medida de ratio enmascara una verdad importante: la diferencia absoluta de riesgo es bastante pequeña: 1 en un millón.
Para abordar este tema, los epidemiólogos a veces calculan en su lugar la diferencia de riesgo en su lugar:
\[RD = I_{E+} – I_{E-}\]
Desafortunadamente, esta medida absoluta de asociación no suele verse en la literatura, quizás porque la interpretación implica causalidad de manera más explícita o porque es más difícil controlar por variables confusas (ver capítulo 7) al calcular las medidas de diferencia.
Independientemente, en nuestro ejemplo de fumado/HTN, el RD es:
\[\mathrm{RD}=\mathrm{I}_{\mathrm{E}+}-\mathrm{I}_{\mathrm{E}-}=75 \text { per } 100 \text { in } 10 \text { years }-33 \text { per } 100 \text { in } 10 \text { years }=42 \text { per } 100 \text { in } 10 \text { years }\]
Obsérvese que el RD tiene las mismas unidades que la incidencia, ya que las unidades no cancelan al restar. La interpretación es la siguiente:
A lo largo de 10 años, el exceso de casos de HTN atribuible al tabaquismo es de 42; los 33 restantes habrían ocurrido de todos modos.
Se puede ver cómo esta interpretación asigna un papel causal más explícitamente a la exposición.
Más comunes (pero aún no tan comunes como las medidas de relación) son un par de medidas derivadas de la RD: el riesgo atribuible (AR) y el número necesario para tratar/número necesario para dañar (NNT/NNH).
El AR se calcula como RD/I E+. Aquí,
\[\mathrm{AR}=42 \text { per } 100 \text { in } 10 \text { years } / 75 \text { per } 100 \text { in } 10 \text { years }=56 \%\]
Interpretación:
El 56% de los casos se puede atribuir al tabaquismo, y el resto habría ocurrido de todos modos.
Nuevamente esto implica causalidad; además, debido a que todas las enfermedades tienen más de una causa (ver capítulo 10), los AR para cada posible causa sumarán bastante más del 100%, haciendo que esta medida sea menos útil.
Por último, calcular NNT/NNH (ambos similares, siendo el primero para exposiciones preventivas y el segundo para dañinas) es simple:
\[\text{NNT} = \dfrac{1}{\text{RD}\]
En nuestro ejemplo,
\[\mathrm{NNH}=1 / 42 \text { per } 100 \text { per } 10 \text { years }=1 / 0.42 \text { per } 10 \text { years }=2.4\]
Interpretación:
A lo largo de 10 años, por cada 2.4 fumadores, 1 desarrollará hipertensión.
Para una exposición protectora, el NNT (comúnmente utilizado en círculos clínicos) se interpreta como el número que necesita tratar para evitar un caso de mal desenlace. Para exposiciones dañinas, como en nuestro ejemplo de fumar /HTN, es el número necesario para estar expuesto para causar un mal resultado. Para muchos medicamentos de uso común, los NNTs están en los cientos o incluso miles. [iii] [iv]
Conclusiones
Los datos epidemiológicos a menudo se resumen en tablas 2×2. Existen 2 medidas principales de asociación comúnmente utilizadas en epidemiología: la relación riesgo/tasa (riesgo relativo) y la razón de probabilidades. El primero se calcula para diseños de estudio que recogen datos de incidencia: cohortes y ECA. Este último se calcula para diseños de estudio que utilizan casos prevalentes: estudios transversales y estudios de casos y controles. Las medidas absolutas de asociación (por ejemplo, la diferencia de riesgo) no se ven con tanta frecuencia en la literatura epidemiológica, pero siempre es importante tener en cuenta los riesgos absolutos (incidencias) al interpretar los resultados.
A continuación se muestra una tabla que resume los conceptos de este capítulo:
| Diseño de estudio | Resumen de métodos | ¿Incidente o casos prevalentes? | Medida Preferida de Asociación |
|---|---|---|---|
| Cohorte | Comience con una muestra no enferma, determine la exposición, siga con el tiempo. | Incidente | Ratio de riesgo o ratio de tasas |
| RCT | Comience con una muestra no enferma, asigne exposición, siga con el tiempo | Incidente | Ración de riesgo o relación de tasas |
| Caso-Control | Comience con enfermos (casos), reclute no enfermos comparables (controles), observe exposiciones previas | Prevalente | Ratio de probabilidades |
| Transversal | A partir de una muestra, evaluar simultáneamente el estado de exposición y el estado de la enfermedad | Prevalente | Ratio de probabilidades |
Referencias
i. Bodner K, Bodner-Adler B, Wierrani F, Mayerhofer K, Fousek C, Niedermayr A, Grünberger. Efectos del parto en agua sobre los resultados maternos y neonatales. Wien Klin Wochenschr. 2002; 114 (10-11) :391-395. (Regreso)
ii. Declercq E. El poder absoluto del riesgo relativo en los debates sobre cesáreas repetidas y parto domiciliario en Estados Unidos. J Clin Ética. 2013; 24 (3) :215-224.
iii. Mørch LS, Skovlund CW, Hannaford PC, Iversen L, Fielding S, Lidegaard Ø. Anticoncepción hormonal contemporánea y riesgo de cáncer de mama. N Engl J Med. 2017; 377 (23) :2228-2239. doi:10.1056/Nejmoa1700732 (Regreso)
iv. Brisson M, Van de Velde N, De Wals P, Boily M-C. Estimar el número necesario para vacunar para prevenir enfermedades y muertes relacionadas con la infección por el virus del papiloma humano. CMAJ Can Med Assoc J. 2007; 177 (5) :464-468. doi:10.1503/cmaj.061709 (Regreso)
- Estos 4 diseños de estudio son la base de casi todos los demás (por ejemplo, los estudios de casos cruzados son un subtipo de estudios de casos y controles). Algunos diseños adicionales están cubiertos en el capítulo 9, pero una comprensión firme de los 4 diseños cubiertos en este capítulo pondrá a los estudiantes de epidemiología comenzando a ser capaces de leer críticamente esencialmente toda la literatura.
- Declercq E. El poder absoluto del riesgo relativo en los debates sobre cesáreas repetidas y parto domiciliario en Estados Unidos. J Clin Ética. 2013; 24 (3) :215-224