
1.9: Diseños de estudio revisados
- Page ID
- 121628

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
Después de leer este capítulo, podrás hacer lo siguiente:
- Comparar y contrastar las fortalezas y limitaciones de los estudios de cohortes, casos y controles, transversales y ensayos controlados aleatorios
- Describir estudios ecológicos y explicar la falacia ecológica
- Describir el uso adecuado de una revisión sistemática y metaanálisis
Ahora que tenemos una comprensión firme de las posibles amenazas para estudiar la validez, en este capítulo volveremos a examinar los 4 diseños principales de estudios epidemiológicos, enfocándonos en fortalezas, debilidades y detalles importantes. También describiré algunos otros diseños de estudio que pueda ver, luego terminaré con una sección sobre revisiones sistemáticas y metaanálisis, que son métodos formales para sintetizar un cuerpo de literatura sobre un tema determinado de exposición/enfermedad.
Cohortes
Recordemos del capítulo 4 que un estudio de cohorte consiste en extraer una muestra en riesgo (no enferma) de la población, evaluar los niveles de exposición y luego seguir a la cohorte a lo largo del tiempo y observar la enfermedad incidente:

Los estudios de cohortes son un diseño de estudio muy fuerte, lo que significa que son menos propensos a sesgos y errores lógicos relacionados con la temporalidad que otros diseños. Primero, debido a que comenzamos con una muestra no enferma, para lo cual evaluamos inmediatamente el estado de exposición, sabemos que la exposición vino primero. Debido a esto, es poco probable que las cohortes tengan una clasificación errónea de la exposición diferencialmente según el estado de la enfermedad porque la exposición se mide antes de que se conozca el estado de la enfermedad (la clasificación errónea del estado de la enfermedad diferencialmente por exposición, sin embargo, sigue siendo un riesgo).
Temporalidad de Cohorte y Periodos Latentes
Para las enfermedades que tienen un largo período latente —es decir, que el inicio biológico de la enfermedad ocurre mucho antes de que se detecte y diagnostique la enfermedad— es posible que algunas de nuestras muestras “no enfermas” estén realmente enfermas pero que aún no hayan sido diagnosticadas. Esto podría suceder, por ejemplo, para un paciente con cáncer mientras su tumor aún es demasiado pequeño para detectarlo. Al realizar estudios sobre padecimientos con periodos latentes largos conocidos o sospechados, los epidemiólogos a menudo excluirán de la muestra a cualquier participante en el que se diagnostique la enfermedad durante los primeros meses de seguimiento, teorizando que esos individuos no estaban realmente libres de enfermedad al inicio del estudio.
En segundo lugar, debido a que los estudios de cohortes buscan la enfermedad incidente, no confunden el padecimiento de la persona con el tiempo que la ha tenido, como lo hacen los estudios de prevalencia (ver capítulo 2 para una discusión sobre la relación matemática entre incidencia, prevalencia y duración de la enfermedad).
En tercer lugar, son el único diseño de estudio que se puede utilizar para evaluar exposiciones raras. Si la exposición es poco común dentro de la población objetivo (digamos, se puede esperar que 10% o menos personas estén expuestas), entonces los estudios de cohortes pueden muestrear deliberadamente a individuos expuestos para garantizar suficiente poder estadístico (la celda más pequeña en la tabla 2 × 2 impulsa la potencia) sin necesitando una muestra irrazonablemente grande. Por ejemplo, si nos preocupan las exposiciones químicas en una fábrica en particular, podríamos inscribir a trabajadores expuestos de esa fábrica así como a un grupo de trabajadores no expuestos de otra fábrica (verificando primero, por supuesto, para asegurarnos de que la segunda fábrica esté realmente libre de exposición) y seguir ambos grupos, buscando enfermedad incidente.
Lo que lleva muy bien a la cuarta fortaleza: se pueden evaluar múltiples resultados en una misma cohorte. En nuestro ejemplo de fábrica anterior, los trabajadores expuestos de la Fábrica 1 y los trabajadores no expuestos de la Fábrica 2 pueden ser seguidos por cualquier enfermedad razonablemente común. (Qué tan común es una llamada de juicio, también podríamos vigilar y rastrear enfermedades poco comunes, siempre y cuando reconozcamos que esos análisis serían poco potentes). Podríamos buscar enfermedades cardíacas de nueva aparición, leucemia, fibromialgia, diabetes, muerte o cualquier otra cosa de interés. Si observamos más de un resultado, entonces también debemos medir todos los resultados de interés en la muestra al inicio. Entonces, para los análisis de cada resultado específico, simplemente eliminamos de la cohorte a las personas que no estaban en riesgo de ese resultado. Por ejemplo, si la Persona A se une a nuestro estudio de fábrica, y al inicio del estudio ya tienen hipertensión pero no tienen melanoma, entonces no incluiríamos a esa persona en los análisis donde la hipertensión es el resultado de la enfermedad. Sin embargo, sus datos podrían incluirse en análisis donde el melanoma es el resultado de la enfermedad, ya que estaban en riesgo de padecer melanoma al inicio del estudio.
Los estudios de cohortes también se pueden utilizar para estudiar múltiples exposiciones, siempre y cuando estas exposiciones sean lo suficientemente comunes como para que no necesitemos muestrear deliberadamente el estado de exposición. Para ello, solo tomaríamos una muestra de la población objetivo, y evaluaríamos multitud de exposiciones. Si queremos evaluar también más de un resultado, entonces necesitamos medir todos los estados de enfermedad de interés al inicio para que los análisis eventuales puedan restringirse a la población en riesgo, como se discutió anteriormente. Esta capacidad de observar múltiples resultados, y potencialmente también múltiples exposiciones, agrega eficiencia a los estudios de cohortes, ya que esencialmente podemos realizar numerosos estudios a la vez.
El estudio del corazón de Framingham es un ejemplo clásico de un estudio de cohorte que evaluó múltiples exposiciones y múltiples resultados. Este estudio, una colaboración entre el Instituto Nacional de Corazón, Pulmón y Sangre de Estados Unidos (una división de los Institutos Nacionales de Salud) y la Universidad de Boston, comenzó en 1948 con la inscripción de poco más de 5,000 adultos que viven en Framingham, Massachusetts. Los investigadores midieron numerosas exposiciones y resultados, luego repitieron las mediciones cada pocos años. A medida que la cohorte envejece, se han inscrito sus cónyuges, hijos, cónyuges de hijos y nietos. El estudio Framingham es responsable de gran parte de nuestro conocimiento sobre enfermedades cardíacas, accidentes cerebrovasculares y trastornos relacionados, así como de los efectos intergeneracionales de algunos hábitos de estilo de vida. Más información y una lista de publicaciones adicionales (se han publicado más de 3,500 estudios utilizando datos de Framingham) se puede encontrar aquí.
Los estudios de cohortes también tienen desventajas. No se pueden utilizar para estudiar enfermedades raras porque la cohorte tendría que ser demasiado grande para ser práctica. Por ejemplo, la fenilcetonuria es un trastorno metabólico genético que afecta a aproximadamente 1 de cada 10,000 bebés nacidos en Estados Unidos. 1 Para conseguir incluso 100 individuos afectados, entonces, necesitaríamos inscribir a un millón de mujeres embarazadas en nuestro estudio, un número que no es ni práctico ni factible.
Además, los estudios prospectivos de cohortes son costosos. Seguir a las personas a lo largo del tiempo requiere un poco de esfuerzo, lo que significa que los costos de personal del estudio son altos. Debido a esto, los estudios de cohortes no pueden utilizarse para estudiar enfermedades con inducción de décadas o periodos latentes.
Por ejemplo, sería difícil realizar un estudio de cohorte que analice si el consumo de productos lácteos en adolescentes está asociado con osteoporosis en mujeres de 80 años, ya que seguir a adolescentes actuales desde hace 60 años o más sería extremadamente difícil. En líneas similares, los sesgos de selección relacionados con la falta de seguimiento pueden ser severos en estudios de larga duración: cuanto más tiempo intentemos seguir a las personas, más probable es que se muevan, cambien números de teléfono/direcciones de correo electrónico, o se cansen de llenar una encuesta cada año y simplemente dejen de participar. Más preocupante sería si las personas que empiezan a sentirse enfermas son las que dejan de responder las consultas del equipo de estudio. ¿Y si estas personas se sintieran enfermas porque estaban a punto de ser diagnosticadas con el resultado en estudio? A pesar de esta dificultad, existen algunos estudios de cohortes largos como Framingham y han arrojado ricos conjuntos de datos y mucho conocimiento sobre la salud humana.
Ensayos Controlados Aleatorizados
Recordemos del capítulo 4 que un ECA es conceptualmente como una cohorte, con una diferencia: el investigador determina el estado de exposición.

Así, todas las fortalezas y debilidades de los estudios de cohortes se aplican también a los ECA, con una excepción: para estudiar múltiples exposiciones, se necesitaría re-aleatorizar para cada exposición. Algunos estudios lo han logrado con éxito (la Women's Health Initiative, por ejemplo, aleatorizó a las mujeres tanto a terapia de reemplazo hormonal como a placebo, y también, por separado, a suplementos de calcio o placebo), pero prácticamente hablando los ECA generalmente se limitan a una exposición.
Una fortaleza adicional de un ensayo aleatorizado (que no se aplica a los estudios de cohortes) es que si el estudio es lo suficientemente grande (al menos varios cientos de participantes) y la asignación de la exposición es verdaderamente aleatoria (es decir, no “todas las demás personas” o algún otro esquema predecible), entonces no habrá confusión. Se puede controlar, estadísticamente, para los factores de confusión medidos en un estudio de cohortes (ver capítulo 7), pero ¿qué pasa con los factores de confusión desconocidos y/o no medidos? La característica clave de la aleatorización es que da cuenta de todos los factores de confusión: conocidos, desconocidos, medidos y no medidos.
Recordemos del capítulo 7 que para que una variable actúe como confusadora, debe cumplir estas condiciones:

La variable debe causar el desenlace, estar estadísticamente asociada con la exposición, y no estar en la vía causal (por lo que la exposición no causa el confuso). Al asignar aleatoriamente la exposición, hemos asegurado que no existen variables que estén asociadas con la exposición.
La imagen ahora se ve así:

Debido a que no hay variables más comunes en el grupo expuesto que el grupo no expuesto (o viceversa), nos hemos librado de toda confusión posible. Los beneficios de esto en términos de validez de estudio interno no pueden ser exagerados.
Sin embargo, los ECA también tienen limitaciones, y estas no deben pasarse por alto. En primer lugar, son incluso más caros que los estudios de cohortes. En segundo lugar, a menudo hay consideraciones éticas que hacen que el diseño del ensayo aleatorio sea inutilizable. Por ejemplo, en este punto, no podríamos justificar éticamente aleatorizar a las personas a una exposición al tabaquismo (debido a que sus daños están muy bien documentados, no podemos pedirle a la gente que comience a fumar para nuestro estudio). Tampoco podemos aleatorizar dónde vive la gente, pero ciertamente dónde vive la gente tiene un profundo efecto en su salud. ii Los estudios observacionales de estas exposiciones, por otro lado, son éticamente viables porque las personas ya han optado por fumar y dónde vivir, y el epidemiólogo se limita a medir estas exposiciones existentes.
En tercer lugar, los ECA suelen tener problemas de generalización porque los tipos de personas que están dispuestas a participar en un estudio donde ellos (el participante) no pueden elegir en qué grupo de estudio estar no son un subconjunto aleatorio de la población general. Por ejemplo, si las únicas personas que tienen tiempo para participar en nuestra intervención de actividad física son las personas jubiladas, entonces ¿podemos generalizar a la población (presumiblemente más joven) que sigue trabajando? Tal vez, pero quizás no. Los investigadores que realizan ECA también restringen demasiado los criterios de inclusión en la medida en que los resultados no son generalizables a la población general. Por ejemplo, un conocido ensayo de control de la presión arterial en adultos mayores excluyó a aquellos con diabetes, cáncer y una serie de otras comorbilidades. iii Dado que la mayoría de las personas mayores tienen al menos una de estas enfermedades crónicas, ¿a quién podemos aplicar realmente los resultados?
Por último, tenemos que precisar con precisión la exposición en un ECA. Si estamos haciendo una intervención de actividad física, ¿vamos a pedir a los aleatorizados al grupo expuesto que caminen? ¿Tomar una clase de yoga? ¿Hacer entrenamiento de fuerza supervisado? Si es así, ¿cuánto? ¿Con qué frecuencia? ¿Con cuánta intensidad? ¿Por cuántas semanas o meses? En un estudio de cohorte, evaluaríamos la actividad física que las personas están haciendo de todos modos, y habría una gran variedad de respuestas, que luego podríamos categorizar de muchas maneras. Con un ensayo aleatorizado, tenemos que decidir sobre todos los detalles. Si nos equivocamos, o si aplicamos la intervención en el momento equivocado en el proceso de la enfermedad, podría parecer que no hay exposición/asociación de enfermedad, cuando realmente la hay y nuestra exposición estuvo ligeramente apagada de alguna manera.
Los ensayos aleatorizados a menudo se denominan el “estándar de oro” de la investigación epidemiológica y clínica debido a su capacidad para minimizar la confusión. Sin embargo, sus inconvenientes son sustanciales, y los estudios observacionales bien realizados no necesariamente deben descartarse simplemente porque no son ECA. Sin embargo, los ECA juegan un papel enorme particularmente en la medicina, ya que la Administración de Alimentos y Medicamentos (FDA) requiere múltiples ECA antes de aprobar nuevos medicamentos y dispositivos médicos. Debido a los estrictos requisitos de la FDA, los protocolos para ensayos aleatorios deben registrarse (en clinicaltrials.gov) antes del inicio de cualquier recolección de datos.
Fuera de la investigación y desarrollo farmacéutico, los ECA, por sus fortalezas metodológicas, tienen el potencial de cambiar la práctica cuando surgen evidencias de estudios nuevos, grandes y bien diseñados. Por ejemplo, en 2005 el Dr. Paul Ridker y sus colegas cambiaron absolutamente la forma en que los médicos pensaban sobre la profilaxis de enfermedades cardíacas en mujeres iv Antes de la publicación de este gran ensayo (20,000 mujeres en cada grupo), asumimos que, al igual que los hombres, las mujeres mayores deberían tomar una aspirina de bebé cada dos días para prevenir ataques cardíacos. Sin embargo, el ensayo Ridker demostró que la aspirina actúa de manera diferente en las mujeres (¡el género es un modificador de efectos!) , y el régimen de aspirina-a-día-prevene-ataques cardíacos no funcionará para la mayoría de las mujeres.
Estudios de casos y controles
Un estudio de casos y controles es un diseño retrospectivo en el que comenzamos encontrando un grupo de casos (personas que tienen la enfermedad en estudio) y un grupo comparable de controles (personas que no tienen la enfermedad):

Un error común que cometen los estudiantes iniciadores de epidemiología es afirmar que “los casos son personas con la enfermedad, que están expuestas”. Esto es incorrecto. Los casos son personas con la enfermedad, y para evitar una clasificación errónea diferencial, es importante que tanto los casos como los controles sean reclutados sin tener en cuenta el estado de exposición. Una vez que hemos identificado todos los casos y controles, entonces evaluamos qué personas estuvieron expuestas.
Debido a que no requieren seguir a las personas a lo largo del tiempo, los estudios de casos y controles son mucho más baratos de realizar que las cohortes o los ensayos aleatorios. También proporcionan una manera eficiente de estudiar enfermedades raras y enfermedades con largos periodos de inducción y/o latentes. Los estudios de casos y controles pueden evaluar múltiples exposiciones, aunque se limitan a un resultado por definición.
Los estudios de casos y controles evalúan la exposición en el pasado. Ocasionalmente, estos datos de exposición pasada provienen de registros existentes (por ejemplo, registros médicos para el historial de presión arterial de una persona), pero generalmente nos basamos en cuestionarios. Por lo tanto, los estudios de casos y controles están sujetos a sesgos de recuerdo, más que a los diseños Los epidemiólogos que realizan estudios de casos y controles deben tener especial cuidado con el recuerdo diferencial por estado de caso. Es plausible que las personas con un padecimiento determinado hayan pasado tiempo pensando en lo que pudo haberla causado y así poder reportar exposiciones pasadas con mayor detalle que los miembros del grupo de control. Independientemente del estado del caso, las preguntas que se hagan deben ser posibles para que las personas respondan. Nadie puede decir con certeza exactamente lo que comieron en un día en particular hace una década; sin embargo, la mayoría de la gente probablemente pueda recordar qué tipo de alimentos suelen comer la mayoría de los días. Por lo tanto, los detalles se sacrifican en favor de una mayor precisión de imagen (que aún puede tener una validez cuestionable, dependiendo de los recuerdos de las personas). Recuerda de los capítulos 5 y 6: pregúntate: “¿La gente me puede decir esto? ¿La gente me dirá esto?”
La selección adecuada de los controles es primordial en los estudios de casos y controles, pero desafortunadamente, quién constituye un control “adecuado” no siempre es obvio de inmediato. Para evitar sesgos de selección, los casos y controles deben provenir de la misma población objetivo, es decir, si los controles hubieran estado enfermos con la enfermedad en cuestión, ellos también habrían sido casos.
Por ejemplo, si los casos son reclutados en un hospital en particular, entonces se deben tomar muestras de controles de la población de personas que también habrían buscado atención en ese hospital de ser necesario. Esto parece bastante sencillo, pero no siempre es fácil de traducir a la práctica. Si estamos estudiando lesión cerebral traumática (TBI) en niños en Oregon, un buen lugar para encontrar casos sería en el Hospital Infantil Doernbecher en Portland. Otros hospitales en todo el noroeste del Pacífico envían a niños con TBI graves a Doernbecher, donde hay una gran cantidad de especialistas pediátricos disponibles para atenderlos; este hospital cuenta con un número suficiente de casos para nuestro estudio.
¿De dónde sacaríamos los controles? Una posibilidad sería tomar como controles a otros niños que son pacientes en Doernbecher, por un padecimiento distinto al TBI. Esto satisface el criterio de que los controles también obtendrían atención en este hospital, porque están recibiendo atención en este hospital. Sin embargo, en la medida en que los niños que reciben atención por otras afecciones también pueden tener antecedentes de exposición inusuales, esto podría llevar a estimaciones sesgadas de asociación. Otra opción sería designar como controles a niños que no estén enfermos, muestreados quizás de un barrio de Portland o dos. Sin embargo, esto también conduciría a sesgos de selección, porque Doernbecher es un hospital de referencia, recibiendo como pacientes a niños de un radio de varios cientos de millas, no solo niños que viven en Portland. Si los niños que viven en zonas más rurales son diferentes a los que viven en la ciudad, tendríamos estimaciones sesgadas de asociación.
La conclusión es que no existe una manera perfecta de reclutar controles, y a los epidemiólogos les encanta hacer agujeros en los grupos de control de otras personas para estudios de casos y controles v, vi (esto se considera un buen deporte en las conferencias de epidemiología). Una forma de reducir el sesgo del grupo de control es reclutar múltiples grupos de control, tal vez uno basado en el hospital y uno comunitario. Si los resultados no son sustancialmente diferentes, entonces cualquier sesgo de selección que esté operando quizás no esté influyendo demasiado en los resultados.
Para las enfermedades crónicas de larga duración vuelve a entrar en juego el tema de la duración de la enfermedad. Para evitar problemas de temporalidad, debemos conocer como mínimo la fecha de diagnóstico y asegurarnos de que estamos evaluando exposiciones que ocurrieron mucho antes de esa fecha. Por condiciones para las que se desconocen los periodos de inducción y latente, los investigadores a veces realizarán un estudio de casos y controles que recluta casos incidentes de enfermedad durante un periodo de varios meses. Así, tan pronto como se reclutan los casos, podemos preguntar sobre exposiciones pasadas con la confianza de que al menos el diagnóstico del caso ocurrió después de esas exposiciones. Si bien un largo período latente podría seguir siendo un problema, una forma de evitar esto sería preguntar sobre las exposiciones en varios períodos de tiempo, digamos, hace 0 a 5 años, hace 6 a 10 años, hace 11 a 15 años, y así sucesivamente, y comparar los resultados a través de estas ventanas.
A pesar de estas dificultades, los estudios de casos y controles han hecho aportes sustanciales a nuestro conocimiento sobre salud a lo largo de los años. El reporte de 1964 del cirujano general Smoking and Health vii, por ejemplo, se basó en la literatura derivada de un estudio de casos y controles realizado por Richard Doll y Austin Bradford Hill. viii
Estudios Transversales
Recordemos del capítulo 4 que en un estudio transversal, extraemos una sola muestra de la población objetivo y evaluamos la exposición actual y el estado de enfermedad en todos:

La principal fortaleza de los estudios transversales es que son los estudios más rápidos y económicos de realizar. Por lo tanto, se utilizan para muchas actividades de vigilancia: la Encuesta Nacional de Examen de Salud y Nutrición (NHANES), el Sistema de Monitoreo de Evaluación del Riesgo de Embarazo (PRAMS) y el Sistema de Vigilancia de Factores de Riesgo Conductual (BRFSS) son todos estudios transversales que se repiten con una nueva muestra cada año (ver capítulo 3) y en otras situaciones donde los recursos puedan ser limitados y/o se requieran respuestas inmediatas.
Los estudios transversales están limitados por el hecho de que no tomamos muestras para exposición ni enfermedad y que en su lugar “obtenemos lo que obtenemos” al extraer nuestra muestra de la población. Por lo tanto, no pueden ser utilizados ni para exposiciones raras ni para enfermedades raras.
Otra limitación es que no tenemos datos sobre la temporalidad: no sabemos si la exposición o la enfermedad vinieron primero porque estamos midiendo la prevalencia de ambos en el mismo momento.
Los estudios transversales junto con la vigilancia (que solo mira las medidas de frecuencia de la enfermedad, no las relaciones de exposición/enfermedad) se limitan así a actividades de generación de hipótesis. No podemos tomar (no vigilancia) de salud pública o decisiones clínicas basadas en evidencia únicamente de estos estudios.
Informes de casos/Serie de casos
En la literatura clínica, a menudo se ven reportes de casos. Se trata de breves blurbs que informan de un paciente interesante e inusual visto por un médico o clínica en particular. Una serie de casos es lo mismo pero describe a más de un paciente, generalmente solo unos pocos, ix, x pero a veces varios cientos. xi Los reportes de casos y las series de casos tienen poco valor para los epidemiólogos porque no son estudios per se; no tienen grupos de comparación. Si se publica una serie de casos diciendo que 45% de los pacientes en esta serie con enfermedad Y también tienen la enfermedad Z, esta no es información útil para un epidemiólogo. ¿Cuántos pacientes que no tienen la enfermedad Y también tienen la enfermedad Z? Sin datos sobre un grupo comparable de pacientes que no presentan la enfermedad Y, no hay nada que hacer con el 45% del punto de datos dado en la serie de casos.
Dicho esto, los informes de casos y las series de casos pueden ser sumamente útiles para los profesionales de la salud pública. Debido a que por definición presentan datos de pacientes inusuales, a menudo pueden actuar como una especie de vigilancia centinela, llamando nuestra atención sobre una nueva amenaza emergente para la salud pública. Por ejemplo, en 1941, un médico de Australia notó un aumento en una especie de defecto congénito que afectaba los ojos del lactante. Publicó esto como una serie de casos, xii planteando la hipótesis de que la infección materna por rubéola era la causa. Otros médicos de todo el mundo intervinieron en que ellos también habían visto un reciente aumento repentino de este defecto congénito en mujeres cuyos embarazos se complicaron por la rubéola, xiii, xiv, xv lo que llevó a nuestra práctica actual de verificar si hay anticuerpos contra la rubéola en todas las mujeres embarazadas y vacunarlas sin inmunidad. Como otro ejemplo, a principios de la década de 1980, un conjunto de series de casos publicadas por los Centros para el Control y la Prevención de Enfermedades (CDC) en su Informe Semanal de Morbilidad y Mortalidad llamó nuestra atención sobre tipos inusuales de cánceres e infecciones oportunistas que ocurren en poblaciones que por lo demás serían jóvenes y sanas. nuestro primer indicio de la epidemia de VIH/SIDA. x, xvi, xvii, xviii Más recientemente, en 2003, los informes de casos que detallaban una infección respiratoria inusual y mortal en personas que viajaban a Hong Kong llevaron a un aumento de la salud pública mundial y la conciencia clínica de este inusual conjunto de síntomas, permitiendo la cuarentena inmediata de los individuos afectados que tenían viajó de regreso a Toronto. xix, xx, xxi Esta rápida acción impidió que el SARS se convirtiera en una pandemia global.
Estudios Ecológicos
Los estudios ecológicos son aquellos en los que se utilizan datos a nivel de grupo (generalmente geográficos) para comparar las tasas de enfermedades y/o comportamientos de la enfermedad. Por ejemplo, esta imagen que muestra la variación en el uso del cinturón de seguridad por estado del capítulo 1 es una especie de estudio ecológico:

Al comparar las tasas de uso del cinturón de seguridad en diferentes estados, estamos comparando datos a nivel de grupo, no datos de individuos. Si bien es útil, este tipo de imagen puede llevar a muchos errores en la lógica. Por ejemplo, asume que todos en un estado dado son exactamente lo mismo, obviamente esto no es cierto. Si bien es cierto que en promedio, las personas en Oregon usan el cinturón de seguridad con más frecuencia que las personas de Idaho, esto no significa que todos en Oregon usen su cinturón de seguridad con más frecuencia que todos en Idaho. Podríamos encontrar fácilmente a alguien en Oregon que nunca use el cinturón de seguridad y alguien en Idaho que siempre lo haga.
El error lógico anterior —atribuir números a nivel de grupo a cualquier individuo— es un ejemplo de la falacia ecológica. Esto también entra en juego al observar los patrones tanto de exposición como de enfermedad utilizando datos a nivel de grupo, como en este ejemplo, al observar el consumo per cápita de arroz y la mortalidad materna en cada país:
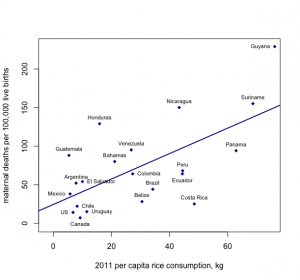
Figura 9-8. Creado con datos de aquí y aquí.
Al mirar esta gráfica, parece que cuanto más arroz consuman los ciudadanos de un país en particular, mayor es la tasa de mortalidad materna. La falacia ecológica aquí se derivaría de asumir que son los consumidores de arroz los que están muriendo por complicaciones relacionadas con el embarazo o el parto, pero no podemos saber si esto es cierto usando solo datos a nivel de grupo.
Con todos estos problemas, entonces, ¿por qué realizar estudios ecológicos? Aún más que los estudios transversales, son rápidos y baratos. También utilizan siempre datos preexistentes: estimaciones censales para los ingresos por condado; la cantidad de algún producto (como el arroz) consumida por un grupo determinado de personas (a menudo rastreadas por los vendedores de ese producto); e información registrada sobre la prevalencia de ciertas enfermedades (generalmente disponible públicamente a través de los sitios web de ministerios de salud de diversos países o como comparaciones por países publicadas por la Organización Mundial de la Salud). El uso de estudios ecológicos se limita sólo a la generación de hipótesis, pero son tan fáciles que pueden ser un buen primer paso para una pregunta de investigación totalmente nueva.
Revisiones sistemáticas y metaanálisis
Debido a que la epidemiología se basa en los humanos, es más propensa tanto al sesgo como a la confusión que otras ciencias. ¿Esto lo vuelve inútil? Absolutamente no, aunque hay que tener una apreciación sólida de los supuestos y limitaciones inherentes a los estudios epidemiológicos. Una de estas limitaciones es que salvo ensayos controlados aleatorios excepcionalmente bien hechos (como el ensayo Ridker, iv mencionado anteriormente), rara vez cambiamos la salud pública o la política clínica con base en un solo estudio epidemiológico. Más bien, hacemos un estudio, luego otro, y luego otro, utilizando cada vez mejores diseños de estudio hasta que finalmente hay un cuerpo de evidencia sobre un tema que proviene de diferentes poblaciones, utiliza diferentes diseños de estudio, tal vez mide la exposición de maneras ligeramente diferentes, y así sucesivamente. Si todos estos estudios tienden a mostrar los mismos resultados generales (al igual que todos los estudios tempranos sobre tabaquismo y cáncer de pulmón), entonces comenzamos a pensar que la asociación podría ser causal (ver capítulo 10 para más detalles sobre esto) e implementamos cambios de salud pública o clínicos.
Cuando los resultados de los estudios existentes sobre un tema son más mixtos, existe una manera formal de sintetizar sus resultados en todos ellos, para llegar a “la” respuesta: metaanálisis (o revisión sistemática, difieren ligeramente, como se discute a continuación). El procedimiento para cualquiera de estos es el mismo:
- Determine el tema con precisión. ¿Nos importan los correlatos de la actividad física en los niños en general, o solo en la clase de educación física en la escuela? ¿Sólo en casa? ¿En todas partes? ¿Nuestro enfoque es todos los niños o solo los niños de la escuela primaria? ¿Sólo adolescentes? A menudo no hay una respuesta correcta, pero al igual que con la definición de nuestra población objetivo (ver capítulo 1), esto debe decidirse con anticipación.
- Buscar sistemáticamente en la literatura artículos relevantes. Por sistemáticamente, me refiero a usar y documentar términos de búsqueda específicos y colocar límites documentados (idioma, fecha de publicación, etc.) en los resultados de búsqueda. La clave es hacer que la búsqueda sea replicable por otros. No es aceptable solo incluir artículos que los autores conocen sin buscar otros en la literatura; hacerlo da como resultado una muestra sesgada de todos los trabajos que deberían haber sido incluidos.
- Reduzca los resultados de búsqueda a solo aquellos que aborden directamente el tema como se determina en el Paso 1.
- Para cada uno de los estudios a incluir, se resumen los datos clave: los métodos de definición y medición de la exposición, la definición de resultados y los métodos de medición, cómo se dibujó la muestra, la población objetivo, los principales resultados, etc.
- Determinar si los trabajos son lo suficientemente similares para el metaanálisis (existen procedimientos estadísticos formales para probarlo, que están más allá del alcance de este libro). xxii (p287)
- Si lo son, entonces los investigadores combinan esencialmente todos los datos de todos los estudios incluidos y generan una medida “general” de asociación y un intervalo de confianza del 95%.
- Si no lo son, entonces los autores sintetizarán los estudios de otras maneras significativas, comparando y contrastando sus resultados, fortalezas y debilidades y llegando a una conclusión general basada en la literatura existente. No se calcula una medida global de asociación, pero generalmente los autores son capaces de concluir que alguna exposición está o no asociada con algún resultado (y quizás más o menos la fuerza de esa asociación).
- Evaluar la probabilidad de sesgo de publicación (nuevamente, existen métodos estadísticos formales para ello) xxii (pp197-200) y el grado en que eso puede o no haber afectado los resultados.
- ¡Publica los resultados!
Idealmente, al menos 2 investigadores diferentes realizarán los pasos 2—4 de manera completamente independiente entre sí, registrándose después de completar cada paso y resolviendo cualquier discrepancia, generalmente por consenso. xxiii Esto proporciona un control contra el sesgo no consciente o inconsciente por parte de los autores (recuerda: todos somos humanos y por lo tanto todos sesgados). Para revisiones sistemáticas y metaanálisis realizados después de 2015 más o menos, el protocolo para la revisión (estrategia de búsqueda, tema exacto, etc.) debe registrarse antes del paso 2 con un registro central, como PROSPERO. Esto proporciona un control contra sesgos: los autores que se desvían de sus protocolos preinscritos deben proporcionar muy buenas razones para hacerlo, y dichos estudios deben interpretarse con extrema precaución.
Los resultados de los metanálisis a menudo se presentan como parcelas forestales en las que cada parcela incluyó el resultado principal del estudio (con el tamaño del cuadrado correspondiente al tamaño de la muestra) y una estimación general de la asociación se indica como un diamante en la parte inferior. Aquí hay un ejemplo de un metaanálisis del consumo de chocolate y la presión arterial sistólica (SBP, el número superior en una lectura de presión arterial):

Figura 9-9. Adaptado de Reid et.al., BMC Medicine 2010
Se puede ver en esta parcela forestal que la mayoría de los estudios mostraron una disminución en la PAS para las personas que comieron más chocolate, aunque no todos los estudios encontraron esto. Algunas estimaciones puntuales son bastante cercanas a 0.0 (que es el valor “nulo” aquí, porque estamos viendo el cambio en un solo número, no en una relación), y 10 de los intervalos de confianza cruzan 0.0, lo que indica que no son estadísticamente significativos. Sin embargo, 6 estudios —los estudios más grandes, ya que sus intervalos de confianza son los más estrechos— son estadísticamente significativos y todos ellos en la dirección del chocolate son beneficiosos. De hecho, el cambio general (o “agrupado”) en la PAS y el IC 95% que se muestran en la parte inferior (el diamante negro) indica una pequeña reducción (aproximadamente 3 mm Hg) en SBP para los consumidores de chocolate. ¿Significa esto que todos deberíamos empezar a comer mucho chocolate? No necesariamente: una caída de 3 mm Hg (“milímetros de mercurio” —aún las unidades en las que medimos la presión arterial, a pesar de que el mercurio no está involucrado desde hace varias décadas) en la PAS no es clínicamente significativa. Una PAS normal está entre 90 y 120, por lo que una caída de 3 mm Hg te sitúa en 87-117, probablemente ni siquiera un cambio fisiológico notable.
Como se aludió anteriormente, el metaanálisis requiere cierta similitud entre los estudios que se agruparán (por ejemplo, necesitan controlar por factores de confusión similares, si no idénticos). A menudo, este no es el caso de un determinado cuerpo de literatura, en cuyo caso, los autores examinarán sistemáticamente todas las pruebas y harán todo lo posible para llegar a una respuesta “una”, tomando en consideración la calidad de los estudios individuales, el patrón general de resultados, etc. Por ejemplo, en una revisión sistemática de la mastectomía reductora de riesgo (RRM), la extirpación quirúrgica profiláctica de los senos en mujeres que aún no tienen cáncer de mama, pero que tienen los genes BRCA-1 o BRCA-2 y por lo tanto se encuentran en muy alto riesgo (donde BRRM se refiere a RRM bilateral, al tener ambas mamas extirpadas). Los autores describieron los resultados generales de este estudio de la siguiente manera:
Veintiún estudios BRRM que analizaron la incidencia de cáncer de mama o mortalidad específica de enfermedad, o ambos, reportaron reducciones después de BRRM, particularmente para aquellas mujeres con mutaciones BRCA1/2. ... Veinte estudios evaluaron medidas psicosociales; la mayoría reportó altos niveles de satisfacción con la decisión de tener RRM pero mayor variación en la satisfacción con los resultados cosméticos. La preocupación por el cáncer de mama se redujo significativamente después de BRRM cuando se comparó tanto con los niveles de preocupación basales como con los grupos que optaron por la vigilancia en lugar de BRRM, pero hubo disminución de la satisfacción con la imagen corporal y los sentimientos sexuales. xxvii (p2)
A continuación, los autores concluyeron:
Si bien los estudios observacionales publicados demostraron que la BRRM fue efectiva para reducir tanto la incidencia como la muerte por cáncer de mama, se sugieren estudios prospectivos más rigurosos. [Debido a los riesgos asociados a esta cirugía] BRRM debe considerarse solo entre aquellos con alto riesgo de enfermedad, por ejemplo, portadores de BRCA1/2. xxvii (p2)
No se proporciona una estimación global “agrupada” del efecto protector asociado a la RRM, pero los autores no obstante son capaces de transmitir el estado general de la literatura, incluso donde se carece del cuerpo de literatura.
Las revisiones sistemáticas y los metaanálisis son excelentes recursos para aprender sobre un tema. De manera realista, nadie tiene tiempo para mantenerse al día con la literatura en otra cosa que no sea un área temática muy estrecha, e incluso entonces en realidad solo es una gran ayuda para los investigadores en ese campo tomar nota de nuevos estudios individuales. Para los profesionales de la salud pública y los médicos que no participan rutinariamente en la investigación, confiar en revisiones sistemáticas y metaanálisis proporciona una imagen general mucho mejor que es potencialmente menos propensa a los sesgos encontrados en estudios individuales. Sin embargo, se debe tener cuidado para leer reseñas bien hechas. El título del artículo debe incluir revisión sistemática o metaanálisis, y los métodos deben reflejar los descritos anteriormente. Tenga cuidado con los artículos de revisión que no son explícitamente sistemáticos, son extremadamente propensos a sesgos por parte de los autores y probablemente deberían ignorarse. [1]
Conclusiones
La siguiente figura es una representación del costo relativo y validez interna de los diseños de estudio discutidos en este capítulo:

Existen muchos tipos de estudios epidemiológicos, desde reportes de un solo paciente inusual hasta metaanálisis formales de docenas de otros estudios. La validez relativa de estos en términos de usar su evidencia para dar forma a políticas varía ampliamente, pero con la excepción de los trabajos de revisión, los estudios “mejores” son los más caros y lentos. Los trabajos de revisión en sí mismos no son particularmente caros, pero no se pueden hacer hasta que se hayan publicado muchos otros estudios, por lo que si los incluyes como costos indirectos, requieren mucho tiempo y dinero. Los 4 tipos principales de estudio (transversal, caso-control, cohorte y ECA) tienen cada uno fortalezas y debilidades, y los lectores de la literatura epidemiológica deben ser conscientes de estos. Hay ocasiones, independientemente de consideraciones de costo o validez, en las que se prefiere un diseño u otro (por ejemplo, casos y controles para enfermedades raras).
Referencias
i. Williams RA, Mamotte CD, Burnett JR. Fenilcetonuria: un error innato del metabolismo de la fenilalanina. Clin Biochem Rev. 2008; 29 (1) :31-41.
ii. ¿Dónde vives podría influir en cuanto tiempo vives? RWJF. https://www.rwjf.org/en/library/inte...ngyoulive.html. Accedido el 19 de febrero de 2019.
iii. Un ensayo aleatorizado de control de presión arterial intensivo versus estándar. N Engl J Med. 2017; 377 (25) :2506. doi:10.1056/nejmx170008
iv. Ridker PM, Cook NR, Lee I-M, et al. Un ensayo aleatorizado de aspirina a dosis bajas en la prevención primaria de enfermedades cardiovasculares en mujeres. N Engl J Med. 2005; 352 (13) :1293-1304. doi:10.1056/Nejmoa050613. (Regreso 1) (Regreso 2)
v. Wacholder S, McLaughlin JK, Silverman DT, Mandel JS. Selección de controles en estudios de casos y controles, I: principios. Am J Epidemiol. 1992; 135 (9) :1019-1028. (Regreso)
vi. Wacholder S, Silverman DT, McLaughlin JK, Mandel JS. Selección de controles en estudios de casos y controles, II: tipos de controles. Am J Epidemiol. 1992; 135 (9) :1029-1041. (Regreso)
vii. Salud CO en S y. Tabaquismo y consumo de tabaco: antecedentes del Informe del Cirujano General. Centros para el Control y la Prevención de Enfermedades. 2017. http://www.cdc.gov/tobacco/data_stat...s/sgr/history/. Accedido el 30 de octubre de 2018. (Regreso)
viii. Muñeca R, Colina AB. Tabaquismo y carcinoma de pulmón. Br Med J. 1950; 2 (4682) :739-748. (Regreso)
ix. Bowden K, Kessler D, Pinette M, Wilson E. Nacimiento submarino: ¿falta la evidencia o falta el punto? Pediatría. 2003; 112 (4) :972-973.
x. Centros para el Control y la Prevención de Enfermedades (CDC). Un grupo de sarcoma de Kaposi y neumonía por Pneumocystis carinii entre varones homosexuales residentes de los condados de Los Ángeles y Orange, California. MMWR Morb Mortal Wkly Rep. 1982; 31 (23) :305-307.
xi. Cheyney M, Bovbjerg M, Everson C, Gordon W, Hannibal D, Vedam S. Resultados de la atención para 16,924 partos domiciliarios planeados en Estados Unidos: el proyecto de estadísticas de la Alianza de Parteras de América del Norte, 2004 a 2009. J Partería Salud de la Mujer. 2014; 59 (1) :17-27. (Regreso)
xii. Gregg NM. Catarata congénita tras sarampión alemán en la madre. Trans Opthalmol Soc Aust. 1941; 3:35-46. (Regreso)
xiii. Greenberg M, Pellitteri O, Barton J. Frecuencia de defectos en lactantes cuyas madres presentaron rubéola durante el embarazo. J Am Med Assoc. 1957; 165 (6) :675-678. (Regreso)
xiv. Manson M, Logan W, Loy R. Rubéola y otras infecciones virales durante el embarazo. Londres: La Oficina de Papelería de Su Real Majestad; 1960. (Regreso)
xv. Lundstrom R. Rubéola durante el embarazo: un estudio de seguimiento de niños nacidos después de una epidemia de rubéola en Suecia, 1951, con investigaciones adicionales sobre profilaxis y tratamiento de la rubéola materna. Acta Pediatr Supl. 1962; 133:1-110. (Regreso)
xvi. Centros para el Control de Enfermedades (CDC). Posible síndrome de inmunodeficiencia adquirida (SIDA) asociado a transfusiones —California. MMWR Morb Mortal Wkly Rep. 1982; 31 (48) :652-654. (Regreso)
xvii. Centros para el Control de Enfermedades (CDC). Pneumocystis pneumonia—Los Ángeles. MMWR Morb Mortal Wkly Rep. 1981; 30 (21) :250-252. (Regreso)
xviii. Centros para el Control de Enfermedades (CDC). Inmunodeficiencia inexplicable e infecciones oportunistas en bebés: Nueva York, Nueva Jersey, California. MMWR Morb Mortal Wkly Rep. 1982; 31 (49) :665-667. (Regreso)
xix. Centros para el Control y la Prevención de Enfermedades (CDC). Síndrome respiratorio agudo severo—Singapur, 2003. MMWR Morb Mortal Wkly Rep. 2003; 52 (18) :405-411. (Regreso)
xx. Centros para el Control y la Prevención de Enfermedades (CDC). Actualización: síndrome respiratorio agudo severo—Estados Unidos, 14 de mayo de 2003. MMWR Morb Mortal Wkly Rep. 2003; 52 (19) :436-438. (Regreso)
xxi. Centros para el Control y la Prevención de Enfermedades (CDC). Grupo de casos de síndrome respiratorio agudo severo entre trabajadores de salud protegidos — Toronto, Canadá, abril de 2003. MMWR Morb Mortal Wkly Rep. 2003; 52 (19) :433-436. (Regreso)
xxii. Egger M, Smith GD, Altman DG, eds. Revisiones sistemáticas en la atención de la salud: metaanálisis en contexto. Londres: BMJ Publishing; 2001. (Regreso 1) (Regreso 2)
xxiii. Harris JD, Quatman CE, Manring MM, Siston RA, Flanigan DC. Cómo escribir una revisión sistemática. Am J Sports Med. 2014; 42 (11) :2761-2768. doi:10.1177/0363546513497567 (Regreso)
xxiv. Gilbert R, Salanti G, Harden M, Ver S. La posición de sueño infantil y el síndrome de muerte súbita del lactante: revisión sistemática de estudios observacionales y revisión histórica de recomendaciones de 1940 a 2002. Int J Epidemiol. 2005; 34 (4) :874-887. doi:10.1093/ije/dyi088
xxv. CDC. Sueño seguro para los bebés. Centros para el Control y la Prevención de Enfermedades. 2018. https://www.cdc.gov/vitalsigns/safesleep/index.html. Accedido enero 10, 2019
xxvi. Grupo de Trabajo sobre el Síndrome de Muerte Súbita Infantil, Moon RY. SIDS y otras muertes infantiles relacionadas con el sueño: ampliación de recomendaciones para un ambiente seguro para dormir infantil. Pediatría. 2011; 128 (5) :1030-1039.
xxvii. Carabina NE, Lostumbo L, Wallace J, Ko H. Mastectomía reductora de riesgo para la prevención del cáncer primario de mama. Cochrane Database Syst Rev. 2018; 4:CD002748. doi:10.1002/14651858.cd002748.pub4 (Regreso 1) (Regreso 2)
- La metasíntesis es una técnica legítima para la revisión sistemática de la literatura cualitativa. Los papeles a tener en cuenta son los llamados “revisión integradora”, “revisión de literatura” o simplemente “revisión”, cualquier cosa que no sea “revisión sistemática”. ”