
6.7: Impresión de Datos Variables
- Page ID
- 154236
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)La impresión de datos variables, o VDP, se refiere a una forma especial de impresión digital donde el contenido del documento está determinado por entradas en un registro o conjunto de datos y puede ser altamente personalizado. El texto variado, los gráficos y las imágenes son elementos típicos de contenido, pero el diseño, el posicionamiento de los elementos e incluso la elección de documentos son solo algunas de las otras variables. Debido a que el contenido de la página impresa cambia constantemente, no sería factible producir este tipo de producto impreso con litografía offset tradicional o con cualquier otro proceso que requiera una placa de imagen fija. La impresión electrofotográfica y de chorro de tinta son ideales para este tipo de impresión, ya que cada página se imagina individualmente.
VDP puede tomar muchas formas. Los documentos transaccionales como facturas y estados de cuenta son probablemente la forma más antigua de VDP, pero estos han evolucionado para incluir marketing o contenido informativo. Esto se conoce como trans-promo o trans-promocional. Una combinación de correspondencia es una forma simple de VDP donde un documento estático tiene elementos de datos agregados directamente a él. Cada registro en el conjunto de datos produce un documento. Otro formulario VDP es cuando ingresa el registro manualmente o carga una tabla de datos simple basada en texto, que luego llena el contenido de una plantilla. Este método se encuentra típicamente en las soluciones web2print y produce elementos como tarjetas de visita, donde el diseño, las fuentes y los elementos requeridos pueden ser predeterminados y el contenido basado en los datos ingresados. Las soluciones VDP más avanzadas pueden incluir herramientas de gestión de campañas, administración de flujos de trabajo, generación de códigos de barras bidimensionales, tecnología de fuentes basadas en imágenes e integración en sistemas externos como bases de datos, correo electrónico, soluciones web2print, limpieza de datos o soluciones de optimización postal.
Uno de los propósitos centrales de la VDP es aumentar la tasa de respuesta y, en última instancia, las conversiones al resultado deseado. Para lograrlo, es fundamental que el contenido presentado sea relevante y tenga valor para el público objetivo. Hoy en día, hay cantidades masivas de datos disponibles sobre los clientes y su comportamiento. Analizar y comprender los datos de los clientes es esencial para mantener un alto grado de relevancia y compromiso con el cliente.
VDP se puede dividir en seis componentes clave: datos, contenido, reglas de negocio, diseño, software y método de salida. Cada componente puede variar en complejidad y capacidad y puede requerir soluciones de software avanzadas para implementarlo. Sin embargo, incluso las herramientas más básicas pueden producir comunicaciones altamente efectivas.
Datos
Los datos utilizados para VDP pueden considerarse simplemente como una tabla o conjunto de datos. Cada fila de la tabla se considera un solo registro. Las columnas son los campos utilizados para describir el contenido del registro. Algunos ejemplos de columnas o campos serían nombre, apellido, dirección, ciudad, etc. La forma más simple y común de representar esta tabla es mediante el uso de un formato de texto sin formato delimitado como el valor separado por comas (CSV) o delimitado por tabulaciones. El delimitador separa las columnas entre sí y una nueva línea representa una nueva fila o registro en la tabla. Aquí hay un ejemplo de datos CSV:
“FirstName”,”LastName”,”Gender”,”Age”,”FavQuotes”
“John”,”Smith”,”M”,”47”,”Do or do not, there is no try.”
“Mary”,”Jones”,”F”,”25”,”Grey is my favourite colour.”
La primera fila contiene los encabezados de fila o lo que representan los campos y no se considera un registro. Notarás que cada campo está separado por una coma pero también está encerrado entre comillas. Las comillas son calificadores de texto y se utilizan comúnmente para evitar problemas cuando el carácter delimitador también puede estar en el contenido del campo como es el caso del primer registro anterior. Muchas aplicaciones VDP admiten bases de datos relacionales más avanzadas como SQL, pero se debe realizar una consulta para extraer los datos que se van a usar, lo que finalmente da como resultado la misma estructura de registros de filas y columnas. Los datos deberán adjuntarse o asignarse al documento en la maquetación de página o aplicación VDP.
Contenido
El contenido se refiere a los elementos que se muestran en cada página. Esto incluiría texto, gráficos e imágenes, tanto estáticas como dinámicas. El contenido dinámico utiliza marcadores de posición, normalmente nombrados por los encabezados de columna de los datos, para marcar la posición del elemento y hacer referencia a los datos en la columna específica del registro actual. Cuando se representa el documento, el marcador de posición se reemplaza por el elemento de datos de registro.
“Querido < <FirstName>>...” se convierte en “Querido Juan...” cuando el documento es renderizado para el primer registro y “Querida María...” para el segundo disco, y así sucesivamente. Un documento completo se representa por registro en el conjunto de datos.
Reglas de negocio
Las reglas de negocio son uno de los elementos clave que hacen que los documentos VDP sean muy útiles. Se pueden considerar como una serie de criterios que se comparan con los datos para determinar qué se muestra en la página. También se pueden utilizar para manipular los datos o filtrar contenido relevante. En casi todos los casos, se requiere algún nivel de scripting. Las soluciones VDP avanzadas tienen capacidad de scripting incorporada, utilizando un lenguaje de scripting común como VBScript o JavaScript, o un lenguaje de scripting propietario que solo es aplicable en esa aplicación específica. Si la herramienta de diseño de página que está utilizando para crear su documento VDP no tiene capacidad de scripting, puede aplicar reglas de negocio a los datos de antemano en una aplicación de hoja de cálculo como Microsoft Excel o incluso Google Sheets.
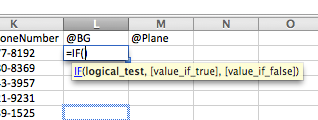
Uno de los métodos más comunes para implementar una regla de negocio es usar una sentencia condicional o IF que comprende una prueba lógica, una acción para un resultado 'verdadero' y una acción para un resultado 'falso' (ver Figura 6.11).
El logical_test significa que la respuesta será verdadera o falsa. En este caso, queremos cambiar nuestros gráficos en función del género.
En inglés sencillo, puedes decir:
“IF gender is male, THEN use plane_blue.tif, or ELSE use plane_orange.tif”
En scripting, se vería algo así:
IF(Gender=”male”,”plane_blue.tif”,”plane_red.tif”)
Al hacer esto en una hoja de cálculo, ingresaría el script en una celda en una nueva columna. El resultado del script se muestra en la celda, no en el script en sí. Esta nueva columna ahora podría usarse para especificar el contenido que se mostrará en su aplicación de maquetación. En aplicaciones VDP dedicadas, el script se adjunta al propio objeto y se procesa y muestra en tiempo real.
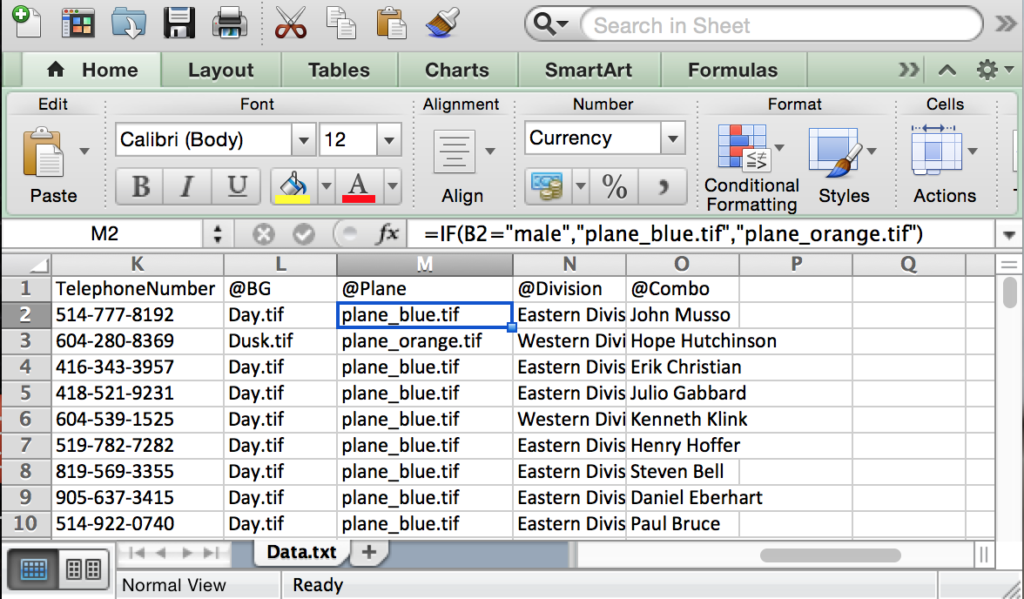
Se agregó la columna “@Plane” para cambiar dinámicamente un gráfico basado en el contenido de la celda en la columna “Género” (B2) (ver Figura 6.12).
Las reglas de negocio también se pueden aplicar al flujo de trabajo de VDP. En este caso, la aplicación o componente de flujo de trabajo puede manipular los datos antes de aplicarlos a un documento, o bien puede seleccionar el documento o destino a utilizar para el registro y mucho, mucho más.
Layout
Al trabajar con documentos de datos variables, hay consideraciones especiales de diseño que debe tener en cuenta. Debido a que la longitud de las palabras cambiará por registro, es necesario que haya suficiente espacio para acomodar el registro más grande y más pequeño, y evitar que se sobrescriba mientras se mantiene la apariencia visual deseada. Este reto se ve agravado por el uso prolífico de fuentes proporcionales. Los anchos de los caracteres difieren con cada letra, por lo que la longitud de las palabras variará incluso cuando el número de caracteres sea el mismo. Esto también puede obligar a un párrafo a refluir a otra página y cambiar el número de páginas en el documento. Es posible que se requieran secuencias de comandos adicionales para manejar escenarios de reflujo. Algunas aplicaciones utilizan algoritmos especiales de ajuste de copia para ajustar dinámicamente el texto en un área definida. El uso de tablas para propósitos de diseño también puede ser útil. Debido a que estamos tratando con documentos generados dinámicamente, es posible que también queramos variar las imágenes. El uso de imágenes con un tamaño y forma consistentes hace que sea más fácil trabajar con ellas. Los documentos transaccionales, como estados de cuenta y facturas, utilizan ampliamente los números. La mayoría de las fuentes, incluidas las proporcionales, mantienen los números monoespaciados. En otras palabras, cada carácter numérico ocupa la misma cantidad de espacio. Esto es importante porque, visualmente, queremos que los números estén bien justificados y alineados verticalmente en columnas con los decimales alineados. Hay, sin embargo, algunas fuentes que no siguen esta práctica común. Estas fuentes pueden ser adecuadas para su uso en un párrafo pero no son para mostrar datos financieros.
Software
Se requiere un software que pueda generar un documento basado en datos para la impresión de datos variables. En los primeros días de VDP, no había muchas opciones para los diseñadores. Era una práctica común mandar código VDP en PostScript, ya que era tanto un lenguaje de programación como un PDL. Aplicaciones como PageMaker e Illustrator eran aplicaciones de diseño PostScript pero carecían de capacidades VDP. Aplicaciones como PlanetPress surgieron como aplicaciones PostScript VDP dedicadas. Hoy en día, los diseñadores tienen una amplia variedad de software disponible para crear VDP. Hay tres tipos básicos de software VDP: una función incorporada dentro de un diseño de página o software de procesamiento de textos, un complemento de terceros o una aplicación VDP dedicada.
Microsoft Word, por ejemplo, tiene una función de combinación de correspondencia pero no tiene la capacidad de variar imágenes, solo texto. Adobe InDesign tiene la función de combinación de datos, que es básicamente una combinación de correspondencia pero también incluye la capacidad de variar las imágenes. En ambos ejemplos, se aplicarían reglas de negocio a los datos antes de utilizarlos en estas aplicaciones.
Hay una serie de plug-ins disponibles para InDesign que son muy sofisticados. Estos aprovechan la amplia capacidad de diseño de página de InDesign al tiempo que agregan secuencias de comandos y otras capacidades específicas de VDP. XMPie y DesignMerge son ejemplos de este tipo de plug-ins. FusionPro es otro producto VDP basado en complementos, y aunque tiene un complemento de InDesign, solo lo usa para asignar cuadros variables de texto e imagen en el diseño. Las reglas de negocio y el contenido específico se aplican en su complemento plug-in para Adobe Acrobat.
PlanetPress y PrintShop Mail son ejemplos de aplicaciones dedicadas que combinan tanto el diseño de página como las funciones VDP. Aunque son muy fuertes en la funcionalidad de VDP, a veces carecen de la sofisticación que encontrarías en InDesign cuando se trata de diseño de página. Estas aplicaciones particulares han pasado recientemente de VDP basado en PostScript a una base más moderna de HTML5 y CSS (hojas de estilo en cascada), lo que facilita la producción y distribución de documentos basados en datos para comunicaciones multicanal.
Método de salida
La 'P' en VDP significa impresión y es el principal método de salida que discutiremos aquí. Sin embargo, la personalización de documentos y las comunicaciones basadas en datos han evolucionado para incluir también correo electrónico, fax, web (PURL, página de destino personalizada), mensajería de texto SMS y diseño receptivo para varios tamaños de pantalla de dispositivos móviles. Con la aparición de los códigos de respuesta rápida (QR), incluso las comunicaciones impresas pueden aprovechar contenido enriquecido y agregar valor adicional a la pieza. Para aprovechar estos canales adicionales de distribución y comunicación, a menudo se emplea un componente de flujo de trabajo.
Un elemento clave para optimizar la salida de impresión de documentos VDP es el almacenamiento en caché. Aquí es donde el RIP de la impresora almacena en caché o almacena elementos repetibles en formato ráster listo para impresión. Esto significa que el RIP procesa estos elementos repetidos una vez, y luego reutiliza estos elementos preprocesados cada vez que el documento los llama. Esto sí requiere un RIP con suficiente potencia para procesar grandes cantidades de datos y recursos con soporte para el esquema de almacenamiento en caché definido en el archivo VDP pero, en última instancia, permite que la impresora imprima a su velocidad nominal completa sin tener que esperar los datos ráster del RIP.
Ha habido muchos formatos de archivo VDP patentados que se han esforzado por mejorar el rendimiento de VDP a lo largo de los años, pero la industria está avanzando rápidamente hacia estándares más abiertos. PoDi, un consorcio sin fines de lucro de empresas líderes en impresión digital, lidera el camino con dos estándares VDP abiertos ampliamente adoptados. Estos estándares son PPML (Lenguaje de marcado de impresión personalizado) y PDF/VT (formato de documento portátil/variable transaccional).
PPML
PPML, introducido por primera vez en 2000, es un lenguaje de impresión basado en XML independiente del dispositivo. Hay dos tipos de PPML: delgado y grueso. Thin PPML es un archivo único, con la extensión .ppml, que contiene todas las instrucciones necesarias para producir el documento VDP. Incluye instrucciones de almacenamiento en caché; sin embargo, todos los recursos como fuentes o imágenes se almacenan externamente al archivo. La ruta a estos recursos se define en el RIP y se recupera durante el proceso de renderizado del documento. Thin PPML es ideal para el desarrollo interno de VDP donde los recursos pueden ser compartidos por múltiples proyectos. Sin embargo, estos archivos son extremadamente pequeños y la velocidad de la red y el ancho de banda pueden afectar el rendimiento y son más difíciles de implementar si se usa un proveedor de impresión externo. Thick PPML es un archivo.zip que contiene todos los recursos requeridos (fuentes, imágenes, instrucciones, etc.). Este formato hace que el archivo sea altamente portátil y fácil de implementar en el dispositivo de impresión, pero tiene un tamaño de archivo más grande en comparación con PPML delgado. Los RIP que admiten el formato PPML pueden importar el archivo.zip directamente. Independientemente del tipo utilizado, PPML se beneficia de un rendimiento excepcional, un estándar abierto, soporte de venta de entradas de trabajo abierto (JDF) y tamaño de archivo reducido en general. Para generar PPML se requiere una solución VDP avanzada.
PDF/VT
PDF/VT es un estándar internacional relativamente nuevo (ISO 16612-2) que tiene mucho potencial. Está construido a partir del estándar PDF/X-4, beneficiándose de sus características, como soporte para transparencia, administración de color basada en ICC, amplio soporte de metadatos, almacenamiento en caché de elementos, verificación previa y mucho más. En resumen, PDF/VT incluye los mecanismos necesarios para manejar trabajos de VDP de la misma manera que la impresión estática de PDF permite a los proveedores de impresión utilizar un flujo de trabajo común para todos los tipos de trabajos, incluido el VDP. Muchas de las últimas versiones de soluciones VDP avanzadas ya son compatibles con PDF/VT, así como muchos fabricantes de DFE.
Para obtener más información sobre PPML y PDF/VT, consulte el sitio web del PoDi en: http://www.standards.podi.org
Atribuciones de medios
- plane_blue de Roberto Medeiros