
15.3: Secuenciación de ADN
- Page ID
- 54379

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A. Breve historia de la secuenciación del ADN
La secuenciación del ARN vino primero, cuando Robert Holley secuenció un ARNt en 1965. La secuenciación directa de los ARNt fue posible porque los ARNt son ácidos nucleicos pequeños y cortos, y porque muchas de las bases en los ARNt se modifican químicamente después de la transcripción. Un método temprano para la secuenciación del ADN desarrollado por Walter Gilbert y sus colegas involucró la fragmentación del ADN, la secuenciación de los pequeños fragmentos de ADN y luego la alineación de las secuencias superpuestas de los fragmentos cortos para ensamblar secuencias más largas. Otro método, la técnica de secuenciación de ADN 'didesoxi' basada en síntesis de ADN, fue desarrollada por Frederick Sanger en Inglaterra. Sanger y Gilbert ganaron el Premio Nobel de Química en 1983 por sus esfuerzos de secuenciación de ADN. Sin embargo, debido a su simplicidad, el método de Sanger se convirtió rápidamente en el estándar para secuenciar todo tipo de ADN clonados.
El primer genoma completo que se secuenció fue el de un bacteriófago (virus bacteriano) llamado Φx174. Al mismo tiempo que se estaban produciendo los avances en la tecnología de secuenciación, también lo fueron algunos de los primeros desarrollos en la tecnología de ADN recombinante. Juntos, estos llevaron a una clonación y secuenciación más eficientes y rápidas del ADN de fuentes cada vez más diversas. El primer foco fue por supuesto en genes y genomas de organismos modelo importantes, como E. coli, C. elegans, levaduras (S. cerevisiae)..., ¡y por supuesto nosotros! Para 1995, Craig Venter y colegas del Instituto de Investigaciones Genómicas habían completado la secuencia de un genoma bacteriano completo (Haemophilus influenzae) y para 2001, el grupo privado de Venter junto con Frances Collins y colegas de los NIH habían publicado un primer borrador del secuencia del genoma humano. Venter había demostrado la eficacia de un enfoque de secuenciación de genoma completo llamado secuenciación de escopeta, que era mucho más rápido que la estrategia de secuenciación “lineal” fragmento a fragmento, siendo utilizada por otros investigadores (¡más tarde!). Dado que el método de secuenciación de ADN de didesoxinucleótidos de Sanger sigue siendo una metodología común y económica, consideremos los fundamentos del protocolo.
B. Detalles de la Secuenciación DiDeoxy
Dado un ADN molde (por ejemplo, un ADNc plasmídico), Sanger utilizó protocolos de replicación in vitro para demostrar que podía:
- Replicar el ADN en condiciones que detuvieran aleatoriamente la adición de nucleótidos en todas las posiciones posibles en hebras en crecimiento.
- Separar y luego detectar estos fragmentos de ADN de ADN replicado.
Recordemos que las ADN polimerasas catalizan la formación de enlaces fosfodiéster al unir el\(\alpha \) fosfato de un nucleótido trifosfato al OH 3' libre de un desoxinucleótido al final de una cadena de ADN en crecimiento. Recordemos también que el azúcar ribosa en los desoxinucleótidos precursores de replicación carecen de un grupo 2' OH (hidroxilo). El truco de Sanger fue agregar didesoxinucleótidos trifosfatos a su mezcla de replicación in vitro. La ribosa sobre un didesoxinucleótido-trifosfato (ddNTP) carece de un OH 3', además del grupo 2' OH (como se muestra a continuación).
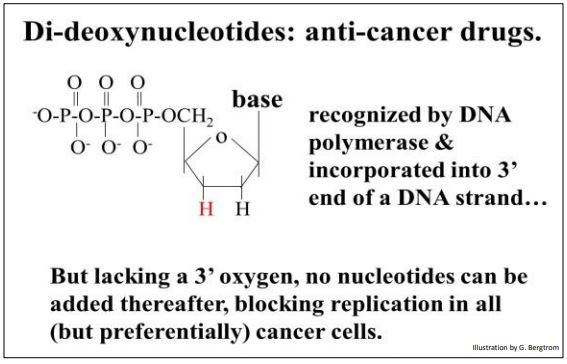
Agregar un didesoxinucleótidos a una cadena de ADN en crecimiento detiene la replicación. ¡No se pueden añadir más nucleótidos al extremo 3' de la cadena de ADN replicante porque el 3'—OH necesario para la síntesis por deshidratación del siguiente enlace fosfodiéster está ausente! Debido a que pueden detener la replicación en células en crecimiento activo, los ddNTPs como la didesoxiadenosina (nombre comercial, cordycepin) son fármacos quimioterapéuticos anticancerígenos.
266 Tratamiento del cáncer con didesoxinucleósidos
Una mirada a un protocolo manual de secuenciación de ADN revela lo que está sucediendo en las reacciones de secuenciación. Se configuran cuatro tubos de reacción, cada uno con el ADN molde a secuenciar, un cebador de secuencia conocida y los cuatro precursores de desoxinucleótidos necesarios para la replicación.
La configuración para la secuenciación manual del ADN se muestra a continuación.
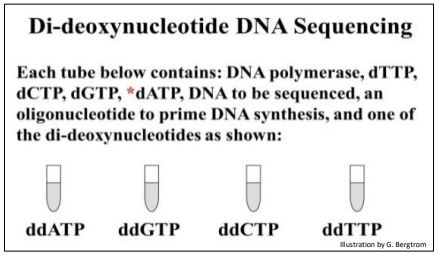
Se agrega un ddNTP diferente, (ddATP, ddCTP, ddGTP o ddTTP) a cada uno de los cuatro tubos. Finalmente, se agrega ADN polimerasa a cada tubo para iniciar la reacción de síntesis de ADN. Durante la síntesis de ADN, se acumulan fragmentos de diferente longitud de ADN nuevo a medida que los ddNTPs incorporan aleatoriamente bases complementarias opuestas en el ADN molde que se está secuenciando. Las expectativas de las reacciones de secuenciación didioxi en los cuatro tubos se ilustran a continuación.
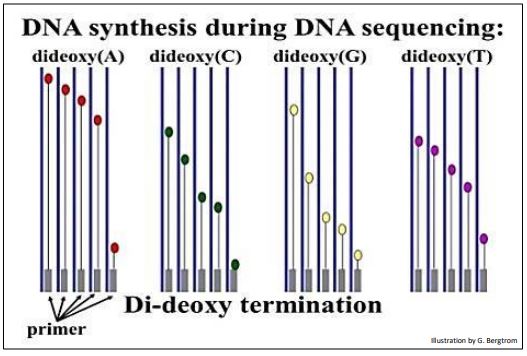
Poco tiempo después de agregar la ADN polimerasa para comenzar las reacciones, la mezcla se calienta para separar las cadenas de ADN y se agrega ADN polimerasa fresca para repetir las reacciones de síntesis. Estas reacciones de secuenciación se repiten hasta 30 veces con el fin de producir suficientes fragmentos de ADN radiactivo para ser detectados. Cuando la ADN polimerasa Taq termoestable de la bacteria termófila Thermus aquaticus estuvo disponible (¡más tarde!) , ya no fue necesario agregar ADN polimerasa fresca después de cada ciclo de replicación. Los muchos ciclos de calentamiento y enfriamiento requeridos para lo que se conoció como secuenciación de ADN de terminación de cadena pronto se automatizaron utilizando termocicladores programables de bajo costo.
Dado que una pequeña cantidad de desoxinucleótido radiactivo (generalmente ATP marcado con 32P) estaba presente en cada tubo de reacción, los fragmentos de ADN recién hechos son radiactivos. Después de la electroforesis para separar los nuevos fragmentos de ADN en cada tubo, la autorradiografía del gel electroforético revela la posición de cada fragmento terminado. La secuencia de ADN puede entonces leerse del gel como se ilustra en la autoradiografía simulada a continuación.
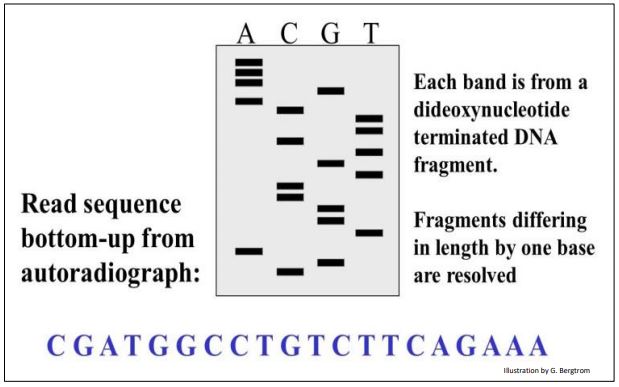
Como se muestra en la caricatura, la secuencia de ADN se puede leer leyendo las bases desde el fondo del gel, comenzando con la C en la parte inferior del carril C. ¡Intenta leer la secuencia tú mismo!
267 Secuenciación Dideoxi Manual
El primer método semiautomático de secuenciación de ADN se inventó en el laboratorio de Leroy Hood en California en 1986. Aunque todavía secuenciando Sanger, los cuatro didesoxinucleótidos en la reacción de secuenciación se etiquetaron para su detección con colorantes fluorescentes en lugar de nucleótidos marcados con fosfato radiactivo. Después de las reacciones de secuenciación, los productos de reacción se electroforizan en un 'secuenciador de ADN automatizado'. La luz UV excita los fragmentos de ADN migratorios terminados en tinte a medida que pasan a través de un detector. El color de su fluorescencia es detectado, procesado y enviado a una computadora, generando gráfica codificada por colores como la de abajo, mostrando el orden (y por lo tanto la longitud) de los fragmentos que pasan por el detector y así, la secuencia de la hebra.
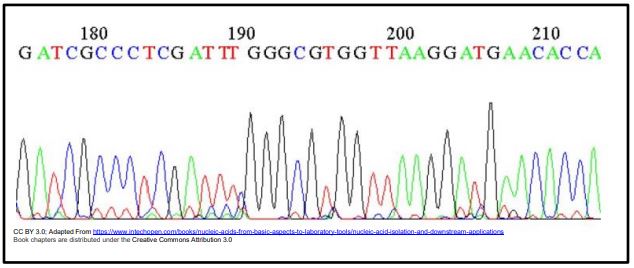
Una característica muy útil de este método de secuenciación es que un ADN molde podría secuenciarse en un solo tubo, conteniendo todos los componentes requeridos, ¡incluidos los cuatro didesoxinucleótidos! Eso se debe a que el detector de fluorescencia en la máquina de secuenciación ve por separado todos los fragmentos cortos terminados en DDNTP a medida que se mueven a través del gel electroforético.
Las innovaciones de Hood se comercializaron rápidamente haciendo posibles grandes proyectos de secuenciación, incluida la secuenciación del genoma completo. La rapidez de la secuenciación automatizada de ADN condujo a la creación de grandes bases de datos de secuencias en Estados Unidos y Europa.
El NCBI (Centro Nacional de Información Biológica) mantiene la base de datos de Estados Unidos. Pese a su ubicación, el NCBI archiva prácticamente todas las secuencias de ADN determinadas a nivel mundial. Los nuevos secuenciadores de ADN 'diminutos' han hecho que la secuenciación del ADN sea tan portátil que en 2016, incluso se utilizó uno en la Estación Espacial Internacional. La expansión de bases de datos y nuevas herramientas y protocolos (algunos se describen a continuación) para encontrar, comparar y analizar secuencias de ADN también han crecido rápidamente.
268 La secuenciación automatizada conduce a grandes proyectos genómicos
C. Secuenciación a Gran Escala
La secuenciación a gran escala se dirige a genomas procariotas enteros y típicamente eucariotas mucho más grandes. Estos últimos requieren estrategias que secuencien fragmentos de ADN largos y/o secuencien fragmentos de ADN más rápidamente. Ya notamos la secuenciación de escopeta utilizada por Venter para secuenciar genomas cada vez más pequeños (incluido el nuestro... o más exactamente, ¡el suyo!). En la secuenciación de escopeta, los fragmentos de ADN clonados de 1000 pares de bases o más se descomponen al azar en fragmentos más pequeños y más fácilmente secuenciados. Los fragmentos son ellos mismos clonados y secuenciados y las secuencias no redundantes se ensamblan alineando regiones solapantes de secuencia. El software informático de hoy en día es bastante experto en la alineación rápida de secuencias superpuestas, así como en la conexión y visualización de secuencias de ADN contiguas largas. La secuenciación de escopeta se resume a continuación.

Los huecos de secuencia que quedan después de la secuenciación de escopeta se pueden rellenar caminando con el cebador, en el que una secuencia conocida cerca de la brecha es la base para crear un cebador de secuenciación para “caminar” en la región del hueco en un ADN intacto que no ha sido fragmentado. Otra técnica de 'llenado de huecos' implica la PCR (la Reacción en Cadena de la Polimerasa, que se describirá en breve). Brevemente, se sintetizan dos oligonucleótidos basándose en información de secuencia a cada lado de un hueco. Luego se usa PCR para sintetizar el fragmento faltante, y el fragmento se secuencia para llenar el hueco.