
15.4: Bibliotecas genómicas
- Page ID
- 54399

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Una biblioteca genómica podría ser un tubo lleno de bacteriófago recombinante. Cada molécula de ADN de fago contiene un inserto fragmentario de ADN celular de un organismo extraño. La biblioteca está hecha para contener una representación de todos los fragmentos posibles de ese genoma. Los bacteriófagos se utilizan a menudo para clonar fragmentos de ADN genómico porque:
- Los genomas de fagos son más grandes que los plásmidos y pueden diseñarse para eliminar una gran cantidad de ADN que no es necesaria para la infección y replicación en células hospedadoras bacterianas.
- el ADN faltante puede ser reemplazado por fragmentos de ADN de inserción foránea de hasta 18- 20 kpb (pares de kilobases), casi 20 veces más largos que los insertos de ADNc típicos en plásmidos.
- Las proteínas de cubierta de fago purificadas se pueden mezclar con el ADN de fago recombinado para producir partículas de fago infecciosas que infectarían bacterias hospedadoras, replicarían lotes de nuevos fagos recombinantes y luego lisarían las células para liberar el fago.
La necesidad de vectores como bacteriófagos que puedan acomodar insertos largos se vuelve obvia a partir del siguiente bit de matemáticas. Un genoma típico de mamífero consta de más de 2 mil millones de pares de bases. Los insertos en plásmidos son muy cortos, raramente superan los 1000 pares de bases. Dividiendo 2,000,000,000 por 1000, se obtienen 2 millones, un número mínimo de clones de fagos que deben ser cribados para encontrar una secuencia de interés. De hecho, necesitarías muchos más que este número de clones para encontrar un gen (¡o partes de uno!). Por supuesto, parte de la solución a este dilema de “aguja en un pajar” es clonar insertos de ADN más grandes en vectores más acomodativos.
A partir de esta breve descripción, puede reconocer la estrategia común para la ingeniería genética de un vector de clonación: determinar las propiedades mínimas que debe tener su vector y eliminar secuencias de ADN no esenciales. Considere el Cromosoma Artificial de Levadura (YAC), hospedado por (replicado en) células de levadura. ¡Los YAC pueden aceptar ingentes insertos de ADN foráneo! Esto se debe a que para ser un cromosoma que se replicará en una célula de levadura se requiere un centrómero y dos telómeros... ¡y poco más!
Recordemos que los telómeros son necesarios en la replicación para evitar que el cromosoma se acorte durante la replicación del ADN. El centrómero es necesario para unir las cromátidas a las fibras del huso para que puedan separarse durante la anafase en la mitosis (y meiosis). Entonces, junto con un centrómero y dos telómeros, solo incluye sitios de restricción para permitir la recombinación con insertos de hasta 2000 Kbp. ¡Eso es un YAC! La parte difícil, por supuesto, es mantener intacto un fragmento de ADN de 2000Kbp de largo el tiempo suficiente para meterlo en el YAC.
Sin embargo un vector es diseñado y elegido, secuenciar su inserto puede decirnos muchas cosas. Pueden mostrarnos cómo se regula un gen revelando conocidas y descubriendo nuevas secuencias reguladoras de ADN. Pueden decirnos qué otros genes están cerca, y dónde están los genes en los cromosomas. Las secuencias de ADN genómico de una especie pueden sondear secuencias similares en otras especies y el análisis comparativo de secuencias puede entonces decirnos mucho sobre la evolución génica y la evolución de las especies.
Una sorpresa temprana de los estudios de secuenciación génica fue que compartimos muchos genes y secuencias de ADN comunes con otras especies, desde levaduras hasta gusanos y moscas... y por supuesto vertebrados y nuestros amigos mamíferos más estrechamente relacionados. Quizá ya sepas que los chimpancés y nuestros genomas son 99% similares. Además, ya hemos visto análisis comparativos de secuencias que muestran cómo las proteínas con diferentes funciones comparten dominios estructurales.
Veamos cómo clonar una biblioteca genómica en fagos. Como verá, los principios son similares a clonar un ADN extraño en un plásmido, o de hecho cualquier otro vector, pero los números y detalles utilizados aquí ejemplifican la clonación en fagos.
A. Preparación del ADN genómico de una longitud específica para la clonación
Para empezar, se aíslan, purifican y luego se digieren con una enzima de restricción de alto peso molecular (es decir, moléculas largas de) el ADN genómico deseado. Por lo general, la digestión es parcial, con el objetivo de generar fragmentos de ADN superpuestos de longitud aleatoria. Cuando el digesto se somete a electroforesis en geles de agarosa, el ADN (teñido con bromuro de etidio, un colorante fluorescente que se une al ADN) parece un frotis brillante en el gel. Todo el ADN se pudo recombinar con ADN vector adecuadamente digerido. Pero, para reducir aún más el número de clones a cribar para una secuencia de interés, los clonadores tempranos generarían una transferencia Southern (llamada así por Edward Southern, el inventor de la técnica) para determinar el tamaño de los fragmentos de ADN genómico con mayor probabilidad de contener un gen deseado.
Comenzando con un gel de digestiones de restricción de ADN genómico, el protocolo de transferencia Southern se ilustra a continuación.
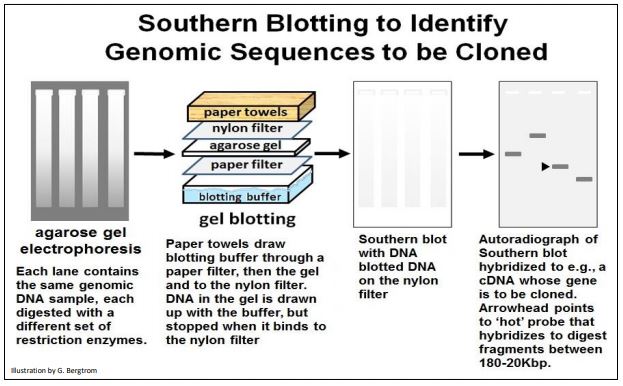
Para resumir los pasos:
a) Digerir el ADN genómico con una o más endonucleasas de restricción.
b) Ejecutar los productos digeridos en un gel de agarosa para separar los fragmentos por tamaño (longitud). El ADN aparece como frotis cuando se tiñe con un tinte fluorescente.
c) Colocar un filtro sobre el gel. El ADN se transfiere (transferencias) al filtro durante, por ejemplo, 24 horas
d) Retire el filtro secado y colóquelo en una bolsa que contenga una solución que pueda desnaturalizar el ADN.
e) Agregar sonda radiactiva (por ejemplo, ADNc) que contenga el gen o secuencia de interés. La sonda hibrida (se une) a secuencias genómicas complementarias en el filtro
f) Preparar una autorradiografía del filtro y ver una 'banda' que representa el tamaño de los fragmentos genómicos de ADN que incluyen la secuencia de interés.
Una vez que conozca el tamaño (o rango de tamaño) de los fragmentos de digestión de restricción que contienen el ADN que desea estudiar, está listo para:
a) ejecutar otro gel de ADN genómico digerido.
b) cortar el trozo de gel que contiene los fragmentos que 'iluminaron' con su sonda en la autorradiografía.
c) eliminar (eluir) el ADN de la pieza de gel en un tampón adecuado
d) preparar el ADN para su inserción en (recombinación con) un vector de clonación genómica
B. Recombinación de ADN genómico de tamaño restringido con ADN de fago
Después de la elución de fragmentos de ADN digeridos por restricción del rango de tamaño correcto de los geles, el ADN se mezcla con ADN de fago digerido compatiblemente a concentraciones que favorecen la formación de enlaces H entre los extremos del ADN del fago y los fragmentos genómicos. La adición de ADN ligasa une covalentemente las moléculas de ADN recombinadas. Estos pasos se abrevian en la siguiente ilustración.
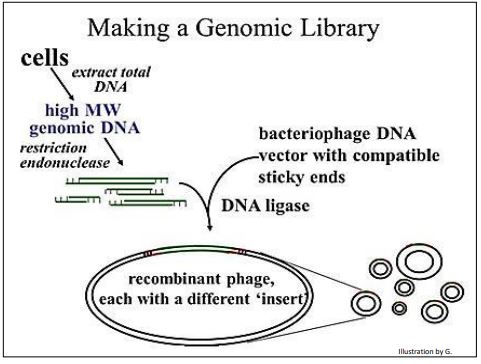
El fago recombinante que se haga a continuación contendrá secuencias que se convierten en la biblioteca genómica.
C. Creación de partículas virales infecciosas con ADN de fago recombinante
El siguiente paso es empaquetar el ADN de fago recombinado con proteínas de cubierta viral purificadas añadidas para producir partículas de fagos infecciosos (abajo)
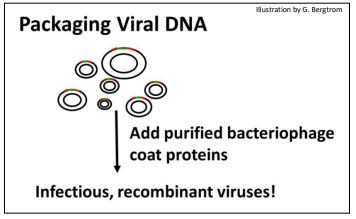
269 Bibliotecas genómicas: Hacer y empaquetar ADN de fago recombinante
Los fagos empaquetados se agregan a un tubo de cultivo lleno de bacterias hospedadoras (típicamente E. coli). Después de la infección, el ADN recombinante ingresa a las células donde se replica y dirige la producción de nuevos fagos que finalmente lisan la célula hospedadora (ilustrado a continuación).
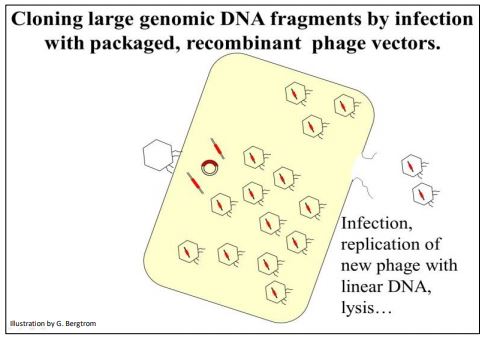
El vector recombinado también se puede introducir directamente en las células hospedadoras por transducción (que es al ADN de fago lo que la transformación es en ADN plasmídico). Ya sea por infección o transducción, el ADN del fago recombinante termina en células hospedadoras que producen nuevos fagos que finalmente lisan la célula hospedadora. Los fagos liberados van a infectar más células hospedadoras hasta que todas las células se hayan lisado. Lo que queda es un tubo lleno de lisado que contiene restos celulares y muchas partículas de fagos recombinantes.
270 Infecta al huésped con fago recombinante para hacer una biblioteca genómica
D. Una nota sobre algunos otros vectores
Hemos visto que los vectores de fagos acomodan insertos de ADN foráneo más grandes que los vectores plasmídicos, y los YAC aún más..., y que para genomas más grandes, el objetivo es elegir un vector capaz de albergar fragmentos más grandes de ADN 'foráneo' para que termines cribando menos clones. Dado un genoma eucariota lo suficientemente grande, puede ser necesario cribar más de cien mil clones en una biblioteca genómica basada en fagos. Aparte de la selección por tamaño de los fragmentos genómicos antes de insertarlos en un vector, seleccionar el vector apropiado es igual de importante. La siguiente tabla enumera los vectores de uso común y los tamaños de insertos que aceptarán.
| Tipo de vector | Tamaño del inserto (miles de bases) |
| Plásmidos | hasta 15 |
| Fago Lambda (\(\lambda \)) | hasta 25 |
| cósmidos | hasta 45 |
| Bacteriófago P1 | 70 a 100 |
| Cromosomas artificiales P1 (PAC) | 130 a 150 |
| Cromosomas artificiales bacterianos (BAC) | 120 a 300 |
| Cromosomas artificiales de levadura (YAC) | 250 a 2000 |
Da click en los enlaces a estos vectores para conocer más sobre ellos. Continuaremos con este ejemplo cribando una biblioteca genómica de lisados de fagos para un fago recombinante con una secuencia genómica de interés.
E. Cribado de una biblioteca genómica; titulación de clones de fagos recombinantes
Un lisado de fago se titula en un césped bacteriano para determinar cuántas partículas de virus están presentes. Un césped bacteriano se hace sembrando tantas bacterias en la placa de agar que simplemente crecen juntas en lugar de como colonias separadas. En una titulación típica, un lisado podría diluirse 10 veces con un medio adecuado y esta dilución se diluye adicionalmente 10 veces... y así sucesivamente. Dichas diluciones en serie 10X se esparcen luego sobre céspedes bacterianos (por ejemplo, E. coli). ¿Qué sucede en una placa de cultivo de este tipo?
Digamos que cuando 10 μl de una de las diluciones se extienden sobre el césped bacteriano, infectan 500 células de E. coli en el césped bacteriano. Después de un día más o menos, habrá pequeños claros en el césped llamados placas..., 500 de ellos en este ejemplo. Se trata de 500 diminutos espacios claros en el césped bacteriano creados por la lisis de una primera célula infectada, y luego progresivamente más y más células vecinas a la célula infectada original. Cada placa es así un clon de un solo virus, y cada partícula de virus en una placa contiene una copia de la misma molécula de ADN de fago recombinante (abajo).

Si realmente contaste 500 placas en la placa de agar, entonces debe haber 500 partículas de virus en los 10 μl sembrados en el césped. Y, si esta placa fue la cuarta dilución en un protocolo de dilución serial de 10 veces, debió haber 2000 (4 X 500) partículas de fago en 10 μl del lisado original sin diluir.
F. Cribado de una biblioteca genómica; sondeo de la biblioteca genómica
Para representar una biblioteca genómica completa, es probable que se tengan que crear muchas placas de tal dilución (~500 placas por placa) y luego cribarse para detectar una placa que contenga un gen de interés. Pero, si en primer lugar solo se insertaran fragmentos seleccionados por tamaño en los vectores de fago, las placas representan solo una biblioteca genómica parcial, requiriendo tamizar menos clones para encontrar la secuencia de interés. Para cualquier tipo de biblioteca, el siguiente paso es hacer filtros de réplica de las placas. La réplica de placas en placas es similar a hacer una réplica de colonias bacterianas filtrantes. Si bien gran parte del ADN del fago en una placa está encerrado en proteínas virales, también habrá ADN en las réplicas de placa que nunca fueron empaquetadas en partículas virales. Los filtros pueden tratarse para desnaturalizar este último ADN y luego hibridarse directamente a una sonda con una secuencia conocida. En los primeros días de la clonación, las sondas para el cribado de una biblioteca genómica eran normalmente un clon de ADNc ya aislado y secuenciado, ya sea de la misma especie que la biblioteca genómica, o de una biblioteca de ADNc de una especie relacionada. Después de remojar los filtros en una sonda marcada radiactivamente, se coloca una película de rayos X sobre el filtro, se expone y se desarrolla. Se formarán manchas negras donde la película se extiende sobre una placa que contiene ADN genómico complementario a la sonda radiactiva. En el ejemplo que se ilustra a continuación, un ADNc de globina podría haberse utilizado para sondear la biblioteca genómica (¡los genes de globina estuvieron entre los primeros en clonarse!).
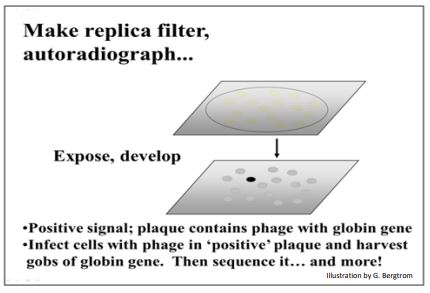
G. Aislamiento de un gen para su posterior estudio
Los fragmentos de ADN genómico clonados son mucho más largos que cualquier gen de interés, y siempre más largos que cualquier ADNc de una biblioteca de ADNc. También están incrustados en un genoma que es miles de veces más largo que el propio gen, haciendo necesaria la selección de un vector apropiado. Si el genoma se puede cribar entre un número razonable de fagos clonados (~100,000 placas por ejemplo), se estudiaría más a fondo la placa que produce una señal positiva en la autoradiografía.
Esta placa debe contener el gen de interés. El siguiente paso es encontrar el gen dentro de un clon genómico que pueda tener tanto una longitud de 20kpb. La estrategia tradicional es purificar el ADN clonado, someterlo a digestión con endonucleasas de restricción y separar las partículas digeridas por electroforesis en gel de agarosa. Usando Southern Blot, los fragmentos de ADN separados se desnaturalizan y se transfunden a un filtro de nylon. Luego se sondea el filtro con la misma sonda etiquetada utilizada para encontrar el clon positivo (placa). El fragmento de ADN más pequeño que contiene el gen de interés puede ser subclonado en un vector adecuado, y cultivado para proporcionar suficiente ADN para un estudio adicional del gen.
271 Cribar una biblioteca genómica, recoger y cultivar un clon de fago