
1.4: Curso Crash en Biología Molecular
- Page ID
- 54854

lecture1_transcript.html #CentralDogma ADN → ARN → Proteína
El dogma central de la biología molecular describe cómo se almacena e interpreta la información genética en la célula: El código genético de un organismo se almacena en el ADN, que se transcribe en ARN, que finalmente se traduce en proteína. Las proteínas llevan a cabo la mayoría de las funciones celulares como la motilidad, la regulación del ADN y la replicación.
Aunque el dogma central es cierto en la mayoría de las situaciones, hay una serie de notables excepciones al modelo. Por ejemplo, los retrovirus son capaces de generar ADN a partir de ARN mediante transcripción inversa. Además, algunos virus son tan primitivos que ni siquiera tienen ADN, sino que solo usan ARN a proteína.
1.4.2 ADN
¿Sabías?
El dogma central a veces se interpreta incorrectamente con demasiada fuerza en el sentido de que el ADN solo almacena información inmutable de una generación a otra que permanece idéntica dentro de una generación, el ARN solo se usa como medio de transferencia de información temporal y las proteínas son la única molécula que puede llevar a cabo acciones complejas.
Nuevamente, hay muchas excepciones a esta interpretación, por ejemplo:
- Las mutaciones somáticas pueden alterar el ADN dentro de una generación, y diferentes células pueden tener diferentes contenidos de ADN.
- Algunas células experimentan alteraciones programadas del ADN durante la maduración, lo que resulta en diferentes contenidos de ADN, la más famosa la inmunidad B y T mientras que las células sanguíneas
- Las modificaciones epigenéticas del ADN pueden heredarse de una generación a otra
- El ARN puede desempeñar muchos papeles diversos en la regulación génica, la detección metabólica y la reacción enzimática
ciones, funciones que antes se pensaba que estaban reservadas a las proteínas.
- Las proteínas en sí mismas pueden sufrir cambios conformacionales que se heredan epigenéticamente sin- modo estados de priones que fueron famosos responsables de la enfermedad de las vacas locas
ADN → ARN → Proteína
Función de ADN
La molécula de ADN almacena la información genética de un organismo. El ADN contiene regiones llamadas genes, que codifican para que se produzcan proteínas. Otras regiones del ADN contienen elementos reguladores, que influyen parcialmente en el nivel de expresión de cada gen. Dentro del código genético del ADN se encuentran tanto los datos sobre las proteínas que necesitan ser codificadas, como los circuitos de control, en forma de motivos reguladores.
Estructura del ADN
El ADN está compuesto por cuatro nucleótidos: A (adenina), C (citosina), T (timina) y G (guanina). A y G son purinas, las cuales tienen dos anillos, mientras que C y T son pirimidinas, con un anillo. A y T están conectados por dos enlaces de hidrógeno, mientras que C y G están conectados por tres enlaces. Por lo tanto, el emparejamiento A-T es más débil que el emparejamiento C-G. (Por esta razón, la composición genética de las bacterias que viven en aguas termales es 80% G-C). lecture1_transcript.html #Complementarity
Las dos cadenas de ADN en la doble hélice son complementarias, lo que significa que si hay una A en una hebra, se unirá a una T en la otra, y si hay una C en una hebra, se unirá a una G en la otra. Las cadenas de ADN también tienen direccionalidad, lo que se refiere a las posiciones del anillo de pentosa donde se conecta la cadena principal de fosfato. Esta convención de direccionalidad proviene del hecho de que la ADN y ARN polimerasa sintetizan en la dirección 5' a 3'. Con esto en mente, podemos decir que las cadenas de ADN son antiparalelas, ya que el extremo 5' de una hebra es adyacente al extremo 3' de la otra. Como resultado, el ADN se puede leer tanto en la dirección 3' a 5' como en la dirección 5' a 3', y los genes y otros elementos funcionales se pueden encontrar en cada una. Por convención, el ADN se escribe de 5' a 3'. Las direcciones 5' y 3' se refieren a las posiciones en el anillo de pentosa donde se conecta la cadena principal de fosfato.
El emparejamiento de bases entre nucleótidos del ADN constituye su estructura primaria y secundaria. Además de la estructura secundaria del ADN, existen varios niveles adicionales de estructura que permiten compactar fuertemente el ADN e influir en la expresión génica (Figura 3). La estructura terciaria describe la torsión en la escalera de ADN que forma una forma helicoidal. En la estructura cuaternaria, el ADN está fuertemente enrollado alrededor de pequeñas proteínas llamadas histonas. Estos complejos de ADN-histona se enrollan adicionalmente en estructuras más ajustadas que se ven en la cromatina.
Antes de que el ADN pueda replicarse o transcribirse en ARN, la estructura de la cromatina debe estar localmente “desempaquetada”. Así, la expresión génica puede ser regulada por modificaciones en la estructura de la cromatina, que hacen más fácil o más difícil que el ADN sea desempaquetado. Esta regulación de la expresión génica a través de la modificación de la cromatina es un ejemplo de epigenética.
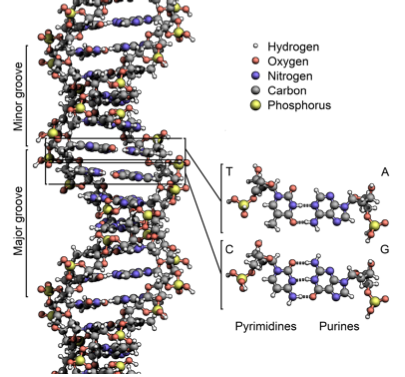
Figura 1.2: La estructura de doble hélice del ADN. Los nucleótidos están en el centro, y el esqueleto de azúcar-fosfato se encuentra en el exterior.
Replicación de ADN
La estructura del ADN, con sus débiles enlaces de hidrógeno entre las bases en el centro, permite separar fácilmente las cadenas con el propósito de replicación del ADN (la capacidad de separar las cadenas de ADN también permite la transcripción, traducción, recombinación y reparación del ADN, entre otras). Esto fue señalado por Watson y Crick como “No ha escapado a nuestro aviso que el emparejamiento específico que hemos postulado de inmediato sugiere un posible mecanismo de copia para el material genético”. En la replicación del ADN, las dos cadenas complementarias se separan, y cada una de las cadenas se utiliza como plantillas para la construcción de una nueva hebra.
Las ADN polimerasas se unen a cada una de las cadenas en el origen de la replicación, leyendo cada hebra existente desde la dirección 3' a 5' y colocando bases complementarias de manera que la nueva cadena crezca en la dirección 5' a 3'. Debido a que la nueva hebra debe crecer de 5' a 3', una hebra (la hebra principal) puede copiarse continuamente, mientras que la otra (la hebra rezagada) crece en trozos que luego son pegados entre sí por la ADN ligasa. El resultado final son 2 piezas bicatenarias de ADN, donde cada una está compuesta por 1 hebra vieja, y 1 nueva hebra; por esta razón, la replicación del ADN es semiconservativa.
Muchos organismos tienen su ADN roto en varios cromosomas. Cada cromosoma contiene dos hebras de ADN, que son complementarias entre sí pero que se leen en direcciones opuestas. Los genes pueden aparecer en cualquiera de las cadenas de ADN. El ADN antes de un gen (en la región 5') se considera “aguas arriba” mientras que el ADN después de un gen (en la región 3') se considera “aguas abajo”.
1.4.3 Transcripción
lecture1_transcript.html #Transcription
ADN → ARN → Proteína
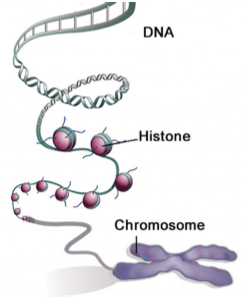
Fuente: Qiu, Jane. “Epigenética: Sinfonía inconclusa”. Naturaleza 441, núm. 7090 (2006): 143-45.
Figura 1.3: El ADN se empaqueta sobre varias capas de organización en un cromosoma compacto
Generación de ARNm
La transcripción es el proceso mediante el cual se produce ARN usando un molde de ADN. El ADN se desenrolla parcialmente para formar una “burbuja”, y la ARN polimerasa es reclutada en el sitio de inicio de la transcripción (TSS) por complejos proteicos reguladores. La ARN polimerasa lee el ADN desde la dirección 3' a 5' y coloca bases complementarias para formar ARN mensajero (ARNm). El ARN usa los mismos nucleótidos que el ADN, excepto que se usa Uracilo en lugar de Timina.
Modificaciones postranscripcionales
El ARNm en eucariotas experimenta modificaciones postraduccionales, o procesos que editan aún más la cadena de ARNm. Lo más notable es que un proceso llamado splicing elimina intrones, interviniendo regiones que no codifican para proteínas, de modo que solo quedan las regiones codificantes, los exones. Diferentes regiones del transcrito primario pueden ser empalmadas para conducir a diferentes productos proteicos (corte y empalme alternativo). De esta manera, se puede generar un enorme número de moléculas diferentes en base a diferentes permutaciones de corte y empalme.
Además del corte y empalme, se procesan ambos extremos de la molécula de ARNm. El extremo 5' está tapado con un nucleótido de guanina modificado. En el extremo 3', se agregan aproximadamente 250 residuos de adenina para formar una cola de poli (A).
RNA
lecture1_transcript.html #RNA
ADN → ARN → Proteína El
ARN se produce cuando se transcribe ADN. Es estructuralmente similar al ADN, con las siguientes diferencias principales:
1. Se utiliza el nucleótido uracilo (U) en lugar de la timina del ADN (T).
2. El ARN contiene ribosa en lugar de desoxirribosa (la desoxirribosa carece de la molécula de oxígeno en la posición 2' que se encuentra en la ribosa).
3. El ARN es monocatenario, mientras que el ADN es bicatenario.
Las moléculas de ARN son el paso intermedio para codificar una proteína. Las moléculas de ARN también tienen funciones catalíticas y reguladoras. Un ejemplo de función catalítica es en la síntesis de proteínas, donde el ARN es parte del ribosoma.
Hay muchos tipos diferentes de ARN, incluyendo:
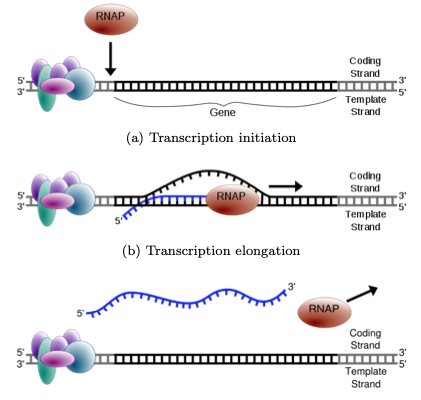
Figura 1.4: El ARN se produce a partir de un molde de ADN durante la transcripción. Se abre una “burbuja” en el ADN, permitiendo que la ARN polimerasa entre y coloque bases complementarias al ADN.
a) Iniciación de la transcripción
b) Alargamiento de la transcripción
c) Terminación de la transcripción
- El ARNm (ARN mensajero) contiene la información para elaborar una proteína y se traduce en secuencia proteica.
- El ARNt (ARN de transferencia) especifica la traducción de codón a aminoácido. Contiene un anti-codón de 3 pares de bases complementario a un codón en el ARNm, y lleva el aminoácido correspondiente a su anticodón unido a su extremo 3'.
- El ARNr (RBA ribosómico) forma el núcleo del ribosoma, el orgánulo responsable de la traducción del ARNm a proteína.
- El ARNsnA (ARN nuclear pequeño) está involucrado en el corte y empalme (eliminación de intrones de) pre- ARNm, así como otras funciones.
Existen otros tipos funcionales de ARN y aún se están descubriendo. Aunque generalmente se piensa que las proteínas llevan a cabo funciones celulares esenciales, las moléculas de ARN pueden tener estructuras tridimensionales complejas y realizar diversas funciones en la célula.
Según la hipótesis del “mundo del ARN”, los primeros años de vida se basaban enteramente en el ARN. El ARN sirvió tanto como repositorio de información (como el ADN hoy en día) como el caballo de batalla funcional (como la proteína hoy en día) en los primeros organismos. Se cree que la proteína surgió después a través de los ribosomas, y se cree que el ADN surgió en último lugar, vía transcripción inversa.
Traducción
lecture1_transcript.html #Translation
ADN → ARN → Proteína
Traducción
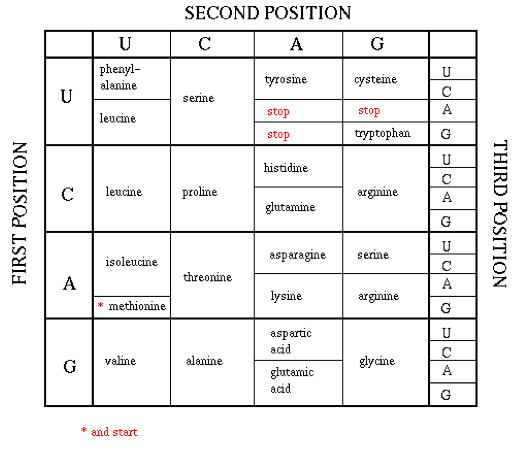
A diferencia de la transcripción, en la que los nucleótidos permanecieron como medio de codificación de información tanto en ADN como en ARN, cuando el ARN se traduce en proteína, la estructura primaria de la proteína está determinada por la secuencia de aminoácidos de la que está compuesta. Dado que existen 20 aminoácidos y solo 4 nucleótidos, las secuencias de 3 nucleótidos en el ARNm, conocidas como codones, codifican para cada uno de los 20 aminoácidos.
Cada una de las 64 posibles 3 secuencias de nucleótidos (codón) especifica de manera única un aminoácido particular, o es un codón de parada que termina la traducción de proteínas (el codón de inicio también codifica metionina). Dado que hay 64 posibles secuencias de codones, el código es degenerado, y algunos aminoácidos se especifican mediante múltiples codificaciones. La mayor parte de la degeneración ocurre en la posición del 3er codón.
Modificaciones postraduccionales
Al igual que el ARNm, la proteína también sufre modificaciones adicionales que afectan su estructura y función. Un tipo de modificación postraduccional (PTM) implica la introducción de nuevos grupos funcionales a los aminoácidos. Más notablemente, la fosforilación es el proceso mediante el cual se añade un grupo fosfato a un aminoácido que puede activar o desactivar la proteína por completo. Otro tipo de PTM es la escisión de enlaces peptídicos. Por ejemplo, la hormona insulina se escinde dos veces después de la formación de enlaces disulfuro dentro de la proteína original.
Proteína
ADN → ARN → Proteína
La proteína es la molécula responsable de llevar a cabo la mayoría de las tareas de la célula, y puede tener muchas funciones, como enzimática, contráctil, transporte, sistema inmune, señal y receptor por nombrar algunas. Al igual que el ARN y el ADN, las proteínas son polímeros elaborados a partir de subunidades repetitivas. En lugar de nucleótidos, sin embargo, las proteínas están compuestas por aminoácidos.
Cada aminoácido tiene propiedades especiales de tamaño, carga, forma y acidez. Como tal, la estructura adicional emerge más allá simplemente de la secuencia de aminoácidos (la estructura primaria), como resultado de las interacciones entre los aminoácidos. Como tal, la forma tridimensional, y por lo tanto la función, de una proteína está determinada por su secuencia. Sin embargo, determinar la forma de una proteína a partir de su secuencia es un problema sin resolver en biología computacional.
Regulación: de las moléculas a la vida
lecture1_transcript.html #Regulation
No todos los genes se expresan al mismo tiempo en una célula. Por ejemplo, las células desperdiciarían energía si producían transportador de lactosa en ausencia de lactosa. Es importante que una célula sepa qué genes debe expresar y cuándo. Se involucra una red reguladora para controlar el nivel de expresión de genes en una circunstancia específica.
La transcripción es una de las etapas en las que se pueden regular los niveles de proteína. La región promotora, un segmento de ADN que se encuentra aguas arriba (más allá del extremo 5') de los genes, funciona en la regulación transcripcional. La región promotora contiene motivos que son reconocidos por proteínas llamadas factores de transcripción. Cuando se unen, los factores de transcripción pueden reclutar ARN polimerasa, lo que lleva a la transcripción génica. Sin embargo, los factores de transcripción también pueden participar en complejas interacciones reguladoras. Puede haber múltiples sitios de unión en un promotor, que pueden actuar como una puerta lógica para la activación génica. La regulación en eucariotas puede ser extremadamente compleja, con la expresión génica afectada no solo por la región promotora cercana, sino también por potenciadores y represores distantes.
Podemos usar modelos probabilísticos para identificar genes que están regulados por un factor de transcripción dado. Por ejemplo, dado el conjunto de motivos que se sabe que se unen a un factor de transcripción dado, podemos calcular la probabilidad de que un motivo candidato también se una al factor de transcripción (ver las notas para el precepto #1). También se puede utilizar el análisis comparativo de secuencias para identificar motivos reguladores, ya que los motivos reguladores muestran patrones característicos de conservación evolutiva.
El operón lac en E. coli y otras bacterias es un ejemplo de un circuito regulador simple. En las bacterias, los genes con funciones relacionadas a menudo se localizan uno al lado del otro, controlados por la misma región reguladora, y se transcriben juntos; este grupo de genes se llama operón. El operón lac funciona en el metabolismo de la lactosa de azúcar, la cual puede ser utilizada como fuente de energía. Sin embargo, las bacterias prefieren usar la glucosa como fuente de energía, por lo que si hay glucosa presente en el ambiente las bacterias no quieren producir las proteínas que están codificadas por el operón lac. Por lo tanto, la transcripción del operón lac está regulada por un circuito elegante en el que la transcripción se produce sólo si hay lactosa pero no glucosa presente en el ambiente.
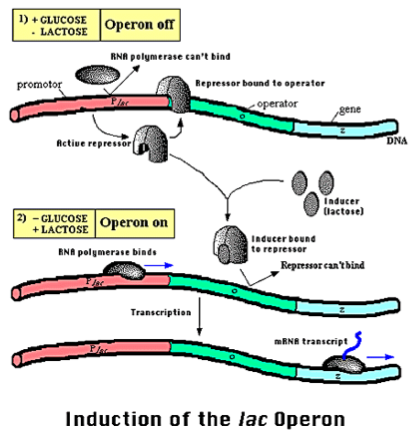
Figura 1.6: El operón Lac ilustra un sistema de regulación biológica simple. En presencia de glucosa, los genes al metabolismo de la lactosa resultan porque la glucosa inactiva una proteína activadora. En ausencia de lactosa, una proteína represora también resulta el operón. Los genes del metabolismo de la lactosa se expresan únicamente en presencia de lactosa y ausencia de glucosa.
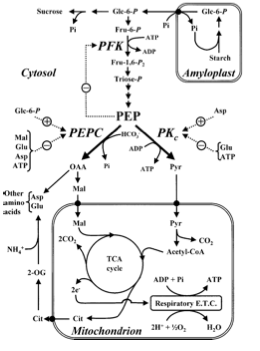
Figura 1.7: Las vías metabólicas y la regulación pueden ser estudiadas por biología computacional. Los modelos se elaboran a partir de información a escala genómica y se utilizan para predecir la función metabólica y para la ingeniería Un ejemplo de ingeniería biológica es modificar el genoma de las bacterias para sobreproducir artemesenina, un antibiótico utilizado para tratar la malaria.
Metabolismo
lecture1_transcript.html#
Los organismos vivos están hechos de bloques de construcción autoorganizados. La fuente de energía es necesaria para organizar los bloques. El mecanismo básico involucrado en los bloques de construcción es degradar las moléculas pequeñas para obtener energía para construir moléculas grandes. El proceso de degradar moléculas para liberar energía se llama catabolismo y el proceso de usar energía para ensamblar moléculas más complejas se llama anabolismo. El anabolismo y el catabolismo son ambos procesos metabólicos. El metabolismo regula el flujo de masa y energía para mantener un organismo en un estado de baja entropía.
Las enzimas son un componente crítico de las reacciones metabólicas. La gran mayoría de (¡pero no todos!) las enzimas son proteínas. Muchas reacciones biológicamente críticas tienen altas energías de activación, por lo que la reacción no catalizada ocurriría extremadamente lenta o nada en absoluto. Las enzimas aceleran estas reacciones, para que puedan ocurrir a un ritmo que sea sustentable para la célula. En las células vivas, las reacciones se organizan en vías metabólicas. Una reacción puede tener muchos pasos, con los productos de un paso sirviendo como sustrato para el siguiente. Además, las reacciones metabólicas a menudo requieren una inversión de energía (notablemente como una molécula llamada ATP), y la energía liberada por una reacción puede ser capturada por una reacción posterior en la ruta. Las vías metabólicas también son importantes para la regulación de las reacciones metabólicas si se inhibe cualquier paso, los pasos posteriores pueden carecer del sustrato o la energía que necesitan para proceder. A menudo, los puntos de control regulatorios aparecen temprano en las vías metabólicas, ya que si es necesario detener la reacción, obviamente es mejor detenerla antes de que se haya invertido mucha energía.
Biología de Sistemas
lecture1_transcript.html #SystemsBiology
La biología de sistemas se esfuerza por explorar y explicar el comportamiento que surge de las complejas interacciones entre los componentes de un sistema biológico. Un artículo reciente interesante en biología de sistemas es “Metabolic gene regulation in a dinámicamente changing environment” (Bennett et al., 2008). Este trabajo hace la suposición de que la levadura es un sistema lineal, invariable en el tiempo, y ejecuta una señal (glucosa) a través del sistema para observar la respuesta. Se observa una respuesta periódica a las fluctuaciones de baja frecuencia en el nivel de glucosa, pero hay poca respuesta a las fluctuaciones de alta frecuencia en el nivel de glucosa. Así, este estudio encuentra que la levadura actúa como un filtro de paso bajo para las fluctuaciones en el nivel de glucosa.
Biología Sintética
lecture1_transcript.html #SyntheticBiology
No solo podemos usar enfoques computacionales para modelar y analizar datos biológicos recopilados de células, sino que también podemos diseñar celdas que implementen circuitos lógicos específicos para llevar a cabo funciones novedosas. La tarea de diseñar nuevos sistemas biológicos se conoce como biología sintética.
Un éxito particularmente notable de la biología sintética es la mejora de la producción de artemesenina. Arteme- senin es un medicamento utilizado para tratar la malaria. Sin embargo, la artemisinina era bastante cara de producir. Recientemente, se ha diseñado una cepa de levadura para sintetizar un precursor del ácido artemisínico a la mitad del costo anterior.
Organismos modelo y biología humana
Existen diversos organismos modelo para todos los aspectos de la biología humana. Importancia del uso de organismos modelo a un nivel apropiado de complejidad.
Nota: En este libro en particular, nos centraremos en la biología humana, y usaremos ejemplos de la levadura de panadero Saccharomyces cerevisiae, la mosca de la fruta Drosophila melanogaster, el gusano nematodo Coenorhabditis elegans y el ratón casero Mus musculus. Trataremos la evolución bacteriana solo en el contexto de la metagenómica del microbioma humano.