8.4: Aprendizaje
- Page ID
- 54684

Vimos cómo puntuar y decodificar una secuencia generada por HMM de dos maneras diferentes. Sin embargo, estos métodos suponían que ya conocíamos las probabilidades de emisión y transición. Si bien siempre somos libres de arriesgarnos a adivinar estos, a veces podemos querer usar un enfoque empírico más basado en datos para derivar estos parámetros. Afortunadamente, el marco HMM permite el aprendizaje de estas probabilidades cuando se proporciona un conjunto de datos de entrenamiento y una arquitectura de conjunto para el modelo.
Cuando se etiquetan los datos de entrenamiento, la estimación de las probabilidades es una forma de aprendizaje supervisado. Uno de esos casos ocurriría si se nos diera una secuencia de ADN de un millón de nucleótidos en la que todas las islas CpG hubieran sido anotadas experimentalmente y se les pidiera que la usáramos para estimar los parámetros de nuestro modelo.
En contraste, cuando los datos de entrenamiento no están etiquetados, el problema de estimación es una forma de aprendizaje no supervisado. Continuando con el ejemplo de isla CpG, esta situación ocurriría si la secuencia de ADN proporcionada no contenía ninguna anotación de isla y necesitábamos estimar los parámetros del modelo e identificar
las islas.
Aprendizaje supervisado
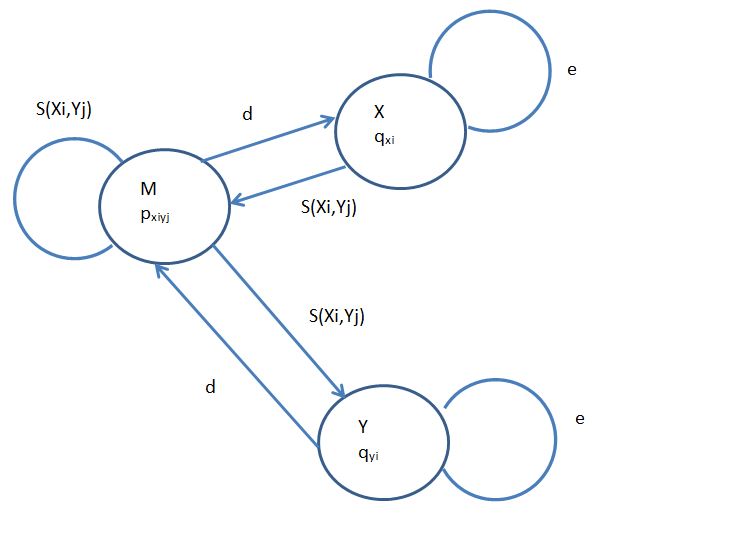
Cuando se proporcionan datos etiquetados, la idea de estimar los parámetros del modelo es sencilla. Supongamos que se le da una secuencia etiquetada x 1,.., x N así como la verdadera secuencia de estado oculto π 1,.., π N. Intuitivamente, se podría esperar que las probabilidades que maximizan la probabilidad de los datos sean las probabilidades reales que se observen dentro de los datos. Este es efectivamente el caso y se puede formalizar definiendo Akl como el número de veces que el estado oculto k pasa a l y E k (b) para que sea el número de veces que b se emite desde el estado oculto k. Los parámetros θ que maximizan P (x|θ) se obtienen simplemente contando de la siguiente manera:
\ [
\ begin {alineado}
a_ {k l} &=\ frac {A_ {k l}} {\ suma_ {i} A_ {k i}}\\
e_ {k} (b) &=\ frac {E_ {k} (b)} {\ sum_ {c} E_ {k} (c)}
\ end {alineado}
\]
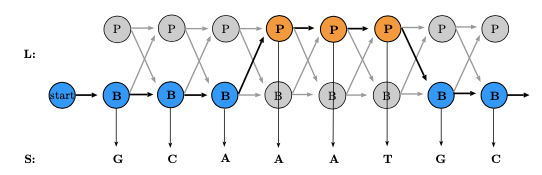
Un conjunto de entrenamiento de ejemplo se muestra en la Figura 8.5. En este ejemplo, es obvio que la probabilidad de transición de B a P es\ (\ begin {ecuación}
\ frac {1} {3+1} =\ frac {1} {4}
\ end {ecuación}\) (hay 3 transiciones B a B y transiciones de 1 B a P) y la probabilidad de emitir una G desde el estado B es\ (\ begin {ecuación}
\ frac {2} {2+2+1} =\ frac {2} {5}
\ end {ecuación}\) (hay 2 G emitidas desde el estado B, 2 C's y 1 A)
Observe, sin embargo, que en el ejemplo anterior la probabilidad de emisión del carácter T del estado B es 0porque no se encontraron tales emisiones en el conjunto de entrenamiento. Una probabilidad cero, ya sea para la transición o emisión, es particularmente problemática porque conduce a una penalización logarítmica infinita. En realidad, sin embargo, la probabilidad cero puede simplemente haber surgido debido a un sobreajuste o un pequeño tamaño de muestra. Para rectificar este problema y mantener la flexibilidad dentro de nuestro modelo, podemos recopilar más datos sobre los que entrenar, reduciendo la posibilidad de que la probabilidad cero se deba a un pequeño tamaño de muestra. Otra posibilidad es usar 'pseudorecuentos' en lugar de recuentos absolutos: agregar artificialmente algunos recuentos a nuestros datos de entrenamiento que creemos que representan con mayor precisión los parámetros reales y ayudan a contrarrestar los errores de tamaño de la muestra.
\ [\ begin {ecuación}
\ begin {array} {l}
A_ {k l} ^ {*} =A_ {k l} +r_ {k l}\\
E_ {k} (b) ^ {*} =E_ {k} (b) +r_ {k} (b)
\ end {array}
\ end {ecuación}. \ nonumber\]
Los parámetros de pseudoconteo más grandes corresponden a una fuerte creencia previa sobre los parámetros, reflejada en el hecho de que estos pseudorecuentos, derivados de tus antecedentes, son comparativamente abrumadoras las observaciones, tus datos de entrenamiento. Asimismo, los parámetros de pseudoconteo pequeños (r << 1) se utilizan con mayor frecuencia cuando nuestros antecedentes son relativamente débiles y pretendemos no abrumar los datos empíricos sino solo evitar probabilidades excesivamente duras de 0.
Aprendizaje no supervisado
El aprendizaje no supervisado implica estimar parámetros basados en datos no etiquetados. Esto puede parecer imposible - ¿cómo podemos tomar datos de los que no sabemos nada y usarlos para” aprender”? - pero un enfoque iterativo puede arrojar resultados sorprendentemente buenos, y es la elección típica en estos casos. Esto puede pensarse vagamente como un algoritmo evolutivo: a partir de alguna elección inicial de parámetros, el algoritmo evalúa qué tan bien los parámetros explican o se relacionan con los datos, utiliza algún paso en esa evaluación para hacer mejoras en los parámetros, y luego evalúa los nuevos parámetros, produciendo incrementos mejoras en los parámetros en cada paso del mismo modo que la aptitud o falta de los mismos de un organismo particular en su entorno produce incrementos incrementales a lo largo del tiempo evolutivo ya que los alelos ventajosos se transmiten preferentemente.
Supongamos que tenemos algún tipo de creencia previa sobre cuál debería ser cada probabilidad de emisión y transición. Dados estos parámetros, podemos usar un método de decodificación para inferir los estados ocultos subyacentes a la secuencia de datos proporcionada. Usando este análisis particular de decodificación, podemos reestimar los recuentos y probabilidades de transición y emisión en un proceso similar al utilizado para el aprendizaje supervisado. Si repetimos este procedimiento hasta que la mejora en la probabilidad de los datos permanezca relativamente estable, la secuencia de datos debería conducir finalmente los parámetros a sus valores apropiados.
FAQ
P: ¿Por qué funciona incluso el aprendizaje sin supervisión? ¿O es mágico?
R: El aprendizaje no supervisado funciona porque tenemos la secuencia (datos de entrada) y esto guía cada paso de la iteración; para pasar de una secuencia etiquetada a un conjunto de parámetros, los posteriores son guiados por la entrada y su anotación, mientras que para anotar los datos de entrada, los parámetros y la secuencia guían el procedimiento.
Para los HMM en particular, dos métodos principales de aprendizaje no supervisado son útiles.
Maximización de expectativas mediante el entrenamiento de Viterbi
El primer método, el entrenamiento Viterbi, es relativamente sencillo pero no del todo riguroso. Después de elegir algunos parámetros iniciales del modelo de mejor estimación, procede de la siguiente manera:
Paso E: Realizar decodificación Viterbi para encontrar π ⋆
Paso M: Calcular los nuevos parámetros\(A_{k l}^{*}, E_{k}(b)^{*}\) utilizando el formalismo de conteo simple en el aprendizaje supervisado (paso de Maximización)
Iteración: Repita los pasos E y M hasta que la probabilidad P (x|θ) converja
Aunque el entrenamiento de Viterbi converge rápidamente, sus estimaciones de parámetros resultantes suelen ser inferiores a las del Algoritmo Baum-Welch. Este resultado se deriva del hecho de que el entrenamiento de Viterbi solo considera el camino oculto más probable en lugar de la colección de todos los caminos ocultos posibles.
Maximización de expectativas: El algoritmo Baum-Welch
El enfoque más riguroso del aprendizaje no supervisado implica la aplicación de la Maximización de Expectativas a los HMM. En general, EM procede de la siguiente manera:
Init: Inicializar los parámetros a algún estado de mejor estimación
Paso E: Estimar la probabilidad esperada de estados ocultos dados los últimos parámetros y la secuencia observada (paso Expectativa)
Paso M: Elija nuevos parámetros de máxima verosimilitud usando la distribución de probabilidad de estados ocultos (paso de Maximización)
Iteración: Repita los pasos E y M hasta que converja la probabilidad de los datos dados los parámetros
El poder de EM radica en el hecho de que se garantiza que P (x|θ) aumente con cada iteración del algoritmo. Por lo tanto, cuando esta probabilidad converge, se ha alcanzado un máximo local. Como resultado, si utilizamos una variedad de estados de inicialización, lo más probable es que podamos identificar el máximo global, es decir, los mejores parámetros θ. El algoritmo Baum-Welch generaliza EM a HMM, en particular, utiliza los algoritmos de avance y retroceso para calcular P (x|θ) y estimar A kl y E k (b). El algoritmo procede de la siguiente manera:
Inicialización 1. Inicializar los parámetros a algún estado de mejor estimación
Iteración 1. Ejecute el algoritmo de avance
2. Ejecute el algoritmo hacia atrás
3. Calcular la nueva probabilidad logarítmica P (x|θ)
4. Calcular Akl y Ek (b)
5. Calcular akl y ek (b) usando las fórmulas de pseudoconteo 6. Repita hasta que P (x|θ) converja
Anteriormente, discutimos cómo calcular P (x|θ) usando los resultados finales del algoritmo hacia adelante o hacia atrás. Pero, ¿cómo estimamos A kl y E k (b)? Consideremos el número esperado de transiciones del estado k al estado l dado un conjunto actual de parámetros θ. Podemos expresar esta expectativa como
\[A_{k l}=\sum_{t} P\left(\pi_{t}=k, \pi_{t+1}=l \mid x, \theta\right)=\sum_{t} \frac{P\left(\pi_{t}=k, \pi_{t+1}=l, x \mid \theta\right)}{P(x \mid \theta)}\nonumber \]
La explotación de la propiedad de Markov y las definiciones de las probabilidades de emisión y transición conduce a la siguiente derivación:
\ [\ comenzar {alineado}
A_ {k l} &=\ suma_ {t}\ frac {P\ izquierda (x_ {1}\ lpuntos x_ {t},\ pi_ {t} =k,\ pi_ {t+1} =l, x_ {t+1}\ lpuntos x_ {N}\ mediados\ theta\ derecha)} {P (x\ mediados\ theta)}\\
&=\ suma_ {t}\ frac {P\ izquierda (x_ {1}\ lpuntos x_ {t},\ pi_ {t} =k\ derecha) * P\ izquierda (\ pi_ {t+1} =l, x_ {t+1}\ lpuntos x_ {N}\ mediados\ pi_ {t},\ theta\ derecha)} {P (x\ mediados\ theta)}\\
&=\ sum_ {t}\ frac {f_ {k} (t) * P\ izquierda (\ pi_ {t+1} =l\ mediados\ pi_ {t} =k\ derecha) * P\ izquierda (x_ {t+1}\ mediados\ pi_ {t+1} =l\ derecha) * P\ izquierda (x_ {t+2}\ lpuntos x_ {N}\ mediados\ pi_ {t+1} =l,\ theta\ derecha)} {P (x\ mediados\ theta)}\
\\ fila derecha A_ {k l} &=\ sum_ {t}\ frac {f_ {k} (t) * a_ {k l} * e_ {l}\ izquierda (x_ {t+1}\ derecha) * b_ {l} (t+1)} {P (x\ mid\ theta)}
\ final {alineado}\]
Una derivación similar conduce a la siguiente expresión para E k (b):
\[E_{k}(b)=\sum_{i \mid x_{i}=b} \frac{f_{k}(t) * b_{k}(t)}{P(x \mid \theta)}\]
Por lo tanto, al ejecutar los algoritmos de avance y retroceso, tenemos toda la información necesaria para calcular P (x|θ) y actualizar las probabilidades de emisión y transición durante cada iteración. Debido a que estas actualizaciones son operaciones de tiempo constante una vez que se han calculado P (x|θ), f k (t) y b k (t), la complejidad de tiempo total para esta versión del aprendizaje no supervisado es θ (K 2 NS), donde S es el número total de iteraciones.
FAQ
P: ¿Cómo codificas tus creencias previas al aprender con Baum-Welch?
R: Esas creencias previas están codificadas en las inicializaciones de los algoritmos hacia adelante y hacia atrás