
3.2: Resumiendo los datos- Estadísticas descriptivas
- Page ID
- 54720

¿Cómo se resumen los datos?
Los datos se resumen de dos formas principales: cálculos de resumen y visualizaciones de resumen
Cálculos: ¿Qué tipos de medidas se utilizan?
Para poder interpretar patrones en los datos, los datos brutos deben primero manipularse y resumirse en dos categorías de mediciones: Medidas de tendencia central y Medidas de variabilidad. Estas dos categorías de medidas encapsulan el primer paso de la investigación científica, la estadística descriptiva.
Medidas de tendencia central (centro) — Proporciona información de cómo se agrupan los datos alrededor de algún valor medio único. Hay dos medidas de centro utilizadas con mayor frecuencia en la investigación biológica:
- Media (promedio) — Suma de todos los valores individuales divididos por el número total de valores en muestra/población. Esta es la medida más utilizada de centro bajo distribución simétrica y es sensible a los valores atípicos.
- Mediana — El valor medio cuando el conjunto de datos se ordena en rango secuencial (de mayor a menor). Esto se usa comúnmente cuando los datos están sesgados y son resistentes a valores atípicos.
Medidas de variabilidad (propagación) — Describe qué tan dispersos o dispersos están los datos. Existen dos medidas principales de propagación utilizadas en la investigación biológica:
- Rango — Cuantifica la distancia entre los valores de datos más grandes y más pequeños.
- Desviación estándar — Cuantifica la variación o dispersión a partir del promedio de un conjunto de datos. Una desviación estándar baja indica que los datos tienden a estar muy cerca de la media; una desviación estándar alta indica que los puntos de datos están dispersos en un amplio rango de valores. Este cálculo es sensible a los valores atípicos.
- Error estándar: cuantifica la variación en las medias de múltiples conjuntos de datos o una distribución de muestra de su conjunto de datos original.
Visualizando los datos: ¿Cómo se utilizan las tablas y gráficas?
Después de calcular todas las estadísticas descriptivas deseadas, normalmente se resumen visualmente en una tabla o gráfica.
Mesas:
Una tabla es un conjunto de valores de datos dispuestos en columnas y filas. Por lo general, las columnas abarcan una categoría de datos amplia y las filas abarcan otra. Dentro de cada categoría amplia hay subcategorías que determinan cuántas columnas y filas consiste la tabla. Las tablas se utilizan para recopilar y resumir datos. Sin embargo, la mayoría de las veces cuando se presentan las tablas, consisten en datos resumidos, no datos brutos. Aunque las tablas permiten que los datos resumidos se presenten de manera ordenada, la mayoría de las personas prefieren traducir tablas a la herramienta de visualización de datos más poderosa, una gráfica.
Gráficas:
Un gráfico es un diagrama que muestra la relación entre cantidades variables, típicamente de dos variables, cada una medida a lo largo de uno de un par de ejes en ángulo recto. Las gráficas pueden verse como un gráfico o un dibujo. La mayoría de los gráficos utilizan barras, líneas o partes de un círculo para mostrar datos. Sin embargo, a veces hay cuando los gráficos se superponen en la parte superior de los mapas para mostrar también la ubicación geográfica, o incluso se animan para ser interactivos.
Categorías principales de tipos de gráfico:
- Círculo/Circular — Un gráfico circular dividido en cortes para ilustrar la proporción numérica. En un gráfico circular, la longitud del arco de cada corte (y en consecuencia su ángulo central y área), es proporcional a la cantidad que representa. Si bien recibe su nombre por su parecido con un pastel que ha sido rebanado, hay variaciones en la forma en que se puede presentar.
- Línea — Un tipo de gráfico que muestra información como una serie de puntos de datos llamados 'marcadores' conectados por segmentos de línea recta. Es un tipo básico de gráfico común en muchos campos. Es similar a una gráfica de dispersión excepto que los puntos de medición están ordenados (típicamente por su valor del eje x) y unidos con segmentos de línea recta. A menudo se usa un gráfico de líneas para visualizar una tendencia en los datos a lo largo de intervalos de tiempo, una serie de tiempo, por lo que la línea a menudo se dibuja cronológicamente.
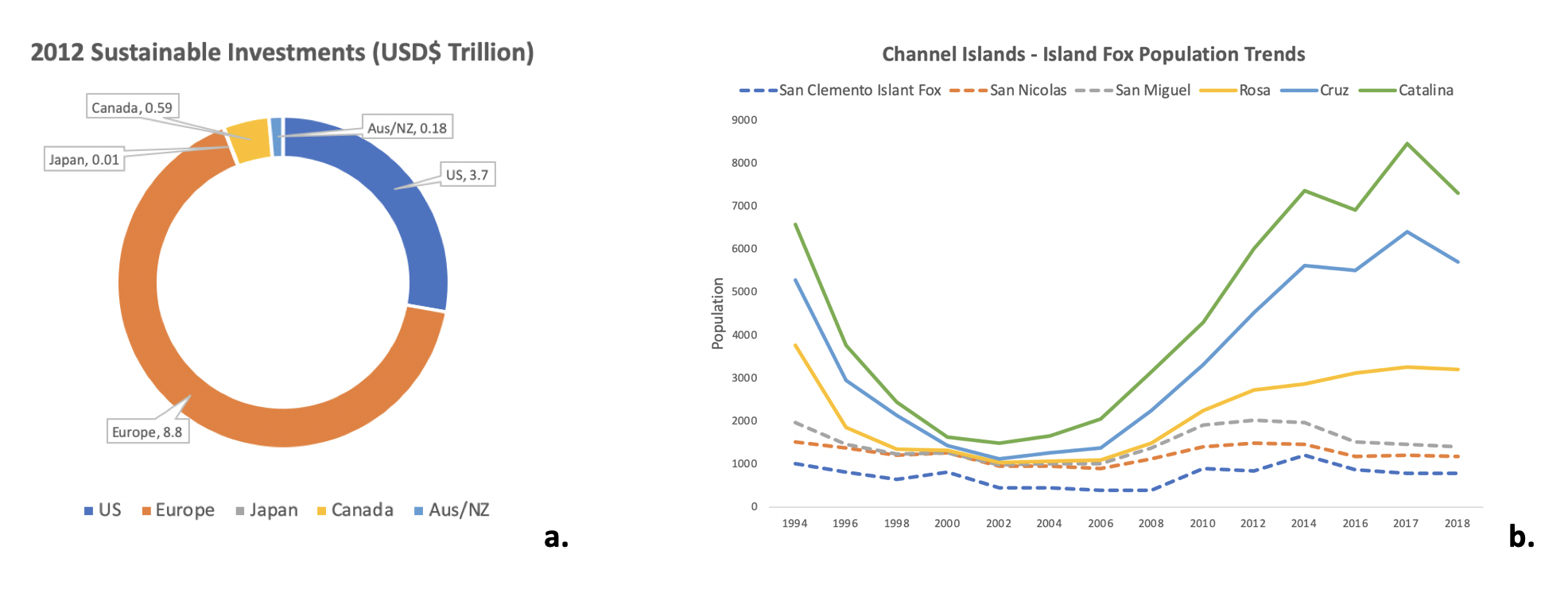
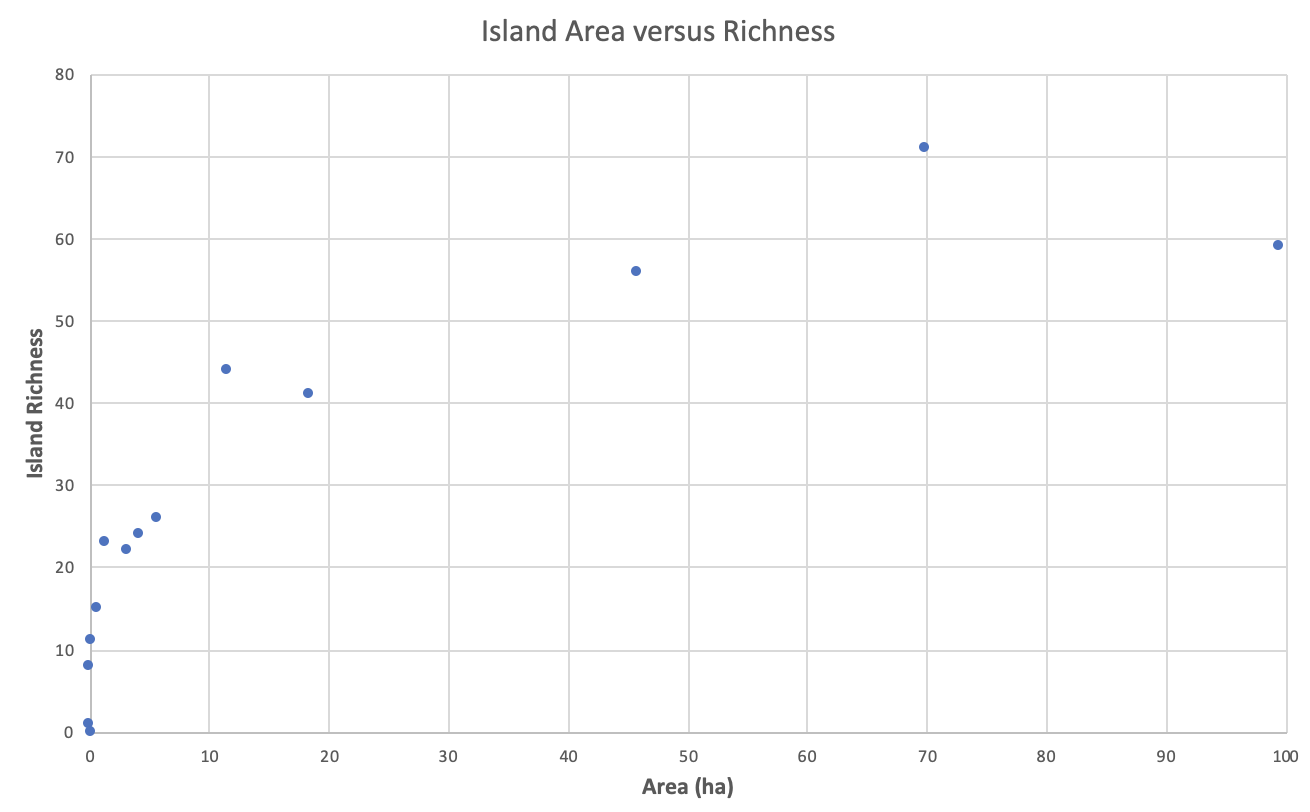
- Gráfica de dispersión — Es una gráfica en la que los valores de dos variables se trazan a lo largo de los ejes horizontal y vertical, revelando el patrón de los puntos resultantes cualquier preajuste de correlación . Los datos se muestran como una colección de puntos, cada uno teniendo el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable que determina la posición en el eje vertical.
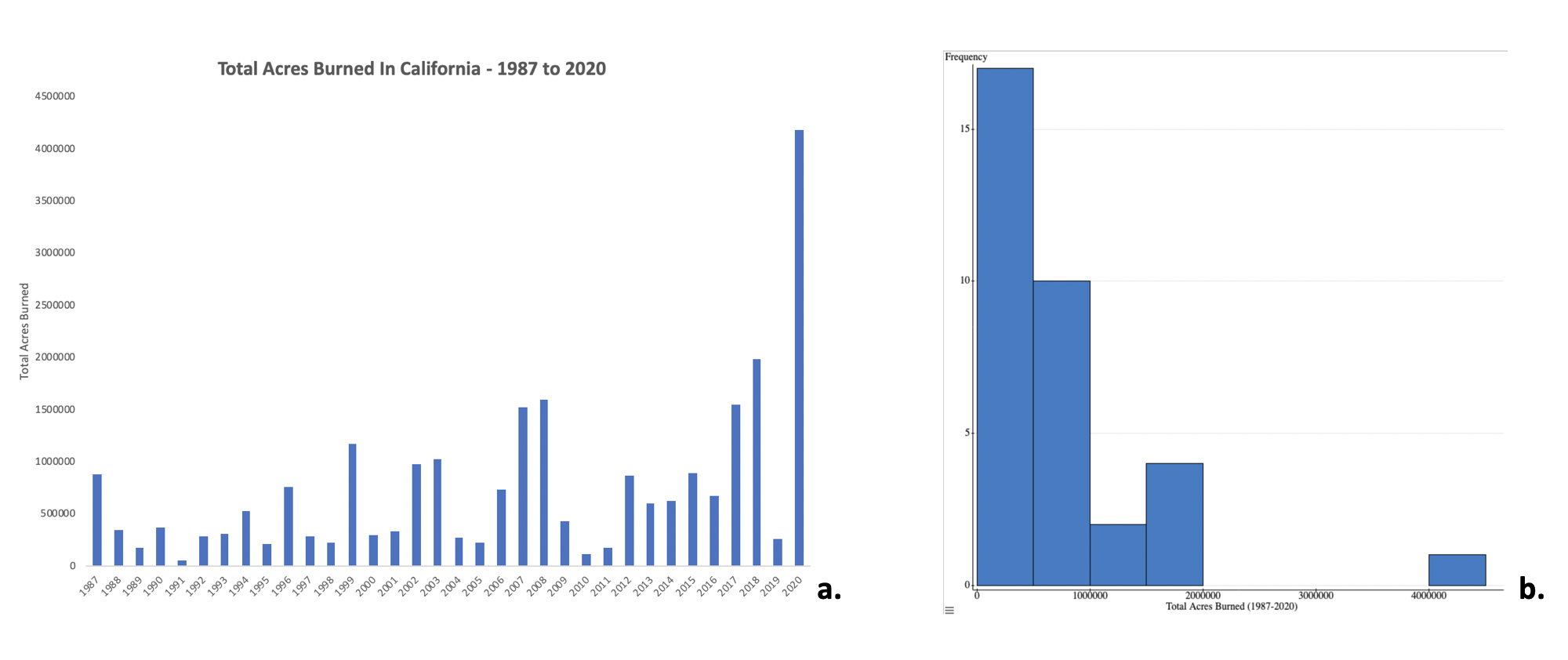
- Barra — Un gráfico o gráfico que presenta datos categóricos con barras rectangulares con alturas o longitudes proporcionales a los valores que representan. Las barras se pueden trazar vertical u horizontalmente.
- Histograma — Es una representación aproximada de la distribución de datos numéricos. Para construir un histograma, el primer paso es “bin” (o “bucket”) el rango de valores, es decir, dividir todo el rango de valores en una serie de intervalos, y luego contar cuántos valores caen en cada intervalo. Los bins generalmente se especifican como intervalos consecutivos, no superpuestos de una variable. Los bins (intervalos) deben ser adyacentes (lo que significa que no hay espacios entre ellos como los hay en los gráficos de barras), y suelen ser (pero no se requiere que sean) de igual tamaño. Si los contenedores son del mismo tamaño, se erige un rectángulo sobre el contenedor con una altura proporcional a la frecuencia, el número de cajas en cada contenedor.
Atribución
Rachel Schleiger (CC-BY-NC)