
4.2: Viendo
- Page ID
- 143465
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Identificar las estructuras clave del ojo y el papel que desempeñan en la visión.
- Resume cómo el ojo y la corteza visual trabajan juntos para detectar y percibir los estímulos visuales en el ambiente, incluyendo el procesamiento de colores, forma, profundidad y movimiento.
Mientras que otros animales dependen principalmente de escuchar, oler o tocar para entender el mundo que los rodea, los seres humanos dependen en gran parte de la visión. Gran parte de nuestra corteza cerebral se dedica a ver, y tenemos habilidades visuales sustanciales. El ver comienza cuando la luz cae sobre los ojos, iniciando el proceso de transducción. Una vez que esta información visual llega a la corteza visual, es procesada por una variedad de neuronas que detectan colores, formas y movimiento, y que crean percepciones significativas a partir de los estímulos entrantes.
El aire que nos rodea está lleno de un mar de energía electromagnética; pulsos de ondas de energía que pueden llevar información de un lugar a otro. Como puede ver en la Figura\(\PageIndex{6}\), las ondas electromagnéticas varían en su longitud de onda, la distancia entre un pico de onda y el siguiente pico de onda, siendo las ondas gamma más cortas de solo una fracción de milímetro de longitud y las ondas de radio más largas de cientos de kilómetros de largo. Los humanos son ciegos a casi toda esta energía; nuestros ojos detectan solo el rango de aproximadamente 400 a 700 mil millonésimas de metro, la parte del espectro electromagnético conocida como espectro visible.
Figura\(\PageIndex{6}\) El Espectro Electromagnético
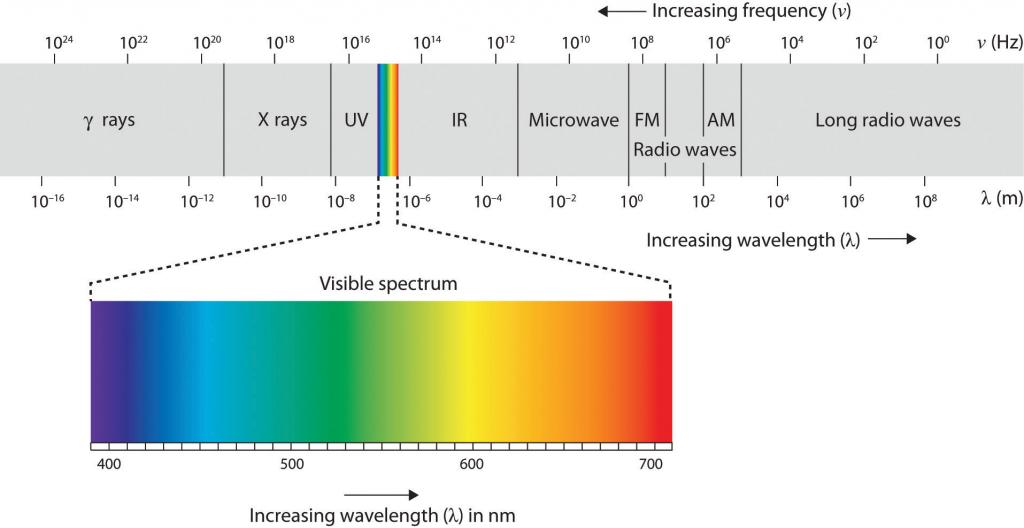
Sólo una pequeña fracción de la energía electromagnética que nos rodea (el espectro visible) es detectable por el ojo humano.
El ojo sensible y la corteza visual perceptora
Como se puede ver en la Figura\(\PageIndex{7}\), la luz ingresa al ojo a través de la córnea, una cubierta transparente que protege el ojo y comienza a enfocar la luz entrante. La luz pasa entonces a través de la pupila, una pequeña abertura en el centro del ojo. La pupila está rodeada por el iris, la parte coloreada del ojo que controla el tamaño de la pupila por constricción o dilatación en respuesta a la intensidad de la luz. Cuando entramos en un cine oscuro en un día soleado, por ejemplo, los músculos del iris abren la pupila y permiten que entre más luz. La adaptación completa a la oscuridad puede tardar hasta 20 minutos.
Detrás de la pupila se encuentra el cristalino, una estructura que enfoca la luz entrante en la retina, la capa de tejido en la parte posterior del ojo que contiene células fotorreceptoras. A medida que nuestros ojos se mueven de objetos cercanos a objetos distantes, se produce un proceso conocido como acomodación visual. La acomodación visual es el proceso de cambiar la curvatura de la lente para mantener la luz que entra al ojo enfocada en la retina. Los rayos de la parte superior de la imagen golpean la parte inferior de la retina y viceversa, y los rayos del lado izquierdo de la imagen golpean la parte derecha de la retina y viceversa, haciendo que la imagen en la retina esté boca abajo y hacia atrás. Además, la imagen proyectada sobre la retina es plana y, sin embargo, nuestra percepción final de la imagen será tridimensional.
\(\PageIndex{7}\)Anatomía de la Figura del Ojo Humano
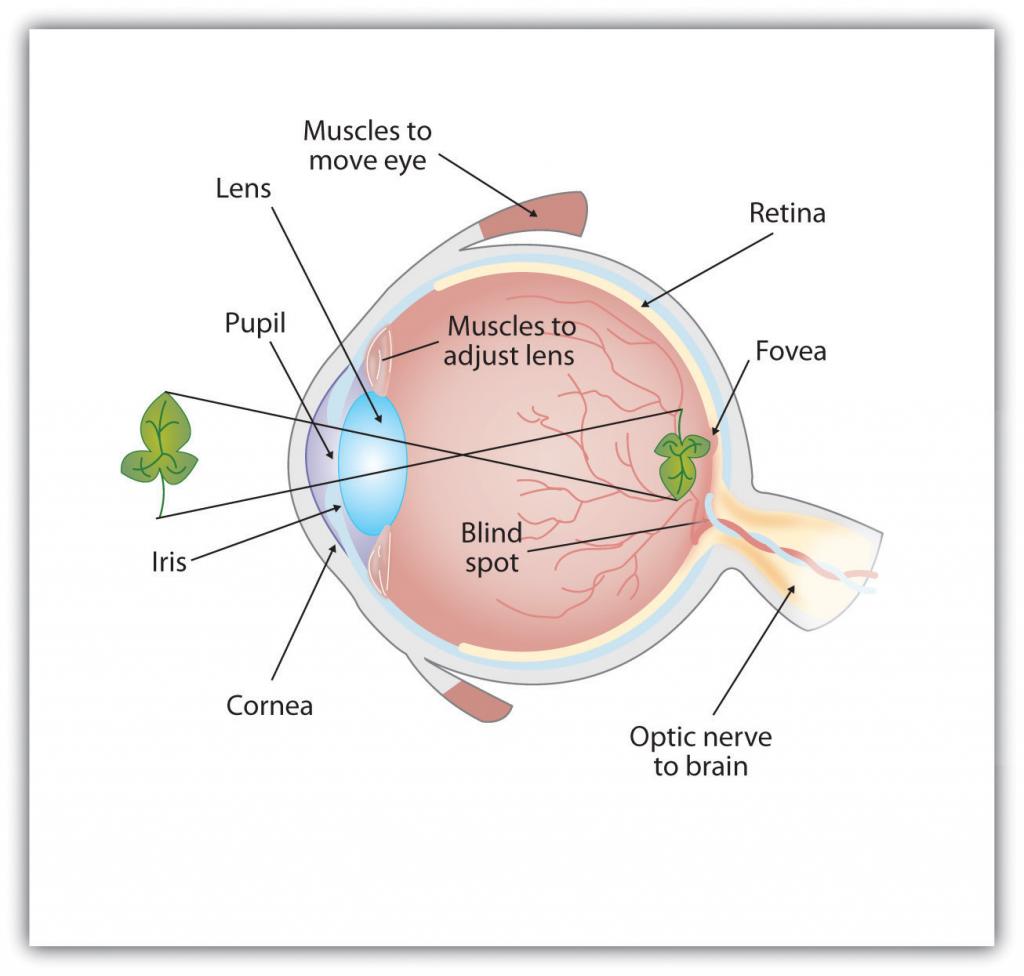
La luz ingresa al ojo a través de la córnea transparente, pasando por la pupila en el centro del iris. El lente se ajusta para enfocar la luz en la retina, donde aparece boca abajo y hacia atrás. Las células receptoras en la retina envían información a través del nervio óptico a la corteza visual.
El alojamiento no siempre es perfecto, y en algunos casos la luz que está golpeando la retina está un poco desenfocada. Como se puede ver en la Figura\(\PageIndex{8}\), si el foco está frente a la retina, decimos que la persona es miope, y cuando el foco está detrás de la retina decimos que la persona es hipermetropía. Los anteojos y lentes de contacto corrigen este problema al agregar otra lente frente al ojo, y la cirugía ocular con láser corrige el problema remodelando el propio cristalino del ojo.
Figura Ojos\(\PageIndex{8}\) Normales, Miopía y Miopía
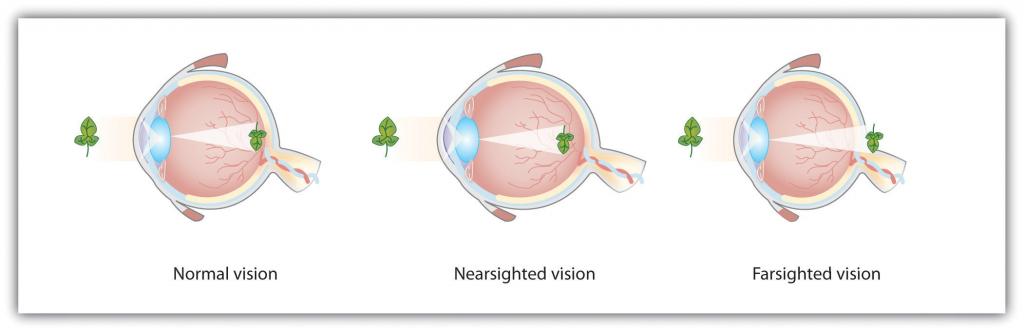
Para las personas con visión normal (izquierda), el cristalino enfoca adecuadamente la luz entrante en la retina. Para las personas miopes (centro), las imágenes de objetos lejanos se enfocan demasiado frente a la retina, mientras que para las personas con hipermetropía (derecha), las imágenes de objetos cercanos se enfocan demasiado detrás de la retina. Los anteojos resuelven el problema agregando una lente secundaria, correctiva.
La retina contiene capas de neuronas especializadas para responder a la luz (Figura\(\PageIndex{9}\)). A medida que la luz cae sobre la retina, primero activa las células receptoras conocidas como bastones y conos. La activación de estas células luego se extiende a las células bipolares y luego a las células ganglionares, que se juntan y convergen, como las hebras de una cuerda, formando el nervio óptico. El nervio óptico es una colección de millones de neuronas ganglionares que envía grandes cantidades de información visual, a través del tálamo, al cerebro. Debido a que la retina y el nervio óptico son procesadores activos y analizadores de información visual, no es inapropiado pensar en estas estructuras como una extensión del cerebro mismo.
Figura\(\PageIndex{9}\) La Retina Con Sus Células Especializadas
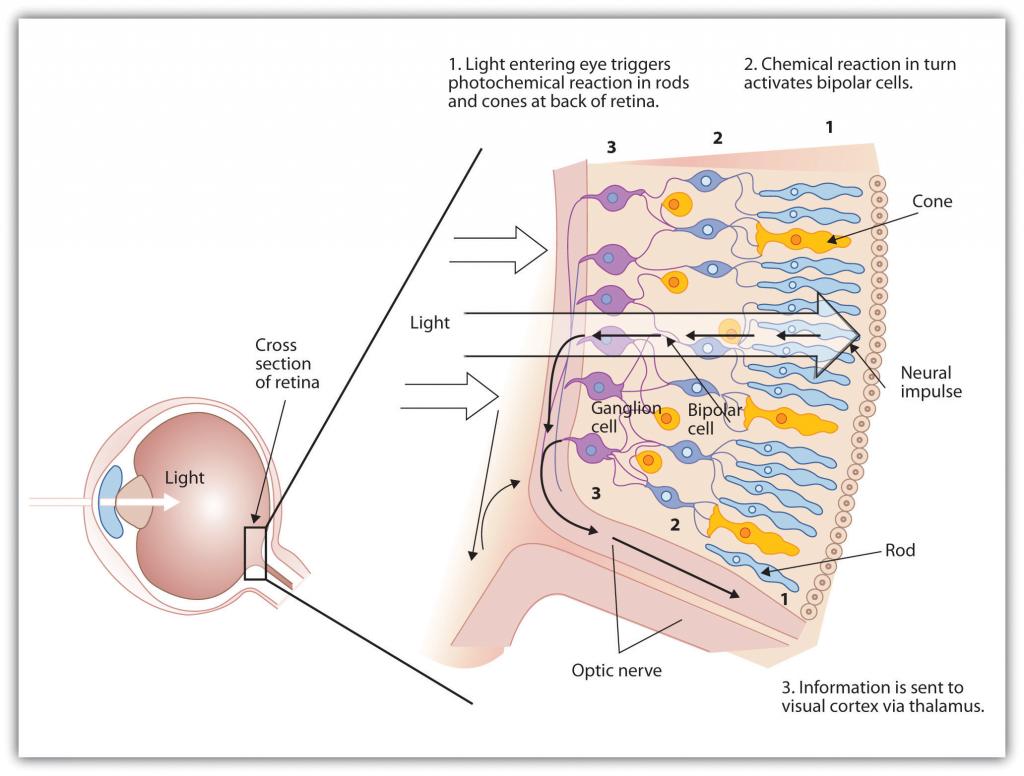
Cuando la luz cae sobre la retina, crea una reacción fotoquímica en los bastones y conos en la parte posterior de la retina. Luego continúan las reacciones a las células bipolares, las células ganglionares y eventualmente al nervio óptico.
Las varillas son neuronas visuales que se especializan en detectar colores negro, blanco y gris. Hay alrededor de 120 millones de varillas en cada ojo. Las varillas no proporcionan mucho detalle sobre las imágenes que vemos, pero debido a que son muy sensibles a la luz de onda más corta (más oscura) y débil, nos ayudan a ver con poca luz, por ejemplo, de noche. Debido a que las varillas se encuentran principalmente alrededor de los bordes de la retina, son particularmente activas en la visión periférica (cuando necesites ver algo por la noche, intenta apartar la mirada de lo que quieres ver). Los conos son neuronas visuales que se especializan en detectar detalles finos y colores. Los aproximadamente 5 millones de conos en cada ojo nos permiten ver en color, pero funcionan mejor con luz brillante. Los conos se localizan principalmente dentro y alrededor de la fóvea, que es el punto central de la retina.
Para demostrar la diferencia entre barras y conos en la atención al detalle, elija una palabra en este texto y concéntrese en ella. ¿Te das cuenta de que las palabras a unos centímetros a un lado parecen más borrosas? Esto se debe a que la palabra en la que te estás enfocando golpea los conos orientados a los detalles, mientras que las palabras que lo rodean golpean las varillas menos orientadas a los detalles, que se encuentran en la periferia.
Figura La sonrisa de\(\PageIndex{10}\) Mona Lisa

Margaret Livingstone (2002) encontró un efecto interesante que demuestra las diferentes capacidades de procesamiento de las varillas y conos del ojo, es decir, que la sonrisa de Mona Lisa, que se conoce ampliamente como “esquiva”, se percibe de manera diferente dependiendo de cómo se mire la pintura. Debido a que Leonardo da Vinci pintó la sonrisa con pinceladas de bajo detalle, estos detalles son mejor percibidos por nuestra visión periférica (las varillas) que por los conos. Livingstone descubrió que la gente calificó a la Mona Lisa como más alegre cuando se les indicó que se enfocaran en sus ojos que cuando se les pidió que miraran directamente su boca. Como dijo Livingstone, “Ella sonríe hasta que miras su boca, y luego se desvanece, como una tenue estrella que desaparece cuando la miras directamente”.
Foto cortesía del Museo del Louvre.
Como se puede ver en la Figura\(\PageIndex{11}\), la información sensorial que recibe la retina se transmite a través del tálamo a las zonas correspondientes de la corteza visual, que se localiza en el lóbulo occipital en la parte posterior del cerebro. Si bien el principio de control contralateral podría llevarte a esperar que el ojo izquierdo enviara información al hemisferio cerebral derecho y viceversa, la naturaleza es más inteligente que eso. De hecho, cada uno de los ojos izquierdo y derecho envía información tanto al hemisferio izquierdo como al derecho, y la corteza visual procesa cada una de las señales por separado y en paralelo. Esta es una ventaja adaptacional a un organismo que pierde de vista en un ojo, pues aunque solo un ojo sea funcional, ambos hemisferios seguirán recibiendo entrada de él.
\(\PageIndex{11}\)Vía de la Figura de las Imágenes Visuales a Través del Tálamo y Hacia la Corteza Visual
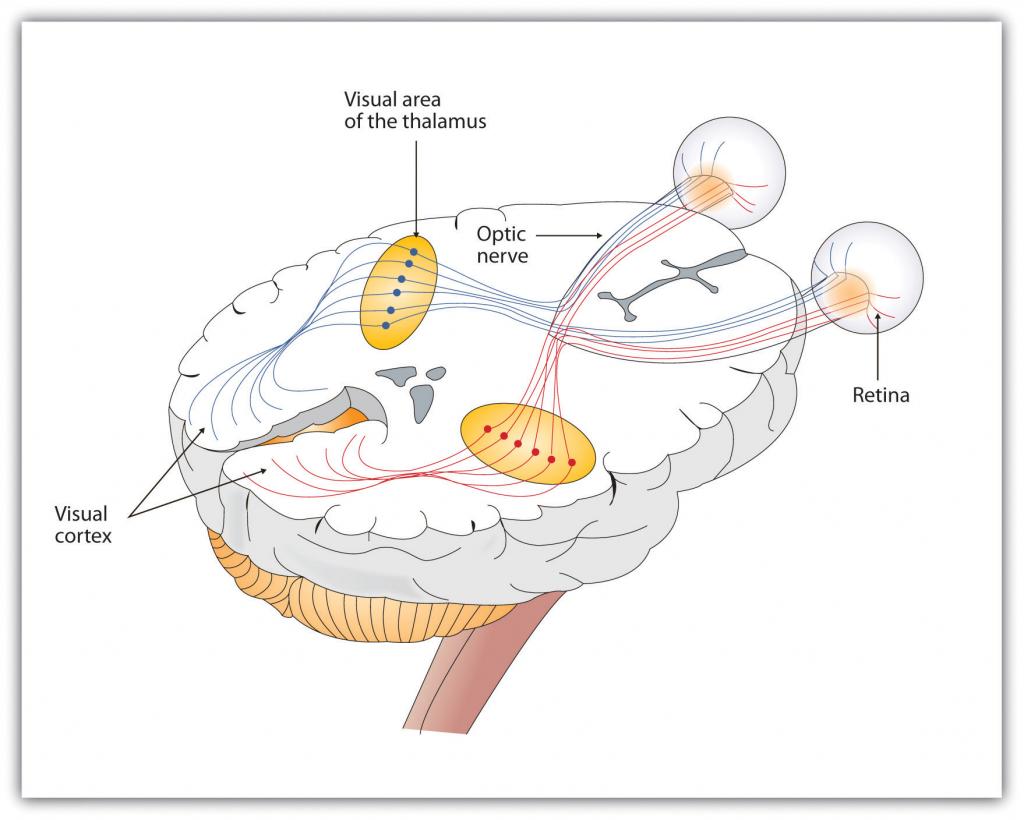
Los ojos izquierdo y derecho envían cada uno información tanto al hemisferio cerebral izquierdo como al derecho.
La corteza visual está conformada por neuronas especializadas que convierten las sensaciones que reciben del nervio óptico en imágenes significativas. Debido a que no hay células fotorreceptoras en el lugar donde el nervio óptico sale de la retina, se crea un agujero o punto ciego en nuestra visión (Figura\(\PageIndex{12}\)). Cuando ambos ojos están abiertos, no experimentamos ningún problema porque nuestros ojos se mueven constantemente, y un ojo compensa lo que el otro pierde. Pero el sistema visual también está diseñado para hacer frente a este problema si solo un ojo está abierto: la corteza visual simplemente llena el pequeño agujero en nuestra visión con patrones similares de las áreas circundantes, y nunca notamos la diferencia. La capacidad del sistema visual para hacer frente al punto ciego es otro ejemplo de cómo la sensación y la percepción trabajan juntas para crear una experiencia significativa.
Demostración de punto\(\PageIndex{12}\) ciego de figura

Puedes hacerte una idea de la extensión de tu punto ciego (el lugar donde el nervio óptico sale de la retina) probando esta demostración. Cierra el ojo izquierdo y mira con el ojo derecho la cruz en el diagrama. Deberías poder ver la imagen del elefante a la derecha (no lo mires, solo fíjate que está ahí). Si no puedes ver al elefante, acércate o más lejos hasta que puedas. Ahora muévete lentamente para que estés más cerca de la imagen mientras sigues mirando la cruz. A una distancia (probablemente un pie más o menos), el elefante desaparecerá completamente de la vista porque su imagen ha caído en el punto ciego.
La percepción se crea en parte a través de la acción simultánea de miles de neuronas detectoras de características, neuronas especializadas, ubicadas en la corteza visual, que responden a la fuerza, ángulos, formas, bordes y movimientos de un estímulo visual (Kelsey, 1997; Livingstone & Hubel, 1988). Los detectores de características funcionan en paralelo, cada uno realizando una función especializada. Cuando se enfrentan a un cuadrado rojo, por ejemplo, los detectores de características de línea paralela, los detectores de características de línea horizontal y los detectores de características de color rojo se activan. Esta activación se transmite luego a otras partes de la corteza visual donde otras neuronas comparan la información suministrada por los detectores de características con imágenes almacenadas en la memoria. De repente, en un destello de reconocimiento, las muchas neuronas se disparan juntas, creando la única imagen del cuadrado rojo que experimentamos (Rodriguez et al., 1999).
Figura\(\PageIndex{13}\) El Cube Necker
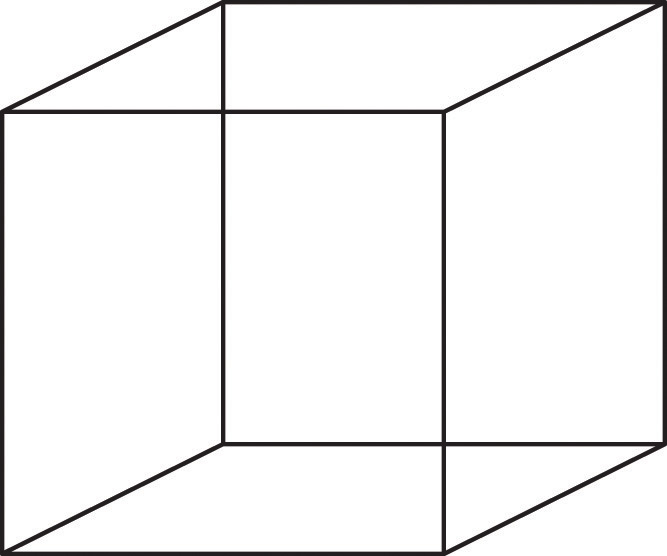
El cubo Necker es un ejemplo de cómo el sistema visual crea percepciones a partir de las sensaciones. No vemos una serie de líneas, sino un cubo. Qué cubo vemos varía dependiendo del resultado momentáneo de los procesos perceptuales en la corteza visual.
Algunos detectores de características están sintonizados para responder selectivamente a objetos particularmente importantes, por ejemplo, rostros, sonrisas y otras partes del cuerpo (Downing, Jiang, Shuman, & Kanwisher, 2001; Haxby et al., 2001). Cuando los investigadores interrumpieron las áreas de reconocimiento facial de la corteza usando los pulsos magnéticos de la estimulación magnética transcraneal (TMS), las personas fueron temporalmente incapaces de reconocer rostros y, sin embargo, aún podían reconocer casas (McKone, Kanwisher, & Duchaine, 2007; Pitcher, Walsh, Yovel y Duchaine, 2007).
Percibir el color
Se ha estimado que el sistema visual humano puede detectar y discriminar entre 7 millones de variaciones de color (Geldard, 1972), pero todas estas variaciones son creadas por las combinaciones de los tres colores primarios: rojo, verde y azul. El tono de un color, conocido como matiz, es transmitido por la longitud de onda de la luz que ingresa al ojo (vemos longitudes de onda más cortas como más azules y longitudes de onda más largas como más rojas), y detectamos brillo a partir de la intensidad o altura de la onda (se perciben ondas más grandes o más intensas como más brillante).
Figura\(\PageIndex{14}\) Ondas sinusoidales de baja y alta frecuencia y ondas sinusoidales de baja y alta intensidad y sus colores correspondientes
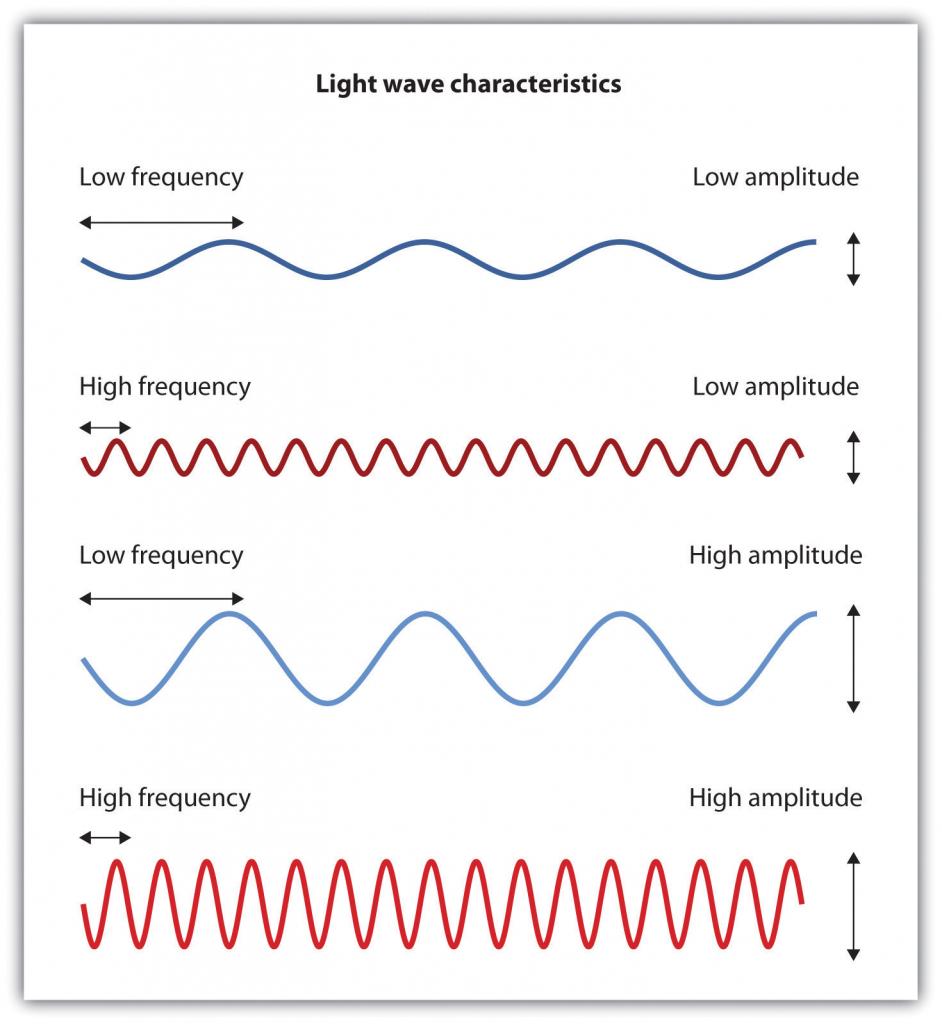
Las ondas de luz con frecuencias más cortas se perciben como más azules que rojas; las ondas de luz con mayor intensidad se ven como más brillantes.
En su importante investigación sobre la visión del color, Hermann von Helmholtz (1821—1894) teorizó que el color se percibe porque los conos en la retina vienen en tres tipos. Un tipo de cono reacciona principalmente a la luz azul (longitudes de onda cortas), otro reacciona principalmente a la luz verde (longitudes de onda medias) y un tercero reacciona principalmente a la luz roja (longitudes de onda largas). La corteza visual luego detecta y compara la fuerza de las señales de cada uno de los tres tipos de conos, creando la experiencia del color. De acuerdo con esta teoría tricromática del color Young-Helmholtz, qué color vemos depende de la mezcla de las señales de los tres tipos de conos. Si el cerebro está recibiendo principalmente señales rojas y azules, por ejemplo, percibirá el púrpura; si está recibiendo principalmente señales rojas y verdes percibirá el amarillo; y si está recibiendo mensajes de los tres tipos de conos percibirá el blanco.
Las diferentes funciones de los tres tipos de conos son evidentes en personas que experimentan daltonismo, la incapacidad de detectar colores verdes y/o rojos. Alrededor de 1 de cada 50 personas, en su mayoría hombres, carecen de funcionamiento en los conos sensibles al rojo o al verde, dejándolos solo capaces de experimentar uno o dos colores (Figura\(\PageIndex{15}\)).
Figura\(\PageIndex{15}\)

Las personas con visión cromática normal pueden ver el número 42 en la primera imagen y el número 12 en la segunda (son vagos pero aparentes). No obstante, las personas daltónicas no pueden ver los números en absoluto.
Wikimedia Commons.
Sin embargo, la teoría tricromática del color no puede explicar toda la visión humana. Por un lado, aunque el color púrpura sí nos aparece como una mezcla de rojo y azul, el amarillo no parece ser una mezcla de rojo y verde. Y las personas con daltonismo, que no pueden ver ni el verde ni el rojo, sin embargo todavía pueden ver el amarillo. Una aproximación alternativa a la teoría Young-Helmholtz, conocida como la teoría del color del proceso oponente, propone que analicemos la información sensorial no en términos de tres colores sino en tres conjuntos de “colores del oponente”: rojo-verde, amarillo-azul y blanco-negro. La evidencia para la teoría del proceso oponente proviene del hecho de que algunas neuronas en la retina y en la corteza visual están excitadas por un color (por ejemplo, rojo) pero inhibidas por otro color (por ejemplo, verde).
Un ejemplo de procesamiento oponente ocurre en la experiencia de una imagen secundaria. Si miras la bandera del lado izquierdo de la figura\(\PageIndex{16}\) durante unos 30 segundos (cuanto más te veas, mejor será el efecto), y luego mueves tus ojos hacia el área en blanco a la derecha de la misma, verás la imagen secundaria. Cuando miramos fijamente las franjas verdes, nuestros receptores verdes se habituan y comienzan a procesarse con menos fuerza, mientras que los receptores rojos permanecen en plena potencia. Cuando cambiamos de mirada, vemos principalmente la parte roja del proceso oponente. Procesos similares crean azul tras amarillo y blanco después negro.
Figura Bandera de\(\PageIndex{16}\) Estados Unidos

La presencia de una imagen secundaria se explica mejor por la teoría del proceso opositor de la percepción del color. Mira la bandera durante unos segundos, y luego mueve tu mirada hacia el espacio en blanco que está junto a ella. ¿Ves la imagen posterior?
Mike Swanson — Bandera de Estados Unidos (invertida) — dominio público.
El tricolor y los mecanismos oponente-proceso trabajan juntos para producir visión del color. Cuando los rayos de luz ingresan al ojo, los conos rojo, azul y verde en la retina responden en diferentes grados, y envían diferentes señales de intensidad de rojo, azul y verde a través del nervio óptico. Las señales de color son luego procesadas tanto por las células ganglionares como por las neuronas en la corteza visual (Gegenfurtner & Kiper, 2003).
Percibir la forma
Uno de los procesos importantes que se requieren en la visión es la percepción de la forma. Los psicólogos alemanes en las décadas de 1930 y 1940, entre ellos Max Wertheimer (1880—1943), Kurt Koffka (1886—1941) y Wolfgang Köhler (1887—1967), argumentaron que creamos formas a partir de sus sensaciones componentes basadas en la idea de la gestalt, un todo significativamente organizado. La idea de la gestalt es que el “todo es más que la suma de sus partes”. Algunos ejemplos de cómo los principios gestálticos nos llevan a ver más de lo que realmente hay se resumen en la Tabla\(\PageIndex{1}\).
| Principio | Descripción | Ejemplo | Imagen |
|---|---|---|---|
| Figura y suelo | Estructuramos la entrada de tal manera que siempre vemos una figura (imagen) contra un suelo (fondo). | A la derecha, es posible que veas un jarrón o puedes ver dos caras, pero en cualquier caso, organizarás la imagen como una figura contra un suelo. | Figura\(\PageIndex{1}\)
|

Figura\(\PageIndex{1}\)

Figura\(\PageIndex{1}\)
Figura\(\PageIndex{1}\)

Figura\(\PageIndex{1}\)

Percibir la profundidad
La percepción de profundidad es la capacidad de percibir el espacio tridimensional y juzgar con precisión la distancia. Sin percepción de profundidad, no podríamos conducir un automóvil, enhebrar una aguja o simplemente navegar por el supermercado (Howard & Rogers, 2001). La investigación ha encontrado que la percepción de profundidad se basa en parte en capacidades innatas y en parte aprendida a través de la experiencia (Witherington, 2005).
Los psicólogos Eleanor Gibson y Richard Walk (1960) probaron la capacidad de percibir la profundidad en bebés de 6 a 14 meses colocándolos en un acantilado visual, mecanismo que da la percepción de una caída peligrosa, en la que los bebés pueden ser probados de manera segura para determinar su percepción de profundidad (Figura \(\PageIndex{22}\)). Los infantes fueron colocados a un lado del “acantilado”, mientras que sus madres los llamaban desde el otro lado. Gibson y Walk encontraron que la mayoría de los infantes o bien se arrastraban lejos del acantilado o permanecían en la pizarra y lloraban porque querían ir con sus madres, pero los infantes percibieron un abismo que instintivamente no podían cruzar. Investigaciones adicionales han encontrado que incluso los niños muy pequeños que aún no pueden gatear tienen miedo de las alturas (Campos, Langer, & Krowitz, 1970). Por otro lado, estudios también han encontrado que los infantes mejoran su coordinación mano-ojo a medida que aprenden a agarrar mejor los objetos y a medida que adquieren más experiencia en el rastreo, lo que indica que también se aprende la percepción de profundidad (Adolph, 2000).
La percepción de profundidad es el resultado de nuestro uso de señales de profundidad, mensajes de nuestro cuerpo y del entorno externo que nos proporcionan información sobre el espacio y la distancia. Las señales de profundidad binocular son señales de profundidad creadas por la disparidad de la imagen retiniana, es decir, el espacio entre nuestros ojos y, por lo tanto, que requieren la coordinación de ambos ojos. Un resultado de la disparidad retiniana es que las imágenes proyectadas en cada ojo son ligeramente diferentes entre sí. La corteza visual fusiona automáticamente las dos imágenes en una sola, lo que nos permite percibir la profundidad. Las películas tridimensionales hacen uso de la disparidad retiniana mediante el uso de gafas 3-D que el espectador usa para crear una imagen diferente en cada ojo. El sistema perceptual convierte rápida, fácil e inconscientemente la disparidad en 3-D.
Una señal de profundidad binocular importante es la convergencia, el giro hacia adentro de nuestros ojos que se requiere para enfocarnos en objetos que están a menos de unos 50 pies de distancia de nosotros. La corteza visual utiliza el tamaño del ángulo de convergencia entre los ojos para juzgar la distancia del objeto. Podrás sentir tus ojos convergiendo si lentamente acercas un dedo a tu nariz mientras sigues enfocándose en ella. Cuando cierras un ojo, ya no sientes la tensión; la convergencia es una señal de profundidad binocular que requiere que ambos ojos funcionen.
El sistema visual también utiliza acomodación para ayudar a determinar la profundidad. A medida que la lente cambia su curvatura para enfocarse en objetos distantes o cercanos, la información transmitida desde los músculos unidos a la lente nos ayuda a determinar la distancia de un objeto. El alojamiento solo es efectivo a distancias de visión cortas, sin embargo, por lo que si bien es útil al enhebrar una aguja o atar cordones de los zapatos, es mucho menos efectivo al conducir o practicar deportes.
Aunque las mejores señales de profundidad ocurren cuando ambos ojos trabajan juntos, somos capaces de ver la profundidad incluso con un ojo cerrado. Las señales de profundidad monocular son señales de profundidad que nos ayudan a percibir la profundidad usando un solo ojo (Sekuler y Blake, 2006). Algunos de los más importantes se resumen en Tabla\(\PageIndex{2}\).
| Nombre | Descripción | Ejemplo | Imagen |
|---|---|---|---|
| Posición | Tendemos a ver objetos más arriba en nuestro campo de visión como más lejos. | Los postes de la cerca a la derecha aparecen más lejos no sólo porque se hacen más pequeños sino también porque aparecen más arriba en la imagen. | Figura\(\PageIndex{2}\)
|

Figura\(\PageIndex{2}\)
 Allan Ferguson — Trolley Cruces Autopista — CC BY 2.0.
Allan Ferguson — Trolley Cruces Autopista — CC BY 2.0.
Figura\(\PageIndex{2}\)
 Bo Insogna, TheLightningMan.com — Relámpago golpeando por las vías del tren — CC BY-NC-ND 2.0.
Bo Insogna, TheLightningMan.com — Relámpago golpeando por las vías del tren — CC BY-NC-ND 2.0.
Figura\(\PageIndex{2}\)

Figura\(\PageIndex{2}\)

Figura\(\PageIndex{2}\)
 Frans Koppelaar — Paisaje cerca de Bolonia — CC BY-SA 2.5.
Frans Koppelaar — Paisaje cerca de Bolonia — CC BY-SA 2.5.
Fuentes de fotos: TBD
Percibir movimiento
Muchos animales, entre ellos los seres humanos, tienen habilidades perceptuales muy sofisticadas que les permiten coordinar su propio movimiento con el movimiento de los objetos en movimiento para crear una colisión con ese objeto. Los murciélagos y aves utilizan este mecanismo para ponerse al día con sus presas, los perros lo usan para atrapar un Frisbee y los humanos lo usan para atrapar un balón de fútbol en movimiento. El cerebro detecta movimiento en parte por el tamaño cambiante de una imagen en la retina (los objetos que se ven más grandes suelen estar más cerca de nosotros) y en parte por el brillo relativo de los objetos.
También experimentamos movimiento cuando los objetos cercanos unos a otros cambian su apariencia. El efecto beta se refiere a la percepción de movimiento que se produce cuando diferentes imágenes se presentan una junto a la otra en sucesión (Nota 4.43 “Efecto Beta y Fenómeno Phi”). La corteza visual llena la parte faltante del movimiento y vemos al objeto moviéndose. El efecto beta se utiliza en películas para crear la experiencia del movimiento. Un efecto relacionado es el fenómeno phi, en el que percibimos una sensación de movimiento causada por la aparición y desaparición de objetos que están cerca unos de otros. El fenómeno phi parece una zona móvil o una nube de color de fondo que rodea los objetos parpadeantes. El efecto beta y el fenómeno phi son otros ejemplos de la importancia de lo gestalt, nuestra tendencia a “ver más que la suma de las partes”.
Efecto Beta y Fenómeno Phi
En el efecto beta, nuestros ojos detectan movimiento a partir de una serie de imágenes fijas, cada una con el objeto en un lugar diferente. Este es el mecanismo fundamental de las películas (películas). En el fenómeno phi, la percepción del movimiento se basa en el ocultamiento momentáneo de una imagen.
Fenómeno Phi: Upload.wikimedia.org/wikipedia/commons/6/6e/Lilac-Chaser.gif
Efecto beta: Upload.wikimedia.org/wikipedia/commons/0/09/Phi_Phenomenom_no_watermark.gif
Claves para llevar
- La visión es el proceso de detectar la energía electromagnética que nos rodea. Solo una pequeña fracción del espectro electromagnético es visible para los humanos.
- Las células receptoras visuales de la retina detectan forma, color, movimiento y profundidad.
- La luz ingresa al ojo a través de la córnea transparente y pasa a través de la pupila en el centro del iris. El lente se ajusta para enfocar la luz en la retina, donde aparece boca abajo y hacia atrás. Las células receptoras en la retina son excitadas o inhibidas por la luz y envían información a la corteza visual a través del nervio óptico.
- La retina tiene dos tipos de células fotorreceptoras: bastones, que detectan brillo y responden al blanco y negro, y conos, que responden al rojo, verde y azul. El daltonismo ocurre cuando las personas carecen de función en los conos sensibles al rojo o al verde.
- Las neuronas detectoras de características en la corteza visual nos ayudan a reconocer objetos, y algunas neuronas responden selectivamente a rostros y otras partes del cuerpo.
- La teoría tricromática del color Young-Helmholtz propone que la percepción del color es el resultado de las señales enviadas por los tres tipos de conos, mientras que la teoría del color del proceso oponente propone que percibamos el color como tres conjuntos de colores del oponente: rojo-verde, amarillo-azul y blanco-negro.
- La capacidad de percibir la profundidad se produce a través del resultado de señales de profundidad binoculares y monoculares.
- El movimiento se percibe como una función del tamaño y brillo de los objetos. El efecto beta y el fenómeno phi son ejemplos de movimiento percibido.
Ejercicios y Pensamiento Crítico
- Considera algunas formas en que los procesos de percepción visual te ayudan a realizar una actividad cotidiana, como conducir un automóvil o andar en bicicleta.
- Imagina por un momento cómo sería tu vida si no pudieras ver. ¿Crees que podrías compensar tu pérdida de vista usando otros sentidos?
Referencias
Adolph, K. E. (2000). Especificidad del aprendizaje: Por qué los infantes caen sobre un verdadero acantilado. Ciencia Psicológica, 11 (4), 290—295.
Campos, J. J., Langer, A., & Krowitz, A. (1970). Respuestas cardíacas en el precipicio visual en lactantes prelocomotores humanos. Ciencia, 170 (3954), 196—197.
Downing, P. E., Jiang, Y., Shuman, M., & Kanwisher, N. (2001). Un área cortical selectiva para el procesamiento visual del cuerpo humano. Ciencia, 293 (5539), 2470—2473.
Gegenfurtner, K. R., & Kiper, D. C. (2003). Visión de color. Revisión Anual de Neurociencia, 26, 181—206.
Geldard, F. A. (1972). Los sentidos humanos (2a ed.). Nueva York, NY: John Wiley & Sons.
Gibson, E. J., & Walk, R. D. (1960). El “acantilado visual”. Scientific American, 202 (4), 64—71.
Haxby, J. V., Gobbini, M. I., Furey, M. L., Ishai, A., Schouten, J. L., & Pietrini, P. (2001). Representaciones distribuidas y superpuestas de caras y objetos en la corteza temporal ventral. Ciencia, 293 (5539), 2425—2430.
Howard, I. P., & Rogers, B. J. (2001). Ver en profundidad: Mecanismos básicos (Vol. 1). Toronto, Ontario, Canadá: Porteous.
Kelsey, C.A. (1997). Detección de información visual. En W. R. Hendee & P. N. T. Wells (Eds.), La percepción de la información visual (2ª ed.). Nueva York, NY: Springer Verlag.
Livingstone M. S. (2000). ¿Hace calor? ¿Es real? ¿O simplemente baja frecuencia espacial? Ciencia, 290, 1299.
Livingstone, M., & Hubel, D. (1998). Segregación de forma, color, movimiento y profundidad: Anatomía, fisiología y percepción. Ciencia, 240, 740—749.
McKone, E., Kanwisher, N., & Duchaine, B. C. (2007). ¿La experiencia genérica puede explicar el procesamiento especial de rostros? Tendencias en Ciencias Cognitivas, 11, 8—15;
Jarra, D., Walsh, V., Yovel, G., & Duchaine, B. (2007). Evidencia de TMS para la participación del área de la cara occipital derecha en el procesamiento facial temprano. Biología Actual, 17, 1568—1573.
Rodríguez, E., George, N., Lachaux, J.-P., Martinerie, J., Renault, B., & Varela, F. J. (1999). La sombra de la percepción: Sincronización a larga distancia de la actividad cerebral humana. Naturaleza, 397 (6718), 430—433.
Sekuler, R., & Blake, R., (2006). Percepción (5ª ed.). Nueva York, NY: McGraw-Hill.
Witherington, D. C. (2005). El desarrollo del control prospectivo de agarre entre 5 y 7 meses: Un estudio longitudinal. Infancia, 7 (2), 143—161.